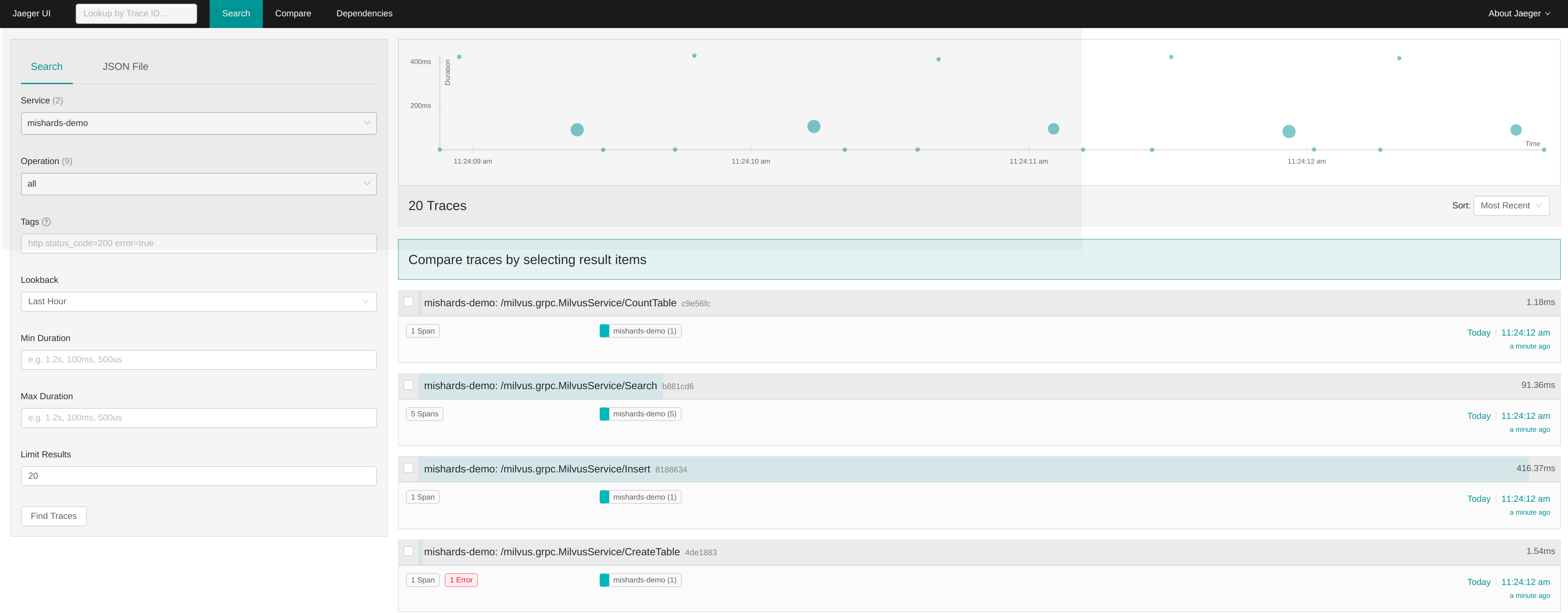
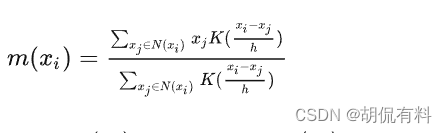链表是一种通过指针串联在一起的线性结构,每一个节点由两部分组成,一个是数据域,一个是指针域(存放指向下一节点的指针)。
链表的类型
单链表
每一个节点由两部分组成,一个是数据域一个是指针域(存放指向下一个节点的指针),最后一个节点的指针域指向null(空指针的意思)。只能向后查询。
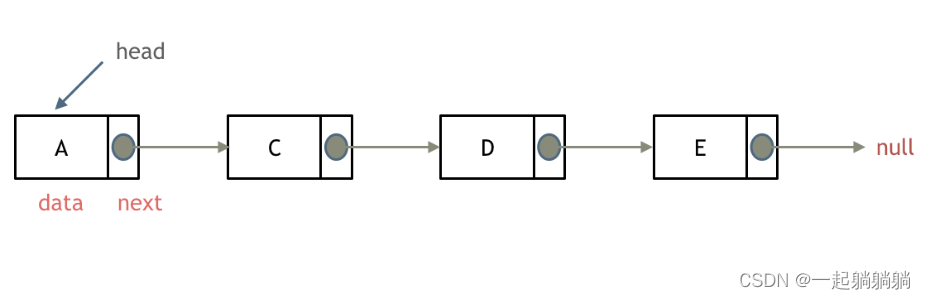
双链表
每一个节点有两个指针域,一个指向下一节点,一个指向上一节点。既可以向前查询也可以向后查询。
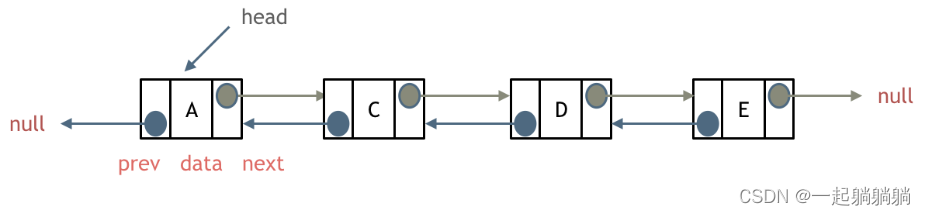
循环列表
就是首尾相连的单链表。
链表的存储方式
数组在内存中是连续分布的,链表不是,链表是通过指针与的指针链接在内存中的各个节点,是散乱分布在内存中的,分配机制取决于操作系统的内存管理。
如图所示:
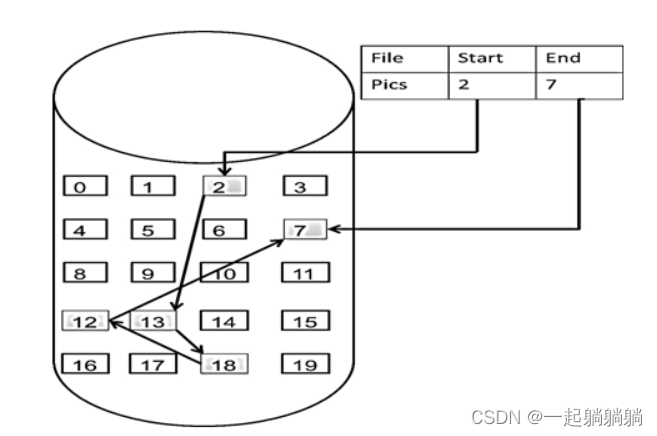
链表的定义
C/C++的定义链表结点的方式:
// 单链表
struct ListNode {
int val; // 节点上存储的元素
ListNode *next; // 指向下一个节点的指针
ListNode(int x) : val(x), next(NULL) {} // 节点的构造函数
};也可以不定义构造函数,C++默认生成一个构造函数,但是这个构造函数不会初始化任何成员变量,下面我来举两个例子:
通过自己定义构造函数初始化节点:
ListNode* head = new ListNode(5);
使用默认构造函数初始化节点:
ListNode* head = new ListNode();
head->val = 5;
所以如果不定义构造函数使用默认构造函数的话,在初始化的时候就不能直接给变量赋值!
链表的操作
删除节点
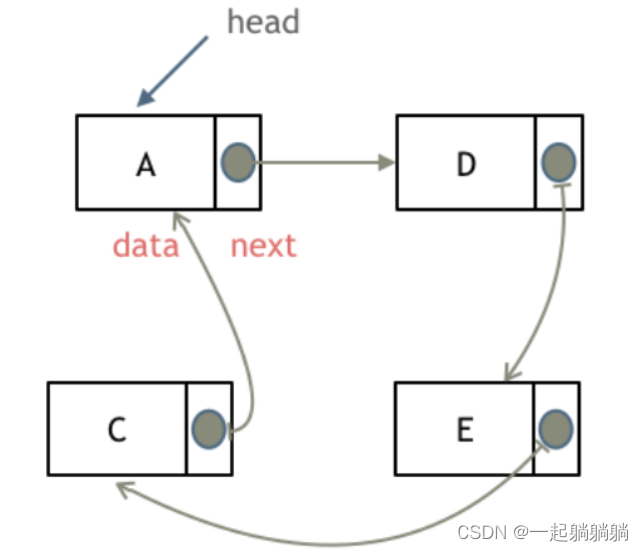
删除D节点,如图所示:
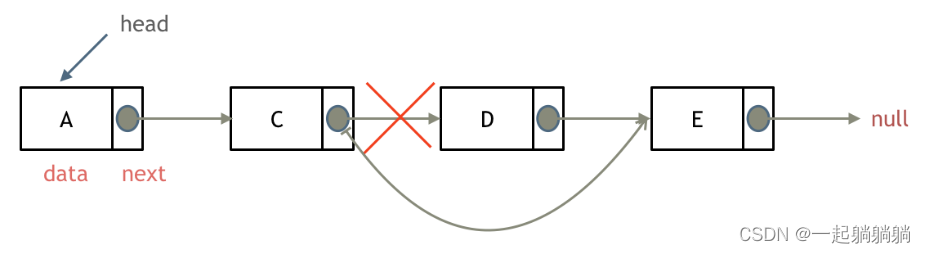
只需要将C的next指针指向E就好了,在C++中可以手动释放D节点内存。
添加节点
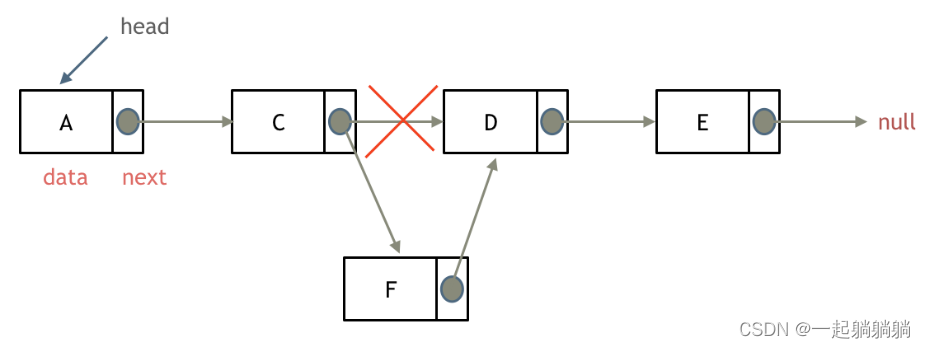
链表的增添和删除都是O(1),也不会影响其他节点,但是如果要删除第n个节点,需要从头查找到第n-1个节点,通过其next指针进行删除操作,查找的时间复杂度是O(N)。
数组和链表的对比
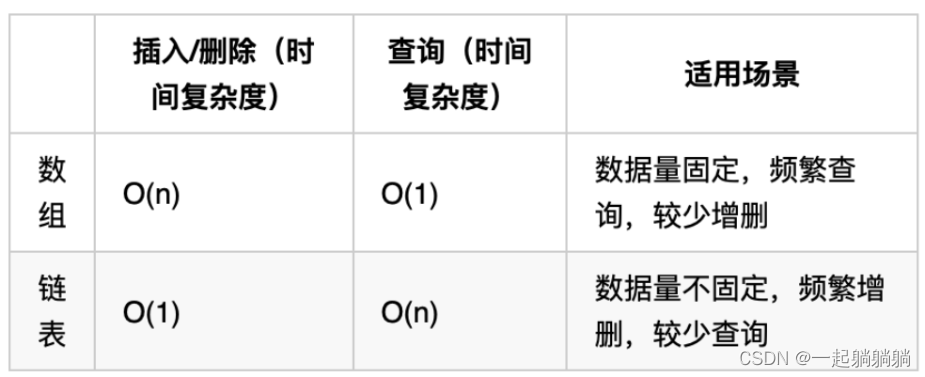
数组在顶的的时候,长度就是固定的,如果想改动数组的长度,就需要定义一个新的数组。
链表的长度可以是不固定的,并且可以动态增删,适合数据量不固定,频繁增删,较少查询的场景。
下面具体说一下单链表实际的代码操作。还是没有彻底弄明白指针,可能有错误,请指出。本人后期也会根据持续的理解进行修正。
如下面代码,第一行就是定义了一个新的链表节点名为head,并且让这个head的节点等同于节点A,包括其节点值以及节点的指数域,也就是说此时head所代表的链表是和A代表的链表是一样的,但是在内存空间中head和A是不一样的,你可以删除A节点并不影响head节点和原来的列表,通常称列表中的第一个节点为头节点。head->val表示的是该节点所存储的数值,head->next表示的是该节点指针域的值,也就是图中C节点的指针。
ListNode* head = A;
head->val;
head->next;
上文中说到的节点A,这个A就是指向该节点的指针。
一般一个链表会用头节点的指针来表示,如下图 ,Head表示的就是该链表。
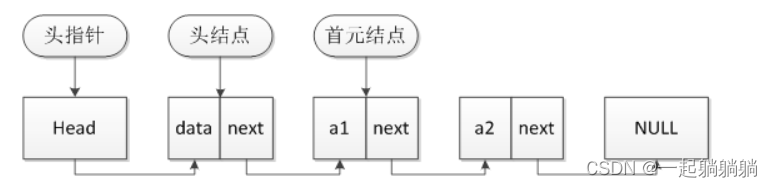
删除单链表节点:
ListNode* temp = D; //释放D节点空间
D = D->next;
delete temp;
结合图1,上面代码就是将节点D删除,并且释放节点空间。在定义上C->next = D,并且都是指针,D改变C->next随之改变,所以进行D = D->next操作后,C->next=D->next,直接C指向E,并且delete temp,也就是删除掉了D。如果不进行D节点的删除,可以直接进行C->next=D->next操作。代码如下:
C->next=D->next //不释放需要删除节点D的空间