【paper】 Canonical Tensor Decomposition for Knowledge Base Completion
【简介】 这篇是 Facebook 法国巴黎 AI 研究中心发表在 ICML 2018 上的文章,是对传统的张量分解方法 CP(Canonical Tensor Decomposition)做的分析改进。对传统的几个双线性方法进行了详细的分析,探究了(1)最优参数与 loss 形式的影响,(2)正则化形式的影响,提出张量核 p 范数正则化方法,(3)并探究了反向关系推理的效果。
正则化那块应该是本文提出的新方法(没看懂),此外没有提出太多新的东西,更多是对老方法的探究。三项工作得出的三方面结论为:
(1)CP 和 ComplEx 模型的表现依赖于最优参数的设置;
(2)建模反向属性时效果有提升;
(3)提出的张量核正则化方法是有效的。
知识库的张量分解模型(之前的)
CP(1927)
最初的 CP 将张量表示为 R 秩一张量的和:

DistMult
DistMult 将张量 X 表示为一秩张量的和:

ComplEx

训练
给定训练三元组 (i,j,k)(i,j,k) 和预测张量 X,多类别的 log-loss 为:

CP 的正则项:

核 p-范数正则化(Nuclear p-Norm Regularization)
section 4 介绍的应该是一种新的正则化方法,全是公式,没看(懂),过吧orz
新的 CP 训练目标(对于一个三元组样本):

实验
链接预测

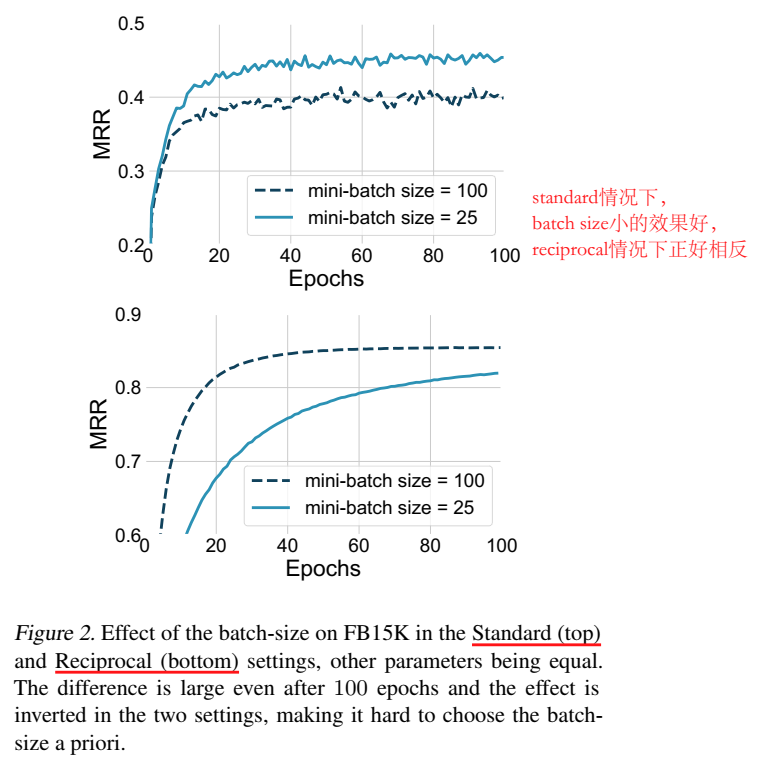
超参设置的影响
【code】 GitHub - facebookresearch/kbc: Tools for state of the art Knowledge Base Completion.
双线性模型(五)(CP、ANALOGY、SimplE) - 胡萝不青菜 - 博客园

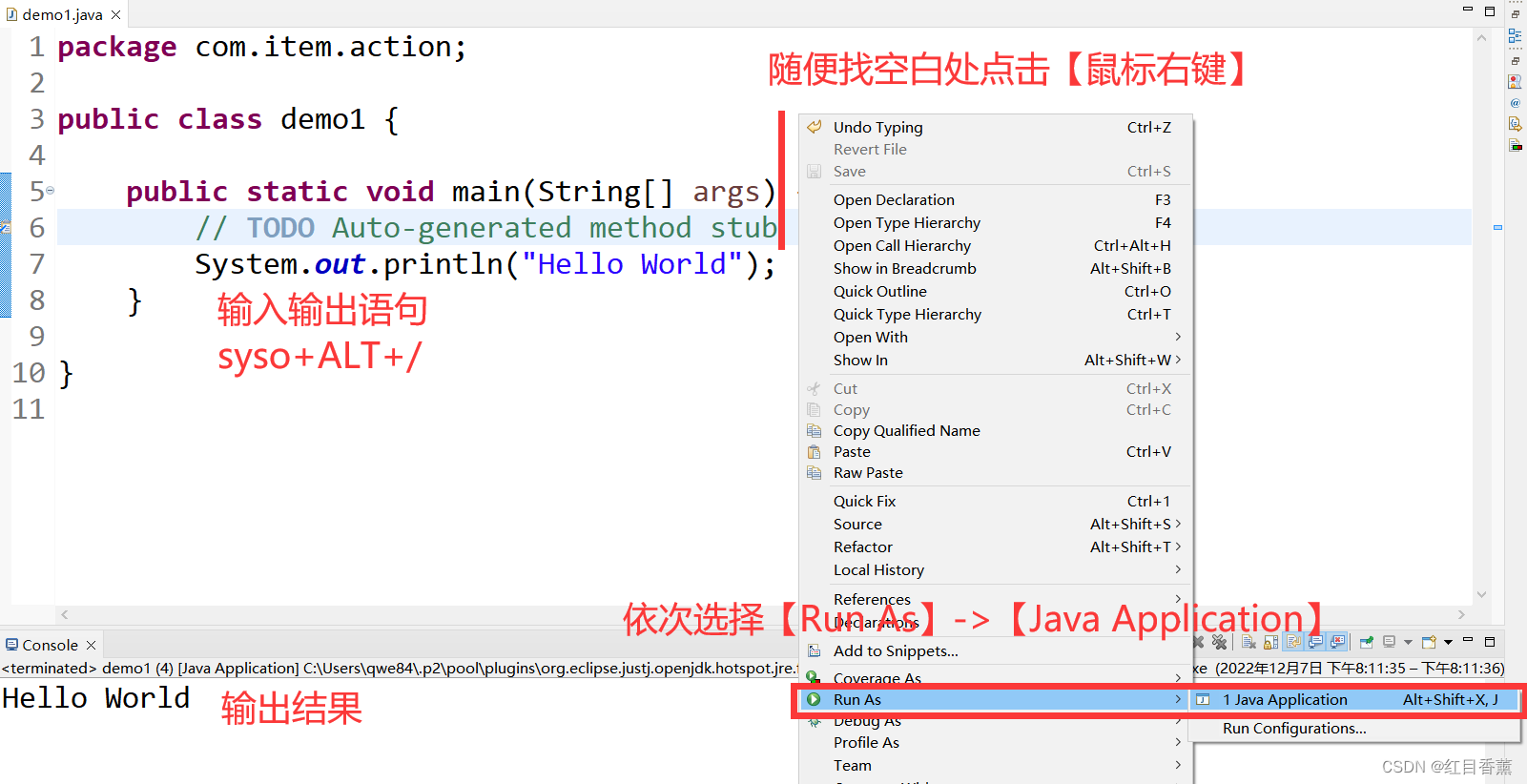
![[附源码]计算机毕业设计JAVA整形美容咨询网站](https://img-blog.csdnimg.cn/4d519d5a7d0c461c97898bde9e26a54b.png)