GBK编码和UTF-8编码是两种不同的字符编码方式;
1、主要区别如下:
(1)字符集范围不同:GBK编码支持中文字符和日韩字符,而UTF-8编码支持全球范围内的字符;
(2)编码方式不同:GBK编码采用双字节编码,每个字符占用2个字节,而UTF-8编码采用变长编码,一个字符的编码长度可为1-4个字节;
(3)兼容性不同:GBK编码在国内应用广泛,但在国际化应用上受到限制,而UTF-8编码具有更好的国际化兼容性;
(4)存储空间大小不同:由于GBK编码每个字符占用2个字节,因此在存储中占用的空间相对较大,而UTF-8编码采用变长编码,可以根据字符的实际长度来分配存储空间,因此在存储中占用的空间相对较小;
总之,GBK编码适用于中文和日韩语言环境,UTF-8编码适用于全球范围内的字符。
2、具体的转码示例:
(1)utf8编码转为gbk编码
std::string utf8ToGbk(const char *pszSrc)
{
if (nullptr == pszSrc)
return "";
//Windows API 函数,用于将多字节字符集(如 ASCII)转换为宽字符集(如 Unicode)
int nLen = MultiByteToWideChar(CP_UTF8, 0, pszSrc, -1, NULL, 0);
wchar_t* pwszGBK = new wchar_t[nLen + 1];
memset(pwszGBK, 0, nLen * 2 + 2);
MultiByteToWideChar(CP_UTF8, 0, pszSrc, -1, pwszGBK, nLen);
nLen = WideCharToMultiByte(CP_ACP, 0, pwszGBK, -1, NULL, 0, NULL, NULL);
char* pszGBK = new char[nLen + 1];
memset(pszGBK, 0, nLen + 1);
WideCharToMultiByte(CP_ACP, 0, pwszGBK, -1, pszGBK, nLen, NULL, NULL);
string strTemp(pszGBK);
delete[] pwszGBK;
pwszGBK = nullptr;
delete[] pszGBK;
pszGBK = nullptr;
return strTemp;
}
(2)gbk编码转为utf8编码
std::string gbk2Utf8(std::string& strData)
{
int nLen = MultiByteToWideChar(CP_ACP, 0, strData.c_str(), -1, NULL, 0);
WCHAR *pWStr1 = new WCHAR[nLen];
MultiByteToWideChar(CP_ACP, 0, strData.c_str(), -1, pWStr1, nLen);
nLen = WideCharToMultiByte(CP_UTF8, 0, pWStr1, -1, NULL, 0, NULL, NULL);
char *pStr2 = new char[nLen];
WideCharToMultiByte(CP_UTF8, 0, pWStr1, -1, pStr2, nLen, NULL, NULL);
string strOutUtf8 = pStr2;
delete[] pWStr1;
pWStr1 = NULL;
delete[] pStr2;
pStr2 = NULL;
return strOutUtf8;
}
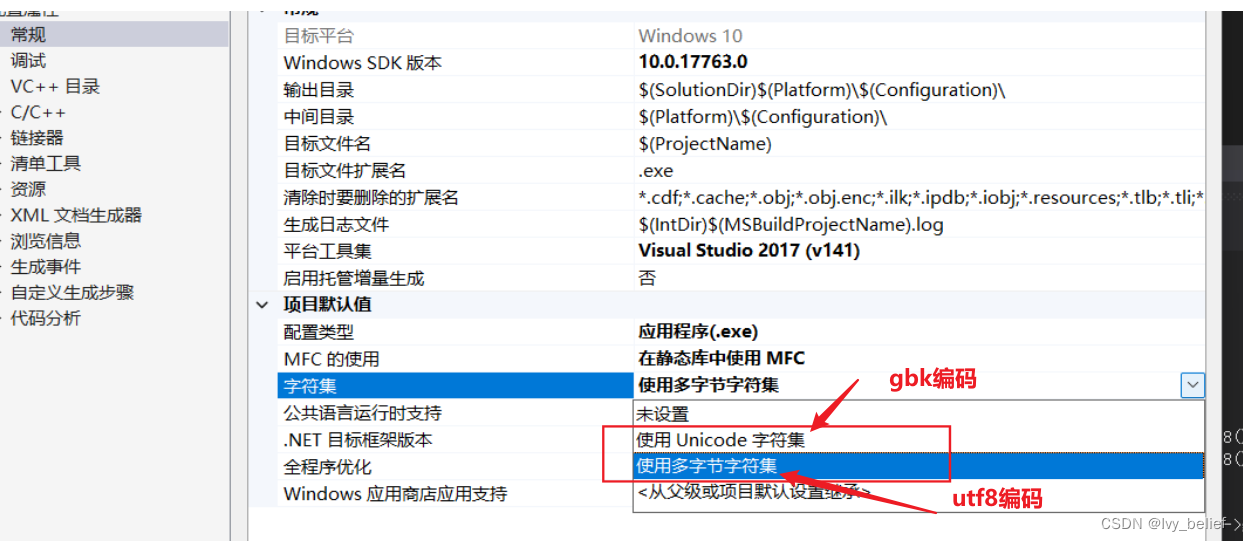
3、编码时也可以在VS上进行选择