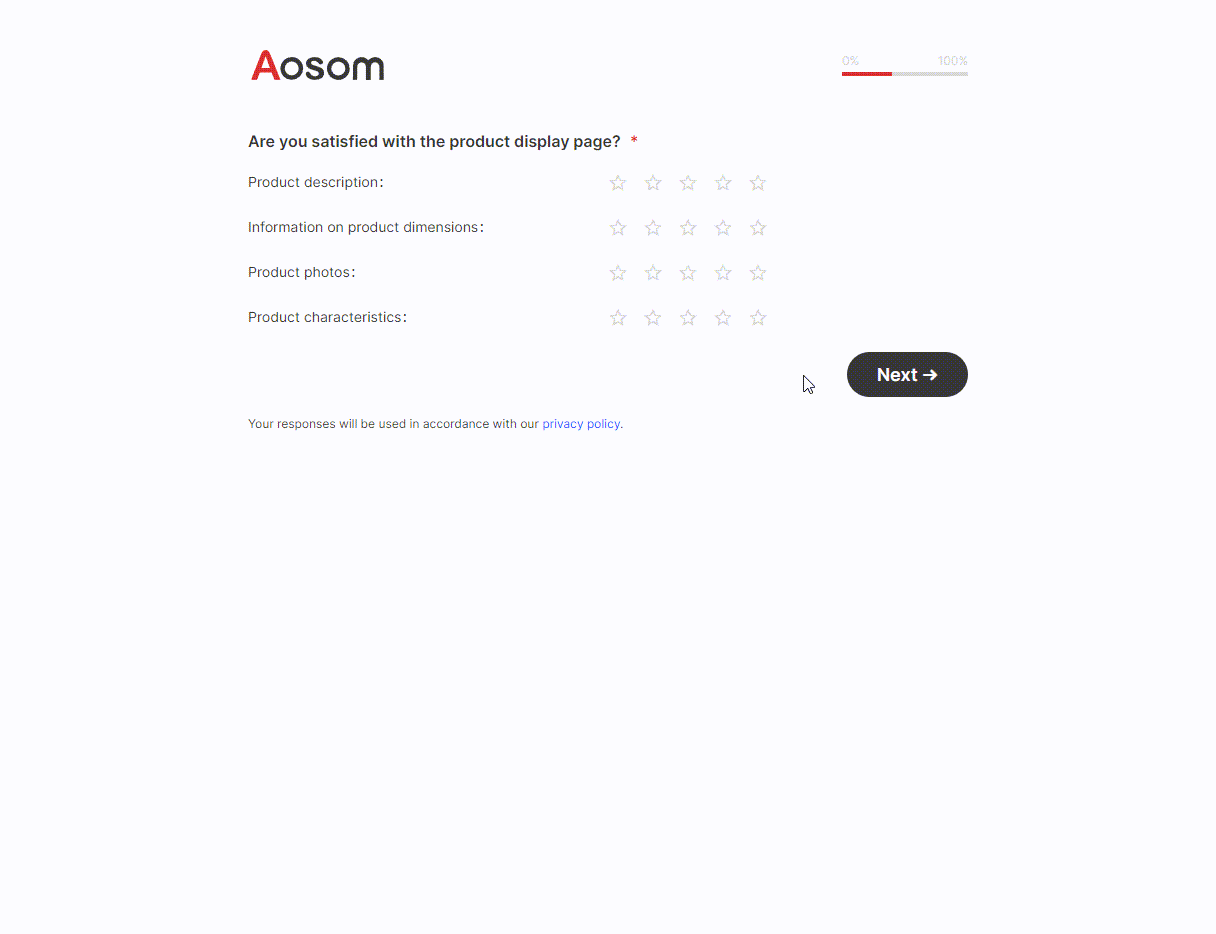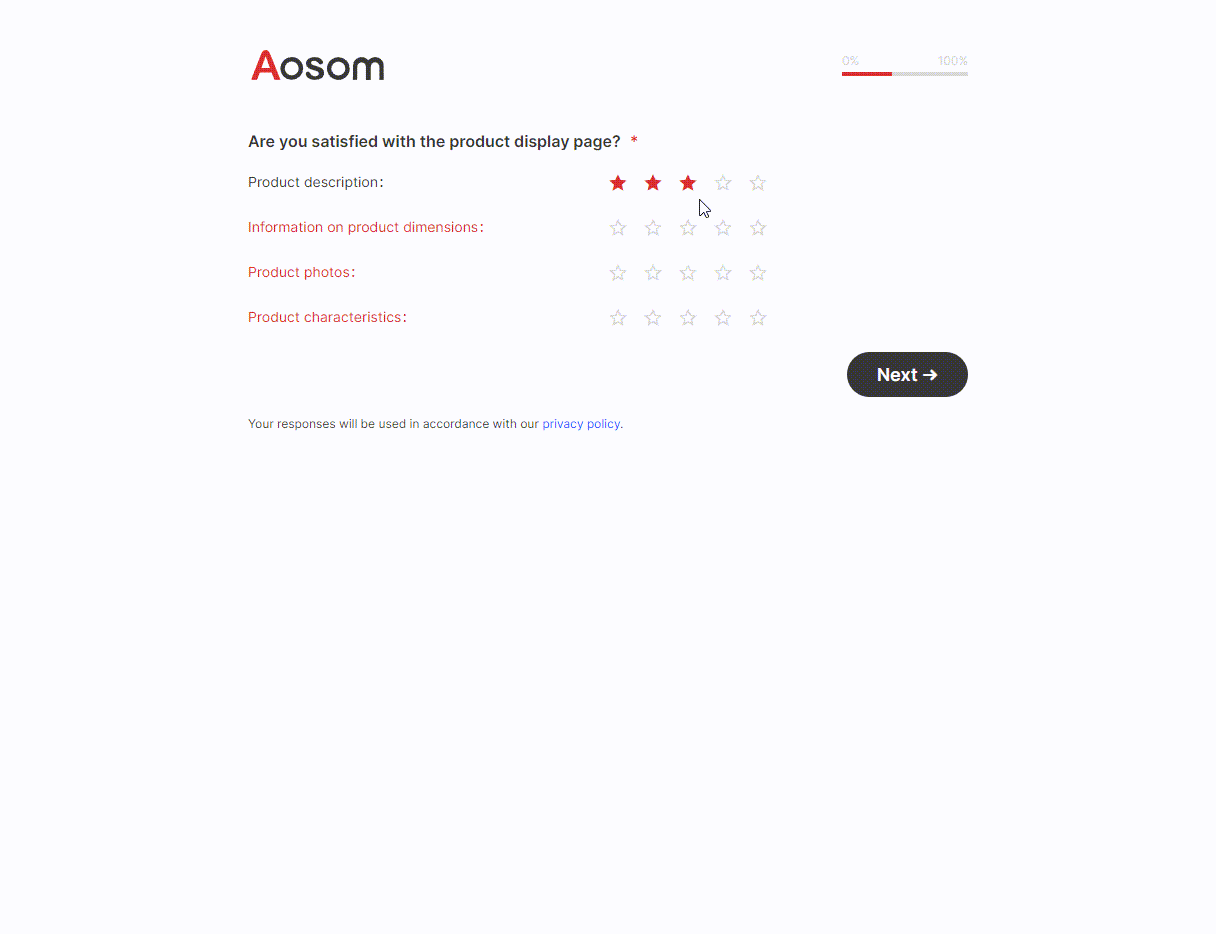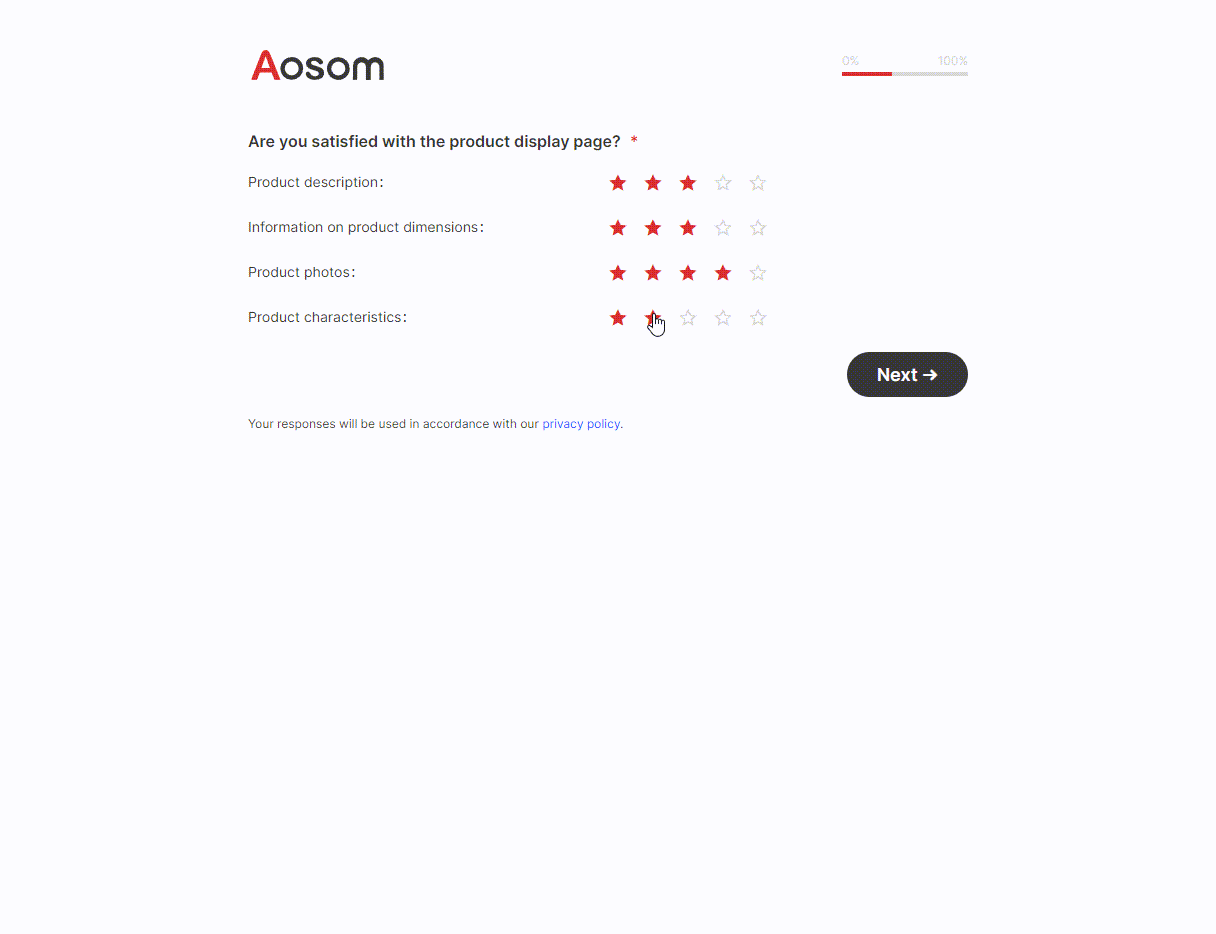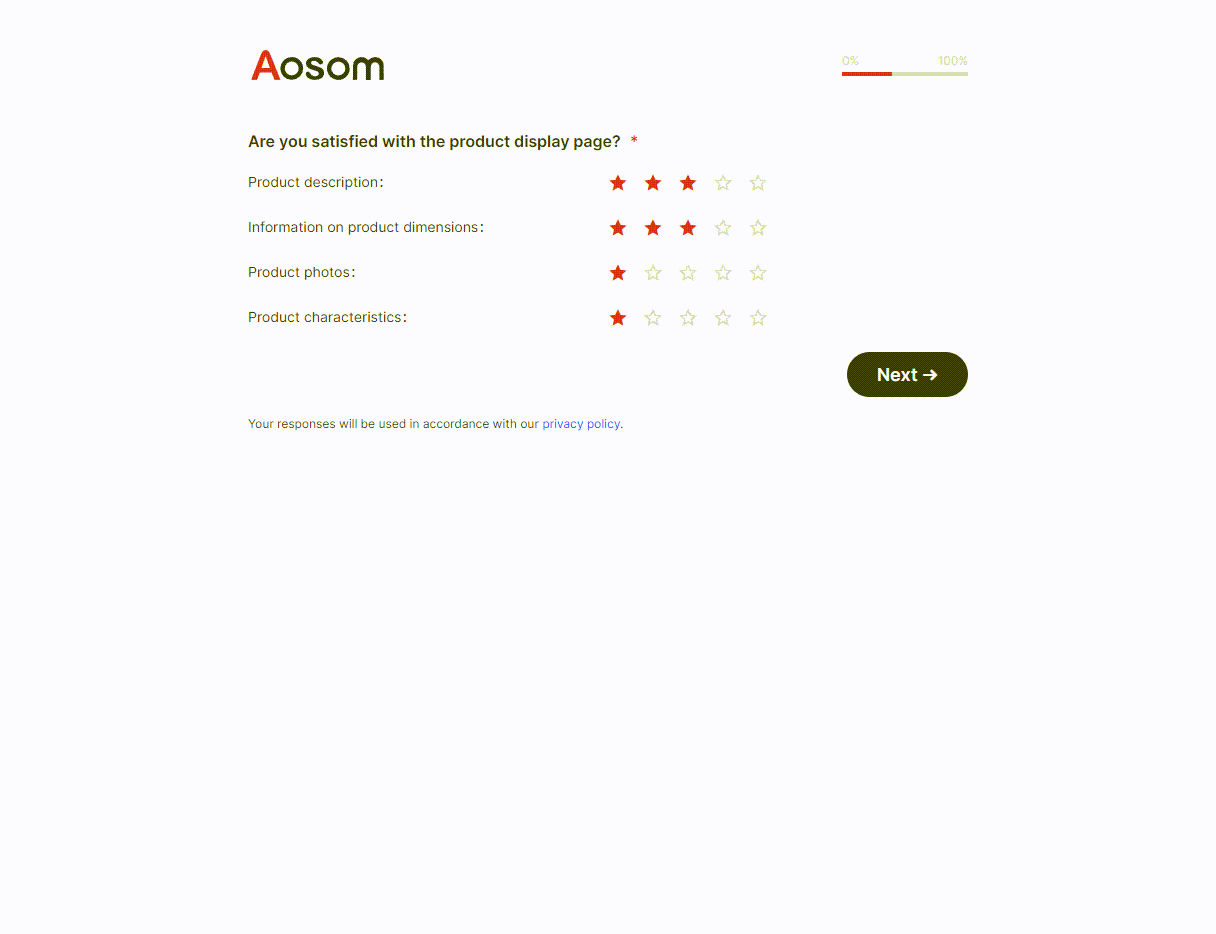
摘要
不断提高程序的运行效率,而又不影响程序功能是程序员的不竭追求。本项目旨在利用并行技术进一步提高程序的效率。
程序设计中,主要实现了百万级数据的求和、求最大值以及排序功能。其中,排序功能使用快速排序算法和归并算法实现。共采用3项加速手段:其一,多线程。综合考虑运算量与线程开销,在求和及求最大值的过程中,分别创建了32个线程,而在排序过程中,创建了64个线程,归并过程中创建了2个线程。其二,AVX指令集。使用AVX指令集对程序进行改写。其三,TCP通信。使用TCP协议进行网络通信,将全部数据分开在两台计算机上进行运算。
架构设计
在本项目中,多机加速程序的架构设计如下:
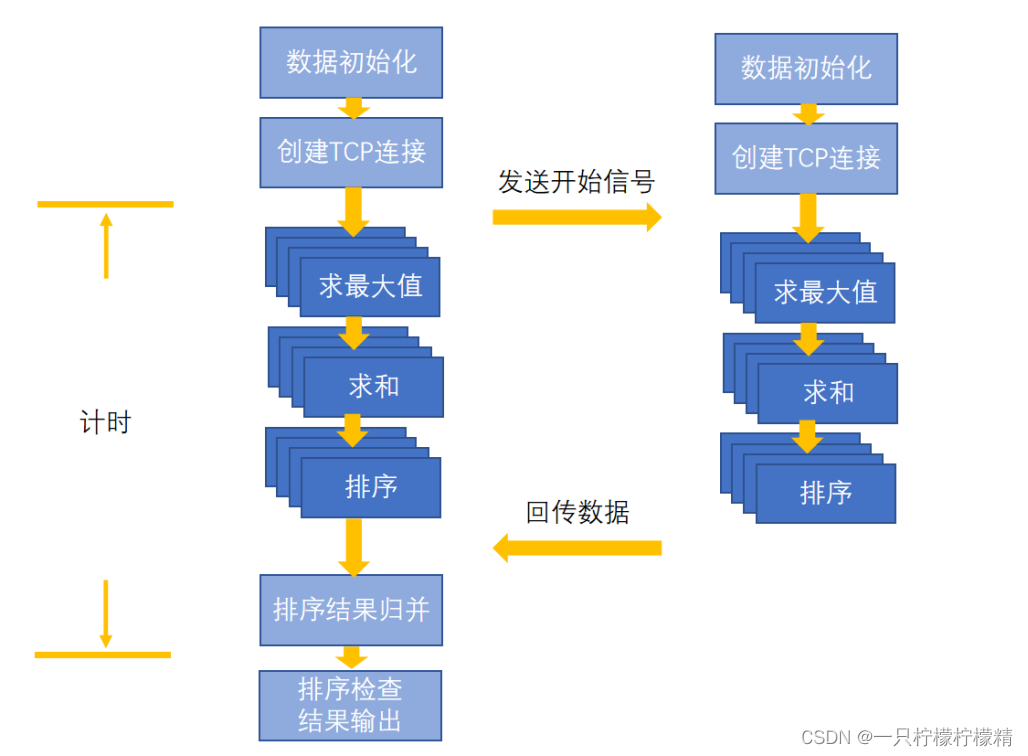
如图1.1所示,本项目的整体架构可分为准备、计算和处理三个部分。
在准备阶段,两台计算机各自初始化640万个单精度浮点数,并分别对socket进行初始化。然后,由客户端向服务器发起请求,服务器接受客户端请求后,分配新的socket套接字,完成连接并等待通信。
在计算阶段,两台计算机分别顺序调用了sumSpeedUp,maxSpeedUp和sortSpeedUp三个函数。其中,sumSpeedUp和maxSpeedUp中分别创建了32个线程用于求和以及求最大值,且未使用其他算法。sortSpeedUp函数则创建了64个线程对全部数据分块进行快速排序,然后再使用归并算法将分块有序的数据排列成整体有序的结果,归并过程共创建2个线程。此外,除排序算法外,计算阶段的所有代码均使用AVX指令集加速。
在结束处理阶段,服务器将计算结果传回客户端。此时,根据两台计算机各自的计算结果,完成最终的求和、求最大值,并再次调用归并函数将两个排序结果进行归并。然后,检查排序结果,输出排序结果是否正确,求和结果以及数据最大值。
详细设计
宏定义及全局变量说明
宏定义如下:
#define MAX_THREADS 64
#define SUBDATANUM 100000
//数据总量
#define DATANUM (SUBDATANUM * MAX_THREADS)
定义三个功能函数各自的线程数,以及每个线程需要处理的数据量:
//sum & max
#define THREADS_NUM 32
#define THREADS_DATANUM SUBDATANUM * 2
//sort
#define THREADS_NUM_SORT 64
#define THREADS_DATANUM_SORT SUBDATANUM
//join
#define JOIN_NUM 2
其他多线程相关量定义如下:
//信号量
HANDLE hSemaphores[THREADS_NUM];
HANDLE hSemaphores_sort[THREADS_NUM_SORT];
HANDLE hSemaphores_join[JOIN_NUM];
//线程ID max & sum
Int ThreadID[THREADS_NUM];
int ThreadID_join[THREADS_NUM];
定义其他全局变量,其中yfsData_max是为了避免在函数内部定义大数组。
//待测试数据
float rawFloatData[DATANUM];
//线程的中间结果 sum & max
float floatResults[THREADS_NUM], floatMaxs[THREADS_NUM];
//线程排序结果
float floatSorts[DATANUM];
//归并辅助
float joinSorts[DATANUM];
//求最大值
__m256 yfsData_max[THREADS_NUM][THREADS_DATANUM/8];
sumSpeedUp函数详述
首先创建32个线程,然后逐个开启。线程函数的核心代码如下:
DWORD WINAPI ThreadProc_sum(LPVOID lpParameter) {
......
float a = 4.0;
__m256 Denominator = _mm256_set1_ps(a);
// AVX批量处理
for (size_t i = 0; i < cntBlock; ++i) {
yfsLoad = _mm256_load_ps(p);
yfsMid =_mm256_log_ps(_mm256_sqrt_ps(_mm256_div_ps(yfsLoad,Denominator)));
yfsSum = _mm256_add_ps(yfsSum, yfsMid);
p += nBlockWidth;
}
......
return 0;
}
其中,变量yfsMid用于完成对原始数据的除法、开方和取对数操作,而变量yfsSum中存储着最终计算结果。32个线程均运行结束后,得到一个存储着32个浮点数的数组,对这32个中间结果求和时,同样使用了AVX指令集加速,该段代码与线程函数中的代码相似。最后关闭线程,函数结束。
maxSpeedUp函数详述
首先创建32个线程,然后逐个开启。线程函数的核心代码如下:
DWORD WINAPI ThreadProc_max(LPVOID lpParameter) {
......
// 数据处理
__m256 yfsData[cntBlock]; // 转换后的数组
......
for (size_t i = 0; i < cntBlock; ++i) {
yfsLoad = _mm256_load_ps(pp);
yfsData[i] = _mm256_log_ps(_mm256_sqrt_ps(_mm256_div_ps(yfsLoad,Denominator)));
pp += nBlockWidth;
}
// 求最大值
__m256 maxVal = yfsData[0];
for (size_t i = 1; i < cntBlock; ++i) {
maxVal = _mm256_max_ps(maxVal, yfsData[i]);
}
......
return 0;
}
首先对原始数据进行除法、开方和取对数处理,将处理结果存入yfsData数组中,该数组的每个变量类型均为__m256。然后使用_mm256_max_ps对处理后的数组进行for循环求最大值,结果存入变量maxVal中。最后对maxVal中的8个浮点数进行比较,得到一道线程的最大值求解结果。
32个线程均运行结束后,得到一个存储着32个浮点数的数组,对这32个中间结果求最大值时,同样使用了AVX指令集加速,该段代码与线程函数中的代码相似。最后关闭线程,函数结束。
sortSpeedUp函数详述
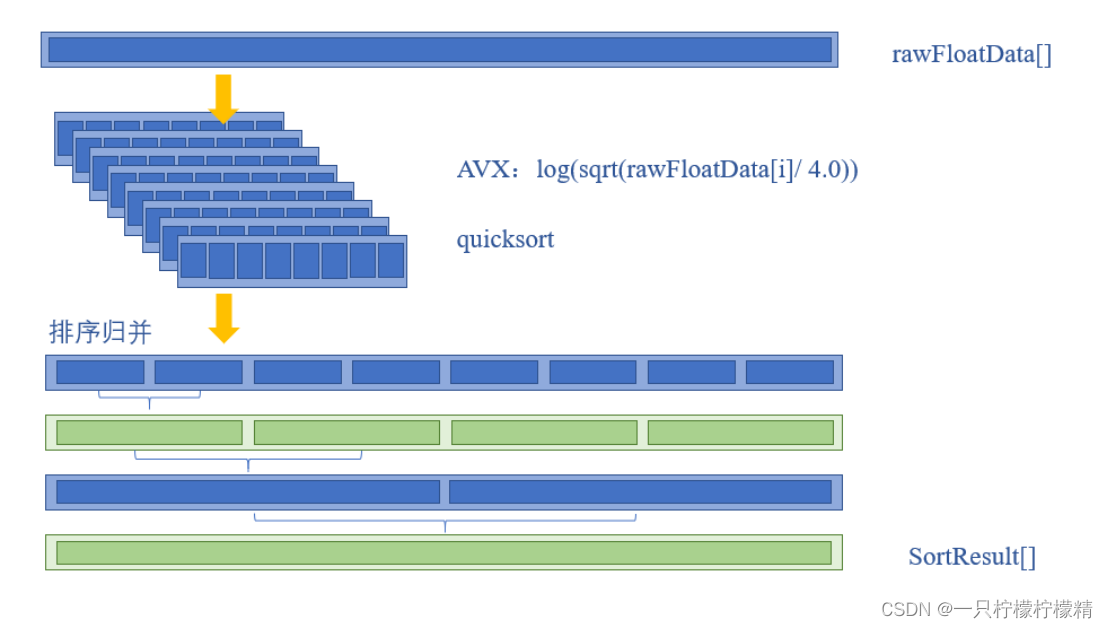
首先创建64个线程,然后逐个开启。排序的线程函数与求最大值的线程函数一样,需要先对数据进行处理,然后再调用快速排序函数。特别地,每个线程的排序结果都放到同一个数组floatSorts中。也就是说,当所有线程运行结束时,所有的数据都放在同一个数组中,且该数组分块有序。
64个线程均运行结束后,调用归并函数对分块有序的数据进行最终的归并排序。归并时,采用两两归并的方式,通过6次归并将64个分块有序的数据归为一块,完成排序的全部内容。共创建2个线程,每个线程完成一半数据的归并,然后再进行最终的归并。归并控制核心代码如下:
int who = *(int*)lpParameter;
float* pin1; //被合并数组
float* pin2; //合并后数组
int num = 32;
bool flag = 0;
int length; //被合并数组长度
for (size_t j = 1; j < 32; j = j * 2) {
if (flag == 0) {
pin1 = floatSorts + who * DATANUM / 2;
pin2 = joinSorts + who * DATANUM / 2;
}
else {
pin1 = joinSorts + who * DATANUM / 2;
pin2 = floatSorts + who * DATANUM / 2;
}
length = SUBDATANUM * j;
for (size_t i = 0; i < num; i = i + 2) {
joinsort((pin1 + i * length), (pin1 + (i + 1) * length), pin2 + i * length, length);
}
num = num / 2;
flag = !flag;
}
如上述代码所示,由于每次归并结束后,结果都会存入另一个数组(例如,64个线程结束后,数组floatSorts以10万数据为一块分块有序。而第一次归并结束,归并结果存入joinSorts数组中,数组joinSorts以20万数据为一块分块有序),因此通过变量flag控制floatSorts和joinSorts轮流作为被归并数组,且归并结果存入另一个数组。由于总归并次数刚好为偶数,故最终结果刚好存在floatSorts数组中,符合要求。
综上,在sortSpeedUp函数中对数据的操作流程如图所示。
排序及归并算法
下面将简要介绍程序中采用的快速排序算法以及分块有序数组的归并算法。
(1)快速排序算法
由于在排序过程中,需要对数据单个进行访问,无法使用AVX指令集加速,因此只能通过在算法层面上进行改进来提高计算速度。如果采用较为基础的冒泡排序等算法,其计算时间会显著变长,因此我们选择了快速排序算法,相对于冒泡排序的时间复杂度,快速排序算法平均时间复杂度只有,其时间消耗在大数据量时变得尤为重要。
快速排序算法采用了分治的主要思想,通过基准数将数组不断的划分为不同范围的两部分,通过不断重复划分过程最终得到整个有序的数组。
在双机加速时,我们虽然无法使用AVX指令集进行加速,快速排序分而治之的思想与多线程十分契合,我们将数组首先分为N个部分,由N个线程将其进行排序得到N个有序的数组,再通过归并得到整个有序的数组。
(2)归并
在得到N个有序数组后,我们需要将他们合并成一个有序的数组。我们采用了两两归并的方式,从两个数组的最小值开始比较,指针不断后移,每次选择两个数据中较小的放入结果数组中,直到其中一个数组为空,将剩下的一个数组直接移到尾部完成一次归并。
两两归并的方式可以十分方便的应用于多线程中,但出于线程带来的额外时间开销的考虑,我们在此仅采用了两个线程进行归并,在将来更复杂数据的归并中,可以尝试使用更多的线程以提高加速比。
TCP 通信
在双机协作版的程序中,由于通信规模较小且对通信可靠性有一定要求,因此我们选用了TCP 作为两台计算机之间传输数据的方式。考虑到传输的数据量较大,且网络传输中一帧的数据量约为1500字节,发送和接受缓冲区的大小也有一定的限制,因此我们试图将大量的数据拆成小包发送,以期能够减少丢包和溢出,提高发送速率。基于以上想法我们提出了一下四种传输方式,并一一进行了实验。
1.发送方整包发送,接收方整包接收;
2.发送方整包发送,接收方循环接收直至接收完全部数据;
3.发送方分包发送,接收方每次指定长度接收,直至收完为止;
4.发送方分包发送,接收方每次整包接收,直至收完为止。
其中发送和接收的核心代码如下所示,通过修改SENDONCE 和RECEIVEONCE的值,可以实现上述四种方式的发送和接收。
发送方:
for (int i = 0; i < DATANUM / SENDONCE; i++)
{
sended=send(newConnection, (char*)&rawFloatData[i*SENDONCE], SENDONCE * sizeof(float), NULL);
//printf("%d:sended:%d\n",i,sended);
}
recv(newConnection, (char*)&count, sizeof(count), NULL);
接收方:
while(1){
QueryPerformanceCounter(&time_start);//计时开始
receivesuccess = recv(Connection, &p[received], RECEIVEONCE * sizeof(float), NULL);
//printf("第%d次接收:接收数据量:%d\n", i, receivesuccess);
i = i + 1;
if (receivesuccess == -1)//打印错误
{
int erron=WSAGetLastError();
printf("erron=%d\n", erron);
}
else (receivesuccess != -1)
{
received = received + receivesuccess;
}
if (received >= DATANUM*4)
{
QueryPerformanceCounter(&time_over); //计时结束
run_time = 1000000 * (time_over.QuadPart - time_start.QuadPart) / dqFreq;
printf("\nrun_time:%fus\n", run_time);
break;
}
}
printf("receive end);
通过对上述四种方式进行测试,我们发现,TCP传输的效果并不好,虽然能够保证数据传输正确,但其平均传输耗时约为13s,且无论上述四种哪种方式,总传输耗时相差不多。当发送方整包发送的时候,发送方能够较快的执行完send函数(如下图所示),但接收方在发送方发送完成后,仍旧需要较长的时间接收,且无论接收方采用何种接收方式,均无法进一步改善传输时间。当接收方采用较大长度接收时,执行单个recv函数耗时较长,但若减小接收长度则执行次数较多,对于改善传输时间,均没有明显作用。且在实验过程中发现,若采用自主分包的方式,容易会在两个数据包发送的交界处带来数据传输错误。


通过查阅相关资料,我们发现send与recv函数实际并不执行具体的发送任务,而只是实现与发送和接收缓冲区的交互,具体的数据发送实际是由TCP协议完成。即意味着,send函数返回时,已经将全部数据送入待发送的数据缓冲区,而此时数据开始向接收缓冲区流动,但由于网络传输中可能存在的某些原因,导致数据在进入接收缓冲区的速度较慢,recv函数每次读取时,缓冲区内的数据没有达到预设的接收长度,因此发生了阻塞。
不仅如此,通过查阅上述资料我们发现,recv函数只是负责从数据缓冲区中拷贝数据,即意为这,recv接收方并不知道发送方的发送方式,无论是s一次end全部数据还是分次放入发送缓冲区,均不影响recv的接收。
关于由于丢包导致大量数据重传进而影响传输速率的猜测,我们试图通过调整单次发送数据的长度和接收数据的长度,以期能够使发送和接收速率相似,进而减少数据重传,但经过试验发现并没有达到预期的效果。
因此,最终我们选择了最为简单方便的方式,即send一次性整包发送,recv一次整包接收,由TCP底层协议对其进行拆包操作。
测试结果及评价
下面对单机版程序、单机加速版程序和双机加速版程序进行测试,测试流程为执行5次任务,并求时间的平均值。
单机版程序测试
1、计算机1测试结果
| 测试次数 | 运行时间 |
|---|---|
| 1 | 7076944.900000us |
| 2 | 7416633.700000us |
| 3 | 8647607.400000us |
| 4 | 6606958.000000us |
| 5 | 8503165.200000us |
平均时间:t1=7650261.84us,数据和:6.17993*107,最大值:5.19648,排序结果正确。
2、计算机2测试结果
| 测试次数 | 运行时间 |
|---|---|
| 1 | 8404677.000000us |
| 2 | 9434140.900000us |
| 3 | 9416527.800000us |
| 4 | 9642741.900000us |
| 5 | 9403498.000000us |
平均时间:t1=9260317us,数据和:6.17993*107,最大值:5.19648,排序结果正确。
加速版程序单机测试
本节中对加速版程序进行单机测试,数据量为双机测试时的两倍,也即与单机版程序测试数据量相同。
1、计算机1测试结果
| 测试次数 | 运行时间 |
|---|---|
| 1 | 412523.900000us |
| 2 | 404471.100000us |
| 3 | 421559.100000us |
| 4 | 404154.000000us |
| 5 | 431603.000000us |
平均时间:t1=414862.22us,数据和:6.17993*107,最大值:5.19648,排序结果正确。
与单机相比,加速比约为18.44。
2、计算机2测试结果
| 测试次数 | 运行时间 |
|---|---|
| 1 | 688923.300000us |
| 2 | 562931.800000us |
| 3 | 568764.300000us |
| 4 | 585099.000000us |
| 5 | 578702.500000us |
平均时间:t1=596884.2us,数据和:6.17993*107,最大值:5.19648,排序结果正确。
与单机相比,加速比约为15.52。
双机版程序测试
双机测试结果如下。其中,接收方运行时间即全部数据的计算时间,发送方运行时间为发送方数据运算与发送数据时间之和。
| 测试次数 | 接收方运行时间 | 发送方运行时间 |
|---|---|---|
| 1 | 12893272.700000us | 205192.100000us |
| 2 | 13647811.700000us | 233872.800000us |
| 3 | 13608242.500000us | 229874.700000us |
| 4 | 13982430.600000us | 254460.700000us |
| 5 | 13314847.300000us | 252905.000000us |
平均时间:t1=13489320.96us,数据和:6.17993*107,最大值:5.19648,排序结果正确。
根据4.3.1中的单机测试结果,求得两台计算机的单机计算平均时间为:8455289.42us,故双机加速比为:0.6268。