在我的文章 “Elastic:开发者上手指南” 的 “NLP - 自然语言处理及矢量搜索”,我对 Elastic Stack 所提供的矢量搜索有大量的描述。其中很多的方法需要使用到 huggingface.co 及 Elastic 的机器学习。这个对于许多的开发者来说,意味着付费使用。在那些方案里,带有机器学习的 inference processor 是收费的。还有那个上传的 eland 也是收费的。
在今天的文章中,我们来介绍另外一种方法来进行矢量搜素。我们绕过使用 eland 来进行上传模型。取而代之的是使用 Python 应用来上传我们已经生成好的 dense_vector 字段值。 我们将首先使用数据摄取脚本将数据摄取到 Elasticsearch 中。 该脚本将使用本地托管的 Elasticsearch 和 SentenceTransformer 库连接到 Elasticsearch 并执行文本嵌入。
在下面的展示中,我使用最新的 Elastic Stack 8.8.1 来进行展示,尽管它适用于其他版本的 Elastic Stack 8.x 版本。
ingest.py
from elasticsearch import Elasticsearch
from sentence_transformers import SentenceTransformer
USERNAME = "elastic"
PASSWORD = "z5nxTriCD4fi7jSS=GFM"
ELATICSEARCH_ENDPOINT = "https://localhost:9200"
CERT_FINGERPRINT = "783663875df7ae1daf3541ab293d8cd48c068b3dbc2d9dd6fa8a668289986ac2"
# Connect to Elasticsearch
es = Elasticsearch(ELATICSEARCH_ENDPOINT,
ssl_assert_fingerprint = (CERT_FINGERPRINT),
basic_auth=(USERNAME, PASSWORD),
verify_certs = False)
resp = es.info()
print(resp)
# Index name
index_name = "test1"
# Example data
data = [
{"id": 1, "text": "The sun slowly set behind the mountains, casting a golden glow across the landscape. The air was crisp and cool, a gentle breeze rustling through the leaves of the trees. Birds chirped in the distance, their melodic songs filling the air. As I walked along the winding path, I couldn't help but marvel at the beauty of nature surrounding me. The scent of wildflowers wafted through the air, intoxicating and refreshing. It was a moment of tranquility, a moment to escape from the chaos of everyday life and immerse myself in the serenity of the natural world."},
{"id": 2, "text": "The bustling city streets were filled with the sound of car horns and chatter. People hurried past, their faces lost in a sea of anonymity. Skyscrapers towered above, their reflective glass windows shimmering in the sunlight. The aroma of street food filled the air, mingling with the scent of exhaust fumes. Neon signs flashed with vibrant colors, advertising the latest products and services. It was a city that never slept, a constant whirlwind of activity and excitement. Amidst the chaos, I navigated through the crowds, searching for moments of connection and inspiration."},
{"id": 3, "text": "The waves crashed against the shore, each one a powerful force of nature. The sand beneath my feet shifted with every step, as if it was alive. Seagulls soared overhead, their calls echoing through the salty air. The ocean stretched out before me, its vastness both awe-inspiring and humbling. I closed my eyes and listened to the symphony of the sea, the rhythm of the waves lulling me into a state of tranquility. It was a place of solace, a place where the worries of the world melted away and all that remained was the beauty of the natural world."},
{"id": 4, "text": "The old bookstore was a treasure trove of knowledge and stories. Rows upon rows of bookshelves lined the walls, each one filled with books of every genre and era. The scent of aged paper and ink filled the air, creating an atmosphere of nostalgia and adventure. As I perused the shelves, my fingers lightly grazing the spines of the books, I felt a sense of wonder and curiosity. Each book held the potential to transport me to another world, to introduce me to new ideas and perspectives. It was a sanctuary for the avid reader, a place where imagination flourished and stories came to life."}
]
# Create Elasticsearch index and mapping
if not es.indices.exists(index=index_name):
es_index = {
"mappings": {
"properties": {
"text": {"type": "text"},
"embedding": {"type": "dense_vector", "dims": 768}
}
}
}
es.indices.create(index=index_name, body=es_index, ignore=[400])
# Upload documents to Elasticsearch with text embeddings
model = SentenceTransformer('quora-distilbert-multilingual')
for doc in data:
# Calculate text embeddings using the SentenceTransformer model
embedding = model.encode(doc["text"], show_progress_bar=False)
# Create document with text and embedding
document = {
"text": doc["text"],
"embedding": embedding.tolist()
}
# Index the document in Elasticsearch
es.index(index=index_name, id=doc["id"], document=document)为了运行上面的应用,我们需要安装 elasticsearch 及 sentence_transformers 包:
pip install sentence_transformers elasticsearch如果我们对上面的 Python 连接到 Elasticsearch 还比较不清楚的话,请详细阅读我之前的文章 “Elasticsearch:关于在 Python 中使用 Elasticsearch 你需要知道的一切 - 8.x”。
我们首先在数据摄取脚本中导入必要的库,包括 Elasticsearch 和 SentenceTransformer。 我们使用 Elasticsearch URL 建立与 Elasticsearch 的连接。 我们定义 index_name 变量来保存 Elasticsearch 索引的名称。
接下来,我们将示例数据定义为字典列表,其中每个字典代表一个具有 ID 和文本的文档。 这些文档模拟了我们想要搜索的数据。 你可以根据您的特定数据源和元数据提取要求自定义脚本。
我们检查 Elasticsearch 索引是否存在,如果不存在,则使用适当的映射创建它。 该映射定义了我们文档的字段类型,包括作为文本的文本字段和作为维度为 768 的密集向量的嵌入(embedding)字段。
我们使用 quora-distilbert-multilingual 预训练文本嵌入模型来初始化 SentenceTransformer 模型。 该模型可以将文本编码为长度为 768 的密集向量。
对于示例数据中的每个文档,我们使用 model.encode() 函数计算文本嵌入并将其存储在嵌入变量中。 我们使用文本和嵌入字段创建一个文档字典。 最后,我们使用 es.index() 函数在 Elasticsearch 中索引文档。
现在我们已经将数据提取到 Elasticsearch 中,让我们继续使用 FastAPI 创建搜索 API。
main.py
from fastapi import FastAPI
from elasticsearch import Elasticsearch
from sentence_transformers import SentenceTransformer
USERNAME = "elastic"
PASSWORD = "z5nxTriCD4fi7jSS=GFM"
ELATICSEARCH_ENDPOINT = "https://localhost:9200"
CERT_FINGERPRINT = "783663875df7ae1daf3541ab293d8cd48c068b3dbc2d9dd6fa8a668289986ac2"
# Connect to Elasticsearch
es = Elasticsearch(ELATICSEARCH_ENDPOINT,
ssl_assert_fingerprint = (CERT_FINGERPRINT),
basic_auth=(USERNAME, PASSWORD),
verify_certs = False)
app = FastAPI()
@app.get("/search/")
async def search(query: str):
print("query string is: ", query)
model = SentenceTransformer('quora-distilbert-multilingual')
embedding = model.encode(query, show_progress_bar=False)
# Build the Elasticsearch script query
script_query = {
"script_score": {
"query": {"match_all": {}},
"script": {
"source": "cosineSimilarity(params.query_vector, 'embedding') + 1.0",
"params": {"query_vector": embedding.tolist()}
}
}
}
# Execute the search query
search_results = es.search(index="test1", body={"query": script_query})
# Process and return the search results
results = search_results["hits"]["hits"]
return {"results": results}
@app.get("/")
async def root():
return {"message": "Hello World"}要运行 FastAPI 应用程序,请将代码保存在文件中(例如 main.py)并在终端中执行以下命令:
uvicorn main:app --reload$ pwd
/Users/liuxg/python/fastapi_vector
$ uvicorn main:app --reload
INFO: Will watch for changes in these directories: ['/Users/liuxg/python/fastapi_vector']
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
INFO: Started reloader process [95339] using WatchFiles
/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/elasticsearch/_sync/client/__init__.py:395: SecurityWarning: Connecting to 'https://localhost:9200' using TLS with verify_certs=False is insecure
_transport = transport_class(
INFO: Started server process [95341]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: 127.0.0.1:59811 - "GET / HTTP/1.1" 200 OK这将启动 FastAPI 开发服务器。 然后,您可以访问 http://localhost:8000/search/ 的搜索端点并提供查询参数来执行搜索。 结果将作为 JSON 响应返回。
确保根据你的要求自定义代码,例如添加错误处理、身份验证和修改响应结构。我们做如下的搜索:
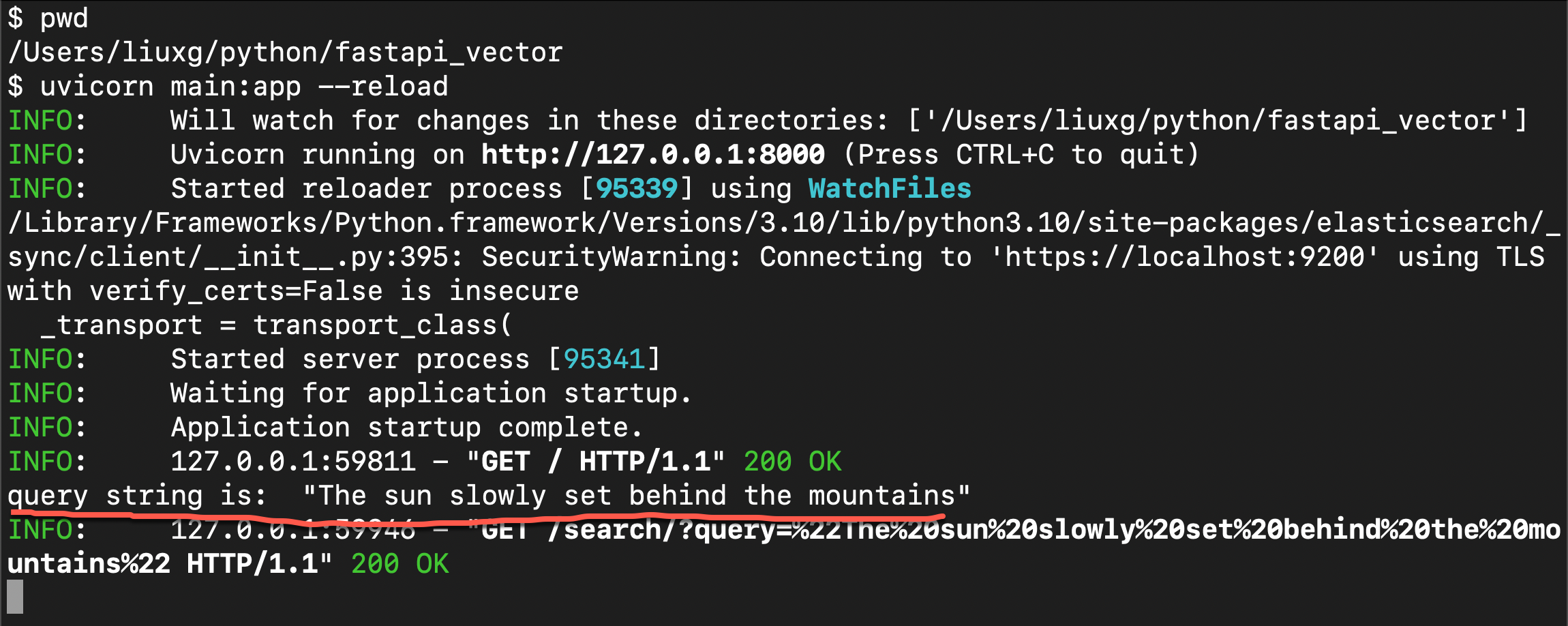
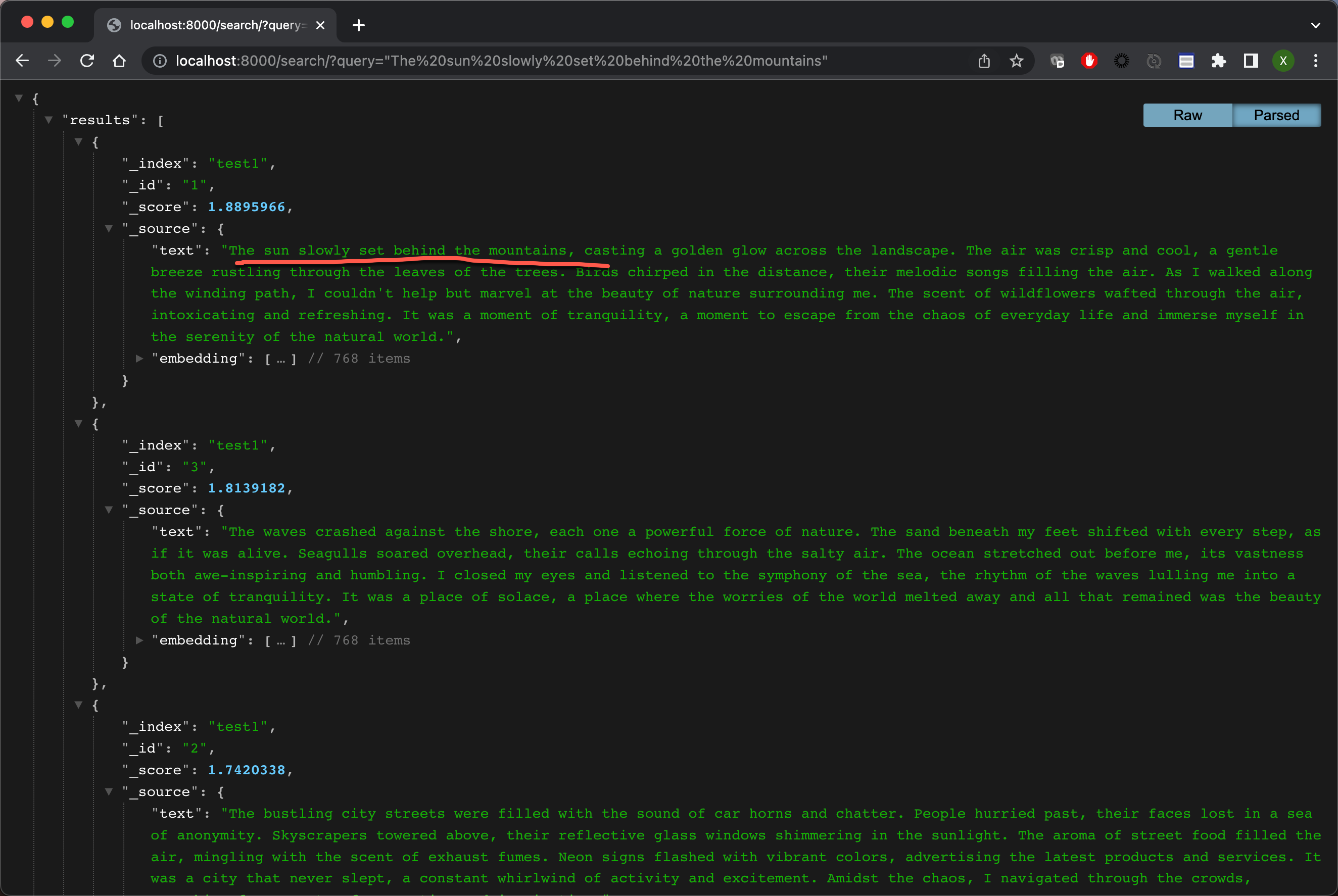
很显然,当我们搜索语句 “The sun slowly set behind the mountains” 的时候,第一个文档是最相近的。其它的文档没有那么相近,但是他们也会作为候选结果返回给用户。










![看看螯合物前体多肽试剂DOTA-E[c(RGDfK)2]的全面解析吧!](https://img-blog.csdnimg.cn/img_convert/1a645a0ad632d629afb72e435adc3646.jpeg)