一、需求;
需求:实现xxx地固定资产的计算以及梳理
1.盘点资产,通过excel表格设计了不同的区域,进行每个区域的资产的计数工作,成为了一个登记事项
2.后续形成文本汇报工作,梳理内容
3.需求把表格中同类的内容进行总体的计算
例如我需要知道表格中A1(服务器机柜数量)最后的总和是多少
问题 :
'\ufeff` 文本中出现的内容,需要解决
通过with open("dysheet.txt","r",encoding="utf-8-sig")as fr:,修改为“utf-8-sig”读取文件方式解决;
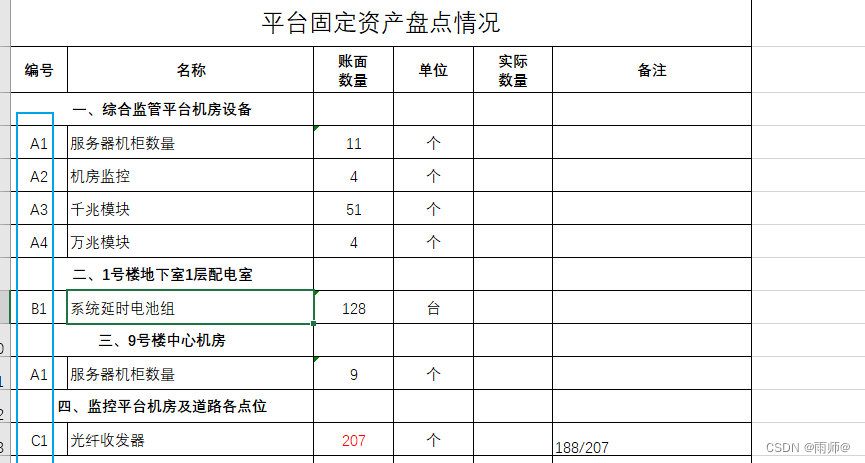
备注说明,名称列中相同的名称,在编号位置同样的编号,为后续python统计提供信息
例如这里的A1 那就是都是服务器机柜数量
二、素材内容
dysheet.txt内容如下;【目的实现这里的A1,A3等是excel表格中的列的“编号”】
A2:机房监控
A3:千兆模块
A4:万兆模块
A5:服务器
A6:防火墙
A7:接入交换机
A8:核心交换机
A9:核心交换机万兆光接口板
A10:核心交换机千兆电接口板
A11:核心交换机千兆光模块接口板
A12:扩展柜
A13:磁盘阵列
A14:万能解码器
A15:卡口应用服务器
A16:存储点播服务器
A17:流媒体服务器
A18:管理控制服务器
B1:系统延时电池组
C1:光纤收发器
三、代码以及注释,代码【读取文本那里还需要优化】
3.1读文本写入字典的时候出现了# {'\ufeffA2',【原来是A2】,出现了这个问题,需要解决
# 读取txt文件内容,形成一个字典,第一个读取的有问题,这个需要解决下
# 读取的内容如下;
# {'\ufeffA2': '机房监控', 'A3': '千兆模块', 'A4': '万兆模块'}
import os
import openpyxl
import re
# 读取excel表格内容,最终形成如下结果
# {'A1': 20, 'A2': 4, 'A3': 51}
def readexcel():
wb=openpyxl.load_workbook("固定资产盘点情况.xlsx")
sheet=wb["监管平台机房设备"]
# 数据内容
datas=list(sheet)
# 创建一个字典,用来存放列名以及统计后面的数字
coldics=dict()
for row in datas:
# 过滤多余的内容
# 第一列
evecolumn = row[0].value
# 第三列 数量的列
num=row[2].value
if re.match("[^ABCDE]+",evecolumn):
continue
if evecolumn in coldics:
coldics[evecolumn]= int(coldics[evecolumn])+int(num)
else:
coldics[evecolumn]=num
return coldics
# 读取txt文件内容,形成一个字典,第一个读取的有问题,这个需要解决下
# 读取的内容如下;
# {'\ufeffA2': '机房监控', 'A3': '千兆模块', 'A4': '万兆模块'}
# print(coldics)
def readtxt():
dics=dict()
with open("dysheet.txt","r",encoding="utf-8")as fr:
for line in fr:
# print(line)
# 取出多余空白符号
if not line:
continue
line=line.strip()
print(line)
key,value=line.split(":")
dics[key]=value
return dics
# print(dics)
# 合并两个字典内容,进行替换
# { '千兆模块': 51, '万兆模块': 8, '服务器': 4, '防火墙': 2, '接入交换机': 23, '核心交换机': 3, '核心交换机万兆光接口板': 3}
def formatdic(datadic,keydic):
# print(datadic,"<=============datadic")
# print(keydic,"<==============keydic=====")
# 新字典用于承装内容
newdic=dict()
for key in datadic:
# newdic[keydic[key]]=datadic[key]
# new key
newkey=keydic.get(key)
newdic[newkey]=datadic[key]
# print(newdic)
return newdic
if __name__ == '__main__':
dicss=readexcel()
datadic=readexcel()
keydic=readtxt()
newdic=formatdic(datadic,keydic)
print(newdic)
3.2解决问题:
在读取文本、csv文件的时候输出部分的开头多出了个不速之客“\ufeff”
查看了txt/csv文件里面也没有特殊字符,怎么输出就多了\ufeff了呢???
原因分析:
utf-8编码的文件时开头会有一个多余的字符\ufeff,在读文件时会读到\ufeff
解决办法:
只需改一下编码就行,把 UTF-8 编码 改成 UTF-8-sig编码即可
def readtxt():
dics=dict()
# with open("dysheet.txt","r",encoding="utf-8")as fr:
with open("dysheet.txt","r",encoding="utf-8-sig")as fr:
for line in fr:
# print(line)
# 取出多余空白符号
if not line:
continue
line=line.strip()
print(line)
lists=line.split(":")
key=lists[0].strip()
value=lists[-1].strip()
# 对key判断是否是空字符串,如果是空字符串还是得跳过内容;
if not key:
continue
# key,value=line.split(":")
print(key,"====",value)
dics[key]=value
return dics
# print(dics)
if __name__ == '__main__':
printdic=readtxt()
print(printdic)
最终代码:--可以使用的代码【解决了上述问题】
import os
import openpyxl
import re
# 读取excel表格内容,最终形成如下结果
# {'A1': 20, 'A2': 4, 'A3': 51}
def readexcel():
wb=openpyxl.load_workbook("固定资产盘点情况.xlsx")
sheet=wb["监管平台机房设备"]
# 数据内容
datas=list(sheet)
# 创建一个字典,用来存放列名以及统计后面的数字
coldics=dict()
for row in datas:
# 过滤多余的内容
# 第一列
evecolumn = row[0].value
# 第三列 数量的列
num=row[2].value
if re.match("[^ABCDE]+",evecolumn):
continue
if evecolumn in coldics:
coldics[evecolumn]= int(coldics[evecolumn])+int(num)
else:
coldics[evecolumn]=num
print("excel-datadic==>",coldics)
return coldics
# 读取txt文件内容,形成一个字典,第一个读取的有问题,这个需要解决下
# 读取的内容如下;
# {'\ufeffA2': '机房监控', 'A3': '千兆模块', 'A4': '万兆模块'}
# print(coldics)
def readtxt():
dics=dict()
# with open("dysheet.txt","r",encoding="utf-8")as fr:
with open("dysheet.txt","r",encoding="utf-8-sig")as fr:
for line in fr:
# print(line)
# 取出多余空白符号
if not line:
continue
line=line.strip()
# print(line)
lists=line.split(":")
key=lists[0].strip()
value=lists[-1].strip()
# 对key判断是否是空字符串,如果是空字符串还是得跳过内容;
if not key:
continue
# key,value=line.split(":")
# print(key,"====",value)
dics[key]=value
# print("keydic内容:",dics)
print("key关键字字典:",dics)
return dics
# print(dics)
# 合并两个字典内容,进行替换
# { '千兆模块': 51, '万兆模块': 8, '服务器': 4, '防火墙': 2, '接入交换机': 23, '核心交换机': 3, '核心交换机万兆光接口板': 3}
def formatdic(datadic,keydic):
# print(datadic,"<=============datadic")
# print(keydic,"<==============keydic=====")
# 新字典用于承装内容
newdic=dict()
for key in datadic:
# newdic[keydic[key]]=datadic[key]
# new key
newkey=keydic.get(key)
newdic[newkey]=datadic[key]
# print(newdic)
return newdic
if __name__ == '__main__':
datadic=readexcel()
keydic=readtxt()
newdic=formatdic(datadic,keydic)
print("最终结果:",newdic)





![看看螯合物前体多肽试剂DOTA-E[c(RGDfK)2]的全面解析吧!](https://img-blog.csdnimg.cn/img_convert/1a645a0ad632d629afb72e435adc3646.jpeg)