一、作业问题
1.CompareTo是按什么规则标准进行比较的?
当前区域性执行单词 (区分大小写和区分区域性) 比较。 有关单词、字符串和序号排序
的详细信息,请参阅 System.Globalization.CompareOptions。
并不是按照ASC码来的。所以特别小心,如下面的与的比较,一个是1一个是-1。若按ASC
小写都在大小后面,应该全是小于即-1,但结果不尽然。
另外,CompareTo只有两个重载,固定区分大小写和区域性。不具有灵活性。
因此,安全比较应该使用String.Compare,它有10个重载。
其中比较安全的是Ordinal或OrdinalIgnoreCase。
string s = "A";
Console.WriteLine(s.CompareTo("a"));//1
Console.WriteLine(s.CompareTo("b"));//-1
Console.WriteLine(string.Compare(s, "ab", StringComparison.Ordinal));//-32
Console.WriteLine(string.Compare(s, "bb", StringComparison.Ordinal));//-33
Console.ReadKey();
注:
Ordinal:使用序号(二进制)排序规则比较字符串。
OrdinalIgnoreCase: 上面比较时,忽略大小写。
2、var是什么东西?
var是类型推断,其声明赋值与其它变量类型一样:var n=100;
var是编译器根据这个表达式右侧的值进行“推断”左侧变量的类型。故声明时必须同时赋值。
而且一旦推断后,变量的类型不再更改变化。
因此,var第一次出现时表达式必须右则必须有“值”,否则无法推荐.
另外,虽然可以用object,但容易装拆箱操作,影响速度。
C#中的var与js的var完全不一样。
C#中的var是强类型。js的var是弱类型。
强类型:在编译时就能确定的类型;
弱类型:在运行时才能确定的类型。
internal class Program
{
private static void Main(string[] args)
{
var n = 100;
var m = 3.2;
var k = "hellow";
var p = new Person();
Console.ReadKey();
}
}
internal class Person
{
public string Name { get; set; }
}
对上面反编译,发现类型已经推荐确定:

var只能用作局部变量(方法中声明的变量),不能用作类的成员变量,
不能用作方法的返回值,也不能用作方法的参数。
private static void Main(string[] args)
{
var n; //错误,声明与赋值,必须同时进行。
n = 100;
var m = 3.2;
m = "hellow"; //错误,上面已经推荐成double,不能更改为string
var k = "hellow";
var p = new Person();
Console.ReadKey();
}
static void GetString(var s)//错误,只声明没赋值,即不能作形参
{
Console.WriteLine(s);
}
隐式类型:
var p = new { Email = "pp@126.com", Age = 20 };
Console.WriteLine(p.ToString());
定义为隐式类型,反编译后,直接推断:
var type;
Console.WriteLine(new <>f__AnonymousType0<string, int>("pp@126.com", 20).ToString());
Console.ReadKey();
注意:
因为ArrayList与Hashtable内部存储的任意类型,无法用Var进行推断。
故一般在泛型中才用var。
二、装箱和拆箱(box、unbox)
1.装箱、拆箱必须是: 值类型一引用类型 或 引用类型一值类型
int n = 100;
string s = Convert.ToString(n);
int m = int.Parse(s);
上面未发生装箱与拆箱。
int x = 200;
object o = x;//装箱
// int y = o;//错误
int y = (int)o; //拆箱
上两种转换类型,但一个发生了装拆箱,一个没有发生,原因何在?
下面是上面两种情况的栈堆操作
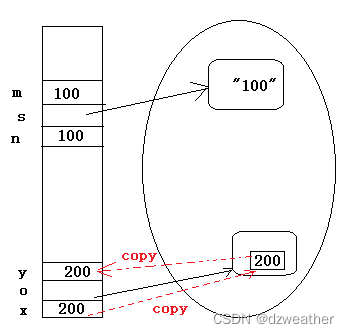
发生装拆箱时,栈与堆之间有数据的copy拷贝动作,即由栈中200复制到堆中200,然后将
地址给o,拆箱时将地址中数据200复制到y中。
而s时未栈并没有向堆复制100,而是直接在堆中创建新的字串100。同样m是也是直接创建。
2.装拆箱判断的前提是:
(1)发生在值类型与引用类型之间(栈与堆);
(2)两者有继承(如父子)关系。
另外一个硬性判断,Convert与Parse不会装拆箱,它只是类型转换。
所以上面的int与string之间的类型转换不是装拆箱。
反编译上面:

判断是否装箱:
//Student为Person子类
Person p = new Person();
Student stu =(Student) p;
未发生装箱。因为未发生在值与引用之间。
p = new Person();是隐式类型转换,不叫装箱。
stu =(Student) p;是显式类型转换,不叫拆箱。
3.问题一:下面代码发生了什么?
private static void Main(string[] args)
{
int d = 999;
object o = d;
double d1 = (double)o;
Console.WriteLine(d1);
Console.ReadKey();
}
在拆箱转为double时会出错,因为:
装箱前是什么类型,拆箱后也必须是什么类型,否则报错。
装箱前为int,拆箱也必须是int,故用double会报错。
即装箱装的是苹果,拆箱后也应是苹果,而不能变成橙子。
修改为:double n = Convert.ToDouble((int)o);//正确
4.问题二:下面是否发生装箱?
int age = 5;
string str = age.ToString();
装箱未发生。装箱是指将值类型转换为引用类型,可以通过将值类型分配给Object类型或
任何值类型的接口引用来实现。在这段代码中,虽然int类型是值类型,但是ToString()
方法返回的是一个string类型,它是引用类型。在这种情况下,不需要进行装箱。
同样看看:
int n = 10;
string s1 = n.ToString();
string s2 = n.GetType().ToString();
Console.WriteLine(s1 + " " + s2);
未发生装箱。
s1 = n.ToString(); 调用了 int 类型的 ToString() 方法,将数值类型的 n 变量转换
为字符串类型,这里没有发生装箱或拆箱操作,因为 n 变量本身并没有被封装为对象类型。
s2 = n.GetType().ToString(); 调用了 int 类型所继承的 Object 类的 GetType() 方法,
将得到 n 变量所属的类型(即类型 Type),然后再调用 Type 类型的ToString()方法,
将得到的类型信息转为字符串类型。这里GetType()方法不涉及到值类型的实例,因此
不涉及装箱操作。
5.问题三:下面是否发生装箱?
int n = 100;
string s = "OK" + n;
发生了装箱。当一个值类型被转换成一个Object,或者被转换成任何一个接口类型,或者
被转换成一个动态类型,编译器都会将其装箱。这个过程中,编译器会在堆上创建一个新
的对象,包含了原始值类型的所有信息,并且返回对这个对象的引用。
Concat(String, String)或Concat(Object, Object)等
在这个代码片段中,由于字符串操作符 “+” 的重载函数并不接受一个值类型作为它的第
二个参数,因此编译器在执行 “OK” + n 表达式时必须将 n 固定到一个对象上,这个过
程就是装箱。因此,整数值 n 被装箱成了一个新的 Object 类型的对象,才能与字符串
“OK” 进行连接操作。
6.问题四:下面发生了几次装箱?
private static void Main(string[] args)
{
int n1 = 100;
M1(n1);
string s = "a";
double d = 10;
int n = 9;
string s1 = s + d + n;
Console.WriteLine(s1);
Console.ReadKey();
}
private static void M1(double d)
{
Console.WriteLine(d);
}
private static void M1(object o)
{
Console.WriteLine(o);
}
M1(n1)会调用M1(double)而不是object,这个重载并没有发生装箱。
后面发生了两次装箱:
第一次装箱动作发生在表达式 “x + d1” 中,其中 string 类型的字符串 “x” 需要和
double 类型的变量 “d1” 进行字符串拼接。由于字符串拼接操作符 “+” 的重载函数并不
接受一个 double 类型的参数,因此编译器将 “d1” 固定到一个对象上,这个过程就是
装箱。因此,变量 “d1” 被装箱成了一个新的 Object 类型的对象,才能与字符串 “x”
进行拼接操作。
第二次装箱动作发生在表达式 “(x + d1) + n1” 中,其中类型为 string 的字符串
“x + d1” 需要和 int 类型的变量 “n1” 进行字符串拼接。由于字符串拼接操作符 “+” 的
重载函数并不接受一个 int 类型的参数,因此编译器将 “n1” 固定到一个对象上,这个
过程就是装箱。因此,变量 “n1” 被装箱成了一个新的 Object 类型的对象,才能与字符
串 “x + d1” 进行拼接操作。
上面没有发生拆箱动作。
7.问题五:装箱与拆箱可以理解成栈与托管堆之间数据的来回复制?
装箱和拆箱涉及值类型(栈)和引用类型(堆)之间的转换,但它们不是数据在栈
和堆之间的复制。
装箱是将一个值类型对象转换为一个引用类型(object、ValueType 或 interface)
的过程,它会在堆上创建一个新的对象,将栈中的值类型数据复制到该对象中,然后将该
对象的引用返回给代码。
拆箱是将一个引用类型对象转换为对应的值类型对象的过程,它会从堆上取出装箱的
对象,将其数据复制到栈上创建的值类型变量中,并将栈上该变量的地址返回给代码。
因此,装箱和拆箱与数据在栈和堆之间的复制不一样,它们涉及栈和堆上对象的转换
操作。
8.问题六:下面是否发生装拆箱?
int n = 100;
IComparable m = n;
int n1 = (int)m;
Console.ReadKey();
由int到对象IComparable装箱一次,由对象到n1又拆箱一次。
提示:
(1)在反编译IL代码中,box表示装箱,unbox表示拆箱。
(2)拆箱并不会销毁原对象,原对象是否存在是根据是否有引用,由GC回收。
9.问题七:下面有装箱吗?
int n = 100;
Console.WriteLine(n);
没有.直接调用的是WriteLine(int32),直接使用int32,无装箱。
10.问题八:有装箱吗?
int n = 100;
Console.WriteLine("雍正{0}", n);
有装箱。结果是“雍正100”,明显是前面字串与后面n连接。
调用的是WriteLine(string, object),因此由int变成object发生装箱。
11.问题九:有装箱吗?
int n = 100;
Console.WriteLine("雍正{0},康熙{1}", n, "23" + n);
有两次。前面n到object是一次。后面“23”与n连接使用装箱变成字符串。
12.问题十:结果是多少?
int n = 100;
int m = 100;
Console.WriteLine(n.Equals(m));
Console.WriteLine(object.ReferenceEquals(n,m));
值相等,equals为真。后面因为是object.ReferenceEquals(object A,object B)
是创建两个对象,因此它们在堆中的地址是不同的,故为false.
13.问:装拆箱情况?
int n = 10;
object o = n;
n = 100;
Console.WriteLine(n + "" + (int)o);
o=n装箱一次,n+""装箱一次,(int)o拆箱一次。(n+"")+(int)o再装箱一次。
14.问:多种类型连接,用+与String.Concat是一样的吗?
在简单的情况下,使用 "+" 运算符和 string.Concat 方法得到的结果是相同的。例如:
string s1 = "Hello";
string s2 = "World";
string s3 = s1 + " " + s2;
string s4 = string.Concat(s1, " ", s2);
在这个例子中,s3 和 s4 中的字符串都是 "Hello World"。
然而,当涉及到更复杂的表达式或程序性能时,使用 string.Concat 方法会更加高效,
因为它使用了内置的StringBuilder 字符串拼接机制,而使用 "+" 运算符则可能会创
建更多的临时字符串实例,从而影响程序性能。
在 C# 6或更高版本中,可以使用字符串插值(string interpolation)作为另一种连
接字符串的方式,它使用 $"..." 或者前缀 @ 符作为模板字符串,例如:
string s1 = "Hello";
string s2 = "World";
string s3 = $"{s1} {s2}";
在这个例子中,s3 也是 "Hello World"。这种方式更直观,也更容易理解和维护。
15.判断这么多装拆箱,有什么用?
装箱的优点:
(1)在某些情况下,需要将值类型存储在引用类型的变量中,这时候装箱就是必要的。
(2)装箱可以将值类型作为对象传递给方法、属性或者参数,使得值类型可以被当作
引用类型使用。
拆箱的优点:
(1)拆箱可以将一个对象类型的引用变量转换为值类型的变量,对于有些场景来说这
是必需的。
(2)拆箱可以提高程序运行时性能,因为直接操作值类型比间接操纵引用类型更快。
装箱和拆箱的缺点:
(1)装箱和拆箱操作会导致性能开销,因为它们需要额外的内存分配和数据拷贝操作。
(2)装箱和拆箱操作会导致内存浪费,因为它们涉及到对象实例创建,这会占用更多
的内存空间。
综上所述,装箱和拆箱对程序的性能和内存开销有着不可忽略的影响,因此应该在程
序设计中尽量避免不必要的装箱和拆箱操作,同时也可以使用一些技巧来减少装箱和
拆箱的次数,从而提高程序的性能。
比较泛型集合List<T>与ArrayList的性能。看一下装箱、拆箱的效率:
ArrayList al = new ArrayList();
Stopwatch sw = new Stopwatch();
sw.Start();
for (int i = 0; i < 1000000; i++)
{
al.Add(i);//装箱
}
sw.Stop();
Console.WriteLine(sw.Elapsed);
List<int> li = new List<int>();
sw.Restart();
for (int i = 0; i < 1000000; i++)
{
li.Add(i);//未发生装箱
}
sw.Stop();
Console.WriteLine(sw.Elapsed);
结果为:

明显看出两者效率不同。
16.凡是在IL中的都是托管,不在IL中的是非托管?
答:这个说法不太准确。C# 代码最终编译为 IL 代码并加载到 CLR 中执行,因此在
IL 中看到的代码都是托管代码。但并不是所有的非托管代码都不能在 IL 中看到,
例如使用 P/Invoke 调用非托管库时,C# 代码中需要使用 extern 关键字来声明非
托管函数,这些声明本身就是 IL 代码。
另外,C# 中还有一些语言特性和语法不能直接在 IL 中看到,例如属性访问器、
迭代器、匿名类型等,但它们本质上也是被编译为 IL 代码并加载到 CLR 中执
行的。
总之,不能简单地通过在 IL 中看到代码来判断它是托管代码还是非托管代码。
通常来说,托管代码是由 C# 编译器生成的 IL 代码,而非托管代码则是通过
P/Invoke 调用非托管库、使用 COM 互操作技术或者使用 C++/CLI 等方式编
写的。
三、自定义泛型<T>
1.T是一个占位符,在使用时,用具体的一个类型来替换。因此这个T也可以写成W,X,Ho等。
例如下面的泛型类:
internal class Program
{
private static void Main(string[] args)
{
MyClasss<string> mc = new MyClasss<string>();//a
mc.SayHi("你好!");//这里写,T的类型变成string
Console.ReadKey();
}
}
internal class MyClasss<T> //b 写也MyClass<W>也可以
{
public void SayHi(T s)
{
Console.WriteLine(s);
}
}
注意:
占位符可以是一个<X>,也可以是多个<X,Y,Z>等等。若是多个,则在声明时如上面
的a处,就应把所有的T进行明确说明,以便后面使用时已经确认了类型。
不能写也<T,params Y>,尽管泛型中的T是占位符,但它占位的是参数类型,而不是
参数本身或其它。即int x,T占位的是int,而params占位的是对整个(int x)的说明,
并且这个说明只能是已知类型的一维数组的说明(修饰),后面不再跟参数。
例如:public static void UseParams2(params object[] list)
internal class Program
{
private static void Main(string[] args)
{
MyClasss<string, double, bool> mc = new MyClasss<string, double, bool>();
mc.SayHi("你好!");
mc.SayChina(3.14);
mc.StandUp(true);
Console.ReadKey();
}
}
internal class MyClasss<T, W, Z> //写也MyClass<W>也可以
{
public void SayHi(T s)
{
Console.WriteLine(s);
}
public void SayChina(W w)
{
Console.WriteLine(w);
}
public void StandUp(Z z)
{
Console.WriteLine(z);
}
}
2.泛型方法
上面泛型类很简单,直接类名后加<T>。
泛型方法则是在方法名的后面加<T>,其后面的参数或方法体内再使用T。
internal class Program
{
private static void Main(string[] args)
{
Person p = new Person();
p.SayHello<String>("用字符串");
p.SayHello<double>(3.14);
Console.ReadKey();
}
}
internal class Person
{
public void SayHello<T>(T s)
{
Console.WriteLine(s);
}
}
3.泛型接口
泛型接口与泛型类的形式一样,可以在返回值或参数中。
internal interface IFace<T>
{
T Look();
void SayHi(T t);
}
但泛型接口的使用有两种方法:
(1)在普通类中使用泛型接口:
internal class Program
{
private static void Main(string[] args)
{
IFace<string> f = new Person();//a
f.SayHi("大漠孤烟直");
Console.WriteLine(f.Look());
Console.ReadKey();
}
}
internal interface IFace<T>
{
T Look();
void SayHi(T t);
}
internal class Person : IFace<string> //b
{
public string Look()
{
return "OK";
}
public void SayHi(string t)
{
Console.WriteLine(t);
}
}
上面在普通类中使用接口时,b处固定了泛型string,使得在a处必须用string。
如果在a处使用int,则程序报错。这就是在写接口中如果固定死了类型,则很受限制。
(2)在泛型类中使用泛型接口。
internal class Program
{
private static void Main(string[] args)
{
IFace<string> f = new Person<string>();//a
f.SayHi("大漠孤烟直");
Console.WriteLine(f.Look("OK"));
IFace<double> f2 = new Person<double>();//c
f2.SayHi(3.14);
Console.WriteLine(f2.Look(142857.0));
Console.ReadKey();
}
}
internal interface IFace<T>
{
T Look(T x);
void SayHi(T t);
}
internal class Person<U> : IFace<U> //b
{
public U Look(U x)
{
return x;
}
public void SayHi(U t)
{
Console.WriteLine(t);
}
}
可以看到b处,用泛型类中的U,意味着,泛型类确定后,泛型接口中的U也就跟随确定了。
这样在a与b处可以比较灵活地定义U。
但如果在a中的接口固定了为IFace<string>再跟上泛型类,这样就把接口固定死了,变成
了第一种在普通类中使用泛型一样。
注意:b处IFace<U>的U不能写成其它T,因为无法确定T。
因为在定义接口时可以写成T,但在使用接口中必须具有“确定性”的指明。
要么只能是U跟随前面类来确定,或者直接写成明确的类型IFace<String>等等.
4.为什么要用泛型?
使用泛型可以减免频繁的装拆箱,提高性能。
使用泛型可以是“重用”,只是数据类型发生了变化。
internal class Program
{
private static void Main(string[] args)
{
MyClass<string> mc1 = new MyClass<string>();//a
mc1[0] = "黄林";
MyClass<int> mc2 = new MyClass<int>();
mc2[0] = 1436;
Console.WriteLine(mc1[0] + mc2[0].ToString());//b
Console.ReadKey();
}
}
internal class MyClass<T> //索引器
{
private T[] _data = new T[3];
public T this[int index]
{
get { return _data[index]; }
set { _data[index] = value; }
}
}
上面算法未发生变化,只是类型发生了变化,仍然使用这段代码。
5.作业:用List<T>泛型版本,对Person类4个对象进行排序(Sort,比较大小).
internal class Program
{
private static void Main(string[] args)
{
List<Person> list = new List<Person>()
{
new Person("小明",20),
new Person("小红",19),
new Person("小朱",22)
};
list.Sort(new PersonComparaer());
foreach (Person p in list)
{
Console.WriteLine($"{p.Name}:{p.Age}");
}
Console.ReadKey();
}
}
internal class Person
{
public string Name { get; set; }
public int Age { get; set; }
public Person(string name, int age)
{
this.Name = name; this.Age = age;
}
}
internal class PersonComparaer : IComparer<Person>
{
public int Compare(Person x, Person y)
{
return x.Age.CompareTo(y.Age);
}
}
四、泛型类型约束 where
泛型在使用<T>后,由于T可以替代很多类型,所以很方便使用。但是,也带来了一些麻烦。
比如<T>只能限制在值类型中使用,但用户并不清楚,造成问题。
为了指明对泛型<T>类型的使用进行限制,用Where进行泛型类型约束。
注意:泛型是对原来任意类型的一种限制,泛型的类型约束相当于再次对固定类型的一种限制。
进一步的限制是让用法更接近使用的目的,不会产生不可控意外。
1、语法
where T:xxx
在泛型的后面紧跟where与当前的占位符T,并由xxx来指明约束的具体限制。
2、约束的种类:
where T : struct
类型参数必须是不可为 null 的值类型。 有关可为 null 的值类型的信息,请
参阅可为 null 的值类型。 由于所有值类型都具有可访问的无参数构造函数,
因此 struct 约束表示 new() 约束,并且不能与 new() 约束结合使用。
struct 约束也不能与 unmanaged 约束结合使用。
where T : class
类型参数必须是引用类型。 此约束还应用于任何类、接口、委托或数组类型。
在可为 null 的上下文中,T 必须是不可为 null 的引用类型。
where T : class?
类型参数必须是可为 null 或不可为 null 的引用类型。 此约束还应用于任
何类、接口、委托或数组类型。
where T : notnull
类型参数必须是不可为 null 的类型。 参数可以是不可为 null 的引用类型,
也可以是不可为 null 的值类型。
where T : default
重写方法或提供显式接口实现时,如果需要指定不受约束的类型参数,此约
束可解决歧义。 default 约束表示基方法,但不包含 class 或 struct 约
束。 有关详细信息,请参阅default约束规范建议。
where T : unmanaged
类型参数必须是不可为 null 的非托管类型。 unmanaged 约束表示 struct
约束,且不能与 struct 约束或 new() 约束结合使用。
where T : new()
类型参数必须具有公共无参数构造函数。 与其他约束一起使用时,new()
约束必须最后指定。 new() 约束不能与 struct 和 unmanaged 约束结合使
用。
where T :<基类名>
类型参数必须是指定的基类或派生自指定的基类。 在可为 null 的上下文
中,T 必须是从指定基类派生的不可为 null 的引用类型。
where T :<基类名>?
类型参数必须是指定的基类或派生自指定的基类。 在可为 null 的上下文
中,T 可以是从指定基类派生的可为 null 或不可为 null 的类型。
where T :<接口名称>
类型参数必须是指定的接口或实现指定的接口。 可指定多个接口约束。
约束接口也可以是泛型。 在的可为 null 的上下文中,T 必须是实现指定
接口的不可为 null 的类型。
where T :<接口名称>?
类型参数必须是指定的接口或实现指定的接口。 可指定多个接口约束。
约束接口也可以是泛型。 在可为 null 的上下文中,T 可以是可为 null
的引用类型、不可为 null 的引用类型或值类型。 T 不能是可为 null
的值类型。
where T : U
为 T 提供的类型参数必须是为 U 提供的参数或派生自为 U 提供的参数。
在可为 null 的上下文中,如果 U 是不可为 null 的引用类型,T 必须
是不可为 null 的引用类型。 如果 U 是可为 null 的引用类型,则 T
可以是可为 null 的引用类型,也可以是不可为 null 的引用类型。
委托约束:
T必须是委托类型
internal class Program
{
public static void Main()
{
MyGenericClass<Action> actionClass = new MyGenericClass<Action>();
Action action = new Action(() => Console.WriteLine("Hello, world!"));
actionClass.PerformOperation(action);
Console.ReadKey();
}
}
public class MyGenericClass<T> where T : Delegate
{
public void PerformOperation(T operation)
{
// 具体实现
// 调用委托实例
operation.DynamicInvoke();
}
}
枚举约束:
T被约束为枚举类型, System.Enum 类型
private static void Main(string[] args)
{
var map = EnumNamedValues<Rainbow>();
foreach (var pair in map)
Console.WriteLine($"{pair.Key}:\t{pair.Value}");
Console.ReadKey();
}
public static Dictionary<int, string> EnumNamedValues<T>() where T : System.Enum
{
var result = new Dictionary<int, string>();
var values = Enum.GetValues(typeof(T));//取得值的数组
foreach (int item in values)
result.Add(item, Enum.GetName(typeof(T), item)!);
return result;
}
internal enum Rainbow
{
Red,
Orange,
Yellow,
Green,
Blue,
Indigo,
Violet
}
上面将枚举的名称与值生成字典。上面用的!操作符,需在netcore中运行。
! (null 包容)运算符
C#中的!(null 包容)运算符是一个C# 9 的新特性,它表示空值判定。
它可以用于不适用null合并 (??) 运算符的情况下进行 null 值的安全
访问。
在之前的版本中,我们需要通过类似以下一种方式来判定空值:
if (myObject != null)
{
myObject.MyMethod();
}
现在,我们可以使用!运算符来达到同样的效果。
myObject!.MyMethod();
在这个例子中,如果myObject不为空,则会调用MyMethod方法。如果
myObject为空,那么将会抛出`System.NullReferenceException`异常。通过
在myObject上使用!运算符,编译器就会认为myObject不会为null,并且语法
完成后,表达式将始终不为null,从而避免出现`NullReferenceException`异常。
除了可以使用!运算符对引用类型进行 null 值判定外,它还可以用于对空合并
运算符(`??`)的左侧进行 null 值判定。例如:
int? length = input?.Length ?? 0;
在这个例子中,?运算符用于进行 null 值判定,如果input是 null,则返回
null,否则返回input.Length。在此之后,??运算符将结果和0进行比较。
如果结果为 null,则返回0,否则返回结果。
需要注意的是,!运算符只应该在确定引用不为null的情况下使用。如果引用
为null,则会触发`NullReferenceException`异常。
int?类型是一种可空的整型
也称作Nullable<int>。与普通的int类型不同,
int?类型可以表示一个整型值,还可以表示null值。 int?类型的简单示例:
private static void Main(string[] args)
{
int? a = 10; int? b = null;
if (a.HasValue)
{ Console.WriteLine($"a 的值为:{a.Value}"); }
else
{ Console.WriteLine("a 为 null"); }
if (b.HasValue)
{ Console.WriteLine($"b 的值为:{b.Value}"); }
else
{ Console.WriteLine("b 为 null"); }
Console.ReadKey();
}
在上面的代码中,我们声明了两个int?类型的变量a和b。a的值为10,而b的值
为null。使用HasValue属性可以判断一个int?类型的变量是否为null,如果不
为null,使用Value属性可以获取该变量的值。在上面的代码中,我们使用if
语句判断a和b是否为空,并输出相应的值或消息。
注意,不能直接对int?类型的变量进行算术运算或其他操作,因为它们可能包
含null值。如果想要对int?类型的变量进行算术运算或其他操作,我们需要先
判断变量是否为null,再进行相关的操作。
private static void Main(string[] args)
{
int? c = 5; int? d = null;
int result1 = c ?? 0;
int result2 = d ?? 0;
Console.WriteLine(result1); // 输出 5
Console.WriteLine(result2); // 输出 0
Console.ReadKey();
}
在上面的代码中,我们使用了空合并运算符(??)操作符,将c和d转换为普通的
int类型。如果c或d为null,则返回默认值0。之后,我们输出了转换后的结果。
??运算符是空合并运算符
用于指定默认值。它用于判断一个表达式是否为null,如果为null,则返回指
定的默认值,否则返回该表达式的值。
示例:
int? a = null;
int b = a ?? 0;
上面声明了一个可空整型变量a并将其赋值为null,之后使用??运算符判断a
是否为null。由于a为null,所以返回默认值0,并将该值赋给整型变量b。
最终,b的值为0。
需要注意的是,??运算符不仅可以用于可空类型,也可以用于非空类型。
对于非空类型,当表达式的值为null时,该运算符会返回指定的默认值,否
则返回该表达式的值。
下面是一个示例,演示如何使用??运算符指定默认值:
string str1 = null;
string str2 = str1 ?? "default value"; Console.WriteLine(str2); // 输出 "default value"
在上面的代码中,我们定义了一个字符串变量str1并将其赋值为null,然后
使用??运算符指定默认值为字符串"default value"。由于str1为null,所
以返回默认值"default value"并将其赋给字符串变量str2。最终,输出字
符串变量str2的值,得到结果为"default value"。
这就是使用??运算符的基本示例。通过使用??运算符,我们可以指定默认
值,避免空引用异常,并增强程序的鲁棒性和可读性。
int? length = input?.Length ?? 0;
int?类型是可空的整型;?.运算符是空值安全访问运算符,用于防止空引用异常;
??运算符是空合并运算符,用于提供默认值。
因此,int? length = input?.Length ?? 0;这行代码的含义如下:
首先,判断input是否为null。如果为null,则input?.Length计算为null。
如果input不为null,则计算input.Length的值,并将计算结果赋给length。
如果在步骤1和步骤2中input.Length计算的结果为null,则使用默认值0。
简单来说,这行代码的作用是:获取input字符串的长度,如果input为null,
则返回0。其中,int?类型是为了处理input为空的情况,?.运算符是为了判
断input是否为空,??运算符是为了指定默认值。 需要注意的是,?.运算符和??运算符都是从左往右进行计算,因此这行代码
的执行顺序是从左往右依次计算的。
3、细解
(1)上面中的struct表示的就是值类型
public class MyClass
{
public static void MyMethod<T>(T argument) where T : struct
{
Console.WriteLine($"{argument.GetType().Name} is a value type.");
}
}
internal class Program
{
private static void Main()
{
int i = 10;
MyClass.MyMethod(i); // 输出: Int32 is a value type.
string s = "foo";
MyClass.MyMethod(s); // 编译错误:string 不是值类型
Console.ReadKey();
}
}
(2)上面class与class?的用法。class表示是引用,后面无?表示该引用不能为null
internal class A
{ public override string ToString() => "A"; }
internal interface IB
{ }
internal delegate string MyDelegate();
internal class Program
{
private static void Main(string[] args)
{
MyClass<string> c1 = new MyClass<string>(); // string可用于引用类型
c1.Process("hello");// 输出:hello
MyClass<A> c2 = new MyClass<A>(); //class A可用于引用类型
c2.Process(new A()); // 输出:Object: A
MyClass<IB> c3 = new MyClass<IB>();
//c3.Process(new A()); // 编译错误:A 类型不满足 IB 接口约束
MyClass<MyDelegate> c4 = new MyClass<MyDelegate>();
c4.Process(() => "test"); // 输出:Object: MyDelegate
Console.ReadKey();
}
}
public class MyClass<T> where T : class
{
public void Process(T obj)
{
Console.WriteLine($"Object: {obj.ToString()}");
}
}
说明:string是引用类型,一种特殊的引用类型;
class A是引用类型;
interface IB是接口,是抽象类型,不是引用类型;
MyDelegate是委托,是引用类型。
注意:委托类型是引用类型,尽管它在某些方面类似于值类型(如不可变性等),
但是它实际上是引用类型。测试代码:
internal class Program
{
public delegate void MyDelegate(int value);
private static void Main(string[] args)
{
MyDelegate handler = MyMethod;
Console.WriteLine(handler.GetType().IsValueType);//False
Console.ReadKey();
}
private static void MyMethod(int value)
{
Console.WriteLine($"Value: {value}");
}
}
上面表示委托不是值类型(False)
约束中class是非空引用,意味着你不能将 null 传递给此类型的泛型参数。
internal class Program
{
private static void Main(string[] args)
{
// 使用 MyList<T> 时必须传递一个非空的引用类型作为 T 的参数
var myList = new MyList<string>(); // 正确
var myList2 = new MyList<int>(); // 错误:int 不是引用类型
var myList3 = new MyList<string?>();//错误,string?是可空的引用类型
}
}
public class MyList<T> where T : class //非空的引用类型约束
{
}
而 where T : class? 是一种可空引用类型约束,表示类型参数可以是引用类型,
也可以是 null。如果你需要在某些情况下为类型参数传递 null 值,可以使用
这种约束。
注意:可为null的引用类型只能用于C#8.0以上,也即net core3.X以上,如果要
测试下面代码不能在net framework框架中。请切换到net core中
internal class Program
{
private static void Main(string[] args)
{
// 使用 UserRepository<T> 时可以传递 null 作为 T 的参数
var userRepository = new UserRepository<User>(); // 正确
var userRepository2 = new UserRepository<string>(); // 正确:string 是引用类型
var userRepository3 = new UserRepository<int>(); // 错误:int 不是引用类型
Console.ReadKey();
}
}
public class User
{ }
public class UserRepository<T> where T : class?
{
public T? GetById(int id)
{
// ...
return null;
}
}
(3)notnull约束,即不能为空,比如值类型。引用类型中有可能为空,所以要注意。
注意:notnull只能在C#8.0以上版本中使用
internal class Program
{
private static void Main(string[] args)
{
MyClass<string> obj1 = new MyClass<string>();
obj1.MyMethod("Hello"); // 错误,因为 string 可以为 null
MyClass<int> obj2 = new MyClass<int>();
obj2.MyMethod(123); // 正确,因为 int 不能为 null
Console.ReadKey();
Console.ReadKey();
}
}
internal class MyClass<T> where T : notnull
{
public void MyMethod(T value)
{
// 在这里可以使用 value 参数,因为 T 必须是 notnull 类型
Console.WriteLine(value.ToString());
}
}
(4)new()约束指定必须有一个无参的公共构造函数。
这样可以允许泛型类型创建出新的实例,并在使用这些实例之前进行初始化
public class MyClass<T> where T : new()
{
public void Process()
{
T obj = new T();
// TODO: 对 obj 进行操作
}
}
internal class MyClassWithoutConstructor
{ }
internal class MyClassWithConstructor
{
public MyClassWithConstructor(int value)
{ }
}
internal class Program
{
private static void Main(string[] args)
{
// MyClassWithoutConstructor 满足约束,可以使用
var c1 = new MyClass<MyClassWithoutConstructor>();
// MyClassWithConstructor 不满足约束,编译错误
//var c2 = new MyClass<MyClassWithConstructor>();// 编译错误
}
}
因为泛型中要用到一个无参的构造函数,若没有该函数则出错,故要进行约束
(5)<基类名>指定基类约束,要求泛型类型参数必须是指定基类的派生类。
T必须是基类或接口.
internal class Animal
{
public virtual void Speak()
{ Console.WriteLine("Animal"); }
}
internal class Dog : Animal
{
public override void Speak()
{ Console.WriteLine("Woof!"); }
}
internal class Cat : Animal
{
public override void Speak()
{ Console.WriteLine("Meow!"); }
}
internal class Program
{
private static void Main(string[] args)
{
Animal animal1 = new Dog();
Animal animal2 = new Cat();
PrintSpeak(animal1); // 输出 "Woof!"
PrintSpeak(animal2); // 输出 "Meow!"
}
private static void PrintSpeak<T>(T animal) where T : Animal
{ animal.Speak(); }
}
猫狗的基类为动物,指定约束基类为动物。
<base class>与<base class>?的区别在于是否为null,类似上面class与class?
在不允许T为null时用前者,否则允许为空时,使用后者泛型类型约束。
public interface IMyInterface
{ }
public class MyBaseClass
{ }
public class MyDerivedClass : MyBaseClass, IMyInterface
{ }
public class MyClass<T> where T : MyBaseClass?
{
public bool IsDerivedFromBaseClass(T obj)
{ return obj is MyBaseClass; }
public bool IsImplementInterface(T obj)
{ return obj is IMyInterface; }
}
internal class Program
{
private static void Main(string[] args)
{
var obj1 = new MyClass<MyDerivedClass>();
MyDerivedClass derived = new MyDerivedClass();
bool result1 = obj1.IsImplementInterface(null); // 正确,因为 T 是 ? 类型的
bool result2 = obj1.IsImplementInterface(derived); // 返回 true
bool result3 = obj1.IsDerivedFromBaseClass(null); // 正确,因为 T 是 ? 类型的
bool result4 = obj1.IsDerivedFromBaseClass(derived); // 返回 true
}
}
这个例子只说明了<base class>?情况,调用两个不同方法。
public class ShapeManager<T> where T : Shape
{ // 方式一:不允许 T 为 null
private List<T> _shapes = new List<T>();
public void AddShape(T shape)
{ _shapes.Add(shape); }
}
public class ShapeManager<T> where T : Shape?
{ // 方式二:允许 T 为 null
private List<T> _shapes = new List<T>();
public void AddShape(T? shape)
{ _shapes.Add(shape); }
}
或者专门对null情况进行处理:
public static void PrintAnimal<T>(T animal) where T : Animal
{// 方式一:不允许 T 为 null
Console.WriteLine(animal.Name);
}
public static void PrintAnimal<T>(T? animal) where T : Animal?
{// 方式二:允许 T 为 null
if (animal == null)
{ Console.WriteLine("null"); }
else
{ Console.WriteLine(animal.Name); }
}
(6)where T:U约束条件表示类型参数 T 必须是指定的类型 U 或其派生类的实例。这
意味着 T 必须是 U 或其派生类的类型,否则编译时将引发错误。
注意:本约束说明泛型中必须有两个类型T与U。
internal interface IGenericBase2<T, U> where T : U
{
void DoSomething();
}
internal class GenericClass : IGenericBase2<GenericClass, object>
{
public void DoSomething()
{ // 实现接口方法
}
}
例子中,必须要有两个类型T与U,用where说明了,U必须是T或T的基类。
注意与where T:<base class>的区别。虽然也说明了后面是T或基类,但它只说明
了其中一个占位符,并没有另一个泛型的出现或者不出现,两者无相互关系。
internal interface IGenericBase<T> where T : IGenericBase<T>
{
void DoSomething();
}
internal class DerivedClass : IGenericBase<DerivedClass>
{
public void DoSomething()
{
// 实现接口方法
}
}
上例并没有U出现,所以只能指明基类名。
下面代码需要在不安全中使用。因此
1.在属性“生成”中设置允许不安全代码。
2.需要用unsafe指明使用sizeof
internal class Program
{
private static void Main(string[] args)
{
MyClass<int> myClass1 = new MyClass<int>();
MyClass<double> myClass2 = new MyClass<double>();
MyClass<MyStruct> myClass3 = new MyClass<MyStruct>();
myClass1.PrintSize(); // 4
myClass2.PrintSize(); // 8
myClass3.PrintSize(); //4(仅一个int类型字段)
}
}
public struct MyStruct
{ public int x; }
public class MyClass<T> where T : unmanaged
{
public void PrintSize()
{
unsafe
{
int size = sizeof(T);
Console.WriteLine($"Size of {typeof(T)} = {size}");
}
}
}
问题:int与double是非托管类型吗?
在C#中,unmanaged类型是指满足以下条件的类型:
基元类型(primitive types),如上所述;
结构体类型(struct types),其成员也必须是unmanaged类型;
引用类型(reference types)的指针类型(如IntPtr、UIntPtr);
泛型类型参数的类型参数必须约束为unmanaged类型。
因此,int、long等整型均属于unmanaged类型。我们可以在泛型约束中使用
where T : unmanaged来限制类型参数为unmanaged类型,也可以使用sizeof关
键字获取这些类型在内存中占用的字节数。
在.NET Framework下,C#中定义的各种数据类型,包括System.Int32,都是CLR所
管理的托管类,它们都是继承自Object类的。托管类可以享受垃圾回收、自动内
存管理等由CLR提供的服务,但同时也存在一些性能损失。
在C#中有一些类型比较特殊,在一些情况下会将它们映射为非托管类型,例如
int、long这些整数类型,以及double、float等浮点数类型。这些类型被映射之
后,就可以直接在本机代码中使用,而无需进行类似于装箱和拆箱这样的操作,
从而提高了程序的执行效率。
但是需要注意的是,这些类型在C#中仅仅是一个语法上的特殊处理,它们在内
存中仍然是通过CLR进行管理的托管对象。
System.Int32属于托管类,而非非托管类。
(7)where T:default主要用于获取缺省值,比如值类型缺省0,布尔false,引用null
只用于一些特殊情况,如获取默认值、创建泛型类型实例等。一般情况下,更常
使用其他的类型约束,如where T : class、where T : struct、
where T : new()等。
internal class Program
{
private static void Main(string[] args)
{
MyGenericClass<int> myInt = new MyGenericClass<int>();
int intVal = myInt.DefaultValue(); // 返回0
MyGenericClass<string> myStr = new MyGenericClass<string>();
string strVal = myStr.DefaultValue(); // 返回null
Console.ReadKey();
}
}
public class MyGenericClass<T> where T : default
{
public T DefaultValue()
{
return default(T);
}
}
(8) 多个约束时用逗号隔开,new()始终在最后。
internal class Program
{
private static void Main(string[] args)
{
MyClass<int, Stream, int, FileStream, Person, int, int> m = new MyClass<int, Stream, int, FileStream, Person, int, int>();
m[0] = 100;
Console.ReadKey();
}
}
internal class MyClass<T, K, V, W, X, Y, Z>
where T : struct //值
where K : class //引用
where V : IComparable //接口
where W : K //W为K或K的子类
where X : class, new()//多约束用逗号隔开
{
private T[] _data = new T[5];
public T this[int index]
{
get { return _data[index]; }
set { _data[index] = value; }
}
}
internal class Person
{
public string Name { get; set; }
}
(9)泛型类、泛型方法、泛型接口、泛型委托。
前三者都学了,后面简单说明一下泛型委托:
委托是一个可用于封装方法的类型,而泛型委托则可以用于封装泛型方法。
泛型委托定义时可以指定泛型参数,使得委托类型能够适应不同类型的参数传递。
泛型委托示例,MyGenericDelegate 为泛型委托类型:
public delegate T MyGenericDelegate<T>(T x, T y);
public static class Calculator
{
public static int Add(int x, int y)
{
return x + y;
}
public static double Multiply(double x, double y)
{
return x * y;
}
}
internal class Program
{
private static void Main(string[] args)
{
MyGenericDelegate<int> intDelegate = Calculator.Add;
MyGenericDelegate<double> doubleDelegate = Calculator.Multiply;
int intResult = intDelegate(3, 4);
Console.WriteLine("Add result: " + intResult);
double doubleResult = doubleDelegate(2.5, 3.2);
Console.WriteLine("Multiply result: " + doubleResult);
Console.ReadKey();
}
}
五、foreach循环-枚举器
1、为什么可以用foreach进行枚举集合或者数组中的元素呢?
因为foreach只是一个简单的傀儡,它能枚举元素,真正起作用的是里面的一个叫
GetEnumerator枚举器的东西。
只要有枚举器的方法,那么foreach就能起作用、进行枚举元素。
2、注意观查下面:
internal class Program
{
private static void Main(string[] args)
{
int[] n = new int[] { 1, 3, 5, 7 };
foreach (var item in n)
{
Console.WriteLine(item + ",");
}
Console.WriteLine("=============");
ArrayList al = new ArrayList() { "a", "b", "c", "d" };
foreach (var item in al)
{
Console.WriteLine(item + ",");
}
Console.WriteLine("=============");
List<string> list = new List<string>() { "aa", "bb", "cc" };
foreach (var item in list)
{
Console.WriteLine(item + ",");
}
Console.WriteLine("=============");
Person p = new Person();
for (int i = 0; i < p.Count; i++)
{//索引器
Console.WriteLine(p[i]);
}
Console.WriteLine("=============");
foreach (var item in p) //出错
{//P不含GetEnumerator,不能使用foreach
Console.WriteLine(item);
}
Console.ReadKey();
}
}
internal class Person
{
private int[] _n = new int[] { 11, 22, 33, 44 };
public int Count
{
get { return _n.Length; }
}
public int this[int index]
{
get { return _n[index]; }
}
}
上面最后的Person类中不含GetEnumerator,所以使用foreach出错。
而前面的int[],ArrayList,List等自带GetEnumerator,故能用foreach
(按F12查看定义中是否有GetEnumerator)
foreach只是一个简化遍历元素的一个写法,真正起作用的是GetEnumerator。
同样的道理,for是因为里面加了一个叫索引器的东西,才能使用for.
3、如何枚举下面中的元素?
internal class Person
{
private string[] Friends = new string[] { "雍正", "康熙", "乾隆", "李世明" };
}
要用foreach枚举,就需要用IEnumerable接口。加入这个接口,并观察里面有什么:
internal class Person:IEnumerable
{
private string[] Friends = new string[] { "雍正", "康熙", "乾隆", "李世明" };
public IEnumerator GetEnumerator()
{
throw new NotImplementedException();
}
}
发现实现了一个叫GetEnumerator的方法,根据上面知道,这个就是枚举的本质,因此,
我们删除那个接口IEnumerable,保留这个方法(吃了糖衣,退回炮弹)。
internal class Person
{
private string[] Friends = new string[] { "雍正", "康熙", "乾隆", "李世明" };
public IEnumerator GetEnumerator()//返回类型IEnumerator,即枚举器
{
throw new NotImplementedException();//a 重点在这里写东西...
}
}
重点是写一个返回类型是枚举器的东西,使用这个枚举器的接口来实现它:
写上class PersonEnumerator:IEnumerator,按Alt+Shift+F10来实现这个接口,自动完成
后的代码如下:
class PersonEnumerator : IEnumerator
{
public object Current => throw new NotImplementedException();//当前位置
public bool MoveNext() //向下移动游标,相当于下一个索引
{
throw new NotImplementedException();
}
public void Reset() //重置 复位到开始
{
throw new NotImplementedException();
}
}
上面的代码,就是一个规范动作,它告诉编译器,如何重置,如何移动游标,如何显示
当前元素,这三个就完成了整个枚举遍历动作,我们无须做任何操作,只需要完成这三
个基础的动作,编译器就知道该怎么做了。
结论:要foreach就是要有GetEnumerator,GetEnumerator就是返回一个类,这个类只
需要完成三个基础动作:重置、移动、当前。这样就可以foreach遍历了
三个基础动作,就是把原来的元素传过来,进行操作。最终的这个类(枚举器)就是:
internal class Program
{
private static void Main(string[] args)
{
Person p = new Person();
foreach (var item in p)
{ Console.WriteLine(item); }
Console.ReadKey();
}
}
internal class Person
{
private string[] Friends = new string[] { "雍正", "康熙", "乾隆", "李世明" };
public IEnumerator GetEnumerator()
{ return new PersonEnumerator(this.Friends); }
}
internal class PersonEnumerator : IEnumerator
{
private string[] _friends;
private int _index = -1;//初始位置
public PersonEnumerator(string[] s)
{ _friends = s; }
public object Current
{
get
{
if (_index == -1 || _index >= _friends.Length)
throw new InvalidOperationException();
return _friends[_index];
}
}
public bool MoveNext()
{ return ++_index < _friends.Length; }
public void Reset()
{ _index = -1; }
}
问题:上面foreach (var item in p)中var推断后,为什么item是object类型??
答:var已经推断出来了,它是根据枚举器中的public object Current里面来
判断的,因为它已经指明了返回是object,故它只能推断成object.
同理Hashtable,Dictionary等里面的Current类型也将决定var推断出的
类型。
问题:public object Current返回类型只能是object吗?
答:是的,只要是IEnumerator接口,它的标准写法就是必须是object,虽然其它
返回类型写法也可以,但不能实现IEnumerator接口(将报错)。
有了foreach,编译器会自动调用上面三个功能,而不是下面这种:
private static void Main(string[] args)
{
Person p = new Person();
//foreach (var item in p)
//{ Console.WriteLine(item); }
IEnumerator etor = p.GetEnumerator();
while (etor.MoveNext())
{
Console.WriteLine(etor.Current);
}
//若还要第二次遍历上面,还得复位
etor.Reset();
while (etor.MoveNext())
{
Console.WriteLine(etor.Current);
}
Console.ReadKey();
}
还有一步一步地控制,同时还得注意复位,有了foreach,只要三个功能齐全,
那么就会自动遍历,自动复位,不会出繁杂。
观察上面编译情况

实际也是用三个基础功能。
上面是标准写法,写出一个枚举器的类,参数由原来的类传到枚举器中。
当然也可以把类本身也当作一个枚举器,只要它也实现了枚举器接口。例如:
internal class Program
{
private static void Main(string[] args)
{
Person p = new Person();
foreach (var item in p)
{ Console.WriteLine(item); }
Console.ReadKey();
}
}
internal class Person : IEnumerator
{
private string[] Friends = new string[] { "雍正", "康熙", "乾隆", "李世明" };
private int _index = -1;//初始位置
public IEnumerator GetEnumerator()
{ return this; }
public object Current
{
get
{
if (_index == -1 || _index >= Friends.Length)
throw new InvalidOperationException();
return Friends[_index];
}
}
public bool MoveNext()
{ return ++_index < Friends.Length; }
public void Reset()
{ _index = -1; }
}
虽然少了些代码,但这不是推荐的写法。
4、标准枚举器
标准枚举器(Enumerator)是一种实现了 IEnumerator 接口的对象,它可以遍历
一组元素。标准枚举器通常用于遍历集合,例如数组、列表或字典等。
标准枚举器实现了 IEnumerator 接口,该接口定义了以下方法:
MoveNext():将枚举器移到集合的下一个元素,如果成功移动则返回 true,
否则返回 false。
Reset():将枚举器重置到集合的开头。
Current:获取集合中当前位置的元素。
foreach 循环使用标准枚举器遍历集合中的元素。使用标准枚举器的好处是,
它提供了一种通用的方式来遍历集合,无论集合的类型如何,遍历方法都是
一样的。
除了标准枚举器之外,C# 还支持其他类型的枚举器,例如 yield 值枚举器和
异步枚举器。这些枚举器通常用于处理大型数据集或异步操作等场景。
private static void Main(string[] args)
{
int[] numbers = { 2, 4, 6, 8, 10 };
// 创建一个标准枚举器
IEnumerator enumerator = numbers.GetEnumerator();
// 使用 MoveNext() 方法来遍历所有元素
while (enumerator.MoveNext())
{
// 使用 Current 属性获取当前元素的值
int number = (int)enumerator.Current;
Console.WriteLine(number);
}
Console.ReadKey();
}
上面用了移动游标来遍历,显示下面再次遍历,不会发生:
private static void Main(string[] args)
{
int[] numbers = { 2, 4, 6, 8, 10 };
IEnumerator enumerator = numbers.GetEnumerator(); // 创建一个标准枚举器
while (enumerator.MoveNext()) // 使用 MoveNext() 方法来遍历所有元素
{
int number = (int)enumerator.Current; // 使用 Current 属性获取当前元素的值
Console.WriteLine(number);
}
while (enumerator.MoveNext())
{
int number = (int)enumerator.Current;
Console.WriteLine(number);
}
Console.ReadKey();
}
因为第二次之前的游标已经到了最末,下次移动时会直接为假而跳出,不会遍历。
但是,若是foreach则会每次自动遍历前,游标回到最前。故第2次foreach仍会遍历。
5、问:for循环实际是利用里面的索引器进行访问,如果没有索引器则无法使用for?
答:这个说法也不太准确。for 循环是一种基于计数器的循环结构,它可以在一个
指定的范围内循环执行语句块。for 循环的三个语句表达式分别控制了循环的初始
值、循环条件和循环迭代方式,其中初始值和迭代方式都可以是任何合法的语句,
不一定是对索引器的访问。
for (int i = 0; i < 10; i++)
{
Console.WriteLine(i);
}
上面并没有使用任何索引器,只是使用一个整型变量 i 来控制循环的次数。
初始值为 0,循环条件为 i 小于 10,循环迭代方式为每次将 i 的值增加 1。
索引器是一种特殊的属性,它定义了一种通过下标(即索引)访问对象内部元素
的方式。在 C# 中,我们可以使用索引器来访问数组、列表、字典等集合类型中
的元素。如果一个对象没有定义索引器,它仍然可以在 for 循环中使用,只是
不能通过索引器访问内部元素而已。
因此,for 循环与索引器并没有必然联系,它们是两个独立的概念。for 循环是
C# 中最基本的循环结构之一,可以用于控制任何计数器类型的循环,而索引器
只是一种访问属性的特殊方式。
6、问:为什么泛型枚举接口实现时会有两个GetEnumerator?
答:输入class Person : IEnumerable<string>按Alt+Shift+F10进行实现接口,
会出现下面:
internal class Person : IEnumerable<string>
{
public IEnumerator<string> GetEnumerator()
{
throw new NotImplementedException();
}
IEnumerator IEnumerable.GetEnumerator()
{
throw new NotImplementedException();
}
}
出现了两个GetEnumerator,是什么原因?
对第一行IEnumerable<string>按F12,可以看到它实现泛型版本的GetEnumerator,
同时,这个还继承于IEnumerable接口,继续对这个IEnumerable按F12查看定义,
发现里面就是上面代码中显示实现的的IEnumerable.GetEnumerator
因此泛型版本是继承于原来的IEnumerable,所以会有两个GetEnumerator。
一个是隐式,一个是显式。
因此,只是是泛型枚举接口就必须实现两个接口,缺一不可。
这种方式的好处在于,当一个容器对象支持多种类型元素时,可以实现多个IEnumerator
接口来支持不同的遍历方式。
例如,在一个包含不同类型图形的集合中,可以实现一个返回所有图形对象的枚举
器,另一个返回仅包含矩形的枚举器。在这种情况下,可以用类似上面的技术实现不同
的 GetEnumerator() 方法来区分这些不同的遍历方式。
注意,对于类内部来说,两个 GetEnumerator() 方法可以使用同名的方法名,因
为它们的 signatures 是不同的。但是对于类外部使用时,需要根据用到的具体类型来
调用对应的方法。例如,当 Person 对象被强制转换为 IEnumerator 接口时,需要使
用 IEnumerable.GetEnumerator() 方法来遍历集合元素,而不能使用泛型的
GetEnumerator() 方法。
7、问:使用两个接口,这两个接口中的方法完全一样,如何在类中区别?
答:若这两个方法仅方法名相同,其它不同,即签名不同,则此时会用重载来区分。
若完全一样,则需要用显示来区分。如下面:
internal interface IF1
{
void Face();
}
internal interface IF2
{
void Face();
}
internal class MyClass : IF1, IF2
{
void IF1.Face()
{
Console.WriteLine("IF1的方法");
}
void IF2.Face()
{
Console.WriteLine("IF2的方法");
}
}
internal class Program
{
private static void Main(string[] args)
{
MyClass mc = new MyClass();
((IF1)mc).Face();
((IF2)mc).Face();
Console.ReadKey();
}
}
IF1 和 IF2 接口都定义了一个 Face() 方法。MyClass 类实现了这两个接口,并
使用显式接口实现语法来实现这两个方法。由于这两个方法具有不同的接口名称和方
法名称,因此它们是不同的方法,并且在 MyClass 类中可以同时存在.
在调用 MyClass 中的 Face() 方法时,需要显式使用接口名称来调用相应的
方法,以便区分.
注意,使用这种方式,这两个方法在MyClass类中都是私有的,不能从MyClass类
的外部访问它们。只能通过显式接口实现语法的方式访问它们,以解决方法重名问题。
8、问:为什么foreach只能用于只读的集合或数组?
答:根据前面知识,知道foreach需要枚举器GetEnumerator返回,而枚举器三个功能
中的一个Current()方法,只有一个Get(可读),而没有Set(可写)。
因此它只能是只读的。
9、yield[jiːld]产生(收益、效益等);
yield return 表达式; (不断产生,直接循环结束)
yield break; (中断产生,跳出)
当yield语句所在的方法的返回值为IEnumerable<T>时,表示自动生成一个可选代类型。
当yield语句所在的方法的返回值为IEnumertor<T>时,表示自动生成一个选代器。
通过yield快速为某类型创建正向与反向选代器。
例1:迭代产生IEnumerable.
internal class Program
{
private static void Main(string[] args)
{
Person p = new Person();
foreach (var s in p.GetAllObject()) //a 这里var推荐什么类型?
{
Console.WriteLine(s);
}
Console.ReadKey();
}
}
internal class Person
{
private string[] Friends = new string[] { "雍正", "康熙", "乾隆", "李世明" };
public IEnumerable GetAllObject()
{
for (int i = 0; i < Friends.Length; i++)
{
yield return Friends[i];
}
}
}
yield关键字被用于生成器函数中,用于创建一个迭代器对象,该迭代器可以产出一
系列值。当迭代器每次迭代时,yield语句会生成一个值,返回给调用方。同时,生
成器函数的当前执行状态也会被保存下来,以便在下一次迭代时恢复执行。yield关
键字能够帮助简化迭代器的实现,使得在不需要一次性计算出所有值的情况下,能
够按需产生序列中的下一个值。
因此,上面代码使用 foreach 循环来迭代并显示序列中的每个元素。在每次循环中,
foreach 语句会自动迭代到下一个序列元素,直到序列中的所有元素都被枚举完毕。
通过这种方式,我们可以使用一个非常简单的函数来创建一个可迭代的序列,而不必
写更加复杂的代码来维护序列的状态和生成下一个元素。
反编译上面:

可以看到实际上使用yield return后产生了一个sealed class,它自己有枚举接口,
枚举器,current类型为object(故上面的a处var推荐为object),同时也还有基础
的三个功能。
例2:换一种写法,用枚举器
internal class Program
{
private static void Main(string[] args)
{
Person p = new Person();
foreach (var s in p) //b 这里var推荐是什么类型?
{
Console.WriteLine(s);
}
Console.ReadKey();
}
}
internal class Person
{
private string[] Friends = new string[] { "雍正", "康熙", "乾隆", "李世明" };
public IEnumerator GetEnumerator()
{
for (int i = 0; i < Friends.Length; i++)
{
yield return Friends[i];
}
}
}
这个是用yield来产生枚举器。所以foreach也能直接使用。
反编译后:

实际上也是生成一个自身就是枚举器的密封类,current也是object。
结论:foreach要运行就必须要有GetEnumerator()方法.
例2中p中直接就有GetEnumerator(),所以直接在foreach中用p.
而例1中的foreach不能直接使用p,因为Person中没有GetEnumerator()方法.
它进行了变化,用GetAllObject()方法,返回了IEnumerable类型,同时根据前面
的反编译,这个返回的类型自身还是枚举器(还包括泛型版本),所以这个方法
是可以用在foreach中的。故例1中foreach用的是p.GetAllObject().
10、问:yield在迭代时内部是怎么操作的?
答:看一下yield break的情况。类型于while中的contiue与break。
private static void Main(string[] args)
{
foreach (var arg in GetElem())
{
Console.WriteLine(arg);
}
Console.ReadKey();
}
private static IEnumerable<int> GetElem()
{
int i = 0;
while (true)
{
if (i > 10)
{
yield break;//跳出
}
else
{
i++; //a
yield return i;//b
}
}
}
当i>10时自动跳出。因此返回的集合就是1-11.
它内部怎么操作的呢?
如果把上面a句放在b句后面,返回的集合又是什么呢?
在使用 yield return 的迭代器函数中,当执行到 yield return 时,函数会返回当
前的值,然后暂停执行并保存函数的当前状态。当下一次迭代开始时,函数会从之前
保存的状态继续执行,直到遇到下一个 yield return 的位置,然后又再次将函数的
状态保存,并返回值。
当执行 yield return i; 时,函数会返回 i 的当前值,然后暂停并保存其状态。当
再次迭代时,函数会从保存的状态继续执行,执行 i++ 语句将i 的值增加 1。由于
foreach 循环仍在访问迭代器,因此函数必须等到下一次foreach 迭代开始时,才会
再次执行 yield return 返回下一个值。
i++ 的作用与普通的函数相同,每次迭代时都会将 i 的值增加 1。而在迭代器中,
返回值的行为与普通函数不同,因为函数会将状态保存,等待下一次迭代开始时再
次执行。
因此,若调整到b后,最先执行yield return 0,显示0.然后继续回到迭代中,使用保
存好的i=0,并i++为1,接下来yield return 1,再次回到main中的foreach。然后又到
GetElem()中使用保存好的i=1,再i++为2,....如此循环
到i=11时,就会跳出。结果为0-10.
11、反向迭代
与正向迭代器类似,只是多了一个从后向前返回值的过程。
private static void Main(string[] args)
{
foreach (var arg in ReverseString("HelloWorld"))
{
Console.WriteLine(arg);
}
List<char> list = ReverseString("China").ToList();
Console.WriteLine(list.ToArray());
Console.ReadKey();
}
private static IEnumerable<char> ReverseString(string str)
{
for (int i = str.Length - 1; i >= 0; i--)
{
yield return str[i];
}
}
上面定义了一个名为 ReverseString 的迭代器函数,它需要一个字符串作为输入。
在这个迭代器函数中,从字符串的末尾开始,逐个返回字符串中的每一个字符。
具体来说,我们使用 for 循环来迭代字符串中的每一个字符,然后使用 yield
return 语句将字符逆序返回。在 for 循环执行完毕后,迭代器函数也就结束了。
在迭代器函数中,由于使用了 yield return,因此在每次返回一个字符后,函
数就会暂停并保存当前的状态。然后,当下一次迭代开始时,函数会从之前保存
的状态继续执行,并依次返回字符串中的后续字符。最终的结果就是一个反向输
出字符串中所有字符的迭代器。
当使用这个迭代器进行迭代时,我们可以调用 foreach 循环来逐一输出迭代结果
或者先使用 ToList() 方法将该 IEnumerable<char> 类型的迭代器转换成集合后
再输出。
后面使用 ToList() 方法可以将一个 IEnumerable 序列转换为 List<T>,以便
在使用迭代器函数的同时也能充分利用常规的列表操作。
迭代器函数 ReverseString() 的执行结果使用 ToList() 方法转换成 List<char>
类型的集合。并再次转为数组进行输出。
注意,使用 ToList() 方法会将整个迭代器的执行结果一次性计算出来,并保存
在集合中,因此如果迭代器函数的数据量非常大,可能会导致程序的内存占用非
常高。在这种情况下,可以考虑使用其他的集合类型,如 LinkedList 或 Queue,
以使内存占用更加可控。
12、问:枚举器与迭代器的区别是什么?
答:迭代器和枚举器都是用于遍历集合类的代码块,它们的功能极其相似。
区别在于迭代器是通过 yield return 语句来实现的;
而枚举器则实现了特定的接口并提供 Current 和 MoveNext 方法。
private static void Main(string[] args)
{
foreach (int i in GetSomeIntegers())// 使用迭代器遍历
{ Console.Write("{0} ", i); }
// 使用枚举器遍历
SomeIntegers someIntegers = new SomeIntegers();
IEnumerator<int> enumerator = someIntegers.GetEnumerator();
while (enumerator.MoveNext())
{ Console.Write("{0} ", enumerator.Current); }
Console.ReadKey();
}
private static IEnumerable<int> GetSomeIntegers()
{
for (int i = 0; i < 10; i++)
{
yield return i;//该迭代器能够返回一组整数。
}
}
public class SomeIntegers : IEnumerable<int>
{
private int[] numbers = { 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 };
public IEnumerator<int> GetEnumerator()
{ return new Enumerator(numbers); }
IEnumerator IEnumerable.GetEnumerator()
{ return GetEnumerator(); }
private class Enumerator : IEnumerator<int> //内部类
{
private int[] numbers;
private int position = -1;
public Enumerator(int[] numbers)
{ this.numbers = numbers; }
public int Current
{ get { return numbers[position]; } }
object IEnumerator.Current //不能省
{ get { return Current; } }
public void Dispose()
{ }
public bool MoveNext()
{ position++; return (position < numbers.Length); }
public void Reset()
{ position = -1; }
}
}
上面两种方式进行遍历时,可以得到相同的遍历结果。
注意,在真正的开发中,为了代码的易读性和简洁性,更推荐使用迭代器而不是枚举器。
13、迭代器yield return返回的类型,只能是IEnumerable或IEnumerable<T>两种吗?
答:使用 yield return 语句实现的迭代器,其返回类型只能是 IEnumerable 或
IEnumerable<T> 类型中的一种。
这是因为使用 yield return 实现的迭代器实际上是一个 yield 状态机,它在执行过
程中会一步一步地返回值,通过 yield return 的方式将这些值传递给调用方,然后
暂停执行等待下一次调用。由于每次调用只会返回一个值,因此返回类型必须是可枚
举的,而 IEnumerable 或 IEnumerable<T> 正好满足这一点。瞌睡来了正好有枕头。
注意,尽管迭代器实现了 IEnumerable 或 IEnumerable<T> 接口,但返回类型并不
一定要显式地声明为这两种接口,可以使用类似于 yield return 的隐式类型推断。
private static void Main(string[] args)
{
foreach (var i in GetSomeValues())
{ Console.Write(i); }
Console.ReadKey();
}
private static IEnumerable GetSomeValues()
{
yield return "Hello";//a
yield return "World";//b
yield return "!";//c
}
上面返回类型未显式地声明为 IEnumerable 或 IEnumerable<T>,但是由于使用了
yield return 语句,编译器会将其自动推断为 IEnumerable。这种隐式类型推断
可以使代码更加简洁易读。
注意,迭代器的返回类型如果是IEnumerable,那么返回的元素类型默认为object。
如果需要返回指定类型的元素,必须将返回类型显式声明为 IEnumerable<T>。
提示:分别在上面a,b,c三处下断点,执行时,会依次在三者中断,已经执行过的下
一次不会再进行执行(中断)。因为这个执行“状态”,函数自动保存并跳过。
迭代器返回类型的推断方式,通常用于返回简单的类型,如字符串、整数等。
private static void Main(string[] args)
{
foreach (var i in GetNumbers())//var自动与IEnumerable<int>匹配
{ Console.Write(i); }
Console.ReadKey();
}
public static IEnumerable<int> GetNumbers()
{
yield return 1;//yield自动推断与IEnumerable<int>匹配
yield return 2;
yield return 3;
}
由于函数的返回类型是 IEnumerable<int>,并且使用了 yield return 语句返回了
整数,因此编译器会自动推断出这个函数的返回类型必须是 IEnumerable<int>。
更改上例的迭代器为集合:
public static IEnumerable<int> GetNumbers()
{
return new List<int>() { 1, 2, 3 };
}
上面直接使用了 return 语句返回了一个整数列表,这样函数的返回类型就明确地
指定为了 IEnumerable<int>。
注意,即使使用了 List<int> 类型,但由于它实现了 IEnumerable<int> 接口,
因此函数的返回类型依然是 IEnumerable<int>。(按F12可查看情况)
注意,虽然使用类型推断可以让代码更加简洁,但有时也会导致一些问题,例如不正
确的类型推断、性能问题等。因此,在选择使用类型推断时,应该理性权衡其利弊。
14、作业:写一个Person类,根据前面两种迭代方式进行枚举。
internal class Program
{
private static void Main(string[] args)
{
Person p = new Person();
foreach (var arg in p)
{
Console.WriteLine(arg);
}
foreach (var arg in p.GetAll())
{
Console.WriteLine(arg);
}
IEnumerable obj = p.GetAll();
foreach (var arg in obj)
{
Console.WriteLine(arg);
}
Console.ReadKey();
}
}
internal class Person
{
private int[] _age = new int[] { 11, 12, 13, 14, 15 };
public IEnumerator GetEnumerator()
{
for (int i = 0; i < _age.Length; i++)
{
yield return _age[i];
}
}
public IEnumerable<int> GetAll()
{
for (int i = 0; i < _age.Length; i++)
{
yield return _age[i];
}
}
}
七、文件操作
1、File类:提供用于创建、复制、删除、移动和打开单一文件的静态方法,
并协助创建 FileStream 对象。
Directory类:公开用于通过目录和子目录进行创建、移动和枚举的静态方法。
此类不能被继承。
System.IO.DirectoryInfo CreateDirectory (string path);
在指定路径中创建所有目录和子目录,除非它们已经存在。因此不会覆盖。
void Delete(string path,bool recursive)
删除目录,recursive表示是否递归删除,如果recursive为false则只能
删除空目录.
Delete(String)只能删除空目录,否则异常。
警告:此删除不会提示,在回收站也不会有。
private static void Main(string[] args)
{
for (int i = 0; i < 5; i++)
{
Directory.CreateDirectory(@"E:\" + i);
}
File.Create(@"E:\1\1.txt");
for (int i = 0; i < 5; i++)
{
Directory.Delete(@"E:\" + i, true);//子目录有文件,参数true
}
Console.ReadKey();
}
问:上面看似正确,但实际中老是报错,什么原因?
答:上面虽然用了true避免了子目录有文件的常见错误。但是:
File.Create操作时,系统会分配一个文件句柄给这个文件,而这个文件
句柄会一直存在,直到该文件被关闭或者程序退出。所以,当你试图删
除这个子目录时,系统会提示“正在使用”,因为文件句柄仍然在使用中。
解决方法:
(1)在使用完文件后,显式地关闭文件句柄,以释放文件句柄。
(2)等待一段时间,直到文件句柄自动关闭或超时。
(3)使用“using”语句,在文件操作完毕后自动关闭文件句柄。
提示:File.Create()返回的是FileStream类型
例:用using
using (FileStream fs = File.Create(@"E:\1\1.txt"))
{
// 执行文件操作
}
例:显式关闭
FileStream fs = null;
try
{
fs = File.Create(@"E:\1\1.txt");
// 执行文件操作...
}
finally
{
if (fs != null)
{
fs.Close(); // 显式关闭文件句柄
}
}
bool Exists(string path) 判断目录是否存在
string[] GetDirectories(string path) 得到一个目录下的子目录
string[] GetDirectories(string path, string searchPattem,
SearchOption searchoption)
通配符查找自录下的子目录,可以搜索到隐藏文件。
最后一个选项可指明是当前目录下的子目录,还是所有子目录。
string sourcePath = @"E:\Look";
if (Directory.Exists(sourcePath))
{
string[] files = Directory.GetDirectories(sourcePath, "*.*", SearchOption.AllDirectories);
foreach (string file in files)
{
Console.WriteLine(file);
}
}
static string[] GetFiles(string path) 得到一个目录下的文件
string[] GetFiles(string path, string searchPattern,
SearchOptionsearchOption)
通配符查找目录下的文件
Directorylnfo GetParent(string path) 得到目录的父目录。
已经是驱动器根目录,则返回null.
move() //移动、剪切。只能在同一个磁盘中。目录没有Copy方法。
可以使用Move()方法实现重命名。
在不同磁盘移动时会提示出错:
private static void Main(string[] args)
{
Directory.CreateDirectory(@"E:\1");
FileStream fs = File.Create(@"E:\1\good.tmp");
fs?.Close();//必须关闭句柄if(fs!=null) fs.close();
Directory.Move(@"E:\1", @"F:\1");//报错:源路径和目标路径必须具有相同的根
Console.ReadKey();
}
解决办法:
要移动跨驱动器的文件或文件夹,需要使用 Directory.GetFiles 和Copy方
法来逐个复制文件,然后使用 File.Delete 和 Directory.Delete 方法删
除原始文件和文件夹。
例:移动到不同驱动器时模板:
private static void Main(string[] args)
{
string sourcePath = @"E:\1";
string destinationPath = @"F:\1";
if (Directory.Exists(sourcePath))
{
string[] files = Directory.GetFiles(sourcePath, "*.*", SearchOption.AllDirectories);
foreach (string file in files)
{
string relativePath = file.Substring(sourcePath.Length);
string destinationFile = destinationPath + relativePath;
Directory.CreateDirectory(Path.GetDirectoryName(destinationFile));
File.Copy(file, destinationFile, true);
}
Directory.Delete(sourcePath, true);
}
Console.ReadKey();
}
上面目标文件夹,更改成其它名字,就起到更名作用。
在同一驱动器,直接用move就可以实现更名。
注意:上面实际一直操作的是文件File,如果是操作目录Directory,那么
用Directory.GetDirectories()
2、DirectoryInfo类:公开用于创建、移动和枚举目录和子目录的实例方法。
此类不能被继承。用来描述一个文件夹对象。
获取指定目录下的所有目录时,返回DirectoryInfo数组。
DirectoryInfo directoryInfo = new DirectoryInfo(directoryPath);
DirectoryInfo[] subDirectories = directoryInfo.GetDirectories("test*");//通配符
FileInfo类:提供用于创建、复制、删除、移动和打开文件的属性和实例方法,
并且帮助创建 FileStream 对象。 此类不能被继承。
用来描述一个文件对象。
获取指定目录下的所有文件时,返回一个FileInfo数组。
DirectoryInfo directoryInfo = new DirectoryInfo(directoryPath);
FileInfo[] files = directoryInfo.GetFiles("*.*");
3、问:File类与FileInfo的区别是什么?
答:File类是静态类,FileInfo是实例类.
两者提供了对文件的访问和操作,若只需要进行文件操作,如读写、复制、删
除等,可以使用 File 类的静态方法;如果需要对文件进行更多的操作,如获
取文件信息、操作文件属性等,则可以使用 FileInfo 类。
//File类的操作
string[] lines = File.ReadAllLines("file.txt");// 读取文件所有行
File.AppendAllText("file.txt", "new line"); // 追加文本到文件末尾
File.Copy("source.txt", "dest.txt"); // 复制文件
File.Delete("file.txt"); // 删除文件
//FileInfo类的操作
FileInfo fileInfo = new FileInfo("file.txt"); // 创建一个 FileInfo对象
if (fileInfo.Exists)// 检查文件是否存在
{
DateTime creationTime = fileInfo.CreationTime;//获取文件创建时间
long fileSize = fileInfo.Length; // 获取文件大小
string[] lines = File.ReadAllLines(fileInfo.FullName);//读取文件所有行
fileInfo.Delete();// 删除文件
}
4、问:Directory类与DirectoryInfo类的区别是什么?
答:同上面一样,Directory是静态类,DirectoryInfo是实例级别的类。
两者都提供了操作目录的方法和属性,若只需要进行目录操作,如创建、删除、
移动等,可以使用 Directory 类的静态方法;如果需要对目录进行更多的操作,
如获取目录信息、操作目录属性等,则可以使用 DirectoryInfo 类。
//Directory类的操作
Directory.CreateDirectory("directory");// 创建目录
Directory.Delete("directory");// 删除目录
Directory.Move("source", "dest");// 移动目录
bool exists = Directory.Exists("directory");// 判断目录是否存在
//DirectoryInfo类的操作
DirectoryInfo directoryInfo = new DirectoryInfo("directory");//创建一个 DirectoryInfo 对象
DateTime creationTime = directoryInfo.CreationTime;//获取目录创建时间
FileInfo[] files = directoryInfo.GetFiles(); //获取所有文件
directoryInfo.Delete(); // 删除目录
5、Path类:
对文件或目录的路径进行操作(很方便),实际操作的是字符串。
目录和文件操作的命名控件System.IO
string p = @"D:\Program Files\Fiddler\license.txt";
Console.WriteLine(Path.GetFileName(p));
Console.WriteLine(Path.GetExtension(p));
Console.WriteLine(Path.GetFileNameWithoutExtension(p));
Console.WriteLine(Path.GetDirectoryName(p));
Console.WriteLine(Path.ChangeExtension(p, "dll"));//有点无点皆可
string ChangeExtension(string path, string extension)
修改文件的后缀,"修改"支持字符串层面的,没有真的给文件改名。例:
string s = Path.ChangeExtension(@"C:\empiF3.png","jpg")
string Combine(string path1, string path2)
将两个路径合成一个路径,比用+好,可以方便解决不加料线的问题,自动处理
路径分隔符的问题。
string s = Path.Combine(@'c:\temp","a.jpg")
前提是,两个路径都就应是合法的路径。
string s1 = @"c:\abc\x\y";
string s2 = @"hello.txt";
Console.WriteLine(s1 + s2);
Console.WriteLine(Path.Combine(s1, s2));//有或无\会自动判断添加
string GetDirectoryName(string path)
得到文件的路径名。Path.GetDirectoryName(@"c:\templa.jpg")
相对路径:若就在程序同一目录,前面无需用路径,直接引用文件名即可操作。
string s = "1.txt";
Console.WriteLine(File.ReadAllText(s));//程序当前目录
Console.WriteLine(Path.GetFullPath(s));
string s = @"c:\x\y\1.txt";//同目录下另一个文件路径的取法
Console.WriteLine(Path.Combine(Path.GetDirectoryName(s), "2.txt"));
string GetExtension(string path) 得到文件的扩展名(包括点号),无则返回Empty.
string GetFileName(string path) 得到文件路径的文件名部分
string GetFileNameWithoutExtension(string path) 得到去除扩展名的文件名
string GetFullPath(string path) 得到文件的全路径.可以根据相对路径获得绝对路径.
string GetTempPath() 得到临时文件夹的路径
该方法法返回操作系统指定的临时文件夹的路径,通常为 %TEMP% 环境变量指定的
路径。
在 Windows 操作系统中,%TEMP% 环境变量指向的是当前用户的临时文件夹路径,
而该路径又默认为 C:\Users\{Username}\AppData\Local\Temp。因此,临时文件
夹的路径并不是固定的,而是会随着操作系统和当前用户的不同而发生变化。
除了Path.GetTempPath方法以外,也可以使用Path.GetTempFileName方法来创建
一个唯一且临时的文件名,该方法会在默认的临时文件夹中创建一个文件并返回
该文件的完整路径。
注意,由于临时文件夹的路径可能随着操作系统或用户的不同而发生变化,因此
不要将重要文件存储到临时文件夹中,以免造成不必要的损失。
此方法按以下顺序检查环境变量是否存在,并使用找到的第一个路径:
(1)TMP 环境变量指定的路径。
(2)TEMP 环境变量指定的路径。
(3)USERPROFILE 环境变量指定的路径。
(4)Windows 目录。
string GetTempFileName() 得到一个唯一的临时文件名
在磁盘上创建一个唯一命名的零字节临时文件,并返回该文件的完整路径。
Console.WriteLine(Path.GetTempFileName());
结果返回C:\Users\dzwea\AppData\Local\Temp\tmp89E0.tmp
其中 tmp89E0 是一个以随机字符串为基础的唯一文件名,.tmp 是一个默认的
文件扩展名。
这样创建的临时文件名有一个非常重要的特点,就是它是唯一的,这可以避免
因为文件名冲突而导致的一系列问题。在创建了临时文件之后,就可以将需要
处理的数据写入到该文件中,使用完毕后,记得删除该临时文件以释放磁盘空
间。可以使用 System.IO.File.Delete 方法来删除临时文件。
private static void Main(string[] args)
{
string tempFilePath = Path.GetTempFileName();
try
{
// 将需要处理的数据写入到 tempFilePath 中
// ...
// 处理完毕后,删除临时文件
File.Delete(tempFilePath);
}
catch (Exception ex)
{
// 异常处理
Console.WriteLine(ex.Message);
}
Console.ReadKey();
}
注意,使用临时文件时需要确保以完全信任的方式处理其中的内容,以避免潜在
的安全风险。同时,请勿将重要的数据保存到临时文件中,以免被滥用。
问:GetTempFileName()生成的临时文件名是按什么规律命名的?
答:Path.GetTempFileName() 方法生成的临时文件名是按照以下规则进行命名:
(1)临时文件名具有一个唯一的文件名。它是由随机数和计数器组成。
(2)临时文件名具有一个 .tmp 扩展名。
(3)临时文件名是在默认的系统临时文件目录中创建的。
(4)临时文件名的格式为:
Path.GetTempPath() + "tmp" + Guid.NewGuid().ToString("N") + ".tmp"
其中:
Path.GetTempPath() 方法获取默认的临时目录路径
"tmp" 是文件名的前缀
Guid.NewGuid().ToString("N") 获取一个新的 GUID 字符串(不含连字符),
用于确保文件名的唯一性。
.tmp 是文件名的后缀
临时文件名中的计数器是通过添加数字的形式实现的。每当 GetTempFileName 方
法被调用时,都会对计数器自增。这就确保了 GetTempFileName 生成的文件名是
唯一的。
注意:由于临时文件名是随机生成的,不能对其格式进行假设或依赖。 文件名可
能会随着不同操作系统、用户或时间的变化而发生变化,在代码中必须以灵
活的方式处理。
string GetRandomFileName ()
返回随机文件夹名或文件名。
与不同的 GetTempFileName是, GetRandomFileName 不会创建文件。它仅返回一
个唯一的字符串。
6、stream类:文件流,抽象类。
FileStream类:文件流,MemoryStream(内存流),Networkstream(网络流)
streamReader类:快速读取文本文件
streamWriter类:快速写入文本文件
GZipstream
八、TreeView使用
1、TreeView是C#中的一种控件,用于显示层次数据(如文件和文件夹结构、组织结构等)。
它通常由一个根节点和多个子节点组成,用户可以通过展开和折叠节点来浏览层次数据。
// 创建TreeView控件
TreeView treeView1 = new TreeView();
treeView1.Size = new Size(200, 200);
// 添加根节点
TreeNode rootNode = new TreeNode("根节点");
treeView1.Nodes.Add(rootNode);
// 添加子节点
TreeNode childNode1 = new TreeNode("子节点1");
TreeNode childNode2 = new TreeNode("子节点2");
rootNode.Nodes.Add(childNode1);
rootNode.Nodes.Add(childNode2);
// 设置TreeView控件的显示样式
treeView1.CheckBoxes = true;
treeView1.ShowLines = true;
treeView1.ShowPlusMinus = true;
// 添加到窗体中
this.Controls.Add(treeView1);
上面先创建了一个TreeView控件,然后添加了一个根节点和两个子节点。
再设置TreeView控件的显示样式(包括是否显示复选框、连线、展开和折叠符号等),
最后将TreeView控件添加到窗体中。
TreeView控件的各种属性和方法来操作树形结构,例如:
TreeView.Nodes:获取树形结构的根节点集合;
TreeNode.Nodes:获取或设置节点的子节点集合;
TreeNode.Text:获取或设置节点的文本内容;
TreeNode.Checked:获取或设置节点是否选中;
TreeView.SelectedNode:获取或设置当前选中的节点;
TreeView.ExpandAll():展开所有节点;
TreeView.CollapseAll():折叠所有节点。
2、举例
例1:form中添加一个treeview控件,按下图增加:

代码:
private void button1_Click(object sender, EventArgs e)
{
treeView1.Nodes.Clear();//清空节点
}
private void button2_Click(object sender, EventArgs e)
{//添加根节点
string nodeName = txtName.Text.Trim();
TreeNode node = treeView1.Nodes.Add(nodeName);//返回节点类型
}
private void button3_Click(object sender, EventArgs e)
{//添加子节点
string nodeName = txtName.Text.Trim();
TreeNode node = treeView1.SelectedNode;
if (node != null)
{
node.Nodes.Add(nodeName);
}
else
{
MessageBox.Show("未选中节点!");
}
}
private void button4_Click(object sender, EventArgs e)
{//显示选中节点文本
if (treeView1.SelectedNode != null)
{
MessageBox.Show(treeView1.SelectedNode.Text);
}
}
private void button5_Click(object sender, EventArgs e)
{//删除节点
TreeNode node = treeView1.SelectedNode;
node?.Remove();
}
private void button6_Click(object sender, EventArgs e)
{//展开节点
TreeNode node = treeView1.SelectedNode;
//node?.Expand();//展开当前
node?.ExpandAll();//展开全部
}
private void button7_Click(object sender, EventArgs e)
{//折叠节点
TreeNode node = treeView1.SelectedNode;
node?.Collapse();
}
private void button8_Click(object sender, EventArgs e)
{//让节点可见,(附带展开到该节点处)
TreeNode node = treeView1.Nodes[3].Nodes[1].Nodes[0];
node.EnsureVisible();
node.BackColor = Color.Red;
}
例2:新建一个form,添加一个按钮,动态生成控件:
private void button1_Click(object sender, EventArgs e)
{
// 创建TreeView控件
TreeView treeView1 = new TreeView();
treeView1.Size = new Size(200, 200);
// 添加根节点
TreeNode rootNode = new TreeNode("根节点");
treeView1.Nodes.Add(rootNode);
// 添加子节点
TreeNode childNode1 = new TreeNode("子节点1");
TreeNode childNode2 = new TreeNode("子节点2");
rootNode.Nodes.Add(childNode1);
rootNode.Nodes.Add(childNode2);
// 设置TreeView控件的显示样式
treeView1.CheckBoxes = true;
treeView1.ShowLines = true;
treeView1.ShowPlusMinus = true;//为假时,通过双击来展开
// 添加到窗体中
this.Controls.Add(treeView1);
}
3、Tag 标记、标签
TreeView 中的 Node 对象有一个名为 Tag 的属性,它可以用来将自定义对象或数
据与节点相关联。
通过设置 Node 的 Tag 属性,我们可以将任何对象或数据与节点相关联,这些数
据或对象可以是一些额外的信息,比如某项任务的编号、排序位置、节点类型等。
Tag 属性的类型是 Object,因此你可以使用任何类型的对象作为其值。例如,
你可以将一个简单的字符串或数字存储在 Tag 中,也可以将一个对象或自定义类
型实例作为 Tag 的值。
private static void Main(string[] args)
{
TreeNode node1 = new TreeNode("节点1");// 创建节点并设置其 Tag 属性
node1.Tag = "这是节点1的 Tag 属性";
TreeNode node2 = new TreeNode("节点2");
node2.Tag = new { Name = "节点2自定义对象", Value = 100 };
TreeView treeView1 = new TreeView();//创建对象
treeView1.Nodes.Add(node1);// 将节点添加到 TreeView 控件中
treeView1.Nodes.Add(node2);
string tag1 = node1.Tag as string;// 获取节点 Tag 属性的值
Console.WriteLine("node1 的 Tag 属性值为:{0}", tag1);
//dynamic 类型表示变量的使用和对其成员的引用绕过编译时类型检查。 改为在运行时解析这些操作。
dynamic tag2 = node2.Tag;
Console.WriteLine("node2 的 Tag 属性值为:{0},{1}", tag2.Name, tag2.Value);
Console.ReadKey();
}
九、递归
1、函数执行时,入栈出栈过程是怎样的?
(1)调用函数时,在调用栈中为该函数分配一个栈帧;
(2)将函数参数的值复制一份到对应的栈帧中;
(3)将函数调用的返回地址和其他必要数据(如保存的寄存器、局部变量等)压入栈帧中;
(4)调用函数开始执行,按照语句的顺序执行函数体中的指令;
(5)如果函数有返回值,将返回值保存到对应的寄存器或栈帧中,并将栈帧出栈,恢复上
一个函数的状态;
(6)若函数执行完毕,则将栈帧出栈,恢复上一个函数的状态。
private static void Main(string[] args)
{
int a = 1; int b = 2;
int sum = Add(a, b);// 调用函数时,将函数参数的值保存在栈帧中
Console.WriteLine("sum = {0}", sum);
}
private static int Add(int x, int y)
{ // 压入调用函数的返回地址和其他必要数据
// 初始化函数的栈帧
// 参数 x 和 y 的值分别保存到栈帧中
int sum = x + y;
// 返回结果前,将栈帧出栈,恢复调用函数的状态
return sum;
}
上面调用 Add 函数并将 a 和 b 作为参数传递。在调用函数时,C# 会先在调用栈中
分配一个栈帧,并将 a 和 b 的值复制一份到栈帧中。函数开始执行后,会按照定
义在函数体内的指令对参数进行相关的操作,最终得到加法结果 sum,并将其保存
到栈帧中。返回结果前,函数会将栈帧出栈,恢复上一个函数的状态。
函数的参数和返回值的保存、入栈和出栈过程都是由编译器和操作系统自动处理的,
程序员只需要关注每个函数的具体实现即可。
问:栈帧是什么?有什么用?
答:在函数调用过程中,每个函数都会有自己的活动记录(Activation Record)或
栈帧(Stack Frame),存储着函数的参数、局部变量、返回地址等信息,以便在函
数调用结束后能够恢复之前的状态。可以将栈帧看作是函数在堆栈中的内存区域或
数据结构。
栈帧通常包括以下几部分:
(1)函数参数:保存调用函数时传递的参数值;
(2)返回地址:保存之前调用函数的执行位置;
(3)局部变量:保存函数内部定义的变量;
(4)控制信息:保存其他调用该函数所需的控制信息,例如异常处理信息、回调函数等。
在栈中,每个函数的栈帧都是按照 FILO(先进后出)的顺序压入栈中,被调用的函数
的栈帧先被压入栈中,调用结束后再将其出栈,以便恢复上一个函数的状态。
因此:栈帧主要用于保存函数的现场。
在 C# 中,每个函数在被调用时,会在调用栈中为该函数分配一个栈帧,栈帧
中保存了该函数执行过程中的所有信息,包括参数、局部变量、返回地址等内容。
当函数执行完毕后,该函数的栈帧将被弹出,之前被调用的函数的栈帧将被恢复,
程序将继续执行下去。
栈帧在函数调用过程中发挥了非常关键的作用,它可以保证函数执行过程
中的数据不会被其他函数或事件干扰,以及复原函数执行过程中的现场。换句
话说,栈帧主要用于保存函数的现场,确保函数执行的可重入性和可预测性。
注意,栈帧不仅仅用于保存函数执行现场,它同时也保存了函数调用的相关信
息,如函数参数、返回地址和其他必要数据。这些信息对于一个正常的函数调
用流程至关重要,缺失或者错误的信息可能会导致程序崩溃或者产生错误的行
为,因此需要谨慎处理栈帧中的信息。
2、递归时入栈出栈的过程是怎么的?
递归调用和普通函数调用的流程是类似的,也需要使用栈来保存程序状态和变量
值等信息。下面是阶乘递归调用时的入栈和出栈过程,以及涉及的栈帧变化情况。
int Factorial(int n)
{
if (n == 1) // 终止条件
return 1;
return n * Factorial(n - 1); // 递归调用
}
当调用Factorial(3)时,过程如下:
(1)初始为栈为空
(2)调用 Factorial(3) 函数,将该函数的返回地址和参数 n=3 压入栈中;
(3)进入 Factorial(3) 函数,新建一个栈帧,并在栈中压入该函数的返回地址
和参数 n=2
(4)进入 Factorial(2) 函数,新建一个栈帧,并在栈中压入该函数的返回地址
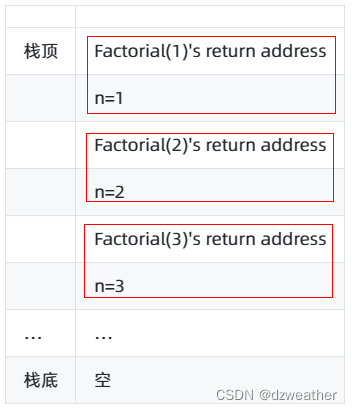
(5)进入 Factorial(1) 函数,满足终止条件,返回值 1 被压入栈中;

(6)Factorial(1) 函数出栈,返回值 1 被传递给 Factorial(2)

(7)Factorial(2) 函数出栈,返回值 2 被传递给 Factorial(3)

(8)Factorial(3) 函数出栈,最终的返回值 6 被传递给调用 Factorial(3) 函数
的部分。

通过这个过程我们可以看到:每次调用 Factorial 函数,都会将当前的函数参数
和返回地址等信息压入一个新的栈帧中,当递归调用结束时,栈顶的栈帧被弹出,
程序将返回到之前的调用位置,执行后续的语句。
注意,在递归调用的过程中,栈的大小会随着调用深度的增加而增大,因此需要
合理设置终止条件以免栈溢出。
3、在使用递归时,应注意哪些问题?
答:需要注意以下几点:
1.堆栈溢出问题:递归是通过不断压入新的方法调用到栈中实现的,如果递
归次数过多,栈就会爆满,导致堆栈溢出问题。为了避免这种情况,可以考虑限
制递归的最大深度,并在达到最大深度时改用迭代算法。
2. 推出递归的条件:递归函数必须有一个条件使之退出递归,否则程序将
可能陷入死循环。因此,在写递归函数时要确保有合适的退出条件。
3. 变量的作用域:每个递归调用都会创建一个新的方法栈帧,并复制所有
参数和本地变量。因此,在递归调用中定义的变量的作用域仅限于当前方法栈帧
中,而不是整个递归过程。
4. 调用顺序:递归函数直到最后一次调用结束后才开始返回。因此,在编
写递归函数时必须清楚理解递归“同时发生”的方式,避免出现潜在的逻辑错误。
5. 性能问题:递归调用通常比迭代算法效率低。因为调用栈的不断压入和
弹出会导致频繁的内存管理,在处理大数据量时可能会导致性能瓶颈。因此,在
使用递归时需要注意其对程序性能的影响。
4、问:是否推荐使用递归?
答:递归是一种非常有用的编程技巧,解决许多与树形或递归结构相关的问题
时非常方便。但是,对于某些问题,递归可能不是最高效的解决方案,特别是
在处理大型输入数据时它可能会造成性能问题。在此情况下,使用迭代算法可
能更加高效。因此,是否使用递归取决于解决方案的情况和性能要求。
总的来说,C#确实支持使用递归,但是需要在特定情况下使用。如果你在
构建一个需要跨越多个层次或层次嵌套的结构的算法或系统,那么可能需要使
用递归算法,在其他情况下可能需要考虑使用更高效的非递归算法。因此,需
要谨慎使用,考虑问题的复杂度和数据大小,并根据具体情况决定是否使用递
归来解决问题。
5、问:递归内部的局部变量如何处理?
答:每个递归调用都会创建新的方法栈帧,方法栈帧中包括每个方法调用的本
地变量。因此,递归中的局部变量的作用域仅限于当前方法栈帧中,而不是
整个递归过程中。
private static void Main(string[] args)
{
Recursion(3);
Console.ReadKey();
}
public static int Recursion(int n)
{
int count = 0;
if (n > 0)
{
count++;
Recursion(n - 1);
}
Console.WriteLine(count);
return n;
}
结果为0111,因为最后一次调用Recursion(0)时,没有进入if,输出是0,同
时也是条件终止时,然后依次出栈。
尽管后面有count++,但是程序总是输出1,而不是我们期望的递归调用的次
数3。因为每个递归调用中的count变量的作用域都仅限于当前方法栈帧中,每
次递归调用都会创建新的count变量,而前面的count变量则被压入栈中。因此,
最后输出的count变量是最后一次递归调用中定义的变量,值为1。
改进写法:
private static void Main(string[] args)
{
Recursion(3, 0);
Console.ReadKey();
}
public static int Recursion(int n, int count)
{
if (n == 0)
{
Console.WriteLine(count);
return n;//此处必须终止,否则溢出。
}
count++;
return Recursion(n - 1, count);
}
count参数而不是在函数中声明和更新变量。在每次递归调用时,我们同时更新
count变量的值,并将其传递给下一次递归调用。这确保了我们递归调用的次数
被正确地计算和输出。结果为3
小心上面的终止条件return n;无此句栈溢出。
6、问:递归终止条件的设置有哪些技巧?
答:必须为递归设置一个适当的终止条件,否则最终程序崩溃。终止条件设置技巧:
1. 边界检查:将可能导致递归无限循环的情况作为边界条件考虑。例如,
当遍历一个节点时,检查是否为null,如果是则终止递归。
2. 计数器:通过计数器或状态变量来追踪递归的深度,并在达到特定深度时
退出递归。这个技巧在遍历嵌套层次较深的数据结构时非常有用。
3. 双重递归/双向递归:使用双重递归或双向递归,即递归调用两个不同的
函数,以便递归继续进行直到两个函数都终止为止。这个技巧在求解问题时很常用。
4. 模式匹配:根据一些特定的规则匹配递归输入,并根据匹配结果来决定是
否继续递归。例如,在处理字符串时,我们可以使用模式匹配停止递归。
5. 剪枝:在递归过程中,如果发现当前状态无解或不符合问题规则,则可以
选择不继续此状态的递归。这个技巧通常在搜索类问题中使用。
7、问题:如何把目录结构递归加载到TreeView控件中?
新建Form添加一个TreeView和Button控件:

private void button1_Click(object sender, EventArgs e)
{
string p = @"D:\Program Files\Red Gate\.NET Reflector";
LoadDirectory(p, treeView1.Nodes);
}
private void LoadDirectory(string p, TreeNodeCollection nodes)
{
string[] dirs = Directory.GetDirectories(p);
foreach (string dir in dirs)
{
TreeNode treeNode = nodes.Add(Path.GetFileName(dir));
LoadDirectory(dir, treeNode.Nodes);
}
foreach (string file in Directory.GetFiles(p))
{
nodes.Add(Path.GetFileName(file));
}
}
关键点:
(1)递归深入。
不断地调用子目录,通过每个子目录来列举。注意两个参数,一个
当前的子目录,一个是子目录的结点。
(2)递归的终止。
递归的终止条件是当没有更多的子目录时,即Directory.GetDirectories(p)返回一
个空数组。这是一个隐含的终止条件,因为在没有子目录的情况下,递归将停止执行,
不再向下遍历目录树。