这里是个演示
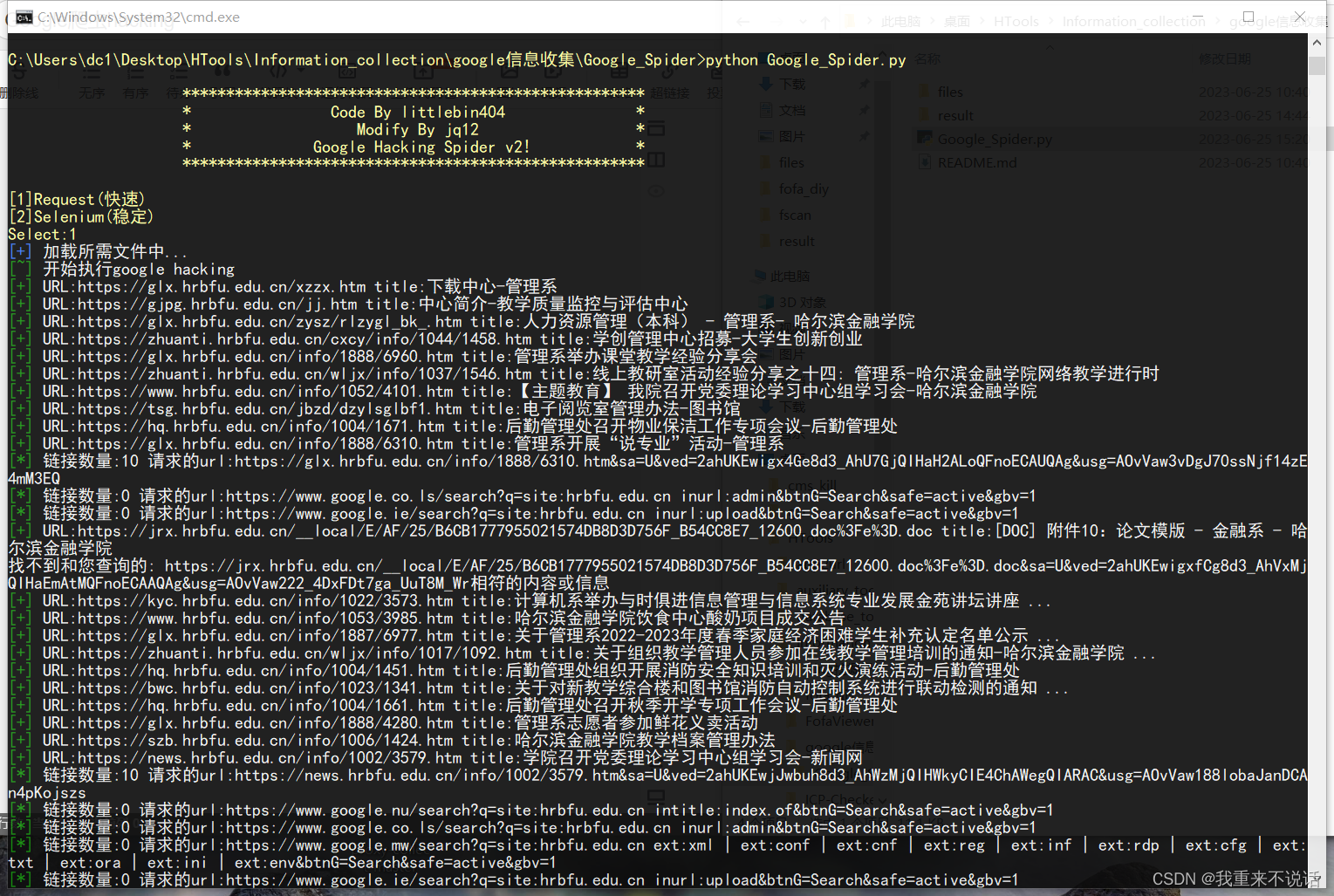
项目是根据这个项目进行修改的
修改了哪些东西:
- 新增个模式,一个Request,一个Selenium
- 原版只能读第一页,修改成可以自动判断
- 添加了更多的搜索摸板
- 输出csv,url+标题+域名
针对第三点:
添加了一下搜索摸板↓
self.search = [
'site:{domain} intitle:"后台" | intitle:"管理" | intitle:"平台" | intitle:"系统" | intitle:"登录" | intitle:"中心" | intitle:"控制"',
'site:{domain} inurl:admin',
'site:{domain} inurl:upload',
'site:{domain} ext:doc | ext:docx | ext:odt | ext:rtf | ext:sxw | ext:psw | ext:ppt | ext:pptx | ext:pps | ext:csv',
'site:{domain} intitle:index.of',
'site:{domain} ext:xml | ext:conf | ext:cnf | ext:reg | ext:inf | ext:rdp | ext:cfg | ext:txt | ext:ora | ext:ini | ext:env',
'site:{domain} ext:sql | ext:dbf | ext:mdb',
'site:{domain} ext:log',
'site:{domain} ext:bkf | ext:bkp | ext:bak | ext:old | ext:backup',
'site:{domain} inurl:login | inurl:signin | intitle:Login | intitle:"sign in" | inurl:auth',
'site:{domain} intext:"sql syntax near" | intext:"syntax error has occurred" | intext:"incorrect syntax near" | intext:"unexpected end of SQL command" | intext:"Warning: mysql_connect()" | intext:"Warning: mysql_query()" | intext:"Warning: pg_connect()"',
'site:{domain} "PHP Parse error" | "PHP Warning" | "PHP Error"',
'site:{domain} ext:php intitle:phpinfo "published by the PHP Group"',
'site:pastebin.com | site:paste2.org | site:pastehtml.com | site:slexy.org | site:snipplr.com | site:snipt.net | site:textsnip.com | site:bitpaste.app | site:justpaste.it | site:heypasteit.com | site:hastebin.com | site:dpaste.org | site:dpaste.com | site:codepad.org | site:jsitor.com | site:codepen.io | site:jsfiddle.net | site:dotnetfiddle.net | site:phpfiddle.org | site:ide.geeksforgeeks.org | site:repl.it | site:ideone.com | site:paste.debian.net | site:paste.org | site:paste.org.ru | site:codebeautify.org | site:codeshare.io | site:trello.com "{domain}"',
'site:github.com | site:gitlab.com "{domain}"',
'site:stackoverflow.com "{domain}" ',
'site:{domain} inurl:signup | inurl:register | intitle:Signup',
'site:*.{domain}',
'site:*.*.{domain}',
'({domain}) (site:*.*.29.* |site:*.*.28.* |site:*.*.27.* |site:*.*.26.* |site:*.*.25.* |site:*.*.24.* |site:*.*.23.* |site:*.*.22.* |site:*.*.21.* |site:*.*.20.* |site:*.*.19.* |site:*.*.18.* |site:*.*.17.* |site:*.*.16.* |site:*.*.15.* |site:*.*.14.* |site:*.*.13.* |site:*.*.12.* |site:*.*.11.* |site:*.*.10.* |site:*.*.9.* |site:*.*.8.* |site:*.*.7.* |site:*.*.6.* |site:*.*.5.* |site:*.*.4.* |site:*.*.3.* |site:*.*.2.* |site:*.*.1.* |site:*.*.0.*)',]
主要代码如下(其他文件可以在原版的github中下载):
# -*- coding:utf-8 -*-
from gevent import monkey;monkey.patch_all()
from colorama import init,Fore
from multiprocessing import Process
from bs4 import BeautifulSoup
import gevent
import asyncio
import random
import time
import requests
import os
import re
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support import expected_conditions
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
'''
基于"site:{domain} inurl:** intext:** "的google搜索工具;
'''
init(wrap=True) #在windows系统终端输出颜色要使用init(wrap=True)
class Google_query(object):
def __init__(self,key):
self.key = key
self.timeout=3
self.calc=0
self.url='/search?q={search}&btnG=Search&safe=active&gbv=1'
#self.url='/search?q={search}'
self.Google_domain=[]
self.search = [
'site:{domain} intitle:"后台" | intitle:"管理" | intitle:"平台" | intitle:"系统" | intitle:"登录" | intitle:"中心" | intitle:"控制"',
'site:{domain} inurl:admin',
'site:{domain} inurl:upload',
'site:{domain} ext:doc | ext:docx | ext:odt | ext:rtf | ext:sxw | ext:psw | ext:ppt | ext:pptx | ext:pps | ext:csv',
'site:{domain} intitle:index.of',
'site:{domain} ext:xml | ext:conf | ext:cnf | ext:reg | ext:inf | ext:rdp | ext:cfg | ext:txt | ext:ora | ext:ini | ext:env',
'site:{domain} ext:sql | ext:dbf | ext:mdb',
'site:{domain} ext:log',
'site:{domain} ext:bkf | ext:bkp | ext:bak | ext:old | ext:backup',
'site:{domain} inurl:login | inurl:signin | intitle:Login | intitle:"sign in" | inurl:auth',
'site:{domain} intext:"sql syntax near" | intext:"syntax error has occurred" | intext:"incorrect syntax near" | intext:"unexpected end of SQL command" | intext:"Warning: mysql_connect()" | intext:"Warning: mysql_query()" | intext:"Warning: pg_connect()"',
'site:{domain} "PHP Parse error" | "PHP Warning" | "PHP Error"',
'site:{domain} ext:php intitle:phpinfo "published by the PHP Group"',
'site:pastebin.com | site:paste2.org | site:pastehtml.com | site:slexy.org | site:snipplr.com | site:snipt.net | site:textsnip.com | site:bitpaste.app | site:justpaste.it | site:heypasteit.com | site:hastebin.com | site:dpaste.org | site:dpaste.com | site:codepad.org | site:jsitor.com | site:codepen.io | site:jsfiddle.net | site:dotnetfiddle.net | site:phpfiddle.org | site:ide.geeksforgeeks.org | site:repl.it | site:ideone.com | site:paste.debian.net | site:paste.org | site:paste.org.ru | site:codebeautify.org | site:codeshare.io | site:trello.com "{domain}"',
'site:github.com | site:gitlab.com "{domain}"',
'site:stackoverflow.com "{domain}" ',
'site:{domain} inurl:signup | inurl:register | intitle:Signup',
'site:*.{domain}',
'site:*.*.{domain}',
'({domain}) (site:*.*.29.* |site:*.*.28.* |site:*.*.27.* |site:*.*.26.* |site:*.*.25.* |site:*.*.24.* |site:*.*.23.* |site:*.*.22.* |site:*.*.21.* |site:*.*.20.* |site:*.*.19.* |site:*.*.18.* |site:*.*.17.* |site:*.*.16.* |site:*.*.15.* |site:*.*.14.* |site:*.*.13.* |site:*.*.12.* |site:*.*.11.* |site:*.*.10.* |site:*.*.9.* |site:*.*.8.* |site:*.*.7.* |site:*.*.6.* |site:*.*.5.* |site:*.*.4.* |site:*.*.3.* |site:*.*.2.* |site:*.*.1.* |site:*.*.0.*)',]
self.target_domain=[]
self.Proxies_ip=[]
self.coroutine=[]
self.ua=[]
self.header=[]
def get_total_pages(self, soap):
# Get the total number of pages from Google search results
page_info = soap.select('#foot td b')
if page_info:
pages = page_info[-1].get_text()
return int(pages)
return 1
def google_search(self,ua,url,proxies,sleep,page=0):
try:
time.sleep(int(sleep))
# Add page parameter for pagination
url_page = url + '&start={}'.format(page*10)
resp=requests.get(url=url_page,headers={'user-agent':ua},proxies=proxies,allow_redirects=False,timeout=30)
if '302 Moved' in resp.text:
print(Fore.YELLOW + '[!] ' + Fore.WHITE + '发现Google验证码!!!')
exit()
else:
soap = BeautifulSoup(resp.text, 'html.parser')
soap = soap.find_all("a")
results_exist = self.handle(soap,url)
# If there are results, repeat search on next page
if results_exist and page < 10: # Set max pages to 10
self.google_search(ua, url, proxies, sleep, page+1)
except Exception as r:
print(Fore.RED+'[-] '+Fore.WHITE+'Error {}'.format(r))
def google_search2(self, url, sleep, page=0):
try:
# 配置Selenium
#driver = webdriver.Chrome(service=Service('path_to_your_chromedriver'))
driver = webdriver.Chrome()
time.sleep(int(sleep))
# Add page parameter for pagination
url_page = url + '&start={}'.format(page*10)
driver.get(url_page)
# 检查是否有验证码
if '我们的系统检测到您的计算机网络中的流量异常' in driver.page_source:
print(Fore.YELLOW + '[!] ' + Fore.WHITE + '发现Google验证码!!!')
input('Press enter after you have solved the captcha...')
# 解析结果
soap = BeautifulSoup(driver.page_source, 'html.parser')
soap = soap.find_all("a")
results_exist = self.handle(soap, url)
# If there are results, repeat search on next page
if results_exist and page < 10: # Set max pages to 10
self.google_search2(url, sleep, page+1)
# 关闭webdriver实例
driver.quit()
except Exception as r:
print(Fore.RED+'[-] '+Fore.WHITE+'Error {}'.format(r))
def handle(self,soap,url):
# Returns True if results exist on the page
count=0
for data in soap:
res1 = "/url?q"
res2 = str(data.get('href'))
if (res1 in res2):
title=data.find('span')
result = re.findall(".*>(.*)<.*", str(title))
if title==None:
break
for x in result:
title=x
url=res2.replace('/url?q=', '')
head, middle, behind = url.partition('&sa') #去除多余查询字符串
print(Fore.GREEN + '[+] ' + Fore.WHITE + 'URL:{} title:{}'.format(
head, title))
# 写入文件
domain = self.get_domain(head)
print('{},{},{}'.format(head, title,domain),
file=open('result/save.csv', 'a+', encoding='utf-8'))
count+=1
if count == 1:
print('找不到和您查询的: {}相符的内容或信息'.format(url))
return False # No results
else:
print(Fore.GREEN + '[*] ' + Fore.WHITE + '链接数量:{} 请求的url:{}'.format(count, url))
return True # Results exist
def get_domain(self,head):
domain = head.replace("https://","").replace("http://","")
domain = domain.split("/")[0]
return domain
# 构造请求
def Build_Request(self,data):
for y in data:
for x in self.search:
time.sleep(2)
url='https://'+random.choice(self.Google_domain)+self.url.format(search=str(x).format(domain=y['target_domain']))
#创建一个普通的Greenlet对象并切换
if self.key=="1":
self.coroutine.append(gevent.spawn(self.google_search,ua=y['user-agent'],url=url,proxies=y['proxies'],sleep=y['sleep']))
elif self.key=="2":
self.coroutine.append(gevent.spawn(self.google_search2,url=url,sleep=y['sleep']))
#将协程任务添加到事件循环,接收一个任务列表
gevent.joinall(self.coroutine)
self.coroutine.clear()
def Do_query(self):
data={}
domain_number=len(self.target_domain)
if(domain_number==0):
print(Fore.YELLOW + '[!] ' + Fore.WHITE + '目标domain为空,请赋值!!')
exit()
for x in range(domain_number):
if self.calc==100:
p=Process(target=self.Build_Request, args=(self.header,))
p.start()
self.header.clear()
self.calc=0
data={}
data['user-agent']=random.choice(self.ua)
data['target_domain']=self.target_domain[x]
data['proxies']={'http':'http://{}'.format(random.choice(self.Proxies_ip)),'https':'http://{}'.format(random.choice(self.Proxies_ip))}
data['sleep']=random.choice([x for x in range(1,10)])
self.header.append(data)
data = {}
self.calc+=1
if len(self.header)>0:
p = Process(target=self.Build_Request, args=(self.header,))
p.start()
self.header.clear()
self.calc = 0
data = {}
def read_file(self,file):
dk = open(file, 'r', encoding='utf-8')
for d in dk.readlines():
data="".join(d.split('\n'))
yield data
async def getfile(self):
if os.path.exists('files/UA.txt') and os.path.exists('files/target_domain.txt') and os.path.exists('files/proxies.txt') and os.path.exists('files/Google_domain.txt'):
print(Fore.BLUE+'[+] '+Fore.WHITE+'加载所需文件中...')
else:
print(Fore.RED+'[-] '+Fore.WHITE+'缺少所需文件..请填补文件')
exit()
print(Fore.GREEN+'[~] '+Fore.WHITE+'开始执行google hacking')
for u in self.read_file('files/UA.txt'):
self.ua.append(u)
for t in self.read_file('files/target_domain.txt'):
self.target_domain.append(t)
for p in self.read_file('files/proxies.txt'):
self.Proxies_ip.append(p)
for g in self.read_file('files/Google_domain.txt'):
self.Google_domain.append(g)
self.Do_query()
if __name__ == '__main__':
author_info = '''
*****************************************************
* Code By littlebin404 *
* Modify By jq12 *
* Google Hacking Spider v2! *
*****************************************************
'''
print(author_info)
key = input("[1]Request(快速)\n[2]Selenium(稳定)\nSelect:")
obj=Google_query(key)
loop=asyncio.get_event_loop()
tk=loop.create_task(obj.getfile())
loop.run_until_complete(tk)