Python读取xlsx中的超链接
xlsx是一种常用的电子表格文件格式,在日常的工作生活中经常使用。xlsx文件中可以包含超链接,作为文件中数据的补充和扩展。而Python作为一门强大的编程语言,可以帮助我们轻松读取xlsx文件中的超链接,进一步实现数据的处理和分析。
在本文中,我们将介绍如何使用Python读取xlsx文件中的超链接,并给出示例代码。同时,我们还将探讨如何在代码中进行优化,使得程序能够更加高效地处理大量数据。
什么是xlsx超链接
超链接是一种在文本或图像中插入的链接,可以指向两个文件之间的关联,或者是互联网上的某个网页。在电子表格中,超链接可以用来建立表格数据和其他资料之间的关联,比如,在某个单元格中插入一个超链接到另一个单元格,或者是插入一个超链接到一个文件或网页。
如何读取xlsx超链接
Python提供了一个很方便的xlrd包,可以用来读取xlsx文件中的各种数据,包括超链接。xlrd包可以通过 pip install xlrd 命令进行安装。
启动Python环境后,我们首先需要打开xlsx文件,然后利用xlrd包读取超链接数据。下面是示例代码:
import xlrd
# 打开xlsx文件
workbook = xlrd.open_workbook('example.xlsx')
# 读取第一个sheet
worksheet = workbook.sheet_by_index(0)
# 读取第一行第一列的超链接
hyperlink = worksheet.hyperlink_map.get((0,0))
# 输出超链接
print(hyperlink.url_or_path)
这段代码中,我们首先使用 open_workbook() 函数打开一个xlsx文件,然后利用 sheet_by_index() 函数读取该文件中的第一个sheet。
接下来,我们使用 hyperlink_map.get() 函数获取一个超链接对象。该对象包含了超链接的各种属性,比如链接的地址、文本和提示等信息。在本示例中,我们只需打印出超链接的地址即可。
如何批量读取xlsx超链接
当需要读取大量xlsx文件中的超链接时,我们可以使用Python的循环语句和列表来批量读取数据。下面是一个读取多个xlsx文件中超链接的示例代码:
import xlrd
import os
# 遍历指定目录下的所有xlsx文件
path = '/Users/coco/workbooks/'
for filename in os.listdir(path):
if filename.endswith('.xlsx'):
filepath = os.path.join(path, filename)
workbook = xlrd.open_workbook(filepath)
sheet = workbook.sheet_by_index(0)
for row in range(sheet.nrows):
for col in range(sheet.ncols):
hyperlinks = sheet.hyperlink_map.get((row, col))
if hyperlinks:
print(filepath, row, col, hyperlinks.url_or_path)
这段代码中,我们首先定义了一个文件路径 path,然后使用 os.listdir() 函数遍历该目录下的所有xlsx文件。当找到文件时,我们使用 open_workbook() 函数打开文件,然后根据sheet的索引值读取数据。
接下来,我们遍历sheet中的每一个单元格,查找其中是否存在超链接。如果存在,则打印出文件名、行号、列号和超链接的地址。
如何优化代码性能
当处理大量xlsx文件时,读取超链接信息可能会非常耗时。如果我们需要快速读取数据,我们可以在读取xlsx文件前进行缓存,把结果保存在列表中。这样,我们就可以避免重复读取文件,提高程序性能。
下面是一个包含缓存功能的示例代码:
import xlrd
import os
# 遍历指定目录下的所有xlsx文件
path = '/Users/coco/workbooks/'
# 定义缓存列表
cache = {}
for filename in os.listdir(path):
if filename.endswith('.xlsx'):
filepath = os.path.join(path, filename)
# 如果缓存中没有对应文件的数据,则读取文件中的超链接信息
if filepath not in cache:
workbook = xlrd.open_workbook(filepath)
sheet = workbook.sheet_by_index(0)
# 读取超链接信息,并保存在缓存列表中
hyperlinks = []
for row in range(sheet.nrows):
for col in range(sheet.ncols):
link = sheet.hyperlink_map.get((row, col))
if link:
hyperlinks.append((row, col, link.url_or_path))
cache[filepath] = hyperlinks
# 直接从缓存中获取文件中的超链接信息
hyperlinks = cache[filepath]
for row, col, url in hyperlinks:
print(filepath, row, col, url)
在这个示例代码中,我们首先定义了一个缓存列表 cache,然后遍历指定目录下的所有xlsx文件。如果某个文件还没有读取过,我们就使用 open_workbook() 函数读取该文件,并且将其中的超链接信息保存在缓存列表中。
当我们需要读取某个文件的超链接信息时,我们就直接从缓存列表中获取即可。这样就避免了多次读取同一个文件的情况,减少了程序的运行时间。
结论
Python提供了强大的xlrd包,可以帮助我们快速读取xlsx文件中的超链接信息。当需要处理大量xlsx文件时,我们可以利用循环语句和列表实现批量读取数据。此外,我们还可以通过缓存技术来优化程序性能,避免重复读取同一个文件。
在实际应用中,我们可以根据需要进一步优化代码,例如,可以使用多线程或进程池来并发处理大量xlsx文件,以提高程序的运行效率。
最后的最后
本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。
对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。
🧡AI职场汇报智能办公文案写作效率提升教程 🧡 专注于AI+职场+办公方向。
下图是课程的整体大纲
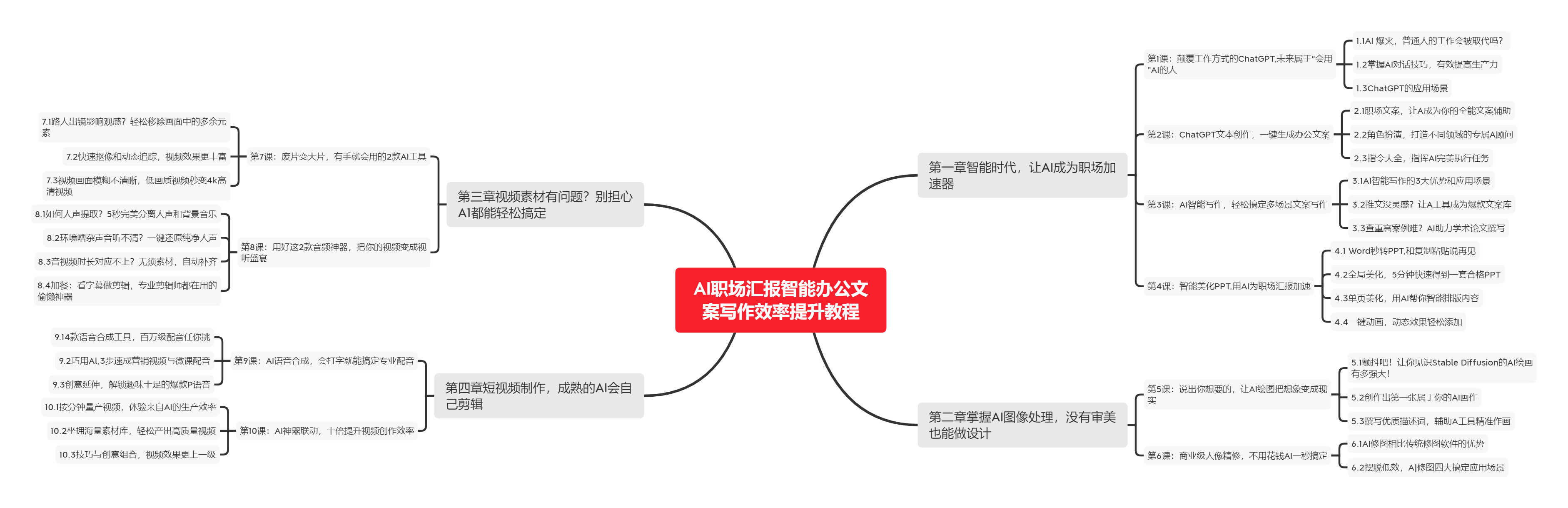

下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具

🚀 优质教程分享 🚀
- 🎄可以学习更多的关于人工只能/Python的相关内容哦!直接点击下面颜色字体就可以跳转啦!
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 AI职场汇报智能办公文案写作效率提升教程 🧡 | 进阶级 | 本课程是AI+职场+办公的完美结合,通过ChatGPT文本创作,一键生成办公文案,结合AI智能写作,轻松搞定多场景文案写作。智能美化PPT,用AI为职场汇报加速。AI神器联动,十倍提升视频创作效率 |
| 💛Python量化交易实战 💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |