总览
大规模“指令调整”的语言模型,即指令微调的LLM,已经表现出非凡的零样本能力,尤其是推广新任务上。 然而,这些模型严重依赖于人类编写的指令数据,而这些数据通常在数量、多样性和创造力方面受到限制,因此阻碍了调整模型的通用性。
基于上述背景,作者提出了Self-instruct框架,一个通过预训练语言模型自己引导自己来提高的指令遵循能力的框架。
大白话点讲,就是
- 大模型自己遵循一套流程来生成数据,
- 再用这些生成的数据来指令微调训自己,
- 从而提高模型自己的能力。
因此核心思想就是生成 指令遵循数据
数据生成
指令数据由指令、输入、输出组成。如下图,作者的数据生成piple包含四个步骤:1)生成任务指令,2)确定指令是否代表分类任务,3)使用输入优先或输出优先方法生成实例,4)过滤低质量的数据。
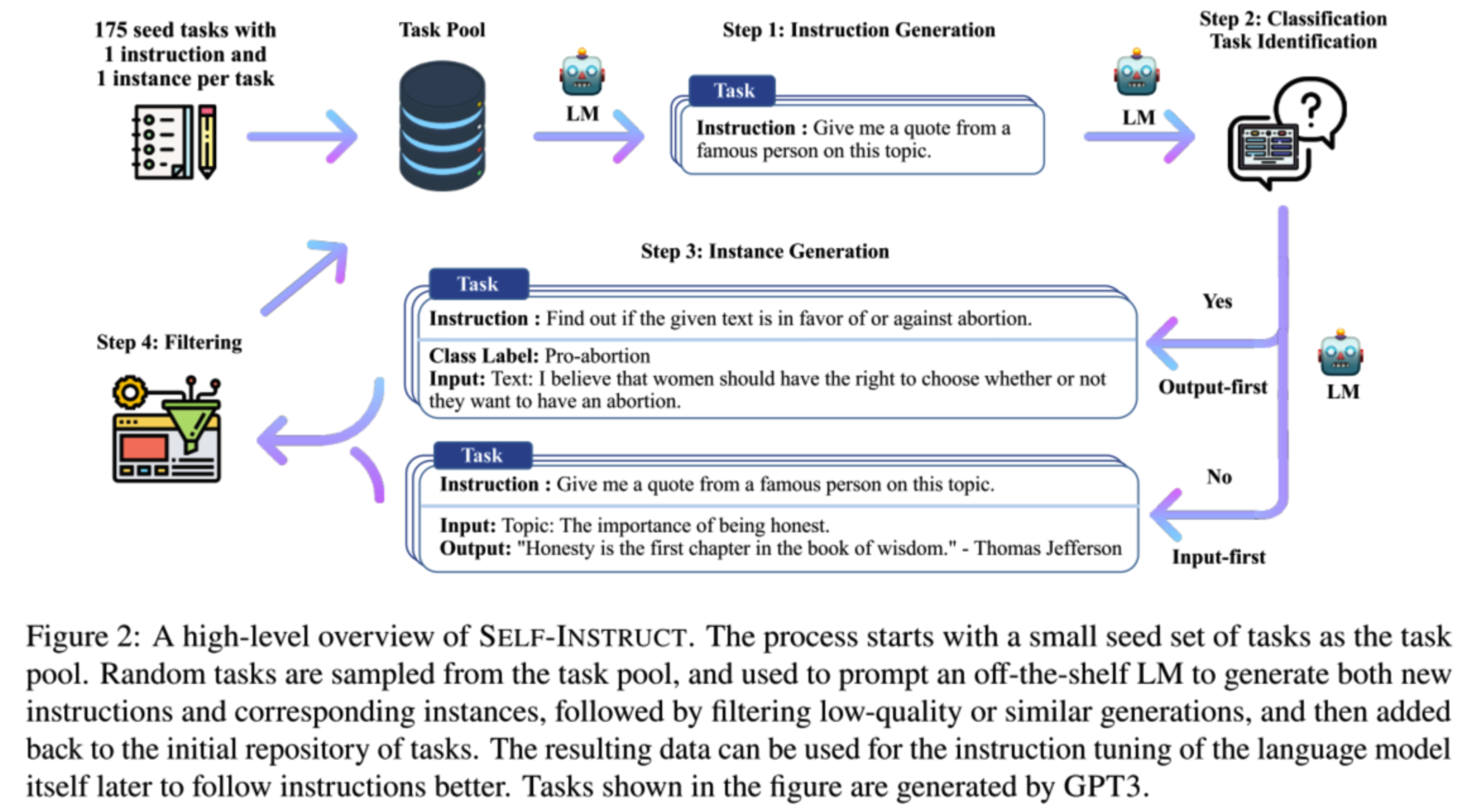
1 指令生成
首先生成丰富的指令,初始化175个任务,每个任务1个指令和1个实例;
- 每一个迭代都选8个任务的指令作为该任务的提示样本,其中6个是人写的,2个是生成的。
- 然后组成输入送入模型进行输出引导,直到达到token限制或者够16个任务

2 分类任务识别
作者对于分类任务和非分类任务的后续处理是不同的,所以需要先区别是否为分类任务,这里同样使用LLM对生成的指令进行区别。如下图(只显示了部分),作者为列举 12 个分类指令和19个非分类指令作为prompt提示,以少样本学习提示的方式让LLM判断是否任务为分类。


3 实例生成
针对每一任务类型,作者独立的生成实例,即整个指令数据。
指令微调一般三部分:指令、输入和输出,大模型需要对这3部分都进行生成。
这部分比较难的是让大模型理解模板任务是什么,并根据指令(上面已经生成了),得到输入,再进一步补充出输出。
作者发现大模型对 指令-输入-输出 提示的上下文学习有效果,于是:
输入优先方式(Input-first Approach)
以下图为例,给大模型一堆例子,指令指导它进行参考生成:如果需要input,就先生成input,如果没有input,就直接生成output

输出优先方式(Output-first Approach)
上面这种输入优先的方式不适合部分任务生成,尤其是分类任务,生成的输入会偏向于某个标签(label),比如是语法错误检测任务,他会生成 语法性的输入。于是作者提出输出优先方式,将输出放在前面进行上下文学习,

4 过滤和后处理
- 为了保证指令多样性,新指令中只有与已有指令ROUGE-L相似度(衡量自然语言相似度的指标)小于0.7的才会被保留;
- 包含特定关键词的指令也剔除(image, picture, graph等LM本来也无法处理的);
- 去除 输入输出完全相同的实例;或者输入相同输出不同的实例;
- 还有一些启发式方法(比如指令太长/短,输出是输入的重复等等)进行剔除;