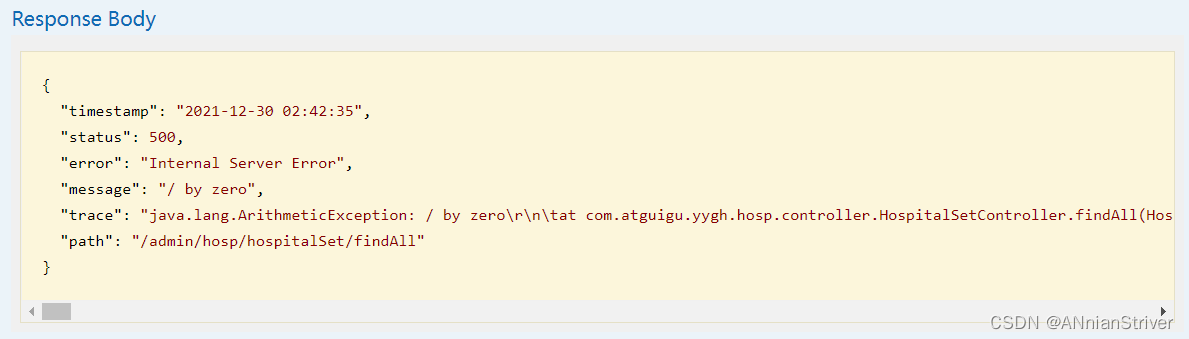
数据仓库HIVE存储数据一般采用parquet格式,但Alibaba datax开源版不支持parquet格式,在网上查了很多资料,写的大多不完整,特此总结出完整版记录一下,供大家参考。
操作步骤
1.从gitee 拉取datax代码,对hdfsreader模块进行改造,主要改造以下4个类。

pom里面添加parquet支持依赖
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-common</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-protobuf</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-protobuf</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-hadoop</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.1</version>
</dependency>Constant如下
public class Constant {
public static final String SOURCE_FILES = "sourceFiles";
public static final String TEXT = "TEXT";
public static final String ORC = "ORC";
public static final String CSV = "CSV";
public static final String SEQ = "SEQ";
public static final String RC = "RC";
public static final String PARQUET= "PARQUET";
}HdfsFileType
public enum HdfsFileType {
ORC, SEQ, RC, CSV, TEXT,PARQUET,
}DFSUtil添加读取parquet方法,根据orc读取方法改造
public void parquetFileStartRead(String sourceParquetFilePath, Configuration readerSliceConfig,
RecordSender recordSender, TaskPluginCollector taskPluginCollector) {
LOG.info(String.format("Start Read parquetfile [%s].", sourceParquetFilePath));
List<ColumnEntry> column = UnstructuredStorageReaderUtil
.getListColumnEntry(readerSliceConfig, com.alibaba.datax.plugin.unstructuredstorage.reader.Key.COLUMN);
String nullFormat = readerSliceConfig.getString(NULL_FORMAT);
StringBuilder allColumns = new StringBuilder();
StringBuilder allColumnTypes = new StringBuilder();
boolean isReadAllColumns = false;
int columnIndexMax = -1;
// 判断是否读取所有列
if (null == column || column.size() == 0) {
int allColumnsCount = getParquetAllColumnsCount(sourceParquetFilePath);
columnIndexMax = allColumnsCount - 1;
isReadAllColumns = true;
} else {
columnIndexMax = getMaxIndex(column);
}
for (int i = 0; i <= columnIndexMax; i++) {
allColumns.append("col");
allColumnTypes.append("string");
if (i != columnIndexMax) {
allColumns.append(",");
allColumnTypes.append(":");
}
}
if (columnIndexMax >= 0) {
Path parquetFilePath = new Path(sourceParquetFilePath);
Properties p = new Properties();
p.setProperty("columns", allColumns.toString());
p.setProperty("columns.types", allColumnTypes.toString());
try {
// 创建 ParquetReader.Builder 实例
ParquetReader.Builder<Group> builder = ParquetReader.builder(new GroupReadSupport(), parquetFilePath);
// 创建 ParquetReader 实例
ParquetReader<Group> reader = builder.build();
// 循环读取 Parquet 文件中的记录
Group line;
List<Object> recordFields;
while ((line = reader.read()) != null) {
recordFields = new ArrayList<Object>();
//从line中获取每个字段
for (int i = 0; i <= columnIndexMax; i++) {
Object field = line.getValueToString(i, 0);
recordFields.add(field);
}
transportOneRecord(column, recordFields, recordSender,
taskPluginCollector, isReadAllColumns, nullFormat);
}
} catch (Exception e) {
String message = String.format("从parquetfile文件路径[%s]中读取数据发生异常,[%s],请联系系统管理员。"
, sourceParquetFilePath, e);
LOG.error(message);
throw DataXException.asDataXException(HdfsReaderErrorCode.READ_FILE_ERROR, message);
}
} else {
String message = String.format("请确认您所读取的列配置正确!columnIndexMax 小于0,column:%s", JSON.toJSONString(column));
throw DataXException.asDataXException(HdfsReaderErrorCode.BAD_CONFIG_VALUE, message);
}
}
//获取parquet文件总列数
private int getParquetAllColumnsCount(String filePath) {
Path path = new Path(filePath);
try {
org.apache.parquet.hadoop.metadata.ParquetMetadata metadata = org.apache.parquet.hadoop.ParquetFileReader.readFooter(hadoopConf, path);
List<ColumnChunkMetaData> columns = metadata.getBlocks().get(0).getColumns();
int columnCount = columns.size();
return columnCount;
} catch (IOException e) {
String message = "读取Parquetfile column列数失败,请联系系统管理员";
throw DataXException.asDataXException(HdfsReaderErrorCode.READ_FILE_ERROR, message);
}
}
//检查文件类型,添加parquet判断
public boolean checkHdfsFileType(String filepath, String specifiedFileType) {
Path file = new Path(filepath);
try {
FileSystem fs = FileSystem.get(hadoopConf);
FSDataInputStream in = fs.open(file);
if (StringUtils.equalsIgnoreCase(specifiedFileType, Constant.CSV)
|| StringUtils.equalsIgnoreCase(specifiedFileType, Constant.TEXT)) {
boolean isORC = isORCFile(file, fs, in);// 判断是否是 ORC File
if (isORC) {
return false;
}
boolean isRC = isRCFile(filepath, in);// 判断是否是 RC File
if (isRC) {
return false;
}
boolean isSEQ = isSequenceFile(filepath, in);// 判断是否是 Sequence File
if (isSEQ) {
return false;
}
// 如果不是ORC,RC和SEQ,则默认为是TEXT或CSV类型
return !isORC && !isRC && !isSEQ;
} else if (StringUtils.equalsIgnoreCase(specifiedFileType, Constant.ORC)) {
return isORCFile(file, fs, in);
} else if (StringUtils.equalsIgnoreCase(specifiedFileType, Constant.RC)) {
return isRCFile(filepath, in);
} else if (StringUtils.equalsIgnoreCase(specifiedFileType, Constant.SEQ)) {
return isSequenceFile(filepath, in);
} else if (StringUtils.equalsIgnoreCase(specifiedFileType, Constant.PARQUET)) {
return isParquetFile(new Path(filepath));
}
} catch (Exception e) {
String message = String.format("检查文件[%s]类型失败,目前支持ORC,SEQUENCE,RCFile,PARQUET,TEXT,CSV六种格式的文件," +
"请检查您文件类型和文件是否正确。", filepath);
LOG.error(message);
throw DataXException.asDataXException(HdfsReaderErrorCode.READ_FILE_ERROR, message, e);
}
return false;
}
//判断文件是否是parquet
private static boolean isParquetFile(Path file) {
try {
org.apache.parquet.hadoop.example.GroupReadSupport readSupport = new GroupReadSupport();
ParquetReader.Builder<org.apache.parquet.example.data.Group> reader = ParquetReader.builder(readSupport, file);
ParquetReader<Group> build = reader.build();
if (build.read() != null) {
return true;
}
} catch (IOException e) {
}
return false;
}
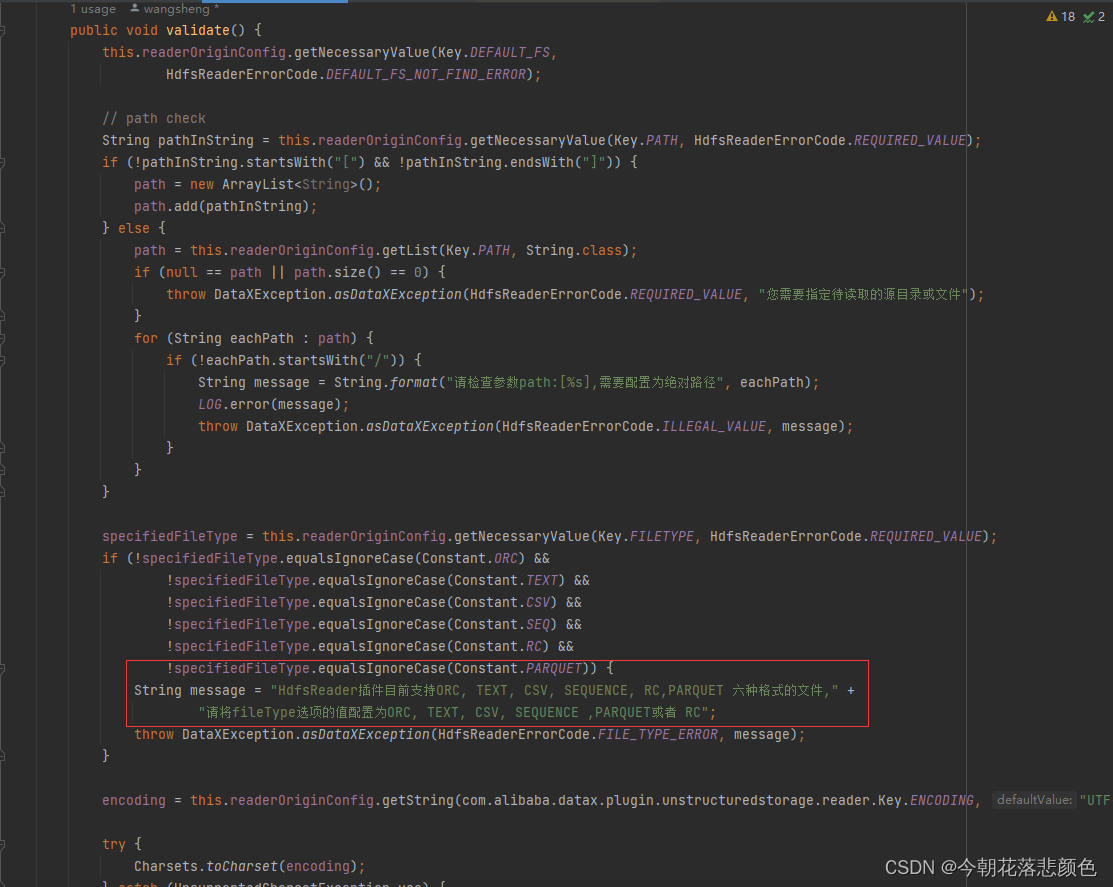
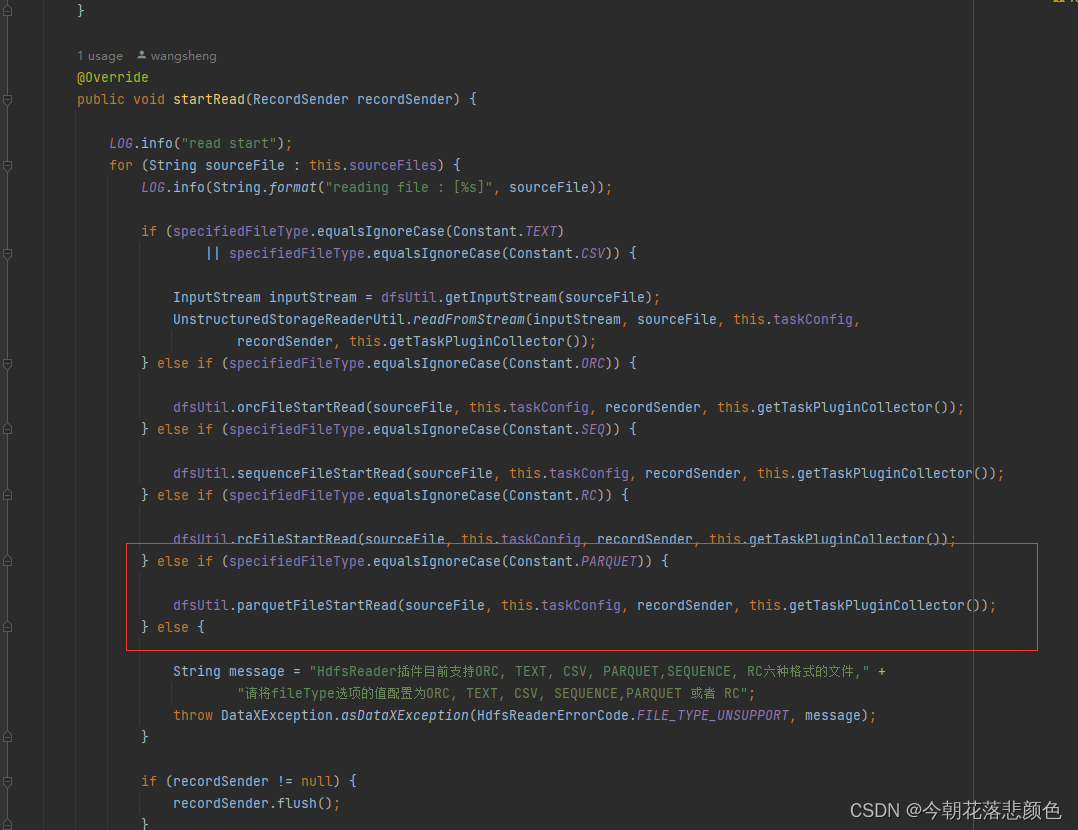
最后是HdfsReader,添加parquet
重新打包hdfsreader,将包替换到datax引擎即可。