目录
- 一、前言
- 二、什么是布隆过滤器?
- 三、布隆过滤器原理
- 四、布隆过滤器使用场景
- 五、空间占用估计
- 六、实际元素超出时,误判率会怎样变化
- 七、布隆过滤器实现方式
- 1、手动硬编码实现
- 2、引入 Guava 实现
- 3、引入 hutool 实现
- 4、通过redis实现布隆过滤器
- 八、使用建议
一、前言
讲个使用场景,比如我们在使用新闻客户端看新闻时,它会给我们不停地推荐新的内容,它每次推荐时要去重,去掉那些已经看过的内容。问题来了,新闻客户端推荐系统如何实现推送去重的?
-
你会想到服务器记录了用户看过的所有历史记录,当推荐系统推荐新闻时会从每个用户的历史记录里进行筛选,过滤掉那些已经存在的记录。问题是当用户量很大,每个用户看过的新闻又很多的情况下,这种方式,推荐系统的去重工作在性能上跟的上么?
-
实际上,如果历史记录存储在关系数据库里,去重就需要频繁地对数据库进行 exists 查询,当系统并发量很高时,数据库是很难扛住压力的
-
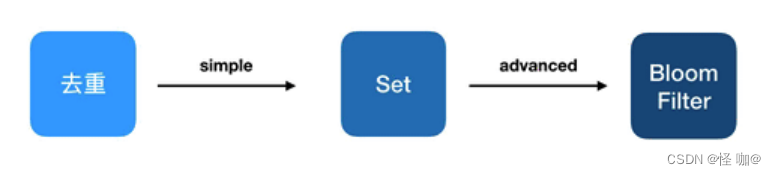
你可能又想到了缓存,但是如此多的历史记录全部缓存起来,那得浪费多大存储空间啊?而且这个存储空间是随着时间线性增长,你撑得住一个月,你能撑得住几年么?但是不缓存的话,性能又跟不上,这该怎么办?
这时,布隆过滤器 (Bloom Filter) 闪亮登场了,它就是专门用来解决这种去重问题的。它在起到去重的同时,在空间上还能节省 90% 以上,只是稍微有那么点不精确,也就是有一定的误判概率。
二、什么是布隆过滤器?
布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
三、布隆过滤器原理
讲述布隆过滤器的原理之前,我们先思考一下,通常你判断某个元素是否存在用的是什么?应该蛮多人回答 HashMap 吧,确实可以将值映射到HashMap 的 Key,然后可以在 0(1)的时间复杂度内返回结果,效率奇高。但是 HashMap的实现也有缺点,例如存储容量占比高,考虑到负载因子的存在,通常空间是不能被用满的,而一旦你的值很多例如上亿的时候,那HashMap占据的内存大小就变得很可观了。
个人认为这个视频讲解的还是比较通俗易懂的,感兴趣的可以看一下:https://www.bilibili.com/video/BV1zK4y1h7pA/?spm_id_from=333.788.top_right_bar_window_history.content.click
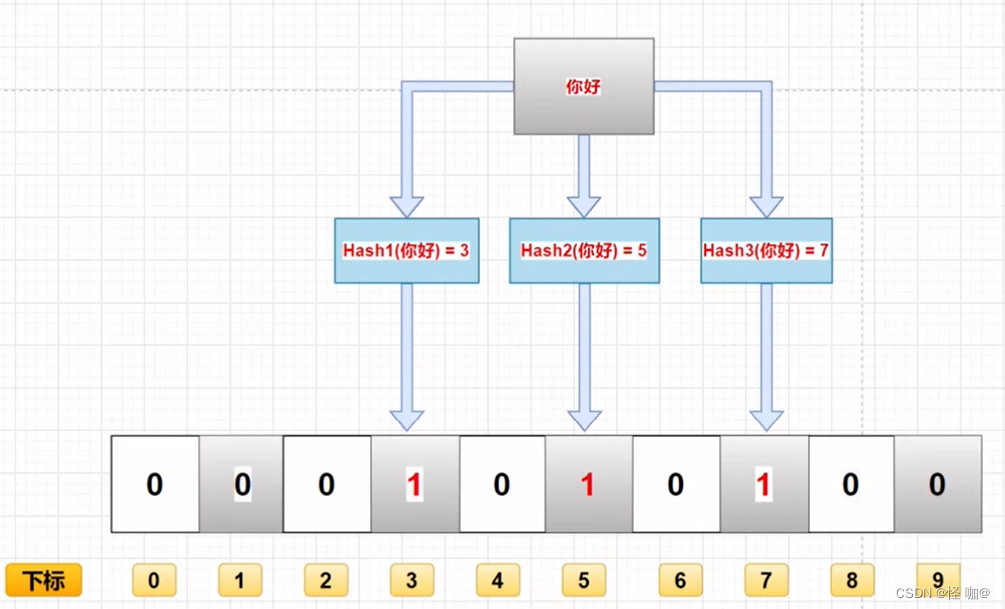
当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
注:图中是三个散列函数,实际当中不一定是三个,所以上面用的k。
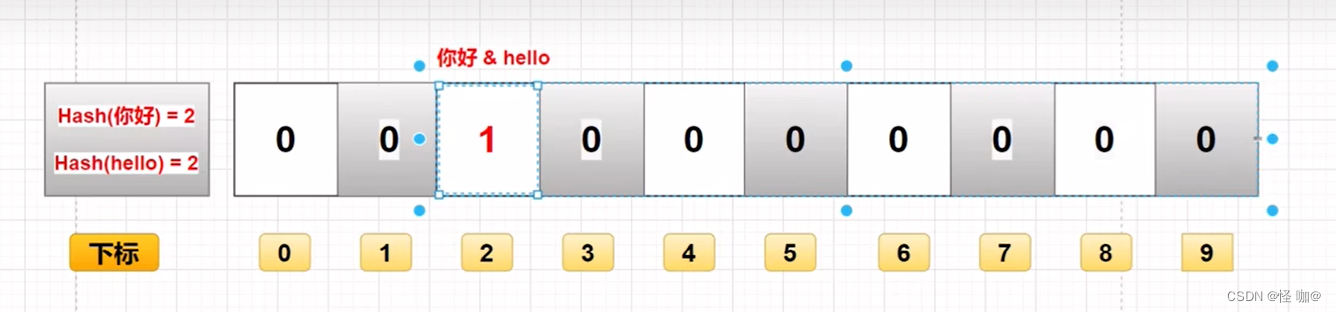
如下图所示,两个不同的值,经过相同的哈希运算后,可能会得出同样的值。即下图中,hello和你好 经过哈希运算后,得出的下标都为2,把位2上的值改为1。所以,无法判断位2上的值为1是谁的值。
同时,如果只存储了"你好"未存储"hello",当查询hello时,经过哈希运算得出值为2,去位2中查看,得知值为1,得出结论"hello"可能存在于过滤器中,即发生了误判。
误判可以通过增多哈希函数进行降低。哈希函数越多,误判率越低。同时,布隆过滤器查找和插入的时间复杂度都为O(k),k为哈希函数的个数。所以,哈希函数越多,时间复杂度越高。具体如何选择,需要根据数据量的多少进行。
优点:
- 占用空间小,因为他是不存储实际数据的。
- 保密性非常好,不存储原始数据,别人也不知道0和1是什么。
- 他底层是基于位数组的,基于数组的特性查询和插入是非常快的。
缺点:
- 由于上文中提到的数据经过哈希计算后值相同的原因,一般情况下不能从布隆过滤器中删除元素。
- 存在误判,本身不在里面可能经过hash计算会认为存在。
四、布隆过滤器使用场景
综上,我们可以得出:布隆过滤器可以判断指定的元素一定不存在或者可能存在! 打个比方,当它说不认识你时,肯定就不认识;当它说见过你时,可能根本就没见过面,不过因为你的脸跟它认识的人中某脸比较相似 (某些熟脸的系数组合),所以误判以前见过你。
套在上面的新闻推荐使用场景中,布隆过滤器能准确过滤掉那些已经看过的内容,那些没有看过的新内容,它也会过滤掉极小一部分 (误判),但是绝大多数新内容它都能准确识别。这样就可以完全保证推荐给用户的内容都是无重复的。
一般有如下几种使用场景:
- 解决Redis缓存穿透
- 在爬虫系统中,我们需要对 URL 进行去重,已经爬过的网页就可以不用爬了。但是URL 太多了,几千万几个亿,如果用一个集合装下这些 URL 地址那是非常浪费空间的。这时候就可以考虑使用布隆过滤器。它可以大幅降低去重存储消耗,只不过也会使得爬虫系统错过少量的页面。
- 邮箱系统的垃圾邮件过滤功能也普遍用到了布隆过滤器,因为用了这个过滤器,所以平时也会遇到某些正常的邮件被放进了垃圾邮件目录中
- 新闻推荐、文章推荐等等。
五、空间占用估计
布隆过滤器有两个参数,第一个是预计元素的数量 n,第二个是错误率 f。公式根据这两个输入得到两个输出,第一个输出是位数组的长度 l,也就是需要的存储空间大小 (bit),第二个输出是 hash 函数的最佳数量 k。hash 函数的数量也会直接影响到错误率,最佳的数量会有最低的错误率。
- k=0.7*(l/n) # 约等于
- f=0.6185^(l/n) # ^ 表示次方计算,也就是 math.pow
从公式中可以看出
- 位数组相对越长 (l/n),错误率 f 越低,这个和直观上理解是一致的
- 位数组相对越长 (l/n),hash 函数需要的最佳数量也越多,影响计算效率
- 当一个元素平均需要 1 个字节 (8bit) 的指纹空间时 (l/n=8),错误率大约为 2%
- 错误率为 10%,一个元素需要的平均指纹空间为 4.792 个 bit,大约为 5bit
- 错误率为 1%,一个元素需要的平均指纹空间为 9.585 个 bit,大约为 10bit
- 错误率为 0.1%,一个元素需要的平均指纹空间为 14.377 个 bit,大约为 15bit
你也许会想,如果一个元素需要占据 15 个 bit,那相对 set 集合的空间优势是不是就没有那么明显了?这里需要明确的是,set 中会存储每个元素的内容,而布隆过滤器仅仅存储元素的指纹。元素的内容大小就是字符串的长度,它一般会有多个字节,甚至是几十个上百个字节,每个元素本身还需要一个指针被 set 集合来引用,这个指针又会占去 4 个字节或 8 个字节,取决于系统是 32bit 还是 64bit。而指纹空间只有接近 2 个字节,所以布隆过滤器的空间优势还是非常明显的。
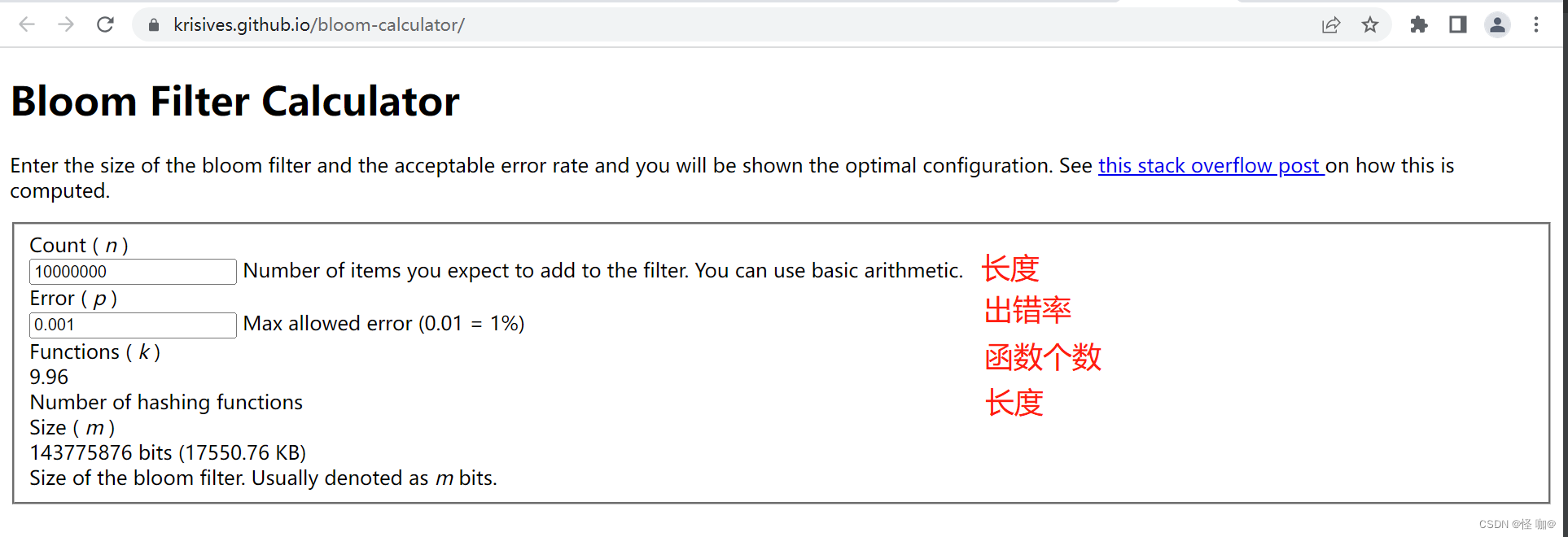
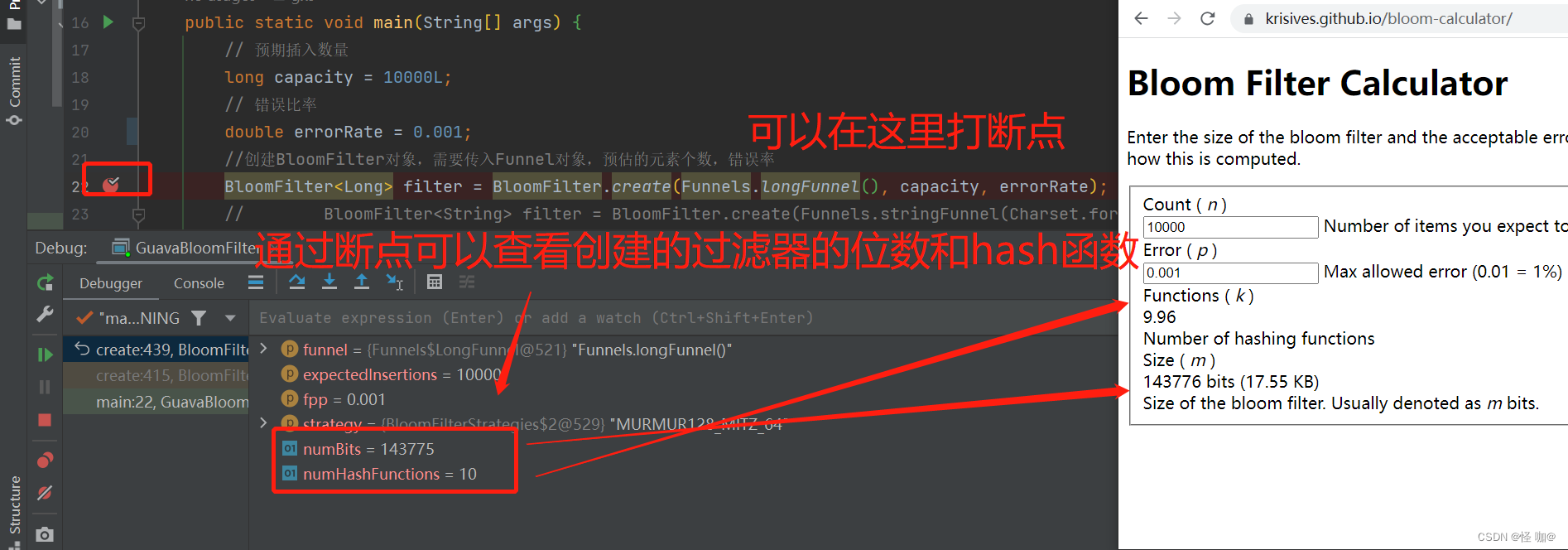
如果读者觉得公式计算起来太麻烦,也没有关系,有很多现成的网站已经支持计算空间占用的功能了,我们只要把参数输进去,就可以直接看到结果,比如 布隆计算器。https://krisives.github.io/bloom-calculator/
六、实际元素超出时,误判率会怎样变化
当实际元素超出预计元素时,错误率会有多大变化,它会急剧上升么,还是平缓地上升,这就需要另外一个公式,引入参数 t 表示实际元素和预计元素的倍数 t
- f=(1-0.5t)k # 极限近似,k 是 hash 函数的最佳数量
当 t 增大时,错误率,f 也会跟着增大,分别选择错误率为 10%,1%,0.1% 的 k 值,画出它的曲线进行直观观察。
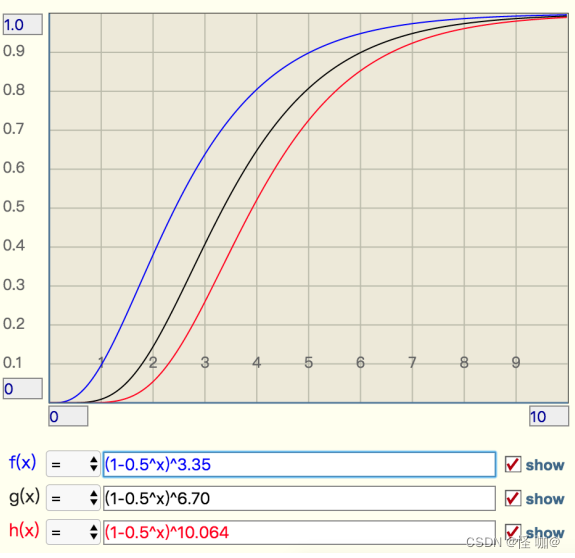
从这个图中可以看出曲线还是比较陡峭的
- 错误率为 10% 时,倍数比为 2 时,错误率就会升至接近 40%,这个就比较危险了
- 错误率为 1% 时,倍数比为 2 时,错误率升至 15%,也挺可怕的
- 错误率为 0.1%,倍数比为 2 时,错误率升至 5%,也比较悬了
得出结论:使用时不要让实际元素远大于初始化大小,当实际元素开始超出初始化大小时,应该对布隆过滤器进行重建,重新分配一个 size 更大的过滤器,再将所有的历史元素批量 add 进去 (这就要求我们在其它的存储器中记录所有的历史元素)。因为 error_rate 不会因为数量超出就急剧增加,这就给我们重建过滤器提供了较为宽松的时间。
七、布隆过滤器实现方式
1、手动硬编码实现
public class MyBloomFilter {
/**
* 位数组大小 33554432
*/
private static final int DEFAULT_SIZE = 2 << 24;
/**
* 通过这个数组创建多个Hash函数
*/
private static final int[] SEEDS = new int[]{6, 18, 64, 89, 126, 189, 223};
/**
* 初始化位数组,数组中的元素只能是 0 或者 1
*/
private BitSet bits = new BitSet(DEFAULT_SIZE);
/**
* Hash函数数组
*/
private MyHash[] myHashes = new MyHash[SEEDS.length];
/**
* 初始化多个包含 Hash 函数的类数组,每个类中的 Hash 函数都不一样
*/
public MyBloomFilter() {
// 初始化多个不同的 Hash 函数
for (int i = 0; i < SEEDS.length; i++) {
myHashes[i] = new MyHash(DEFAULT_SIZE, SEEDS[i]);
}
}
/**
* 添加元素到位数组
*/
public void add(Object value) {
for (MyHash myHash : myHashes) {
bits.set(myHash.hash(value), true);
}
}
/**
* 判断指定元素是否存在于位数组
*/
public boolean contains(Object value) {
boolean result = true;
for (MyHash myHash : myHashes) {
result = result && bits.get(myHash.hash(value));
}
return result;
}
/**
* 自定义 Hash 函数
*/
private class MyHash {
private int cap;
private int seed;
MyHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
/**
* 计算 Hash 值
*/
int hash(Object obj) {
return (obj == null) ? 0 : Math.abs(seed * (cap - 1) & (obj.hashCode() ^ (obj.hashCode() >>> 16)));
}
}
public static void main(String[] args) {
long capacity = 10000000L;
System.out.println(2 << 24);
MyBloomFilter myBloomFilter = new MyBloomFilter();
//put值进去
for (long i = 0; i < capacity; i++) {
myBloomFilter.add(i);
}
// 统计误判次数
int count = 0;
// 我在数据范围之外的数据,测试相同量的数据,判断错误率是不是符合我们当时设定的错误率
for (long i = capacity; i < capacity * 2; i++) {
if (myBloomFilter.contains(i)) {
count++;
}
}
System.out.println(count);
}
}
2、引入 Guava 实现
引入Guava的依赖:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>32.0.1-jre</version>
</dependency>
代码实现:
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
public class GuavaBloomFilter {
public static void main(String[] args) {
// 预期插入数量
long capacity = 10000L;
// 错误比率
double errorRate = 0.01;
//创建BloomFilter对象,需要传入Funnel对象,预估的元素个数,错误率
BloomFilter<Long> filter = BloomFilter.create(Funnels.longFunnel(), capacity, errorRate);
// BloomFilter<String> filter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf-8")), 10000, 0.0001);
//put值进去
for (long i = 0; i < capacity; i++) {
filter.put(i);
}
// 统计误判次数
int count = 0;
// 我在数据范围之外的数据,测试相同量的数据,判断错误率是不是符合我们当时设定的错误率
for (long i = capacity; i < capacity * 2; i++) {
if (filter.mightContain(i)) {
count++;
}
}
System.out.println(count);
}
}
输出结果:
假如数据为10000容错率为0.01,统计出来的误判个数是87。

3、引入 hutool 实现
引入hutool 的依赖:
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.20</version>
</dependency>
代码实现:
import cn.hutool.bloomfilter.BitMapBloomFilter;
public class HutoolBloomFilter {
public static void main(String[] args) {
// 一旦数量过大很容易出现内存异常:Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
int capacity = 1000;
// 初始化
BitMapBloomFilter filter = new BitMapBloomFilter(capacity);
for (int i = 0; i < capacity; i++) {
filter.add(String.valueOf(i));
}
System.out.println("存入元素为=={" + capacity + "}");
// 统计误判次数
int count = 0;
// 我在数据范围之外的数据,测试相同量的数据,判断错误率是不是符合我们当时设定的错误率
for (int i = capacity; i < capacity * 2; i++) {
if (filter.contains(String.valueOf(i))) {
count++;
}
}
System.out.println("误判元素为=={" + count + "}");
}
}
hutool 的布隆过滤器不支持 指定 错误比率,并且内存占用太高了,个人不建议使用。
4、通过redis实现布隆过滤器
https://blog.csdn.net/weixin_43888891/article/details/131406938
八、使用建议
比起容错率RedisBloom还是够可以的。 10000的长度0.01的容错,只有58个误判!比Guava 还要强,并且Guava 他并没有做持久化。