文章目录
- 一. PG体系结构
- 1.1 PG的体系结构概述
- 1.2 PostgreSQL进程概述
- 二. PG内存结构
- 三. PostgreSQL进程
- 3.1 后台进程
- 3.2 后端进程(backend)或服务器进程
- 3.3 用户进程或客户端进程
- 3.4 数据库服务器启动流程
- 四. PG逻辑结构
- 4.1 PostgreSQL cluster
- 4.2 database和cluster的关系
- 4.3 数据库实例和cluster的关系
- 4.4 PostgreSQL的tablespace
- 4.5 Sgment
- 4.6 Extent
- 4.7 Block
- 五. PG物理结构
- 5.1 cluster的物理结构图谱
- 5.2 cluster在文件系统上的结构
- 5.3 测试一个表空间及表的例子
- 参考:
一. PG体系结构
1.1 PG的体系结构概述
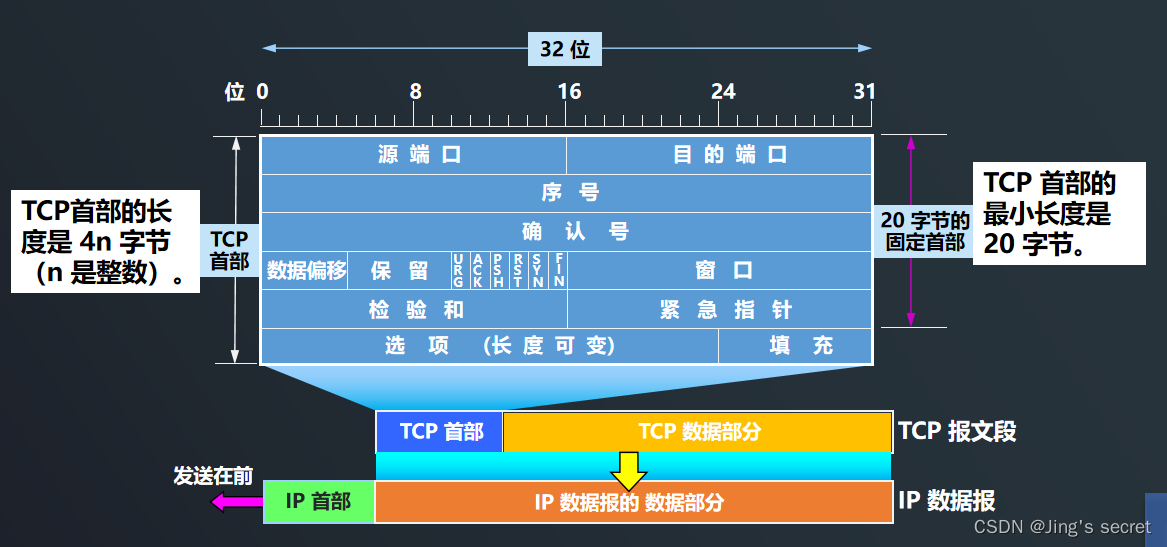
PostgreSQL的主要结构如下:
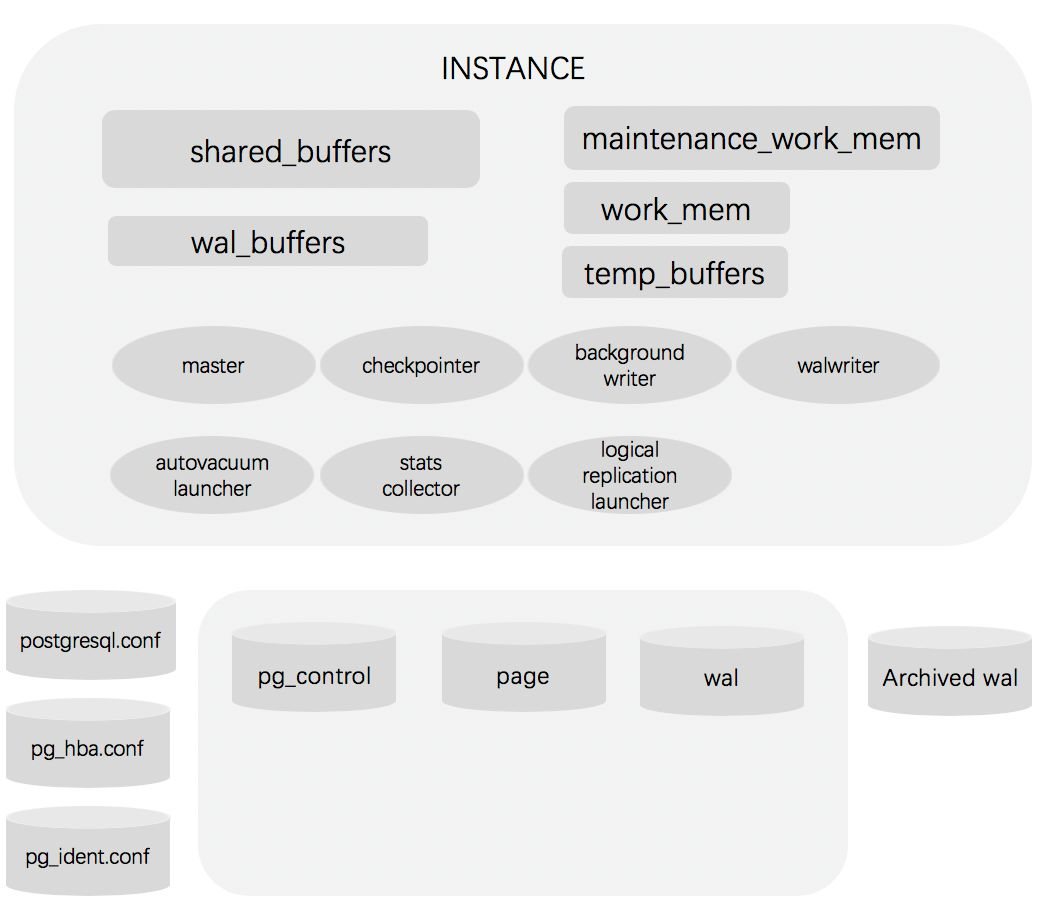
1.2 PostgreSQL进程概述
PostgreSQL进程结构图谱和分类:
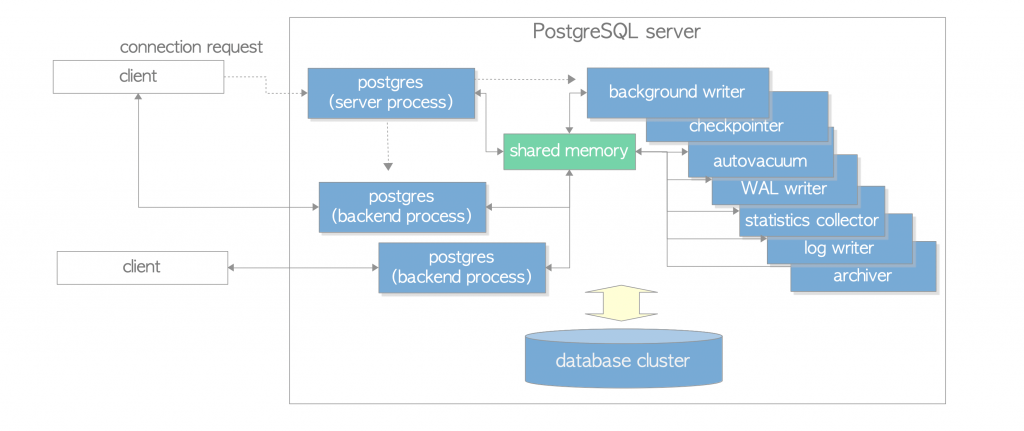
二. PG内存结构
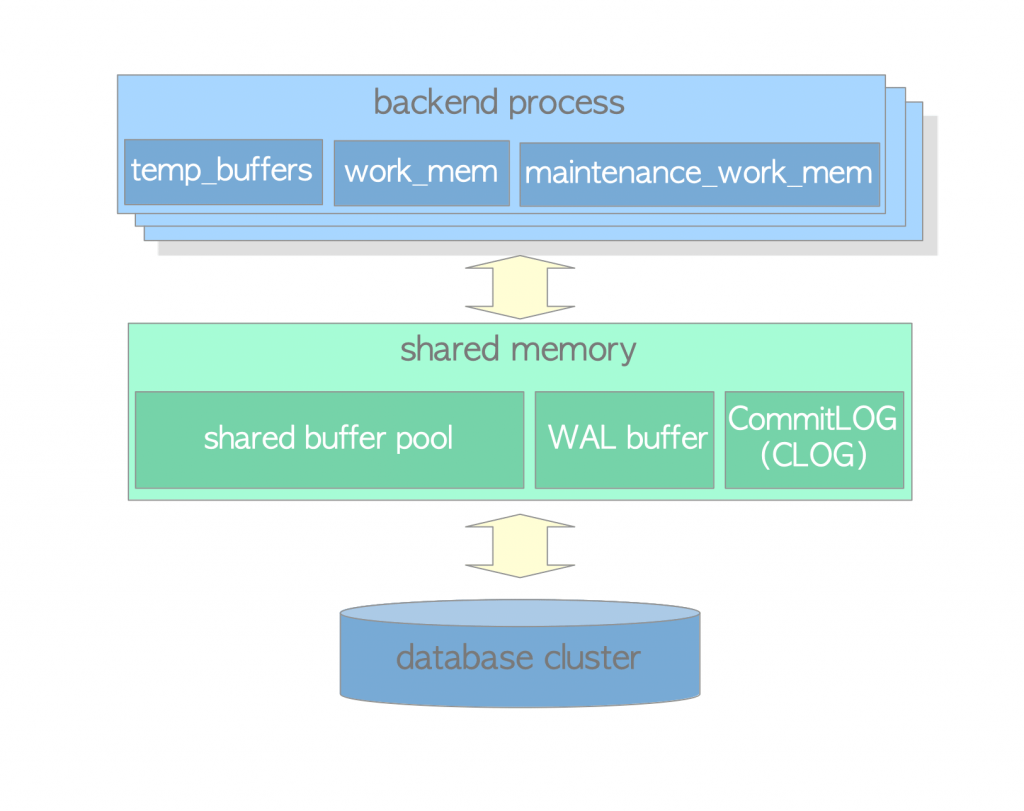
内存结构分为共享内存、本地内存。类似于Oracle的SGA和PGA。
共享内存
是指数据库服务器向操作系统申请的共享内存段,如数据共享缓冲区、日志缓冲区、事务提交日志内存区等,提供给PostgreSQL服务器的所有进程使用。
数据共享缓冲区:PostgreSQL把要操作和处理的表、index,读入到内存中,放到该区域缓存。类似于Oracle的database buffer cache。其大小由shared_buffers参数决定。
日志缓冲区:用于缓存数据库中对数据修改的日志记录,如:update table test set id=1这条SQL语句,数据库会把这个操作的信息记录在该内存区,将来写出到日志文件中,如果配置为归档模式,则最终写出到归档日志文件中去,用于恢复使用。其大小由wal_buffers参数决定。类似于Oracle的log buffer。
提交日志缓冲区:该内存区域有别于wal buffer日志缓冲区。它用于记录数据库中所有事务的提交状态,事务是否已经提交,是否已经终止,是否进行中,子事务等状态信息。用于MVCC。
本地内存
当我们和数据库建立一个连接请求时,数据库帮我们创建1个后端进程。并给该后端进程分配的内存区域,该内存区域只属于这一个后端进程使用,可以认为是私有的。用于处理和响应我们向数据库发起的请求操作。通常包含:工作区work mem、维护工作区、临时缓冲区。
工作区:该内存区用于处理客户端SQL语句请求的order by排序、distinct过滤、表合并连接merge-join、哈希连接hash-join操作等。由work_mem参数决定大小。
维护工作区:该内存区域用于处理重建索引reindex、vacuum空间回收操作、给表添加外键约束等。由maintenance_work_mem参数决定大小。
临时缓冲区:该内存区用于创建和访问临时表时,存放临时表的数据。该内存区和因为SQL中因为大表排序或hash table而在服务器上建立的临时文件(位于pgsql_tmp路径下)没有直接关系。由temp_buffers参数决定大小。
三. PostgreSQL进程
PostgreSQL数据库的进程可以分为三类:后台进程、后端进程或叫服务器进程、客户端进程或用户进程。
3.1 后台进程
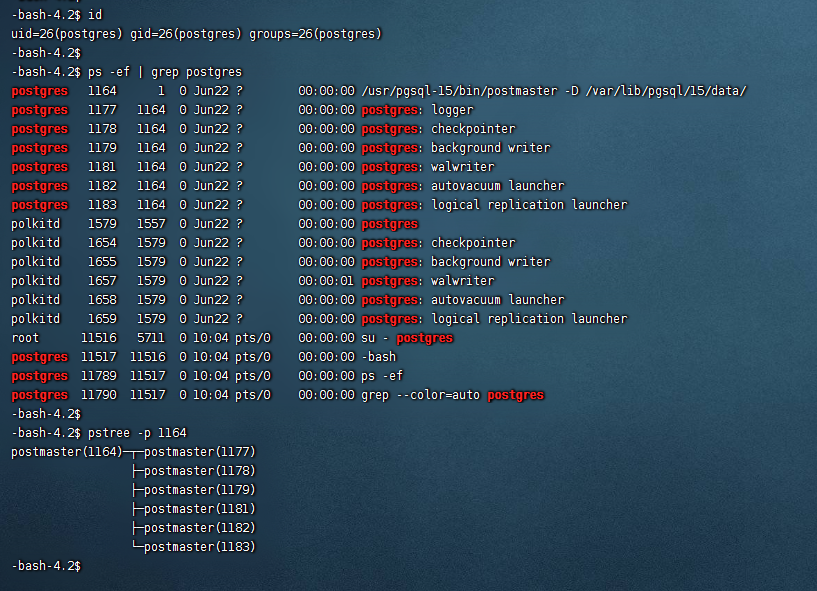
此处我的测试库因为有些功能还未安装,有些进程不存在。
-
/usr/pgsql-15/bin/postmaster -D /var/lib/pgsql/15/data/是数据库服务器的master进程,其它诸如checkpoint,background writer,walwrite,autovacuum launcher,stats collector,logical replication launcher都是由它fork的子进程。当然,数据库运行模式不同,配置不同,也可能有其它后台进程,如归档进程等。 -
postgres:PostgreSQL数据库的核心进程,也是整个cluster的父进程,该进程出现问题,整个cluster就over了。该进程由操作系统的守护进程1号进程派生。Linux下的1号进程是整个服务器的守护进程,类比于Java程序中的Object类,一切类的父类。 -
checkpointer:检查点进程,等价于Oracle的CKPT进程,负责完成数据库的检查点,通知数据库的写进程DBWR将内存中的脏数据写出到磁盘。 -
background writer:等价于Oracle的DBWR进程,负责将内存中的脏数据写出到磁盘。 -
walwriter:等价于Oracle的LGWR进程,负责将日志缓冲区中的记录关于数据库的修改的日志写出到日志文件中去,确保数据的修改不会丢失,用于恢复使用。 -
autovacuum launcher:自动清理工作进程。由于PostgreSQL不像Oracle那样有undo的机制,将数据被修改前的信息写入到undo,然后修改数据。PostgreSQL采取的是在原数据块上进行保留旧的数据,并作标记,等到将来修改提交生效之后,旧的数据(dead tuple翻译为死元组)不需要的话,就得清理,由该进程来完成。 -
stats collector:统计信息收集进程。用于及时的更新数据库中的统计信息,如表、index有多少条记录,数据分布等,给优化器提供最新的信息,便于优化器选择最优的执行计划。避免统计信息不准确,导致优化器选择错误的执行计划,导致SQL性能下降或偏差。 -
logical replication launcher:逻辑复制进程。用于完成逻辑复制的工作。 -
archiver:归档进程,等价于Oracle的ARCH进程,用于完成数据库日志文件的归档。当数据库配置了归档模式之后,可以看到该进程。
3.2 后端进程(backend)或服务器进程
当我们的应用程序和图形界面的客户端工具,连接到PostgreSQL数据库服务器时。master进程会为该应用程序创建1个服务器进程,用于处理和响应该客户端应用程序的请求。
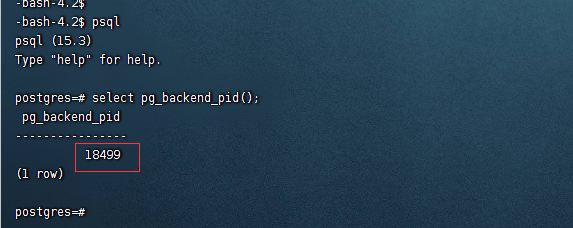
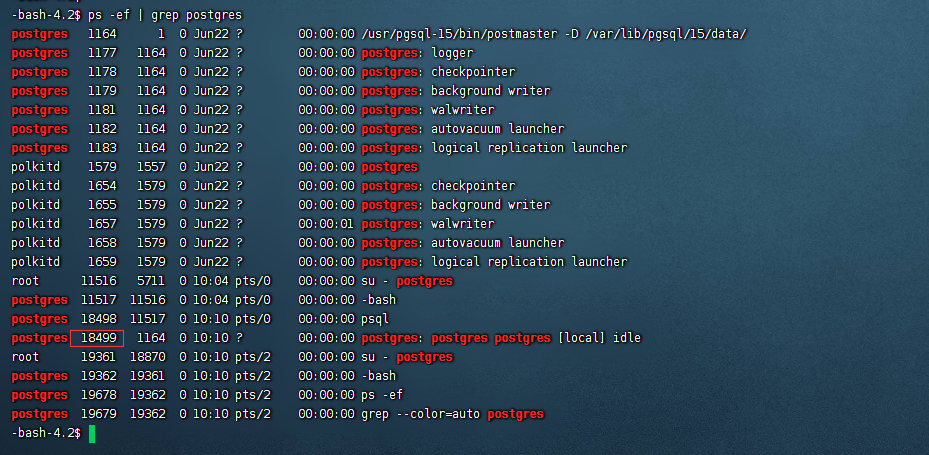
如上,可以看到服务器进程号是18499,通过select pg_backend_pid()查询。同时,看到服务器上该进程的父进程是1164,由 /usr/pgsql-15/bin/postmaster -D /var/lib/pgsql/15/data/这个主进程派生。
后端进程或服务器进程的数量由max_connections参数决定。
每一个后端进程一次只能访问一个数据库。它和客户端进程进行TCP通信,开户端断开之后,该进程自动回收消失。客户端重新连接或发起新连接时重新创建新的后端进程。
由于进程的创建或回收,比较消耗操作系统的资源,因此,多数情况下,应用系统都会通过连接池的方式和数据库建立连接。
从PostgreSQL官方给后端进程的命名可以看到还是一脉相承的,比如,我们查看当前会话所在的后端进程号或者叫服务器进程的时候,我们调用的是pg_backend_pid()函数,杀会话所在进程时,调用的是pg_terminate_backend(),或者pg_cancel_backend()。
3.3 用户进程或客户端进程
指的是连接数据库服务器的应用程序或者客户端工具等。
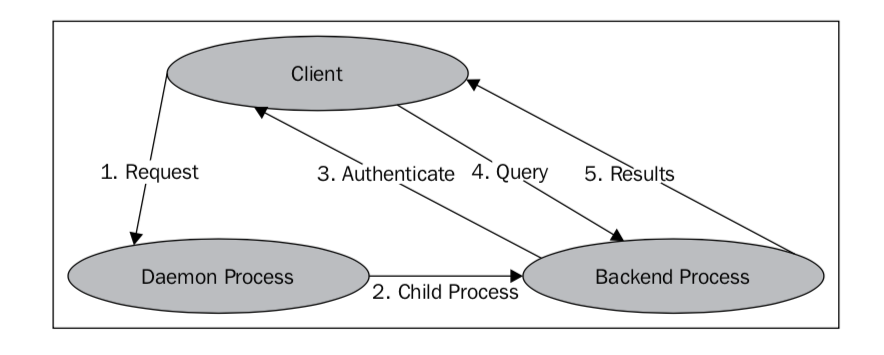
每个用户进程或者客户端进程对应一个服务端进程。
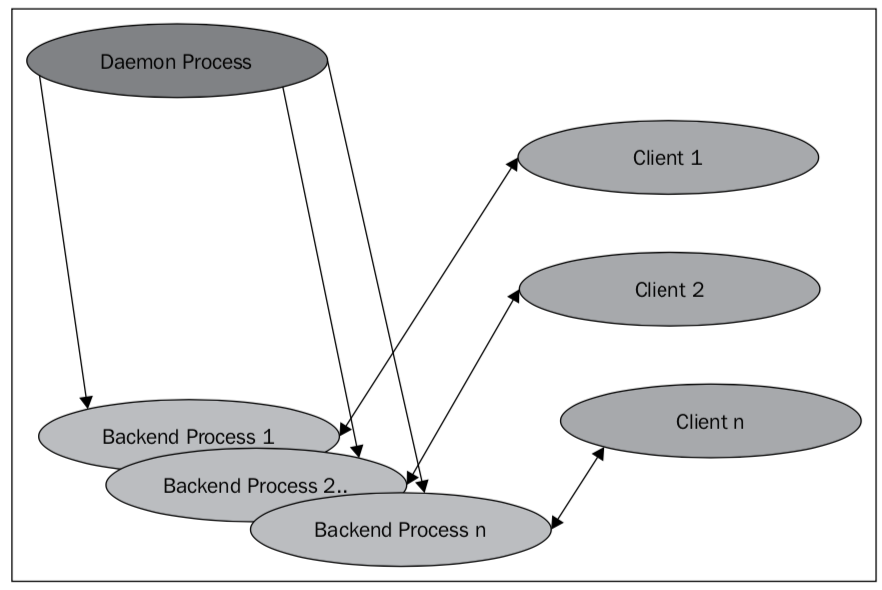
这2张图引自《PostgreSQL for DBA Architects》p21-22。
3.4 数据库服务器启动流程
当我们通过pg_ctl工具来启动PostgreSQL数据库时,先在操作系统上创建1个master进程,然后该进程派生出一系列的后台进程,同时该进程监听$PGDATA/postgresql.conf配置文件中指定的端口。并且,向操作系统申请内存,用于数据库的正常运行操作,处理客户端的连接请求操作处理。最后,数据库可以正常对外提供服务。
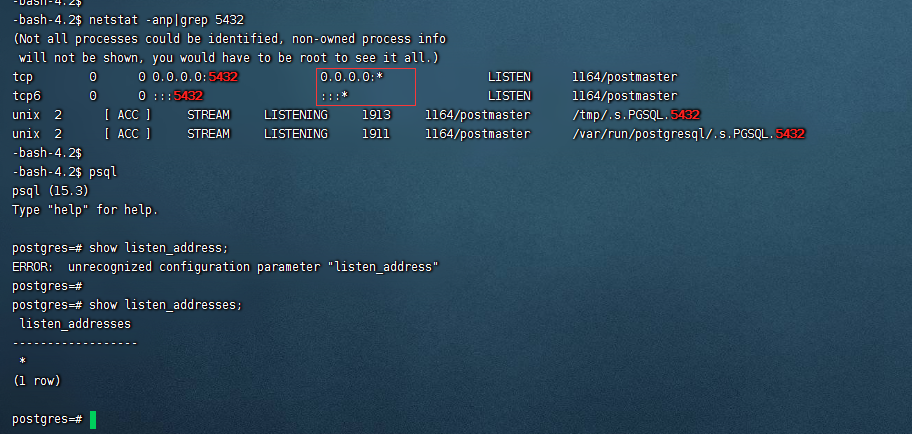
四. PG逻辑结构
PG逻辑结构图解:

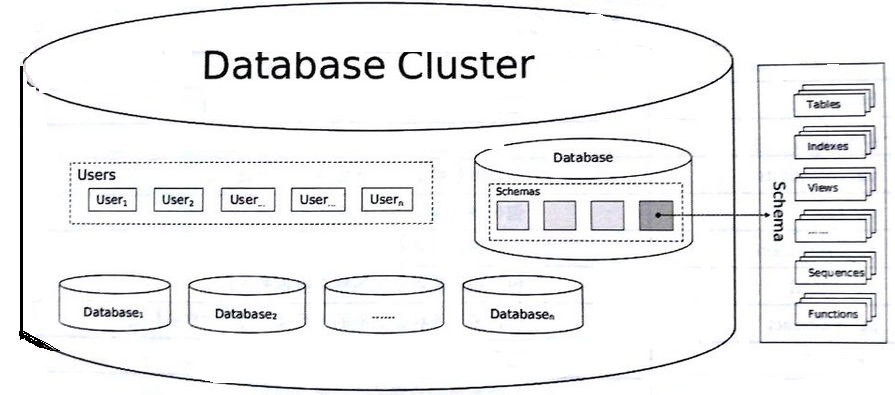
4.1 PostgreSQL cluster
当我们在一台服务器上安装部署并且初始化一个PostgreSQL数据库之后,严格的讲,其实是我们安装部署了一套PostgreSQL数据库软件,然后初始化了一个PostgreSQL的database cluster。这里的cluster是什么概念呢?
首先,这里的cluster完全是个逻辑上的概念,它是指一系列的数据库的集合。它所包含的数据库就是指,当我们以postmaster -D /var/lib/pgsql/15/data/ start来启动数据库cluster时,由这个-D参数指定,或者是PGDATA环境变量指定的路径下的所有的数据库的集合。当然,这么说太抽象了,其实,从物理上,我们可以这么说明和解释:
[root@sr-fe ~]# su - postgres
上一次登录:日 6月 25 10:10:40 CST 2023pts/2 上
-bash-4.2$
-bash-4.2$ env | grep PGDATA
PGDATA=/var/lib/pgsql/15/data
-bash-4.2$
-bash-4.2$
-bash-4.2$ ll /var/lib/pgsql/15/data
total 68
drwx------ 5 postgres postgres 33 Jun 9 19:17 base
-rw------- 1 postgres postgres 30 Jun 25 00:00 current_logfiles
drwx------ 2 postgres postgres 4096 Jun 25 10:10 global
drwx------ 2 postgres postgres 188 Jun 15 00:00 log
drwx------ 2 postgres postgres 6 Jun 9 19:17 pg_commit_ts
drwx------ 2 postgres postgres 6 Jun 9 19:17 pg_dynshmem
-rw------- 1 postgres postgres 4574 Jun 12 10:28 pg_hba.conf
-rw------- 1 postgres postgres 1636 Jun 9 19:17 pg_ident.conf
drwx------ 4 postgres postgres 68 Jun 22 22:16 pg_logical
drwx------ 4 postgres postgres 36 Jun 9 19:17 pg_multixact
drwx------ 2 postgres postgres 6 Jun 9 19:17 pg_notify
drwx------ 2 postgres postgres 6 Jun 9 19:17 pg_replslot
drwx------ 2 postgres postgres 6 Jun 9 19:17 pg_serial
drwx------ 2 postgres postgres 6 Jun 9 19:17 pg_snapshots
drwx------ 2 postgres postgres 6 Jun 12 10:28 pg_stat
drwx------ 2 postgres postgres 6 Jun 9 19:17 pg_stat_tmp
drwx------ 2 postgres postgres 18 Jun 9 19:17 pg_subtrans
drwx------ 2 postgres postgres 6 Jun 9 19:17 pg_tblspc
drwx------ 2 postgres postgres 6 Jun 9 19:17 pg_twophase
-rw------- 1 postgres postgres 3 Jun 9 19:17 PG_VERSION
drwx------ 3 postgres postgres 60 Jun 9 19:17 pg_wal
drwx------ 2 postgres postgres 18 Jun 9 19:17 pg_xact
-rw------- 1 postgres postgres 88 Jun 9 19:17 postgresql.auto.conf
-rw------- 1 postgres postgres 29451 Jun 12 10:25 postgresql.conf
-rw------- 1 postgres postgres 58 Jun 22 22:16 postmaster.opts
-rw------- 1 postgres postgres 95 Jun 22 22:16 postmaster.pid
-bash-4.2$
-bash-4.2$ oid2name
All databases:
Oid Database Name Tablespace
--------------------------------
5 postgres pg_default
4 template0 pg_default
1 template1 pg_default
-bash-4.2$
-bash-4.2$ psql
psql (9.2.24, server 15.3)
WARNING: psql version 9.2, server version 15.0.
Some psql features might not work.
Type "help" for help.
postgres=# \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+-------------+-------------+-----------------------
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
(3 rows)
postgres=# select oid,datname from pg_database ;
oid | datname
-----+-----------
5 | postgres
1 | template1
4 | template0
(3 rows)
postgres=#
4.2 database和cluster的关系
数据库是指一些列数据库对象的集合,比如表,index,view,function等这些数据库对象隶属于一个特定的数据库。
cluster指的是一些列数据库的集合。比如:一个cluster初始化之后,包含3个默认数据库:postgres,默认的管理数据库;template0,默认的不可修改的空数据库;template1,默认的模板数据库,当我们创建数据库时,会参照该数据库来创建。
当我们在template1模板数据库中创建和安装1个数据库插件extension,uuid之后,再去创建新的数据库,那么新数据库中就会自动包含该uuid这个extension。
1个cluster可以包含多个数据库,反过来1个database只能隶属于1个cluster。
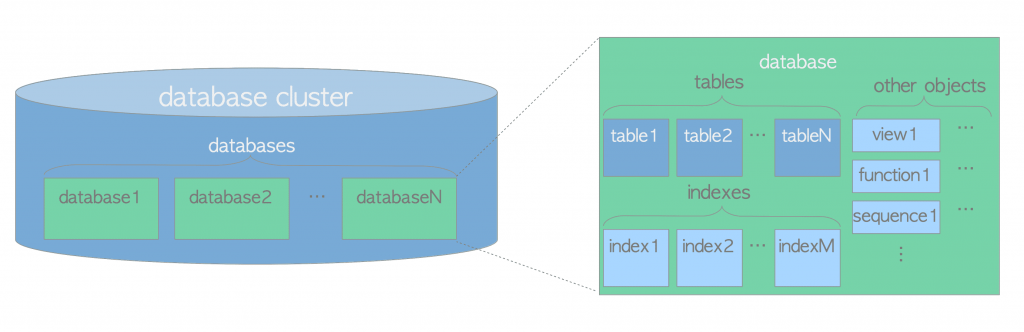
4.3 数据库实例和cluster的关系
我们定义数据库实例是指一堆PostgreSQL的后台进程和内存结构,cluster指的是我们在初始化数据库时,指定的PGDATA环境变量指向的操作系统上的那个路径下的一堆的文件。
一个数据库实例在其一个生命周期内(从启动到关闭)只能“挂载”一个数据库cluster,反之,一个cluster也只能被一个实例挂载访问。二者之间是严格的一对一关系。
但是,在一台服务器上,我们可以安装一套PostgreSQL数据库软件,用这个数据库软件可以创建多个实例和多个cluster。每个实例对应于一个cluster。只要每个cluster所指定的监听端口不同,我们就可以同时运行多个实例和cluster。
如:我们可以在这套环境上再初始化一个实例和cluster,将其指向另外一个监听端口即可。
4.4 PostgreSQL的tablespace
定义:
tablespace依然是一个逻辑概念,它是隶属于cluster的。
查看:
通过pg_tablespace字典表来查看cluster下表空间的信息,或者是\db命令也可查看表空间的信息;

默认表空间:
每个cluster默认情况下有2个表空间,分别命名为pg_default用于存放各个数据库私有的数据库对象,pg_global用于存放cluster全局共享的数据库对象信息,例如:cluster中数据库本身的信息,表空间的信息,数据库订阅信息,数据库复制信息,数据库认证授权信息、控制文件等。
专用表空间:
pg_global表空间是专表空间专用的,只能存放全局共享的数据库对象,不能存放用户数据,否则报错:
pg_default,表空间,默认存放cluster下所有数据库的所有数据库对象。这一点儿上,倒是有点儿类似于Oracle数据库的专表空间专用。
表空间和数据库的关系:一个表空间可以给多个数据库使用,一个数据库里的不同数据库对象也可以存放在不同的表空间下。表空间和数据库的关系,不严格的讲,可以说是多对多的关系。不像Oracle数据库中,一个数据库可以包含多个表空间,且每个表空间只能属于一个数据库使用。
如何创建表空间:OS上路径需提前创建,postgres用户得有读写操作系统文件系统权限,数据库管理员权限。
-- 不要把表空间目录放在data目录下
-bash-4.2$ psql
psql (9.2.24, server 15.3)
WARNING: psql version 9.2, server version 15.0.
Some psql features might not work.
Type "help" for help.
postgres=#
postgres=# create tablespace newtbs location '/var/lib/pgsql/15/data/tbs_dir';
WARNING: tablespace location should not be inside the data directory
CREATE TABLESPACE
postgres=#
创建库表时指定表空间:
create database newdb tablespace newtbs;
create table test_tbs(id int) tablespace newtbs ;
修改表空间:
数据库创建之后,或者数据库对象(表、index等)创建之后,也可以分别通过alter database/table/index来修改表空间信息。
表空间作用:
主要用于逻辑上隔离数据库对象,或者用于数据库存储空间规划或迁移存储。想要通过表空间的设置,进而对于数据库性能提升?作用不大,毕竟现在基本上都是直接上SSD(Solid State Drive )存储给数据库使用。
4.5 Sgment
一个段是分配给一个逻辑结构(一个表、一个索引或其他对象)的一组区,是数据库对象使用的空间的集合;段可以有表段、索引段、回滚段、临时段和高速缓存段等。
4.6 Extent
区是数据库存储空间分配的一个逻辑单位,它由连续数据块所组成。第一个段是由一个或多个盘区组成。当一段中间所有空间已完全使用,PostgreSQL为该段分配一个新的范围。
4.7 Block
数据块是PostgreSQL 管理数据文件中存储空间的单位,为数据库使用的I/O的最小单位,是最小的逻辑部件。默认值8K。
五. PG物理结构
5.1 cluster的物理结构图谱
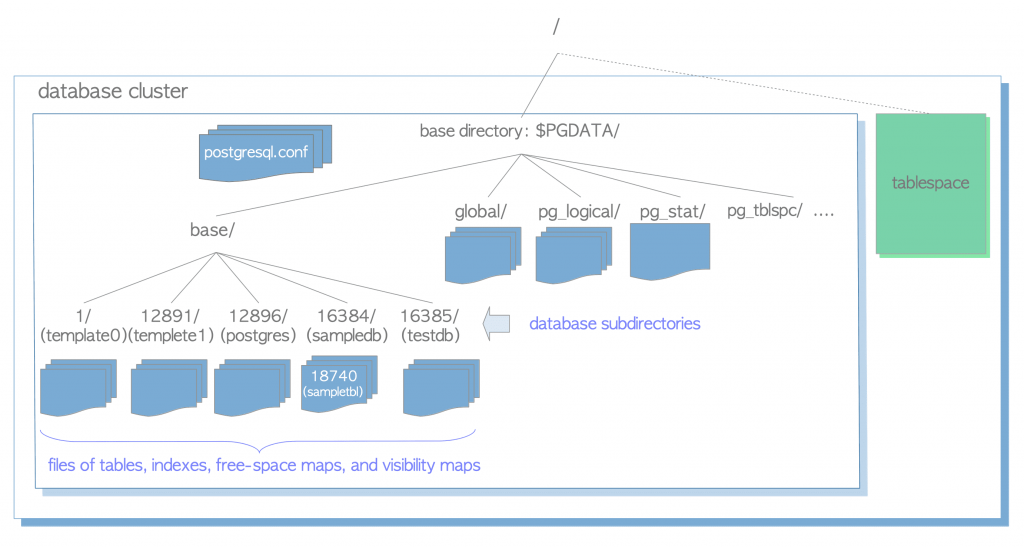
5.2 cluster在文件系统上的结构
目录文件概述:
base --存放默认数据库的目录
global --存放的数据库相关的字典视图或者表文件
pg_commit_ts --事务存放的提交的时间戳数据
pg_dynshmem --动态内存分配存放的空间(dynamic share memeory)
pg_hba.conf --基于主机的配置文件
pg_ident.conf --基于对等认证的配置文件
pg_logical --存储数据库内部状态的逻辑解码数据
pg_multixact --存放多事务状态的数据
pg_notify --消息通知目录(LISTEN状态目录)
pg_replslot --存放复制槽的数据
pg_serial --提交的可串行化事务的状态数据
pg_snapshots --执行导出快照函数时的状态信息数据
pg_stat --统计信息目录
pg_stat_tmp --临时统计信息目录
pg_subtrans --子事务目录
pg_tblspc --表空间映射目录
pg_twophase --两阶段提交状态的数据
PG_VERSION --存放主版本编号的文件
pg_wal --存储 WAL 文件的目录
pg_xact --事务提交的状态数据
postgresql.auto.conf --存储通过 ALTER SYSTEM 命令修改的参数文件(可以手动修改)
postgresql.conf --数据库的参数配置文件
postmaster.opts --上一次数据库启动状态的命令
postmaster.pid --存放当前数据库的主进程编号及相关目录及端口的信息
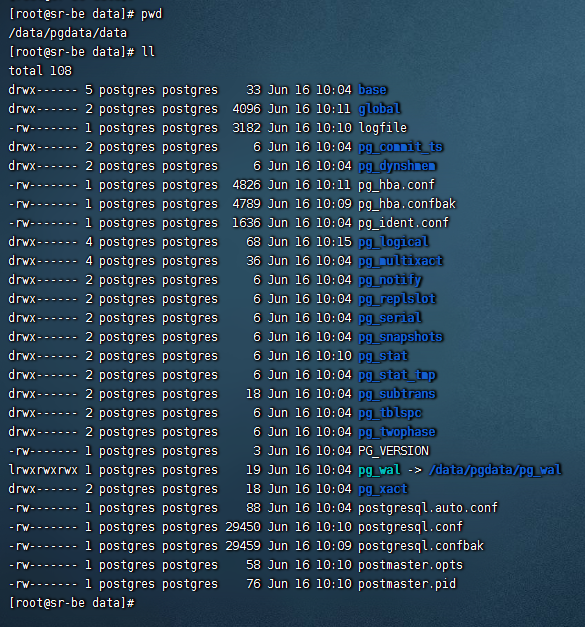
数据文件:
$PGDATA/base:用于存放当前cluster下所有的数据库,数字化命名的路径表示各个数据库,每个数字表示数据库的oid。一些创建数据库时指定了表空间的库会存在表空间目录下,而不是这个目录。
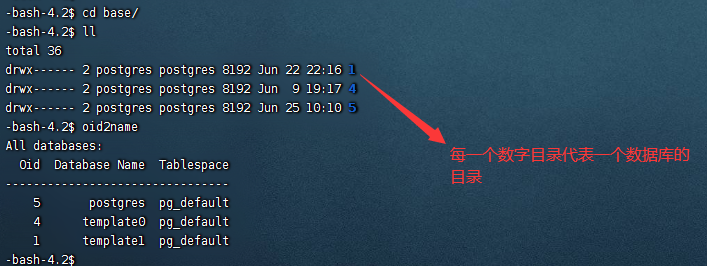
关于文件名中类似如1213_fsm、1213_vm的文件,表示空闲空间映射文件(free space map),可见性映射文件(visibility map)。
表空间:
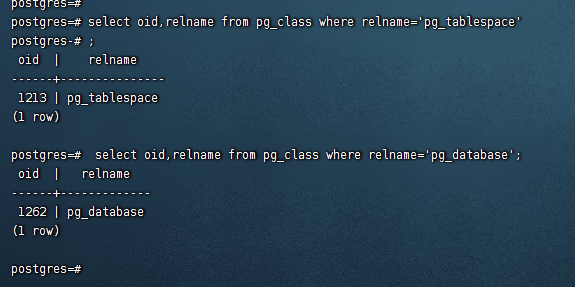
global:用于存放cluster级别共享的全局表,如pg_database,pg_tablespace表,其文件命名依旧采用oid的数字化格式。
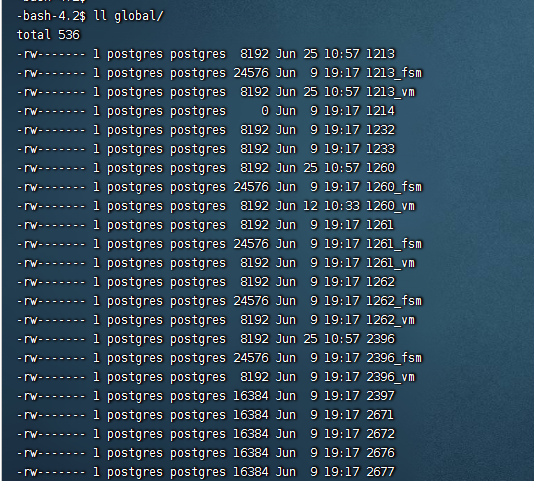
我们可以从数据库中验证这些cluster级别的共享系统表的oid和global下的数字文件名匹配:
5.3 测试一个表空间及表的例子
代码:
create tablespace testtbs location '/var/lib/pgsql/newtbs';
create database newdb tablespace testtbs;
\c newdb;
create table test_tbs(id bigint) tablespace newtbs ;
insert into test_tbs select * from generate_series(1,1000000000);
测试记录:
postgres=# create tablespace testtbs location '/var/lib/pgsql/newtbs';
CREATE TABLESPACE
postgres=# create database newdb tablespace testtbs;
CREATE DATABASE
postgres=#
postgres=#
postgres=# \c newdb;
psql (9.2.24, server 15.3)
WARNING: psql version 9.2, server version 15.0.
Some psql features might not work.
You are now connected to database "newdb" as user "postgres".
newdb=# create table test_tbs(id bigint) tablespace newtbs ;
CREATE TABLE
newdb=# insert into test_tbs select * from generate_series(1,1000000000);
INSERT 0 1000000000
newdb=#

表的数据达到1G后会分割文件,所以会有这么多的文件
表大小达34GB
SELECT pg_size_pretty(pg_total_relation_size('test_tbs'));

SELECT datname, oid as database_id FROM pg_database WHERE datname = 'newdb';
SELECT nspname, oid as schema_id FROM pg_namespace WHERE nspname = 'public';
SELECT relname, oid as table_id FROM pg_class WHERE relname = 'test_tbs';
SELECT pg_relation_filepath('public.test_tbs');

参考:
- https://github.com/digoal/blog
- https://blog.csdn.net/m0_50880099/article/details/124431279
- http://www.taodudu.cc/news/show-1287235.html?action=onClick
- https://www.modb.pro/mes/1820
- https://www.modb.pro/db/389130
- http://www.knockatdatabase.com/2021/04/01/postgresql-architecture/#1