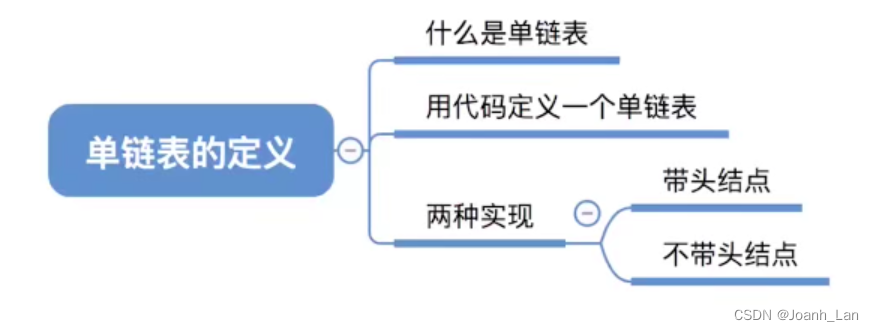
数据结构–单链表的定义
本节的学习目标:
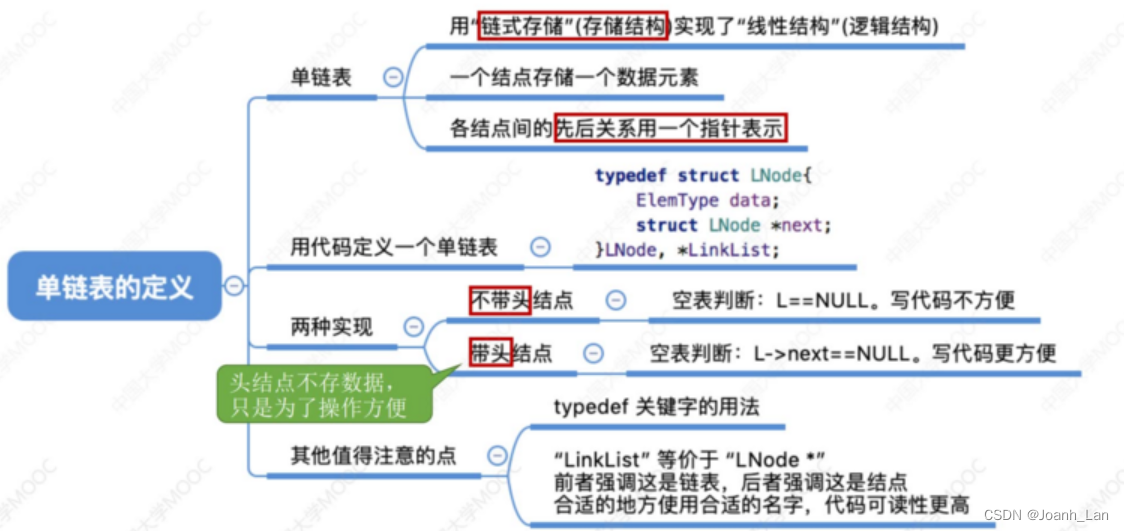
单链表的定义(如何用代码实现)
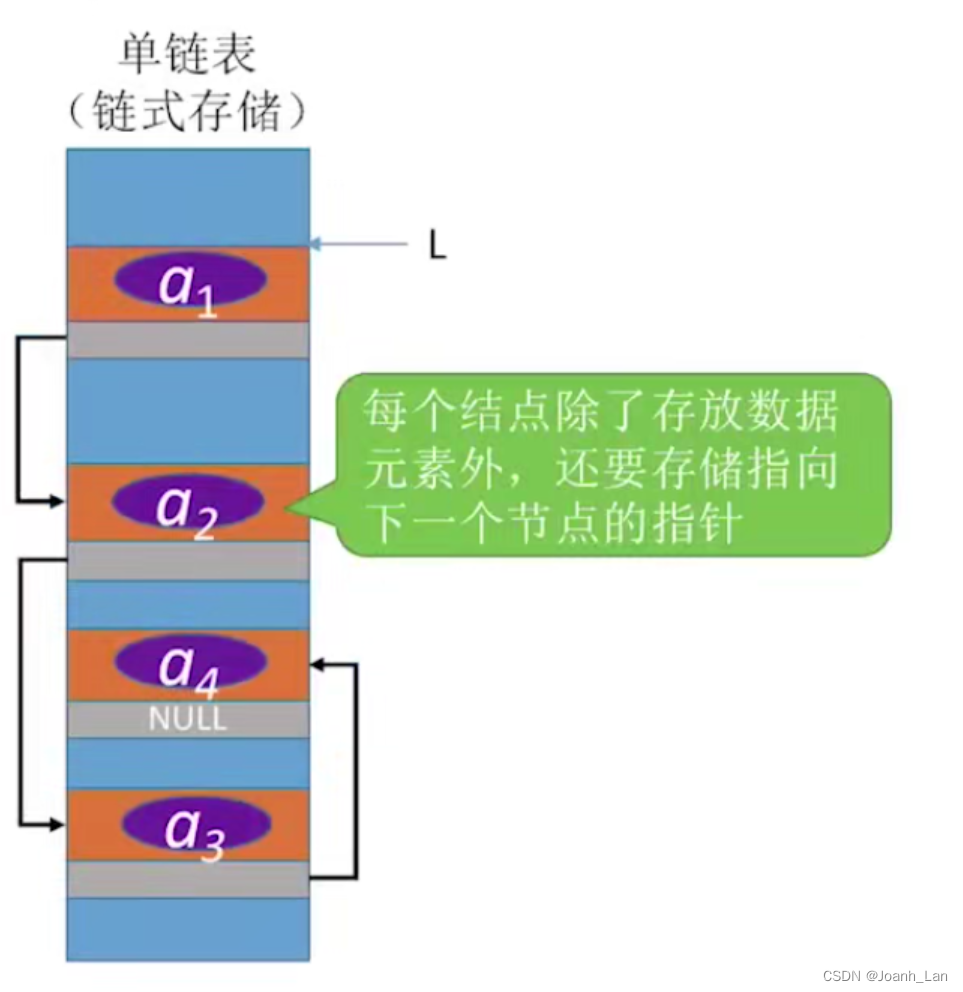
优点:不要求大片连续空间,改变容量方便
缺点:不可随机存取,要耗费一定空间存放指针
代码实现
struct LNode
{
ElemType data; //数据域
struct LNode *next; //指针域
};
struct LNode *p = (struct LNode*)malloc(sizeof(struct LNode));
//增加一个新的结点:在内存中申请一个结点所需空间,并用指针p指向这个结点
为了方便 我们经常使用typedef
t y p e d e f < 数据类型 > < 别名 > \color{purple}typedef <数据类型> <别名> typedef<数据类型><别名>
代码一:
struct LNode
{
ElemType data; //数据域
struct LNode *next; //指针域
};
typedef struct LNode LNode;
typedef struct LNode* LinkList;
代码二:
typedef struct LNode
{
ElemType data; //数据域
struct LNode *next; //指针域
} LNode, *LinkList;
代码一与代码二是等价的
我们一般使用代码二
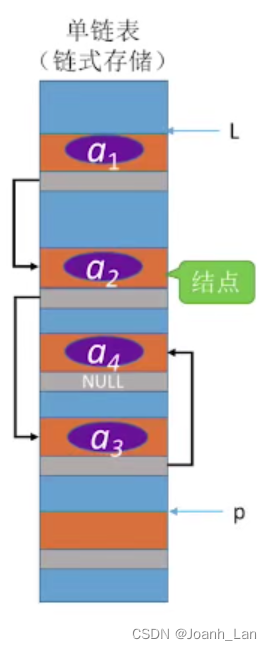
如何表示一个单链表
要表示一个单链表时,只需声明一个头指针L,指向单链表的第一个结点
LNode * L; //声明一个指向单链表第一个结点的指针
//或:
LinkList L; //声明一个指向单链表第一个结点的指针
// 这个可读性更强
不带头结点的单链表
typedef struct LNode
{
ElemType data; //每个节点存放一个数据元素
struct LNode *next; //指针指向下一个节点
}LNode, *LinkList;
bool Empty(LinkList L) //判断单链表是否为空
{
return L == NULL;
}
void InitList(LinkList&L)
{
L = NULL;
}
int main()
{
LinkList L; //声明一个指向单链表的指针
InitList(L); //初始化一个空表
// ... ...
return 0;
}
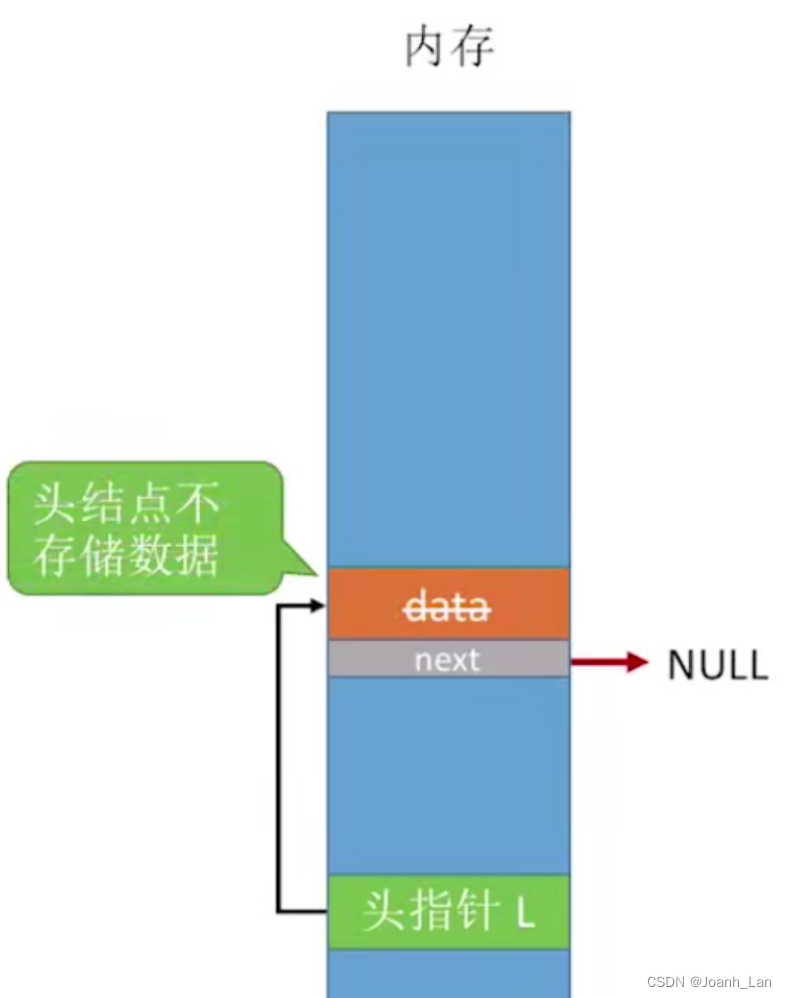
带头结点的单链表
typedef struct LNode
{
ElemType data; //每个节点存放一个数据元素
struct LNode *next; //指针指向下一个节点
}LNode, *LinkList;
bool Empty(LinkList L) //判断单链表是否为空
{
return L->next == NULL;
}
bool InitList(LinkList&L)
{
L = (LNode *)malloc(sizeof(LNode)); //分配一个头结点
if (L == NULL) //内存不足,分配失败
return false;
L->next = NULL; //头结点之后暂时还没有节点
return true;
}
int main()
{
LinkList L; //声明一个指向单链表的指针
InitList(L); //初始化一个空表
// ... ...
return 0;
}
不带头 VS 带头
带头结点,写代码更方便
不带头结点,写代码更麻烦
对第一个数据结点和后续数据结点的处理需要用不同的代码逻辑
对空表和非空表的处理需要用不同的代码逻辑
一般我们使用带头结点的单链表
知识点回顾与重要考点