sharding-jdbc是sharding-sphere下的一个模块,可以理解为增强版的jdbc,用于解决分库分表、读写分离问题,本文基于4.1.1版本进行说明数据分片功能的流程
该版本提供了如下功能
1.数据分片(包括强制路由功能)
2.读写分离
3.编排治理(接入配置中心和配置动态刷新)
4.分布式事务
5.数据脱敏
本文着重于数据分片功能的解析
1.相关概念
- 表相关概念
| 名词 | 概念 |
|---|---|
| 逻辑表 | 水平拆分后有相同逻辑和数据结构的表的总称,如:t_oder_0~9,逻辑表为t_oder |
| 真实表 | 在数据库真实存在的表 |
| 数据节点 | 数据分片的最小单元,由数据源+表组成 如ds_0.t_order_0 |
| 绑定表 | 指分片规则一致的两个表,如订单和订单明细通过用户或订单id进行分片,绑定后会减少路由sql数量 |
| 广播表 | 分片数据源中都存在的表,适用于数据量不大且需要与海量数据关联查询的场景,如元数据、字典表等 |
- 分片相关概念
| 名词 | 概念 |
|---|---|
| 分片键 | 用于水平拆分的字段,支持多个 |
| 分片算法 | 具体的数据路由策略,目前提供4种分片算法 |
| 用于处理单一分片键的场景,支持=&IN,实现策略PreciseShardingAlgorithm |
| 用于处理单一分片键的场景,支持between and、>、<、>=、<=场景,实现策略RangeShardingAlgorithm |
| 用于处理多分片键的场景,需要开发者自行处理路由逻辑,实现策略ComplexKeysShardingAlgorithm |
| 可用于sharding-jdbc不支持的sql场景,如 insert into xx select * from xx where ...,配合HintManager(本地线程)使用 |
| 分片策略 | 分片算法封装,可表示数据源、数据表的分片策略,配置时关注 |
| StandardShardingStrategy 单一分片键场景使用 |
| ComplexShardingStrategy 复合分片策略,多分片键场景使用 |
| InlineShardingStrategy 提供groovy表达式的单一分片键处理,减少冗余的代码开发 |
| HintShardingStrategy 不通过解析sql传入分片信息,直接从本地线程取 |
| NoneShardingStrategy 返回所有可选的节点 |
层级关系为 分片引擎->分片策略->分片算法
2.接入方式
1.原生接入
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>${sharding-sphere.version}</version>
</dependency> |
引入依赖后,可以使用yaml配置解析为bean的模式,也可以直接使用bean模式进行配置
-
yaml配置,摘自官方示例
dataSources: #数据源配置,支持多个数据源 ds_0: !!com.zaxxer.hikari.HikariDataSource #<!!数据库连接池实现类> driverClassName: com.mysql.jdbc.Driver #数据库驱动名 jdbcUrl: jdbc:mysql://localhost:3306/demo_ds_0?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8 #数据库url链接 username: root #数据库用户名 password: #数据库密码 ds_1: !!com.zaxxer.hikari.HikariDataSource driverClassName: com.mysql.jdbc.Driver jdbcUrl: jdbc:mysql://localhost:3306/demo_ds_1?serverTimezone=UTC&useSSL=false&useUnicode=true&characterEncoding=UTF-8 username: root password: shardingRule: tables: #数据分片规则,可配置多个逻辑表 t_order: #逻辑表名称 actualDataNodes: ds_${0..1}.t_order_${0..1} # 数据节点,由数据源名+表名组成,小数点分割,支持inline表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点,用于广播表或分库表 tableStrategy: #分表逻辑,同分库策略 standard: #单分片键 shardingColumn: order_id #分片列名 preciseAlgorithmClassName: org.apache.shardingsphere.example.algorithm.PreciseModuloShardingTableAlgorithm #精确分片算法 =&IN rangeAlgorithmClassName: org.apache.shardingsphere.example.algorithm.RangeModuloShardingTableAlgorithm # 范围分片 between keyGenerator: type: SNOWFLAKE #自增列生成类型,可自定义id生成 column: order_id # 自增列名称 props: worker.id: 123 t_order_item: actualDataNodes: ds_${0..1}.t_order_item_${0..1} tableStrategy: standard: shardingColumn: order_id preciseAlgorithmClassName: org.apache.shardingsphere.example.algorithm.PreciseModuloShardingTableAlgorithm rangeAlgorithmClassName: org.apache.shardingsphere.example.algorithm.RangeModuloShardingTableAlgorithm keyGenerator: type: SNOWFLAKE column: order_item_id props: worker.id: 123 bindingTables: - t_order,t_order_item #绑定表规则表,需要保证绑定表间的插入逻辑、数据节点一致,好处是联表查询时不会出现笛卡尔积的情况 broadcastTables: #广播表 - t_address defaultDatabaseStrategy: #默认数据库分片策略,同分库策略 standard: shardingColumn: user_id preciseAlgorithmClassName: org.apache.shardingsphere.example.algorithm.PreciseModuloShardingDatabaseAlgorithm rangeAlgorithmClassName: org.apache.shardingsphere.example.algorithm.RangeModuloShardingDatabaseAlgorithmprops: #属性配置 sql.show: #是否开启SQL显示,默认值: false executor.size: #工作线程数量,默认值: CPU核数 max.connections.size.per.query: # 每个查询可以打开的最大连接数量,默认为1, check.table.metadata.enabled: #是否在启动时检查分表元数据一致性,默认值: false
max.connections.size.per.query配置实际使用时需要关注,相关文章
2.spring接入
依赖引入
<!-- for spring boot -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<!-- for spring namespace -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-namespace</artifactId>
<version>${sharding-sphere.version}</version>
</dependency> |
配置示例
spring.shardingsphere.datasource.names= #数据源名称,多数据源以逗号分隔 spring.shardingsphere.datasource.<data-source-name>.type= #数据库连接池类名称 spring.shardingsphere.datasource.<data-source-name>.driver-class-name= #数据库驱动类名 spring.shardingsphere.datasource.<data-source-name>.url= #数据库url连接 spring.shardingsphere.datasource.<data-source-name>.username= #数据库用户名 spring.shardingsphere.datasource.<data-source-name>.password= #数据库密码 spring.shardingsphere.datasource.<data-source-name>.xxx= #数据库连接池的其它属性 spring.shardingsphere.sharding.tables.<logic-table-name>.actual-data-nodes= #由数据源名 + 表名组成,以小数点分隔。多个表以逗号分隔,支持inline表达式。缺省表示使用已知数据源与逻辑表名称生成数据节点,用于广播表(即每个库中都需要一个同样的表用于关联查询,多为字典表)或只分库不分表且所有库的表结构完全一致的情况 #分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一 #用于单分片键的标准分片场景 spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.standard.sharding-column= #分片列名称 spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.standard.precise-algorithm-class-name= #精确分片算法类名称,用于=和IN。该类需实现PreciseShardingAlgorithm接口并提供无参数的构造器 spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.standard.range-algorithm-class-name= #范围分片算法类名称,用于BETWEEN,可选。该类需实现RangeShardingAlgorithm接口并提供无参数的构造器 #用于多分片键的复合分片场景 spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.complex.sharding-columns= #分片列名称,多个列以逗号分隔 spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.complex.algorithm-class-name= #复合分片算法类名称。该类需实现ComplexKeysShardingAlgorithm接口并提供无参数的构造器 #行表达式分片策略 spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.inline.sharding-column= #分片列名称 spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.inline.algorithm-expression= #分片算法行表达式,需符合groovy语法 #Hint分片策略 spring.shardingsphere.sharding.tables.<logic-table-name>.database-strategy.hint.algorithm-class-name= #Hint分片算法类名称。该类需实现HintShardingAlgorithm接口并提供无参数的构造器 #分表策略,同分库策略 spring.shardingsphere.sharding.tables.<logic-table-name>.table-strategy.xxx= #省略 spring.shardingsphere.sharding.tables.<logic-table-name>.key-generator.column= #自增列名称,缺省表示不使用自增主键生成器 spring.shardingsphere.sharding.tables.<logic-table-name>.key-generator.type= #自增列值生成器类型,缺省表示使用默认自增列值生成器。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID spring.shardingsphere.sharding.tables.<logic-table-name>.key-generator.props.<property-name>= #属性配置, 注意:使用SNOWFLAKE算法,需要配置worker.id与max.tolerate.time.difference.milliseconds属性。若使用此算法生成值作分片值,建议配置max.vibration.offset属性 spring.shardingsphere.sharding.binding-tables[0]= #绑定表规则列表 spring.shardingsphere.sharding.binding-tables[1]= #绑定表规则列表 spring.shardingsphere.sharding.binding-tables[x]= #绑定表规则列表 spring.shardingsphere.sharding.broadcast-tables[0]= #广播表规则列表 spring.shardingsphere.sharding.broadcast-tables[1]= #广播表规则列表 spring.shardingsphere.sharding.broadcast-tables[x]= #广播表规则列表 spring.shardingsphere.sharding.default-data-source-name= #未配置分片规则的表将通过默认数据源定位 spring.shardingsphere.sharding.default-database-strategy.xxx= #默认数据库分片策略,同分库策略 spring.shardingsphere.sharding.default-table-strategy.xxx= #默认表分片策略,同分表策略 spring.shardingsphere.sharding.default-key-generator.type= #默认自增列值生成器类型,缺省将使用org.apache.shardingsphere.core.keygen.generator.impl.SnowflakeKeyGenerator。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID spring.shardingsphere.sharding.default-key-generator.props.<property-name>= #自增列值生成器属性配置, 比如SNOWFLAKE算法的worker.id与max.tolerate.time.difference.milliseconds spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.master-data-source-name= #详见读写分离部分 spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.slave-data-source-names[0]= #详见读写分离部分 spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.slave-data-source-names[1]= #详见读写分离部分 spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.slave-data-source-names[x]= #详见读写分离部分 spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.load-balance-algorithm-class-name= #详见读写分离部分 spring.shardingsphere.sharding.master-slave-rules.<master-slave-data-source-name>.load-balance-algorithm-type= #详见读写分离部分 spring.shardingsphere.props.sql.show= #是否开启SQL显示,默认值: false spring.shardingsphere.props.executor.size= #工作线程数量,默认值: CPU核数 |
3.数据分片流程解析
sharding-jdbc主要执行流程如下
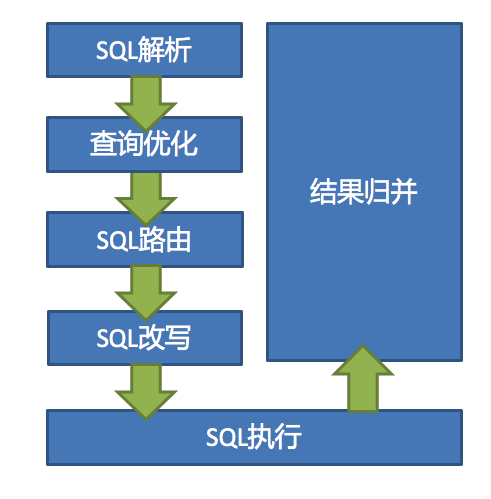
spring加载执行流程梳理
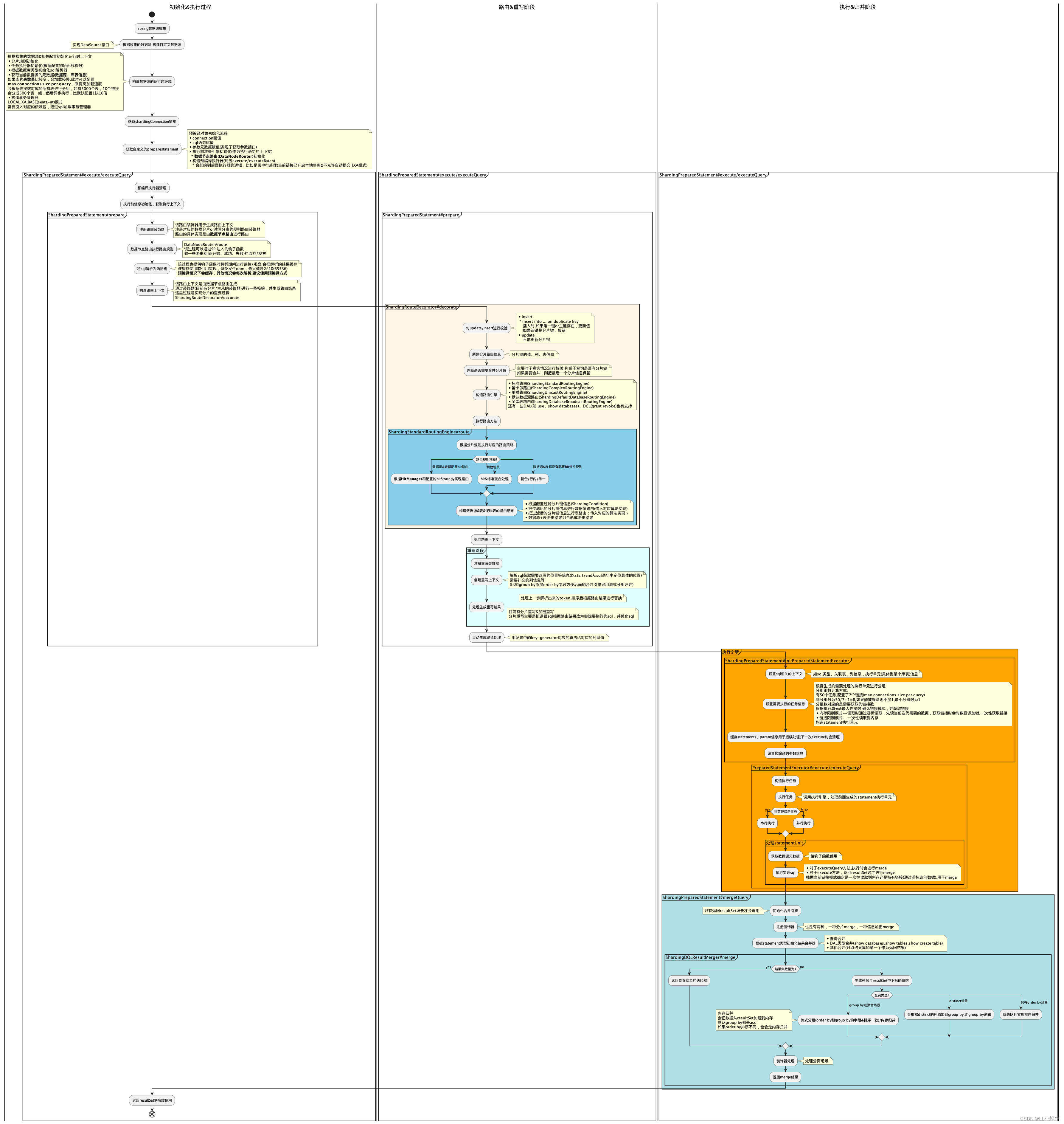
实际使用时主要关注
- max.connection.size.per.query的配置(执行和初始化阶段都会有影响)
- 尽量使用预编译(解析sql时使用)
- 有绑定关系的表应该配置上
- 查询时尽量避免出现内存归并的方式导致OOM
- 如果当前链接已开启事务,执行时会串行执行
- 使用hint方式,确保分片时路由时HitManager有值,否则无法走到分片逻辑(异步时候注意)
解析引擎
- org.apache.shardingsphere.sql.parser.SQLParserEngine#parse
路由引擎
- org.apache.shardingsphere.sharding.route.engine.ShardingRouteDecorator#decorate 生成分片路由结果
- org.apache.shardingsphere.sharding.route.engine.ShardingRouteDecorator#getShardingConditions 路由信息
- org.apache.shardingsphere.sharding.route.engine.type.standard.ShardingStandardRoutingEngine#route 根据数据节点组装的路由逻辑

改写引擎
- org.apache.shardingsphere.sharding.rewrite.context.ShardingSQLRewriteContextDecorator#decorate 参数重写、添加重写各种场景重写方法
- org.apache.shardingsphere.underlying.rewrite.sql.token.generator.SQLTokenGenerators#generateSQLTokens 解析statement,生成重写所需要的token
- org.apache.shardingsphere.underlying.pluggble.prepare.BasePrepareEngine#rewrite(org.apache.shardingsphere.underlying.rewrite.context.SQLRewriteContext) 根据token生成返回改写后需要执行的sql,库表信息

执行引擎
- org.apache.shardingsphere.shardingjdbc.jdbc.core.statement.ShardingPreparedStatement#initPreparedStatementExecutor 初始化
- org.apache.shardingsphere.shardingjdbc.executor.PreparedStatementExecutor#obtainExecuteGroups 获取具体的链接,这一步会确认链接模式
- org.apache.shardingsphere.sharding.execute.sql.prepare.SQLExecutePrepareTemplate#getSynchronizedExecuteUnitGroups
- org.apache.shardingsphere.sharding.execute.sql.prepare.SQLExecutePrepareTemplate#getSQLExecuteGroups 具体在这里判断,会根据分组结果获取链接
- org.apache.shardingsphere.shardingjdbc.jdbc.adapter.AbstractConnectionAdapter#getConnections 获取链接的逻辑,注意数据源配置的链接数是否满足单次执行的链接数,否则可能出现等待假死情况
- org.apache.shardingsphere.sharding.execute.sql.prepare.SQLExecutePrepareTemplate#getSQLExecuteGroups 具体在这里判断,会根据分组结果获取链接
- org.apache.shardingsphere.sharding.execute.sql.prepare.SQLExecutePrepareTemplate#getSynchronizedExecuteUnitGroups
- org.apache.shardingsphere.shardingjdbc.executor.PreparedStatementExecutor#obtainExecuteGroups 获取具体的链接,这一步会确认链接模式
- org.apache.shardingsphere.shardingjdbc.executor.PreparedStatementExecutor#execute 执行
- org.apache.shardingsphere.shardingjdbc.executor.PreparedStatementExecutor#executeQuery 查询,会用到链接模式来确定流式还是内存

归并引擎
- org.apache.shardingsphere.sharding.merge.ShardingResultMergerEngine#newInstance 选择归并类型
- org.apache.shardingsphere.sharding.merge.dql.ShardingDQLResultMerger#merge DML归并
- org.apache.shardingsphere.sharding.merge.dql.ShardingDQLResultMerger#build 各归并场景处理
- org.apache.shardingsphere.sharding.merge.dql.ShardingDQLResultMerger#decorate 分页装饰器
- org.apache.shardingsphere.sharding.merge.dql.ShardingDQLResultMerger#merge DML归并

总结
分片数据功能里用了比较多的设计模式,如装饰器、工厂、委托、模版、发布-订阅、建造者、上下文等,整体代码、流程设计很优秀,值得学习,里面还有许多实现细节还有没有分析到,比如事务,sql解析,归并,各类上下文等,只是把大概的流程梳理了一下,整理出使用时需要注意的点