全连接神经网络
隐藏层的节点数决定了模型拟合能力,如果在单隐藏层设置足够多的节点,理论上可以拟合世界上各种维度的数据进行任意规则的分类,但会过拟合。
隐藏层的数量决定了其泛化能力,层数越多,推理的能力越强,(个人观点为:层数越多学习到的特征越多,考虑的因素越多,因此增强了泛化能力)
全连接网络常常放在最后,还具有维度调节的作用,一般前后层维度变换在5倍以内。一般用维度先扩大再缩小的思路。
激活函数
激活函数用来加入非线性因素,弥补线性模型缺陷,常用的有Sigmoid、tanh、ReLU。
有多种形式
类形式和函数形式。
input=torch.autograd.Variable(torch.tensor([0.3,3]))
print(nn.Sigmoid()(input))
print(nn.functional.sigmoid(input))
#tensor([0.5744, 0.9526])
#tensor([0.5744, 0.9526])
更好的激活函数,Swish与Mish,后者没有参数更方便,一般都可以在Relu上直接更换取得更好的效果。
GELU,高斯误差线性单元,与随机正则化有关,可以起到自适应Dropout的效果。
Swish是GELU的特例,Mish是GELU的特例。
训练时特征之间的差距不断变大,输入数据本身差距大时用tanh会好一些,反之用Sigmoid比较好。
损失函数
L1损失函数,计算y’和y的绝对值然后进行平均值计算
MSE损失函数,计算y’和y的相减平方取平均值
预测值要与真实值控制在同样的数据分布内,如进入Sigmoid激活函数后取值为0到1,真实值也应该归一化为0到1。
pre=torch.tensor([1.0,1.5,3.0,3.0])
label=torch.tensor([2.2,3.1,2.0,3.0])
L1Loss=nn.L1Loss()(pre,label)
#(1.2+1.6+1.0+0.0)/4=0.95
MSELoss=nn.MSELoss()(pre,label)
#(1.44+2.56+1.0+0.0)/4=1.25
交叉熵损失函数,一般用在分类问题上,可以加类别权重。
pre=torch.tensor([0.,1.])
label=torch.tensor([0.,1.])
CrossEntropyLoss=nn.CrossEntropyLoss(torch.tensor([1,0.1]))(pre,label)
print(CrossEntropyLoss)
#tensor(0.0313)
其他激活函数…数不胜数
关于损失函数的选取,用输入标签的类型来选取损失函数,如果输入是无界的实数值,用平均方差。如果输入标签是位矢量(分类标识),使用交叉熵函数比较合适。
Softmax算法本质也是一种激活函数,在分类任务中很重要。Sigmoid之类的一般的激活函数只能分两类,而Softmax可以理解成其扩展。如果多分类任务中,每个类彼此不是互斥关系,可以使用多个二分类来组成。分几类最后放几个输出。
利用两边ln,将乘法变加法,然后转换成e的x次方。
实例3:Softmax与交叉熵的应用
logits有两个数据,一个数据有3个元素,代表3个类别。(0类、1类、2类)
labels对应类别标签。
使用LogSoftmax和NLLLoss,与直接用CrossEntropyLoss计算出的损失是一样的。
import torch
logits = torch.autograd.Variable(torch.tensor([[1.5,0.5,6], [0.1,3,0]]))
labels = torch.autograd.Variable(torch.LongTensor([2,1]))
print(logits)
print(labels)
print('Softmax:',torch.nn.Softmax(dim=1)(logits))
logsoftmax = torch.nn.LogSoftmax(dim=1)(logits)
print('logsoftmax:',logsoftmax)
output = torch.nn.NLLLoss()(logsoftmax, labels)
print('NLLLoss:',output)
print ( 'CrossEntropyLoss:', torch.nn.CrossEntropyLoss()(logits, labels) )
优化器模块
有了正向结构和损失函数后,就可以优化参数了。这个过程在反向传播中完成,优化函数为优化器。为了让损失函数最小,对其求导,找到最小值时的函数切线斜率(梯度),让权重沿着梯队来调整。
优化器与梯度下降
梯度下降法也叫最速下降法,用梯度下降(负梯度)的方向求解极小值。
优化器的类别
批量梯度下降、随机梯度下降,小批量梯度下降为上述两种方法的折中。
主流的优化器有,RMSProp、AdaGrad、Adam、SGD等,有各自的特点和适应的场景。
构建一个常用的Adam优化器
lr为学习率,默认为0.001,
weight_decay为权重参数的衰减率
amsgrad为是否使用二阶冲量
learning_rate=0.01
optimizer=torch.optim.Adam(model.parameters(),lr=learning_rate)
print(optimizer)
print(list(optimizer.param_groups[0].keys()))
#Adam (
#Parameter Group 0
# amsgrad: False
# betas: (0.9, 0.999)
# capturable: False
# differentiable: False
# eps: 1e-08
# foreach: None
# fused: None
# lr: 0.01
# maximize: False
# weight_decay: 0
#)
#['params', 'lr', 'betas', 'eps', 'weight_decay', 'amsgrad', 'maximize', 'foreach', 'capturable', 'differentiable', 'fused']
更好的优化器Ranger…
如何选择优化器
RMSProp、AdaGrad、Adam、SGD,前3个适合自动收敛,最后一个常用于手动精条模型,自动一般用Adam。
一般先用Adam然后用SGD精调。
进一步提升使用AMSGrad、Adamax、Ranger优化器。
退化学习率,在训练速度与精度之间找到平衡。
修改第三章实例,实现每50步将学习率乘0.99,实现将学习率变小的功能。
lr_scheduler退化学习率接口,简化等价写法。
epochs = 1000 #定义迭代次数
losses = [] #定义列表,用于接收每一步的损失值
lres = [] #定义列表,用于接收每一步的学习率
#scheduler=torch.optim.lr_scheduler.StepLR(optimizer,step_size=50,gamma=0.99)
for i in range(epochs):
loss = model.getloss(xt,yt)
losses.append(loss.item())
optimizer.zero_grad()#清空之前的梯度
loss.backward()#反向传播损失值
optimizer.step()#更新参数
# scheduler.step()
if i%50 ==0:
for p in optimizer.param_groups:
p['lr']*=0.99
lres.append(optimizer.state_dict()['param_groups'][0]['lr'])
plt.plot(range(epochs),lres,color='r')
plt.show()
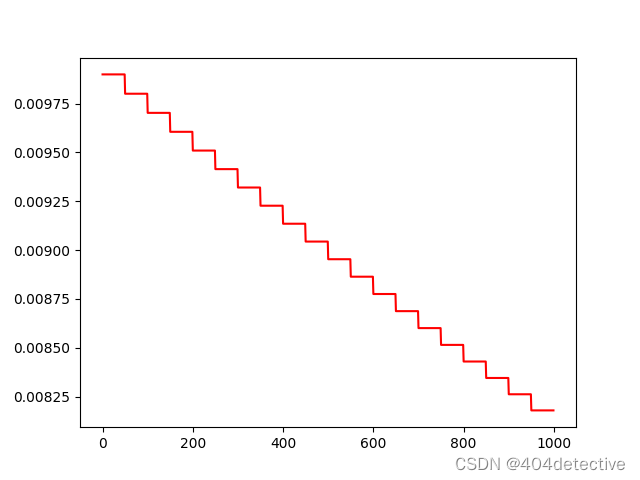
lr_scheduler存在多种退化方式
StepLR等间隔、MultiStepLR多间隔、指数衰减、余弦退火、根据指标调整等。
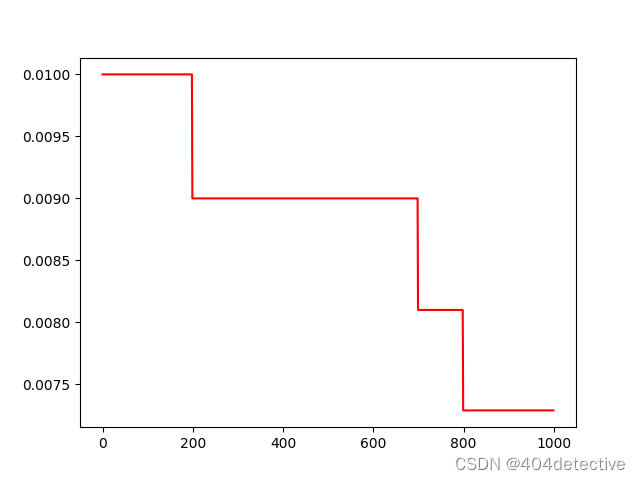
使用lr_scheduler实现MultiStepLR多间隔为200,700,800时。
scheduler=torch.optim.lr_scheduler.MultiStepLR(optimizer,milestones=[200,700,800],gamma=0.9)
使用lr_scheduler实现ReduceLROnPlateau时,注意要在scheduler.step(loss.item())传入损失,作为被监控的值。
scheduler=torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer,mode='min',factor=0.5,patience=5,verbose=True,threshold=0.0001,threshold_mode='abs',cooldown=0,min_lr=0,eps=1e-08)

实例4:预测泰坦尼克号船上的生存乘客
大体流程:
载入titanic3.csv,
Index([‘pclass’, ‘survived’, ‘name’, ‘sex’, ‘age’, ‘sibsp’, ‘parch’, ‘ticket’,
‘fare’, ‘cabin’, ‘embarked’, ‘boat’, ‘body’, ‘home.dest’],
舱位等级、是否获救、姓名年龄等等。
1.离散数据特征:如该任务中的男人和女人,数据没有连续性,做特征变换转化为one-hot编码,或者词向量。
具有固定类别的样本处理容易,如性别,按总的类别数变换
没有固定类别的样本,如名字,用hash算法或类似的散列算法处理
2.连续数据特征:如该任务中的年龄,做特征变换做对数运算或归一化处理。
3.连续数据与离散数据相互转化
(1)按最大最小值归一化处理
(2)对其进行对数运算
(3)按照其分布情况分为几类,做离散化处理。如90%的样本在0.1到1之间,10%的在1000到10000之间
前期数据处理:
将离散数据转成One-hot编码,如性别中有男女,男女成为新的特征分别一列,(1,0)为男(0,1)为女。
get_dummies()出来为布尔值可以用下面的代码做转换。
data = titanic_data.replace({True:1, False:0}).to_numpy()
#用哑变量将指定字段转成one-hot
titanic_data = pd.concat([titanic_data,
pd.get_dummies(titanic_data['sex']),
pd.get_dummies(titanic_data['embarked'],prefix="embark"),
pd.get_dummies(titanic_data['pclass'],prefix="class")], axis=1)
print(titanic_data.columns )
print(titanic_data['sex'])
print(titanic_data['female'])
print(titanic_data['embark_C'])
对Nan过滤填充,剔除无用数据列。本例只对连续数据年龄和乘客票价用平均值进行填充。
# print(titanic_data['age'])
# #处理None值
titanic_data["age"] = titanic_data["age"].fillna(titanic_data["age"].mean())
titanic_data["fare"] = titanic_data["fare"].fillna(titanic_data["fare"].mean())#乘客票价
# print(titanic_data['age'])
剔除无关的数据,不能用来做特征。如姓名,票号等等。
# #删去无用的列
titanic_data = titanic_data.drop(['name','ticket','cabin','boat','body','home.dest','sex','embarked','pclass'], axis=1)
print(titanic_data.columns)
分离样本和标签并制作数据集
将survived列拿出当做label,并将训练特征one-hot编码中的bool值转化成数值0和1。
取70%作为训练集,30%作为测试集。
np.random.choice(n,m,replace=False) n个里选m个不重复
list(set(range(len(labels))) - set(train_indices)) 用样本数量的下标减去选取训练集的下标得到剩下测试集的下标元组,然后转化成列表
set() 函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等
# #分离样本和标签
labels = titanic_data["survived"].to_numpy()
print(labels)
titanic_data = titanic_data.drop(['survived'], axis=1)
data = titanic_data.replace({True:1, False:0}).to_numpy()
print(data)
# #样本的属性名称
feature_names = list(titanic_data.columns)
print(feature_names)
# #将样本分为训练和测试两部分
np.random.seed(10)#设置种子,保证每次运行所分的样本一致
train_indices = np.random.choice(len(labels), int(0.7*len(labels)), replace=False)
test_indices = list(set(range(len(labels))) - set(train_indices))
train_features = data[train_indices]
train_labels = labels[train_indices]
test_features = data[test_indices]
test_labels = labels[test_indices]
print(len(test_labels))#393
定义Mish激活函数与多层全连接网络:
输入为12个特征,[‘age’, ‘sibsp’, ‘parch’, ‘fare’, ‘female’, ‘male’, ‘embark_C’, ‘embark_Q’, ‘embark_S’, ‘class_1’, ‘class_2’, ‘class_3’] 再到隐藏层12和8和神经元,最后输出2个预测结果。
# ###########################################
class Mish(nn.Module):#Mish激活函数
def __init__(self):
super().__init__()
print("Mish activation loaded...")
def forward(self,x):
x = x * (torch.tanh(F.softplus(x)))
return x
torch.manual_seed(0) #设置随机种子
class ThreelinearModel(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(12, 12)
self.mish1 = Mish()
self.linear2 = nn.Linear(12, 8)
self.mish2 = Mish()
self.linear3 = nn.Linear(8, 2)
self.softmax = nn.Softmax(dim=1)
self.criterion = nn.CrossEntropyLoss() #定义交叉熵函数
def forward(self, x): #定义一个全连接网络
lin1_out = self.linear1(x)
out1 = self.mish1(lin1_out)
out2 = self.mish2(self.linear2(out1))
return self.softmax(self.linear3(out2))
def getloss(self,x,y): #实现LogicNet类的损失值计算接口
y_pred = self.forward(x)
loss = self.criterion(y_pred,y)#计算损失值得交叉熵
return loss
##############################
训练模型并输出结果
我这里训练了500轮。
net = ThreelinearModel()
num_epochs = 600
optimizer = torch.optim.Adam(net.parameters(), lr=0.04)
print(train_features.dtype)
print(train_labels.dtype)
input_tensor = torch.from_numpy(train_features).type(torch.FloatTensor)
label_tensor = torch.from_numpy(train_labels)
losses = []#定义列表,用于接收每一步的损失值
for epoch in range(num_epochs):
loss = net.getloss(input_tensor,label_tensor)
losses.append(loss.item())
optimizer.zero_grad()#清空之前的梯度
loss.backward()#反向传播损失值
optimizer.step()#更新参数
if epoch % 20 == 0:
print ('Epoch {}/{} => Loss: {:.2f}'.format(epoch+1, num_epochs, loss.item()))
os.makedirs('models', exist_ok=True)
torch.save(net.state_dict(), 'models/titanic_model.pt')
def moving_average(a, w=10):#定义函数计算移动平均损失值
if len(a) < w:
return a[:]
return [val if idx < w else sum(a[(idx-w):idx])/w for idx, val in enumerate(a)]
def plot_losses(losses):
avgloss= moving_average(losses) #获得损失值的移动平均值
plt.figure(1)
plt.subplot(211)
plt.plot(range(len(avgloss)), avgloss, 'b--')
plt.xlabel('step number')
plt.ylabel('Training loss')
plt.title('step number vs. Training loss')
plt.show()
plot_losses(losses)
#输出训练结果
out_probs = net(input_tensor).detach().numpy()
out_classes = np.argmax(out_probs, axis=1)
print("Train Accuracy:", sum(out_classes == train_labels) / len(train_labels))
#测试模型
test_input_tensor = torch.from_numpy(test_features).type(torch.FloatTensor)
out_probs = net(test_input_tensor).detach().numpy()
out_classes = np.argmax(out_probs, axis=1)
print("Test Accuracy:", sum(out_classes == test_labels) / len(test_labels))
#####################################
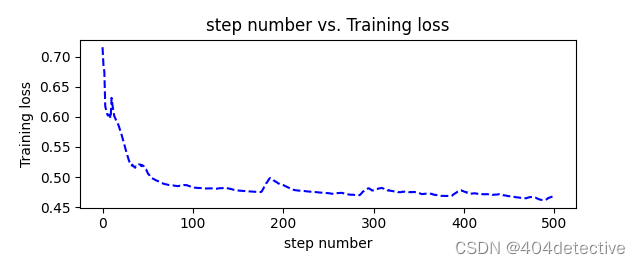
如果不加平滑的话效果如下。
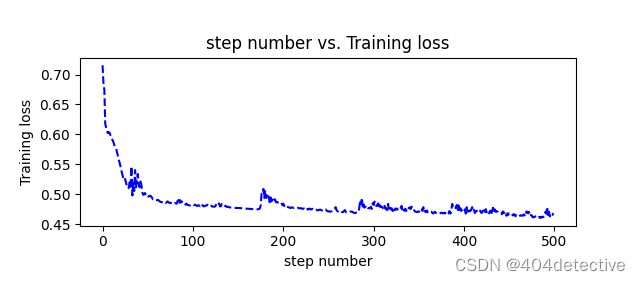
Train Accuracy: 0.8417030567685589
Test Accuracy: 0.7938931297709924
完整代码:
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
import os
from scipy import stats
import pandas as pd
titanic_data = pd.read_csv(r"E:\desktop\Home_Code\pytorch\chapter5\titanic3.csv")
print(titanic_data.columns)
#用哑变量将指定字段转成one-hot
titanic_data = pd.concat([titanic_data,
pd.get_dummies(titanic_data['sex']),
pd.get_dummies(titanic_data['embarked'],prefix="embark"),
pd.get_dummies(titanic_data['pclass'],prefix="class")], axis=1)
print(titanic_data.columns )
print(titanic_data['sex'])
print(titanic_data['female'])
print(titanic_data['embark_C'])
# print(titanic_data['age'])
# #处理None值
titanic_data["age"] = titanic_data["age"].fillna(titanic_data["age"].mean())
titanic_data["fare"] = titanic_data["fare"].fillna(titanic_data["fare"].mean())#乘客票价
# print(titanic_data['age'])
# #删去无用的列
titanic_data = titanic_data.drop(['name','ticket','cabin','boat','body','home.dest','sex','embarked','pclass'], axis=1)
print(titanic_data.columns)
# #
# ####################################
# #分离样本和标签
labels = titanic_data["survived"].to_numpy()
print(labels)
titanic_data = titanic_data.drop(['survived'], axis=1)
data = titanic_data.replace({True:1, False:0}).to_numpy()
print(data)
# #样本的属性名称
feature_names = list(titanic_data.columns)
print(feature_names)
# #将样本分为训练和测试两部分
np.random.seed(10)#设置种子,保证每次运行所分的样本一致
train_indices = np.random.choice(len(labels), int(0.7*len(labels)), replace=False)
test_indices = list(set(range(len(labels))) - set(train_indices))
train_features = data[train_indices]
train_labels = labels[train_indices]
test_features = data[test_indices]
test_labels = labels[test_indices]
print(len(test_labels))#393
# ###########################################
class Mish(nn.Module):#Mish激活函数
def __init__(self):
super().__init__()
print("Mish activation loaded...")
def forward(self,x):
x = x * (torch.tanh(F.softplus(x)))
return x
torch.manual_seed(0) #设置随机种子
class ThreelinearModel(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(12, 12)
self.mish1 = Mish()
self.linear2 = nn.Linear(12, 8)
self.mish2 = Mish()
self.linear3 = nn.Linear(8, 2)
self.softmax = nn.Softmax(dim=1)
self.criterion = nn.CrossEntropyLoss() #定义交叉熵函数
def forward(self, x): #定义一个全连接网络
lin1_out = self.linear1(x)
out1 = self.mish1(lin1_out)
out2 = self.mish2(self.linear2(out1))
return self.softmax(self.linear3(out2))
def getloss(self,x,y): #实现LogicNet类的损失值计算接口
y_pred = self.forward(x)
loss = self.criterion(y_pred,y)#计算损失值得交叉熵
return loss
##############################
net = ThreelinearModel()
num_epochs = 600
optimizer = torch.optim.Adam(net.parameters(), lr=0.04)
print(train_features.dtype)
print(train_labels.dtype)
input_tensor = torch.from_numpy(train_features).type(torch.FloatTensor)
label_tensor = torch.from_numpy(train_labels)
losses = []#定义列表,用于接收每一步的损失值
for epoch in range(num_epochs):
loss = net.getloss(input_tensor,label_tensor)
losses.append(loss.item())
optimizer.zero_grad()#清空之前的梯度
loss.backward()#反向传播损失值
optimizer.step()#更新参数
if epoch % 20 == 0:
print ('Epoch {}/{} => Loss: {:.2f}'.format(epoch+1, num_epochs, loss.item()))
os.makedirs('models', exist_ok=True)
torch.save(net.state_dict(), 'models/titanic_model.pt')
def moving_average(a, w=10):#定义函数计算移动平均损失值
if len(a) < w:
return a[:]
return [val if idx < w else sum(a[(idx-w):idx])/w for idx, val in enumerate(a)]
def plot_losses(losses):
avgloss= moving_average(losses) #获得损失值的移动平均值
plt.figure(1)
plt.subplot(211)
plt.plot(range(len(avgloss)), avgloss, 'b--')
plt.xlabel('step number')
plt.ylabel('Training loss')
plt.title('step number vs. Training loss')
plt.show()
plot_losses(losses)
#输出训练结果
out_probs = net(input_tensor).detach().numpy()
out_classes = np.argmax(out_probs, axis=1)
print("Train Accuracy:", sum(out_classes == train_labels) / len(train_labels))
#测试模型
test_input_tensor = torch.from_numpy(test_features).type(torch.FloatTensor)
out_probs = net(test_input_tensor).detach().numpy()
out_classes = np.argmax(out_probs, axis=1)
print("Test Accuracy:", sum(out_classes == test_labels) / len(test_labels))
#####################################