大家好,Generative AI Model的出现,给游戏开发带来一些新的变革.比如像stable dissfusion可以快速的生成图像,设计人物的原型,背景设定.像DreamFusion和这个Magic3D这种模型,它可以通过文本快速的建模3D对象.还有像chatgpt这种可以编写故事啊可以做模拟人物对话.AItts可以进行语音合成.
所以现在各种技术和大模型的出现,我觉得赋予了每个人这种创造力,所以说我觉得在未来的这种游戏开发当中,AI整个工具的占比,会发生一种颠覆性的提升吧.在AI的加持下,我觉得未来的这种游戏制作者,他可能会更关注的是游戏本身的设计,而这些繁琐的实现则可以丢给AI,这是一种新的游戏制作方式,在很多厂商中已经出现了.
呃关于2D图像的模型生成,其实在dissfusion model这种底层算法的革新后,并在大规模数据和这种算力的加持下
其实涌现了大批量图像算法啊,我观察下来是比较优秀的通用的模型.比如说包括的是像Dall-E2,Midjourney,Stable Dissfusion啊其实这不同底层的这个算法,其实都是大同小异的啊,都是这种dissfusion model的变种.
最大的区别就在于底层的训练数据这其实驱使了整个模型的输出风格有所差异.可以看到Midjourney
这种整体的风格,其实是比较偏影视及大作的,它的视觉效果是更震撼的,而像Stable Dissfusion的风格它其实更宽泛,而像Dall-E2这种模型,他就更适合做写实和设计类的类型的生成.
Midjourney

Stable Dissfusion

Dall-E2

这边提一下midjouney这家公司,它是在AIGC的时代下的一个比较典型的例子.AIGC必然会取代一大批人。但与此同时呢,它也会给小公司和个人带来从未有过的机遇.midjouney它没有自己的软件,没有app,没有融资,使用的是discord的UI,靠11个人自筹资金,在不到一年的时间拥有了全球千万用户,年营收上亿美金。
同样可以对比的是discord的公司,discord 同样也是一家比较优秀的公司,但是它本质上仍然是一个非常正统的互联网公司。巧的是discord的营收一年也是一亿美金,但是呢,它需要不断的融资,并且它的员工人数目前是600多人。

所以呢,AIGC的时代下,我们将会看到公司变得越来越小,但是产品的影响力却很大。互联网类型下劳动密集的公司会越来越少,几个人,十几个人的小公司将更多的出现。
好了,收,回到刚才的话题,相较于不同的这种游戏设计风格,我觉得大家可以选择不同的这种模型,来做生成啊.同时咧,也不必局限于比较哪个好就只用哪个,这些都是工具,还是要以我为主,为我所用.我们要做使用工具的人,不要做工具人.
比如说我们要创建一个游戏地图,直接生成一张地图也是没有问题的,但是不能精准的控制毎一块区域的内容,这时候就可以这种合成的方式来实现
- 首先,在 MidJourney和Stable Dissfusion中生成一些很酷的图像,可以通过合适的prompt来生成鸟瞰视角的地图块

2.然后把它们上传到Dall-E2上
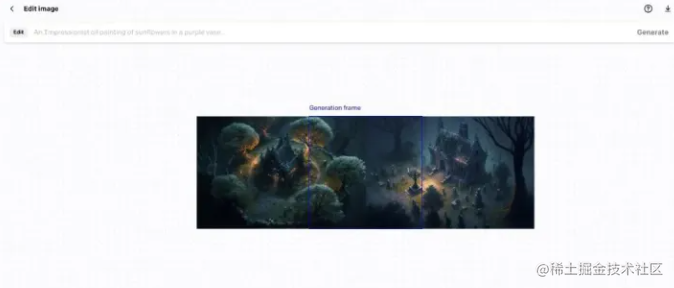
3.删除一些图像之间重叠的部分,并使用相同的提示生成连接两张图片的细节

4.然后它们就神奇的融合在一起了
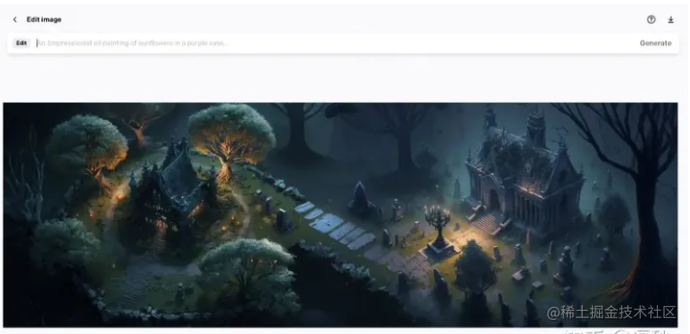
- 重复这个步骤,不断扩大这张图直到满意为止。
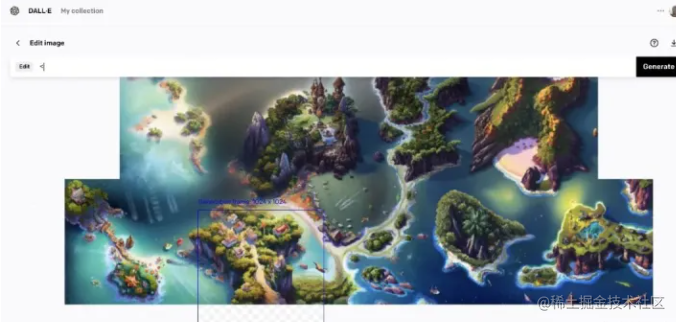
这对于制作生成D&D地图非常有用。在回合制RPG、策略游戏中这种类型的地图还是比较常见的。
同时呢也有一些国内的模型,比如像百度的文心一言啊,太乙的stable-diffusion,画宇宙啊相较于国外的模型
主要是在中文模型的语境下,做了一些优化,不用再去翻译成英文的prompt,但是对文心一言来说,我还是喜欢它之前那种桀骜不驯的样子,嗯,这边找到了一些优化前的文生图片,来玩一玩百度的报菜名吧.
https://juejin.cn/post/7215842168454627387
在二次元绘图模型上,NovalAI和nijijourney是比较不错的模型,像NovalAI是,它的训练数据主要来自于这个Danbooru这个网站,里面大部分是来自日本动画、漫画和游戏的图片,总的来说,NovelAI 就是用 Danbooru 的图片在 Stable Diffusion 的基础上做了模型的优化训练(fine-tune)。Nijijourney听这个名字大家就可能猜到和Midjourney有关,它是其实是midjourney和Spellbrush合作的一款专门针对二次元的AI生成器.但其实整体观察下来这个NovelAI相比Nijijourney,它整体的视觉是更偏向那种那种传统的漫画,Nijijourney风格比较多样化,画面更精致.
NovalAI

Nijijoruney

这与此同时啊,在在网上其实也有蛮多这些开发者,贡献了各种fine-tune的diffusion model,我这里提供两个
找模型的网站,一个是这个Civitai,另一个是这个HuggingFace,其实这两个网站,都可以比较快速的得到
你所需风格的模型啊,权重啊,然后可以加载到本地的部署的框架下,就可以使用了.比如去github上找这种开源的AUTOMATIC1111 webui现成的框架,或者懒一点的直接去B站找,弄好的一键包,比如秋叶系列哪些.
https://civitai.com/

https://huggingface.co/
当然了也可以通过自己训练模型,来获取到特定角色和特定风格的一些模型,主流方案就是三种吧
一种这个Textual Inversion,它是可以通过学习这种特定的token的编码,来锁定学习的对象
但是它整个的这附加网络的大小其实就有几十k,所以很难捕获到对象的细节,他比较适合做一些风格转换啊
简单物体的生成,由于它是不修改整个原始的模型的,所以说它的能力比较有限
Textual Inversion
根据模型引用给定的图像并选择最匹配的图像,做的迭代越多越好.通过寻找到一个latent空间来描述一个近似训练图的复杂概念,并将该空间分配给关键字
模型文件小: ~30KB
通常不能捕获物品细节,擅长风格转换,本地训练时对性能要求不高
Hypeenetwork
通过引入一个新的参数模块,来学习特定的知识,使用时可以插入该模块来引导生产.
模型文件小: ~87MB
适合学习较大的概念,如艺术风格,简单物体,在较低训练步数就能看到一些结果.本地训练时对性能要求不高,不需要大显存.
DreamBooth
重新训练整个模型,修改所有网络参数
模型文件小: 2-5GB
适合训练人脸,动物和复杂物体
显卡要求最高
它是整个训练了重新的网络参数,它整个网络都会被fine-tune,所以它的训练代价是最大的
但同时它的效果也是最好的,它是可以比较准确的捕捉到你上传的图片的这些人物特征,但是其实他也是需要一些繁
繁琐的一些调参才会出现比较惊艳的效果.这个调参,主要也就包括你输入的图像的数量和风格是否一致
然后你prompt编写是否规范,然后还有一些像学习力啊,迭代步数是否合理,所以说这个也是蛮花精力去调节的
如果不选择这个训练模型,也是有一些方法是可以来控制风格和人物的
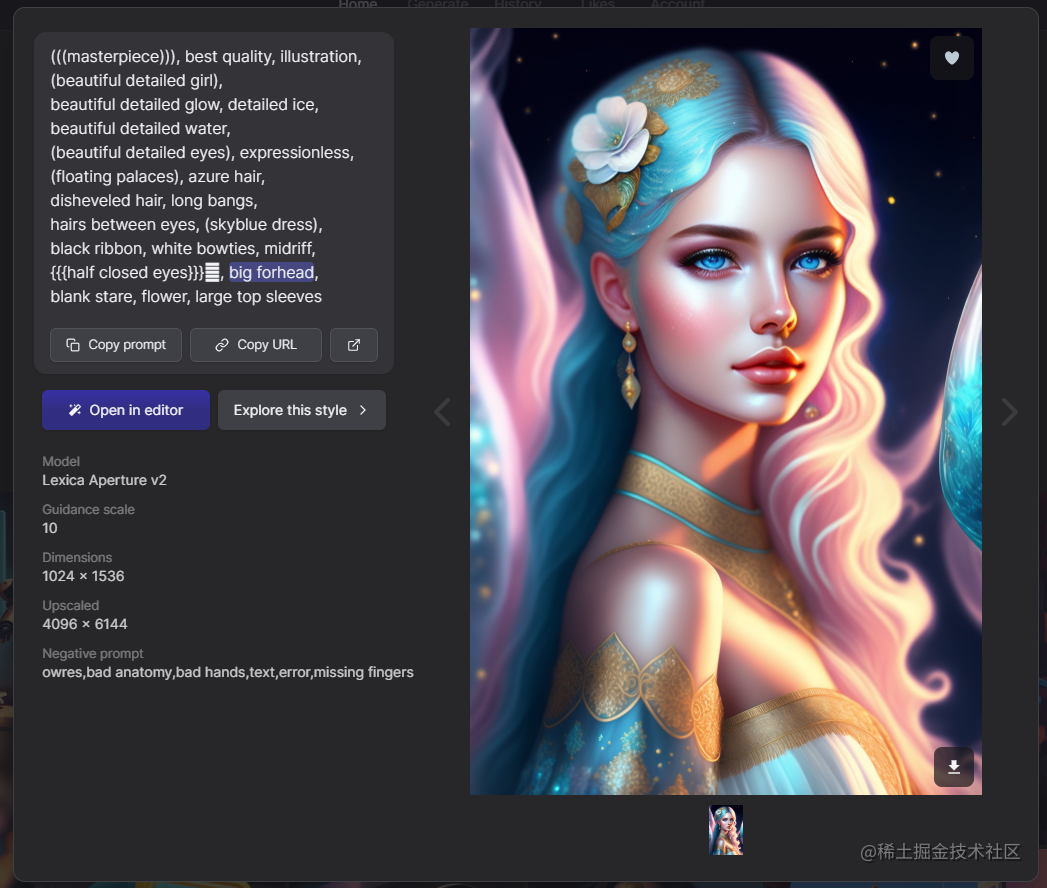
1.比如通过prompt,这里也推荐几个我比较常用的网站lexica和画宇宙,可以通过搜索来快速的获取,想要图片的关键字,prompt,尺寸啊,以及说它具体的随机种子是什么
https://lexica.art/
2.还可以用ChatGPT,Claude这种语言模型来生成成我们想要的的prompt
比如用这个调教
1.prompts分为两个部分,positive和negative,他们分别控制你希望生成的内容,和不希望生成的内容。
2.promot可以是单词、复合词语和简单的短语,不要出现复杂的句式。
3.根据stable difussion prompt datebase,每个prompt具有不同的分类,分为画面质量(例如high quality,low detailed)、画风(例如realism)、构图(例如f/1.4,135mm焦距,vanishing point)、内容(例如black hair,constructures)。每个分类的可以输入多个prompt,他们之间用’,'隔开。
4.你可以定义每个prompt的权重,权重的范围在0~2,支持小数点后4位精度,0代表不重要,1代表普通,2代表非常重要。你可以通过’(prompt:weight)'这种直接指定的方式控制,注意括号是必须的,不可以省略。例如(black hair:1.5),(best quality:2)
5.一般来说,一份好的prompt的权重分配应该是质量>画风>构图>内容,即给与质量最高的权重,这可以控制图像生成的效果。
6.在生成prompt时,仅需要生成对应的英文,不要用中文解释。 现在,如果你了解了 ,请回复我:“我已了解。”,并生成四个质量有关的prompt作为测试
它是可以直接反馈出一个完整的prompt,个生成的语句相比于直接翻译来说,它的细节和准确度是更好的,所以说我们最后发现,结果还是AI其实是最懂AI的.
3.此外,AI绘画领域的lora和controlnet也迅速的发展了起来。lora模型的自训练和controlnet对画面的控制能力,都让文生图变得更加的落地,补全了它进入工作流的最后一块拼图
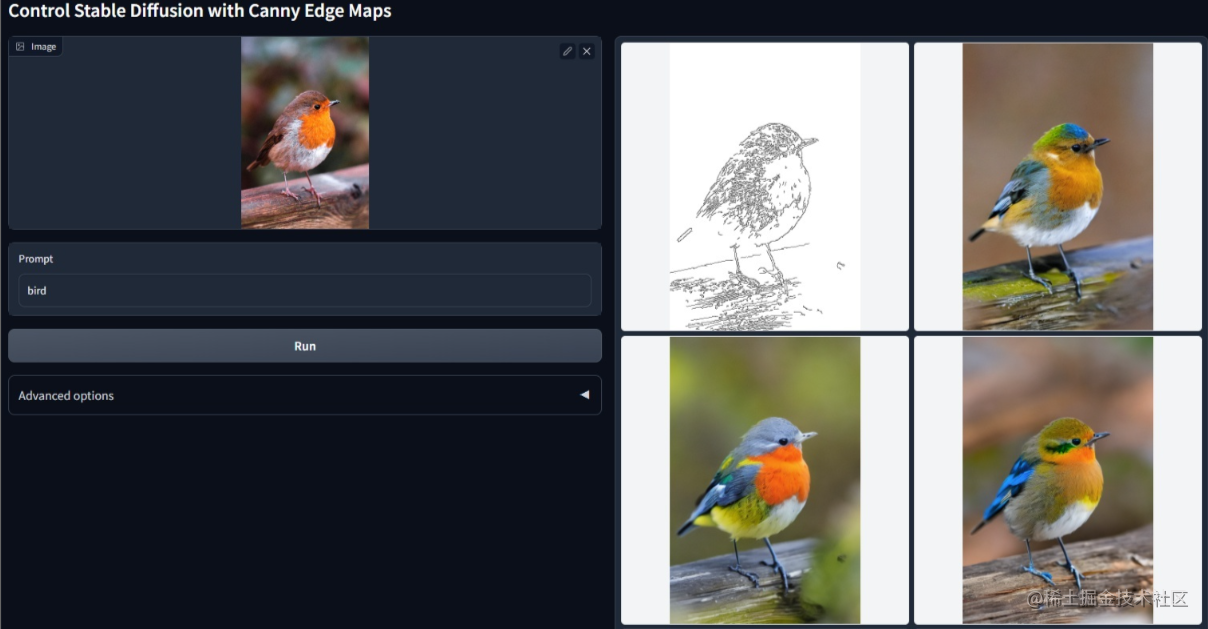
呃对于整个可控生成的话,其实也是有一些其他方案啊,比如说我们可以用人偶,来摆设出底图的layout,这里是推荐比如说像无限人偶这样的软件,它是可以通过,比如说我就摆设一些人物的具体的一些姿态,然后我再通过摆设过后的姿态,在AI中使用image to image的方式,来生成固定的姿态和色彩的人物,这种方案的话我觉得还是蛮可控的啊

http://www.pofiapp.com/
4.关于AI生成内容的身份锁定方面,有一些技巧,比如先选择一个比较大的画布,然后在这个大画布上
,可以画多个人物,就像叙事壁画一样,其实包括它的正面和侧面图,然后这样的话我在一幅画画面下
,画几个人物,它的几个人物的特征都会保持一致.
常用的一些AI处理软件吧,最主要就比如说waifu2x这种超分的软件,还有自动抠图的photo Cutter,Erase bg,clipdrop.还有自动上色的palette.fm,一些打光的像Relight,还有一些修复的工具CleanUp,这可能在零零散散的这个后续的后处理上可能都会用上
waifu2x

palette.fm

Relight

在3D模型的生成方面,比如说这个Google开发了这个文生的3D模型的DreamFusion,通过输入文本直接AI生成3D模型,是自带贴图的,但是这个效果吧比较差强人意,但是也可以勉强可以挑出一些,可以用的3D模型

还有一些像是比较有意思的,像这monstermash,它是可以通过直接很简单的像这种简笔画或者一些简单的图片,比如说你是用NovalAI生成的人物,可以快速的膨胀成一个3D模型,然后我就添加一些简单的骨骼动作,我就会做一些简单的3D动效,我觉得这还是蛮有意思的
https://monstermash.zone/
在代码生成方面呢,我推荐使用的是ChatGPT这种,它其实是可以做代码生成的,我自己实测下来感觉,它的这个代码水平已经超过了大学生了,甚至我觉得,有些地方还是超过我现在了,对所以说我觉得这个整个ChatGPT它生成代码能力还是蛮强的.在VSCode中使用ChatGPT的中文插件的体验是很不错的,填一个自己的openai key就好了,优化和解释代码的右键操作也是很方便的.
还一个我比较喜欢用的是github的copilot,其实它这个功能和字面意思也是比较像的,它叫副驾驶员嘛
所以说它主要还是做代码的辅助生成,我在写完半行代码的时候,帮我补全下一半,节省我打字的时间,生成的内容我体验下来大部分还是符合我的预期.
代码生成还有一个codex,还没体验过,你们可以去试试水
在游戏策划方面
然后在这文本生成上,我依旧还是比较首推的ChatGPT/GPT4,他的这个效果上,在整个的这个对话质量上,还有他续写的文章的一些水平上,我觉得都是目前应该是最强的,而且他的这个通用性和广泛性,也是最好的.当然也是有一系列国产的可以用啊,像阿里的通义千问,但是我都没排队到,这里就不能推荐了.这个展开太多了呢,我们还没可以专门来一期玩玩.
在游戏语音和音乐方面
mubert AI作曲,AIVA AI,声咖,腾讯智影,MoeGoe合成语音
AI生成音乐的整体的韵律和这个氛围感,我觉得差不多生成的质量已经达到了,这个游戏的基本使用的水平了吧
哎



![[Flask] 初识Flask](https://img-blog.csdnimg.cn/3c2b1873d2634e40ad535563d3a1a6a6.png)