TCP是一个基础协议,这里相关的十八个问题也都是常见的问题。无论是前端还是后端同学,都应该掌握的这些问题。过于基础的问题,比如TCP格式是什么 占多少字节 三次握手的流程等等,由于过于简单,我们不介绍,本系列总结的这十八问里面 都是进阶型的问题。
一:TCP三次握手双方都交换了哪些东西?

三次握手的流程如上图,不再赘述。除了确认了双方ip及port的连通性(使用syn+ack机制),我们还需要关注到以下内容:
1. 同步双方初始序列号。序列号是TCP协议的可靠性机制的手段。按照序列号可以保证连接上数据的有序性以及确认可达性。
2. windows size 窗口大小。 客户端和服务端都会发送各自的windows size,最终协商出二者最小值,这是TCP流控的所需要的。
3. MSS。 TCP连接的对端发往本端的最大TCP报文段的长度。握手成功后,数据传输时,数据部分(不包括TCP头)的长度不能超过协商的TCP-MSS,否则会进行分片。
二:既然IP层会分片,为什么还需要在TCP层用MSS来限制大小?
IP层分片是按照MTU进行分片。TCP层分片是按照MSS大小进行分片。

MTU是整个网络包的最大值;MSS是数据包能携带的应用数据的最大值;
看起来似乎可以依靠IP层进行分片,但是这样是存在隐患的。假设TCP层不分片,把某个15k的数据包都传给IP层,IP层就需要分成10个片。当这10个IP分片中的任意一个丢失,这10片都需要进行重传。如果在TCP层进行分片就不会出现这种问题,哪个分片丢失只需要传输该分片即可。
三:TCP四次挥手时,为什么time_wait等待时间是2MSL?如果系统产生大量的timewait怎么办

上图为四次握手的过程。可见time_wait状态只会存在于主动关闭的一方。
MSL是 Maximum Segment Lifetime,包的最大生存时间。超过这个时间,这个包就会丢掉。主动关闭的一方最后一次发送ACK报文,不一定能到达对端,如果没有到达对端,那么对端就有可能继续发送数据过来,这时本端就不能关闭连接;2个MSL的意思就是,网络中数据包的发送被对端接收后 对端又回复了响应报文,所以一来一回需要2个MSL。linux系统里的2MSL默认是60s。可以进行修改。
#define TCP_TIMEWAIT_LEN (60*HZ)
大量的timewait会占用很多内存。我们可以这样进行改善。
vim /etc/sysctl.conf
然后,在这个文件中,加入下面的几行内容:
net.ipv4.tcp_syncookies = 1 //表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭;
net.ipv4.tcp_tw_reuse = 1 //表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;
net.ipv4.tcp_tw_recycle = 1 //表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭;
net.ipv4.tcp_fin_timeout = 30 //修改系統默认的 TIMEOUT 时间但我们要清楚地知道,这些手段只是改善,而且timewait的阶段是十分有必要存在的,那么在工程中我们一般关注的是服务端的性能,所以我们可以考虑应该让客户端去主动断开连接,或者让业务使用HTTP长连接。
相关视频推荐
4个小时搞懂tcp/ip协议栈,从tcp/ip协议栈原理到实现一个网络协议栈
dpdk从tcp/ip协议栈开始,准备好linux环境一起开始
7道面试题打通C/C++后端开发的技术脉络
免费学习地址:c/c++ linux服务器开发/后台架构师
需要C/C++ Linux服务器架构师学习资料加qun812855908获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享

四:listen时backlog参数的用处
backlog是内核中全连接队列的最大长度。
在 TCP 三次握手的时候,Linux 内核会维护两个队列,分别是:半连接队列,也称 SYN 队列;全连接队列,也称 accept 队列;服务端收到客户端发起的 SYN 请求后,内核会把该连接存储到半连接队列,并向客户端响应 SYN+ACK,接着客户端会返回 ACK,服务端收到第三次握手的 ACK 后,内核会把连接从半连接队列移除,然后创建新的完全的连接,并将其添加到 accept 队列,等待进程调用 accept 函数时把连接取出来。
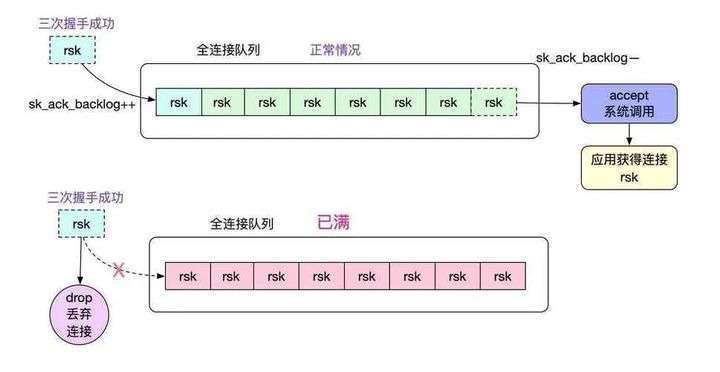
五:服务端调用accept函数是不是标识着TCP 建连成功?
服务端调用accept仅仅是从内核的全连接队列中取一个连接而已。跟TCP三次握手没有半毛钱关系;没有accept,tcp也一样建连成功,也就是说tcp的建连过程不需要accept。

六:什么是SYN攻击
SYN 攻击指的是,客户端在短时间内伪造大量不存在的IP地址,向服务器不断地发送SYN包,服务器回复SYN+ACK,并等待确认。由于客户端的IP地址是不存在的,所以服务器就一直收不到,那么服务器需要不断的重发直至超时,这些伪造的SYN包将长时间占用内核的半连接队列,半连接队列如果占满了,那么正常的SYN请求会被丢弃,导致正常的连接无法完成。可以使用
netstat
来检测SYN攻击
如何防御呢:服务器接收到TCP SYN包并返回TCP SYN + ACK包时,先不要进行资源分配,先根据这个SYN包计算出一个cookie值,这个cookie作为将要返回的SYN ACK包的初始序列号。当客户端返回一个ACK包时,根据包头信息计算cookie,与返回的确认序列号进行对比,如果相同,则是一个正常连接,然后,分配资源,建立连接。
七:TCP的RTT和RTO是怎么计算的
首先,要理解RTT和RTO这两个概念。
-
RTT(Round Trip Time):一个连接的往返时间,即从数据发送开始算起,到收到这个数据的ack报文为止,这个时间段叫RTT,这是拥塞控制算法重要的输入条件,准确的RTT时间是拥塞控制算法能够准确的前提条件;
-
RTO(Retransmission Time Out):重传超时时间。超时重传是TCP重传的其中一个机制,就是在发送数据时,设定一个定时器,当超过指定的时间后,没有收到对方的 ACK 确认应答报文,就会重发该数据。这个指定的时间就叫RTO。这个定时器的超时时间,如果设置的过大了,那么就导致一个包丢了好久还没开始重发,这就会导致传输效率的降低;如果设置的过小,那么就会导致包其实没丢就开始重发,过多的重发包会加剧网络的拥塞。所以RTO的设置应该准确。理论上来说,应该设置为略大于当时的RTT的值。
我们知道,网络的质量是随时变化的,所以RTT一定是实时变化的,那么RTO也应该是随时变化的。并且RTT的值决定了RTO的值。
TCP 通过采样 RTT 的时间,然后进行加权平均,算出一个平滑 RTT 的值(首次计算SRTT=RTT)
SRTT = 7/8*SRTT + 1/8*RTT;
然后再进行计算每次取样之后新的RTT值与SRTT的差值RTT_VAR(取绝对值)
Delta = |RTT - SRTT|RTT_var = 3/4*RTT_var + 1/4*Delta
有了SRTT和RTT_VAR,RTO就可以轻易算出来了。
RTO = SRTT + 4*RTT_VAR
别问7/8,1/8,3/4,1/4,4这些计算系数是怎么来的,问就是经验所得。再问一下,经验准吗?还真不一定。。。不准你也得这么用,毕竟写死在内核里的
下面是内核源码(tcp_input.c)
/*
* srtt is stored as fixed point with 3 bits after the
* binary point (i.e., scaled by 8). The following magic
* is equivalent to the smoothing algorithm in rfc793 with
* an alpha of .875 (srtt = rtt/8 + srtt*7/8 in fixed
* point). Adjust rtt to origin 0.
*/
delta = rtt - 1 - (tp->t_srtt >> TCP_RTT_SHIFT);
if ((tp->t_srtt += delta) <= 0)
tp->t_srtt = 1;
if ((tp->t_srtt += delta) <= 0)
tp->t_srtt = 1;
/*
* We accumulate a smoothed rtt variance (actually, a
* smoothed mean difference), then set the retransmit
* timer to smoothed rtt + 4 times the smoothed variance.
* rttvar is stored as fixed point with 2 bits after the
* binary point (scaled by 4). The following is
* equivalent to rfc793 smoothing with an alpha of .75
* (rttvar = rttvar*3/4 + |delta| / 4). This replaces
* rfc793's wired-in beta.
*/
if (delta < 0)
delta = -delta;
delta -= (tp->t_rttvar >> TCP_RTTVAR_SHIFT);
if ((tp->t_rttvar += delta) <= 0)
tp->t_rttvar = 1;
} else {
/*
* No rtt measurement yet - use the unsmoothed rtt.
* Set the variance to half the rtt (so our first
* retransmit happens at 3*rtt).
*/
tp->t_srtt = rtt << TCP_RTT_SHIFT;
tp->t_rttvar = rtt << (TCP_RTTVAR_SHIFT - 1);
}
tp->t_rtt = 0;
tp->t_rxtshift = 0;
/*
* the retransmit should happen at rtt + 4 * rttvar.
* Because of the way we do the smoothing, srtt and rttvar
* will each average +1/2 tick of bias. When we compute
* the retransmit timer, we want 1/2 tick of rounding and
* 1 extra tick because of +-1/2 tick uncertainty in the
* firing of the timer. The bias will give us exactly the
* 1.5 tick we need. But, because the bias is
* statistical, we have to test that we don't drop below
* the minimum feasible timer (which is 2 ticks).
*/八:TCP除了超时重传还有哪些重传机制
快速重传:如果连续收到了3个相同的ack,但是RTO还没超时,也需要重传,不再等超时流。这个机制解决的是RTO算的太长了,实际包已经丢了但还是没到达RTO的情况。但是这又带来了另一个问题,是只重传ack的那个呢 还是 重传所有没ack的呢。这就是选择重传机制,当然了超时重传也会面临重传哪些包的问题。
选择重传:TCP的option字段有一个SACK,用于告知发送端哪些包是真丢了。那么发送端根据SACK就可以选择性只重传丢失的包。假如seq5丢了,但是seq6接收端收到了,那么发送端就只需要重发seq5就可以了,不需要再发送seq6;要使用SACK,客户端和服务端必须同时支持SACK才可以,建立连接的时候需要使用SACK Permitted的option

九:拥塞控制和流量控制到底是什么区别?
TCP初学者最迷茫的问题,大概就是拥塞控制和流量控制傻傻分不清楚了吧,各种窗口,感觉都是为了控制发送速度的。
流量控制
解决的问题是 避免发送端发送数据的过快导致接收端没有能力接收。比如当接收方非常繁忙,或者内存缓冲区很小了,这个时候网卡收到的包会被内核丢掉,记住这个包可不是因为网络不好而丢包的,而是接收方资源不足了而迫不得已丢的包,这不仅导致发送端那些包白发了,还会导致网络拥堵。所以为了防止这种损人不利己的事儿发生,就需要流量控制。接收端实时告诉发送端自己的接收能力,通过windows_update帧来通告接收窗口。
流量控制的算法是 滑动窗口算法,这里涉及到的窗口是 发送窗口 和 接收窗口
以上,我们了解到流量控制解决了发送端和接收端的问题。那么除了两端,我们还需要考虑中间网络的情况,发送端有能力发送那么多数据,接收端也有能力接收那么多数据,但是中间的网络有能力传输这么多数据吗?这就是拥塞控制要解决的问题。
拥塞控制:
网络的拥堵有可能是各种各样的原因造成的,有可能是上网的人太多,也有可能是中间网络设备有故障了。这跟我们平时路上堵车的原理一样一样的。在网络出现拥堵时,如果继续发送大量数据包,可能会导致数据包时延、丢失等,这时 TCP 就会重传数据,但是一重传就会导致网络的负担更重,于是会导致更大的延迟以及更多的丢包,这个情况就会进入恶性循环被不断地放大....
所以,TCP 不能忽略网络上发生的事,它被设计成一个无私的协议,当网络发送拥塞时,TCP 会自我牺牲,降低发送的数据量。
于是,就有了拥塞控制,控制的目的就是避免「发送方」的数据填满整个网络。
拥塞控制算法是通过 慢启动、拥塞避免、拥塞发生、拥塞恢复等阶段实现的,常见的算法有Reno,New-Reno,Cubic,BBR,BBRv2. 这里涉及的窗口是拥塞窗口
十:什么叫零窗口
在流量控制中,接收端实在过于繁忙,应用程序无法再读取内存缓冲区内的数据,那么此时再来新的数据包就无处安放了,这个时候接收方回复给发送方的ACK中,Win就要归零,告诉发送方你别再发了,我GG了。
零窗口有什么风险?
接收方告诉发送方零窗口之后,发送方就不能再发数据了,就会等接收方告诉自己啥时候能发了才能继续发送数据。当接收方的数据被应用程序读取后,有能力继续接受数据后,接收方会通告发送方win值,让发送方继续发送数据过来。这个逻辑看起来没有问题。但是如果接收方通过win值的包丢了呢?那么发送方就会死等。
怎么解决这个问题?
TCP 为每个连接设有一个持续定时器,只要 TCP 连接一方收到对方的零窗口通知,就启动持续计时器。如果持续计时器超时,就会发送窗口探测 ( Window probe ) 报文,而对方在确认这个探测报文时,给出自己现在的接收窗口大小。
十一: 什么叫 糊涂窗口
如果接收方太忙了,来不及取走接收窗口里的数据,那么就会导致发送方的发送窗口越来越小。
到最后,如果接收方腾出几个字节并告诉发送方现在有几个字节的窗口,而发送方会义无反顾地发送这几个字节,这就是糊涂窗口综合症。
糊涂窗口的危害?
为了发送几个字节的数据,需要带上TCP+IP+MAC头部那么多字节,这就像花几百块钱坐高铁跑去长沙,就吃了一口臭豆腐就回来了一样,性价比太低了。
如何解决糊涂窗口:
1. 避免让接收端通告小窗口给发送方。当「窗口大小」小于 min( MSS,缓存空间/2 ) ,也就是小于 MSS 与 1/2 缓存大小中的最小值时,就会向发送方通告窗口为 0,也就阻止了发送方再发数据过来。
2. 发送方 延时发送数据,经典算法是Nagle 算法。当数据量特别小的时候先不发送,而是攒多了要发送的数据再一起发送。但是这对于实时性要求很高的业务,是很不利的。这个功能的开启,一定要慎重慎重再慎重!
十二:TCP的拥塞控制算法如何配置
在linux命令行中,我们可以使用sysctl命令来操作拥塞控制算法。
查看当前系统支持的拥塞控制算法有哪些
# sysctl net.ipv4.tcp_available_congestion_control查看当前系统正在使用的拥塞控制算法
# sysctl net.ipv4.tcp_congestion_control配置当前系统的拥塞控制算法(以cubic为例)
# sysctl net.ipv4.tcp_congestion_control=cubic十三:什么是TSO(TCP Segment Offload)?
TSO (TCP Segmentation Offload) 是一种利用网卡替代CPU对大数据包进行分片,降低CPU负载的技术。如果数据包的类型只能是TCP,则被称之为TSO。此功能需要网卡提供支持。
正常数据包分片是在内核IP层做的,按照MTU大小进行分片,分成多个MTU大小的数据包。然后再把这些小数据包交给IP层,IP层找到下一跳MAC地址,然后交给数据链路层封装MAC头,最后交给网卡驱动,通过网卡发送出去。数据包到达目的地后,目的地内核再把分片的数据包重组起来。然而分片和重组的操作都会有不小的性能消耗,所以内核为了避免在IP层分片,基本上在TCP层就已经按照MSS大小进行分段了,这样每个TCP包到达IP层后,不会超过MTU,这样的话也就不会存在分片和重组了。
MTU一般大小为1500个字节,MSS一般大小为1460个字节。所以正常没有TSO功能的情况下,每个包都只有1500个字节,如果要发送的数据很大,就会分成多个1500个字节的数据包,在内核中进行拷贝,这样就会消耗CPU,导致CPU负载就很低,所以TSO就出现了。
TSO 是使得网络协议栈能够将大块 buffer 推送至网卡,然后网卡执行分片工作,这样减轻了CPU的负荷,其本质实际是延缓分片。这种技术在Linux中被叫做GSO(Generic Segmentation Offload),它不需要硬件的支持分片就可使用。对于支持TSO功能的硬件,则先经过GSO功能处理,然后使用网卡的硬件分片能力进行分片;而当网卡不支持TSO功能时,则将分片的执行放在了将数据推送的网卡之前,也就是在调用网卡驱动注册的ndo_start_xmit函数之前。
十四:数据包的分片到底是TCP做的还是IP层做的?
一般来说,传输层我们叫分段,IP层才叫分片。
对于TCP协议来说,一般是不会存在IP分片的,因为TCP层就已经按照MSS大小进行分好了,到达IP层就不需要再分片;但是对于UDP来说,UDP不会对其进行分段,那么就只好在IP层进行分片了,IP层分片后数据包到达目的地后再由目的端的IP层进行重组。所以TCP数据包一般避免了IP分片,UDP数据包如果程序员不在应用层进行分段,就会引起IP分片。
TCP是如何协商MSS的?
TCP在三次握手建连的时候,SYN报文的option字段中写明了本端的MSS值;服务端在回复SYN+ACK时候也写明了服务端的MSS值。而最终取两端的小值作为最终的MSS值,这就是MSS的协商过程。所以看到了吗,MSS的值只看客户端和服务端的能力,根本不顾中间网络设备的死活,假设万一中间设备所能承受的MTU很小呢,比客户端和服务端的都小呢?那么在到达该网络设备前还是会进行IP分片,所以TCP无法完全保证不会产生IP分片。
为何IP分片不好?
一个UDP报文如果因为size > MTU,则会被IP层分成两片或者多片,但是只有一片有端口号,由于其它分片没有端口号,能否通过防火墙则完全看防火墙的脸色,所以对于能否通信成功是一个未知数。如果防火墙网开一面,不检查端口号,分片可以全部通行,到目的地再组装到一起,IP层提交给UDP/DNS,一点问题没有。但是防火墙的安全功能大打折扣,如何阻止非法的外来攻击包?如果防火墙严格检查端口号,则没有端口号的分片则统统丢弃,造成通信障碍。所以选择一个合适的UDP size至关重要,避免分片。
十五:TCP keepalive
TCP使用探测包来进行保活,该探测包payload为空,按照应用程序的频次发送,如果对端在应用程序的要求内无回应,主动探测端就会通过发送FIN报文来关闭连接。
这里涉及四个参数,
SO_KEEPALIVE:是否开启保活
TCP_KEEPIDLE:连接空闲多久就开始触发探测包的发送
TCP_KEEPINTVL:每隔这么长时间就发送一个探测包
TCP_KEEPCNT:连续发送这么多个探测包都得不到回应的话就把连接断掉
下面写个简单代码展示一下用法
int keepAlive = 1;
int keepIdle = 10;
int keepInterval = 3;
int keepCount = 57;
Setsockopt(listenfd, SOL_TCP, TCP_KEEPIDLE, (void *)&keepIdle, sizeof(keepIdle));
Setsockopt(listenfd, SOL_TCP,TCP_KEEPINTVL, (void *)&keepInterval, sizeof(keepInterval));
Setsockopt(listenfd,SOL_TCP, TCP_KEEPCNT, (void *)&keepCount, sizeof(keepCount));
Setsockopt(listenfd, SOL_SOCKET, SO_KEEPALIVE, (void*)&keepAlive, sizeof(keepAlive));上述保活参数(int keep_alive = 1;int keep_idle = 10;int keep_interval = 3;int keep_count = 57;)表示10秒内无交互后,每隔3秒检测一次,57次都没得到响应时会断开连接。
假设服务端开启了保活机制,客户端挂了(内核都挂了),会发生什么呢?这里分两个情况:
-
客户端挂了后,服务端没有数据进行交互了,那就会触发探测,在探测过程中,如果客户端重启成功了,会回应RST报文,这个时候服务端收到RST报文就会把连接资源释放掉;如果在探测过程中,客户端一直没有进行重启成功,那么就会等待探测次数用完然后服务端释放连接。
-
客户端挂了后,服务端还有数据往客户端发送,那么同样的,如果客户端重启成功了,会回应RST,服务端收到RST报文就会把连接资源释放掉。但是如果客户端一直没有重启成功,那么就触发了TCP的超时重传机制。内核会根据 tcp_retries2(最大重传次数) 设置的值,计算出一个最大超时时间。在重传报文且一直没有收到对方响应的情况时,先达到「最大重传次数」或者「最大超时时间」这两个的其中一个条件后,就会停止重传。
nginx如何配置keepalive?
nginx可以通过listen命令中添加参数来配置so_keepalive
listen 8443 so_keepalive=on|off|[keepidle]:[keepintvl]:[keepcnt] nginx还有一个指令keepalive_timeout,注意这个指令可不是tcp 保活,这个是连接超时时间:定义了 Nginx 在处理完一次请求后,在处理下一次请求之前,与客户端保持连接的时间长度。这样可以减少建立连接的时间,提高请求的效率。
十六:一条TCP连接的开销
| TCP状态 | 收发数据 | 客户端 | 服务端 | 备注 |
| Establish | 无 | 3.42k | 3.27k | socket_alloca等核心内核对象 |
| Establish | 客户端发送服务端不收 | 7.66k | 5.47k | 客户端的发送缓存区没回收,服务器也多了接收缓存区 |
| Establish | 客户端发送服务端接收 | 3.24k | 服务器接收缓存区用完回收了 | |
| Establish | 服务器发送客户端不收 | 4.82k | 3.39k | 服务器发送缓存区及时回收了,客户端多了size-1024等内核对象 |
| Establish | 服务器发送客户端接收 | 3.56k | 客户端接收缓存区用完回收了 | |
| Time_Wait | 无 | 0.5k | 0 | Time_wait下会回收无用对象,服务端就直接关闭了 |
十七:是时候谈谈拥塞控制了(此问题摘录于网络)
端到端的TCP只能看到两个节点,那就是自己和对方,它们是看不到任何中间的路径的。可是IP网络却是一跳一跳的,它们的矛盾之处在于TCP的端到端流量控制必然会导致网络拥堵。因为每条TCP连接的一端只知道它对端还有多少空间用于接收数据,它们并不管到达对端的路径上是否还有这么大的容量,事实上所有连接的这些空间加在一起将瞬间超过网络的容量,因此TCP也不可能按照滑动窗口流量控制机制很理想的运行。
那么,TCP就势必需要一种拥塞控制机制,来感知网络路径的拥塞情况。
拥塞控制是一个整体的机制,它不偏向于任何TCP连接,因此这个机制内在的就包含了公平性。为什么会产生丢包呢?不要把路由器想成一种线速转发设备,再好的路由器只要接入网络,总是会拉低网络的总带宽,因此即使只有一个TCP连接,由于TCP的发送方总是以发送链路的带宽发送分段,这些分段在经过路由器的时候排队和处理总是会有时延,因此最终肯定会丢包的。丢包的延后性也会加重拥塞。假设一个TCP连接经过了N个路由器,前N-1个路由器都能顺利转发TCP分段,但是最后一个路由器丢失了一个分段,这就导致了这些丢失的分段浪费了前面路由器的大量带宽。
在介绍拥塞控制之前,首先介绍一下拥塞窗口,它实际上表示的也是“可以发送多少数据”,然而这个和接收端通告的接收窗口意义是不一样的,后者是流量控制用的窗口,而前者是拥塞控制用的窗口,体现了网络拥塞程度。
拥塞探测分为两类,一是慢启动,二是拥塞窗口加性扩大(也就是熟知的拥塞避免,然而这种方式是避免不了拥塞的)。
拥塞避免旨在还没有发生拥塞的时候就先提醒发送端,网络拥塞了,这样发送端就要么可以进入快速重传/快速恢复或者显式的减小拥塞窗口,这样就避免网络拥塞的一沓糊涂之后出现超时,从而进入慢启动阶段。
所谓快速重传/快速恢复是针对慢启动的,我们知道慢启动要从1个MSS开始增加拥塞窗口,而快速重传/快速恢复则是一旦收到3个冗余ACK,不必进入慢启动,而是将拥塞窗口缩小为当前阀值的一半加上3,然后如果继续收到冗余ACK,则将拥塞窗口加1个MSS,直到收到一个新的数据ACK,将窗口设置成正常的阀值,开始加性增加的阶段。
当进入快速重传时,为何要将拥塞窗口缩小为当前阀值的一半加上3呢?加上3是基于数据包守恒来说的,既然已经收到了3个冗余ACK,说明有三个数据分段已经到达了接收端,既然三个分段已经离开了网络,那么就是说可以在发送3个分段了,只要再收到一个冗余ACK,这也说明1个分段已经离开了网络,因此就将拥塞窗口加1个MSS。直到收到新的ACK,说明直到收到第三个冗余ACK时期发送的TCP分段都已经到达对端了,此时进入正常阶段开始加性增加拥塞窗口。
超时重传和收到3个冗余ACK后重传:这两种重传的意义是不同的,超时重传一般是因为网络出现了严重拥塞(没有一个分段到达,如果有的话,肯定会有ACK的,若是正常ACK,则重置重传定时器,若是冗余ACK,则可能是个别报文丢失或者被重排序,若连续3个冗余ACK,则很有可能是个别分段丢失),此时需要更加严厉的缩小拥塞窗口,因此此时进入慢启动阶段。而收到3个冗余ACK后说明确实有中间的分段丢失,然而后面的分段确实到达了接收端,这因为这样才会发送冗余ACK,这一般是路由器故障或者轻度拥塞或者其它不太严重的原因引起的,因此此时拥塞窗口缩小的幅度就不能太大,此时进入快速重传/快速恢复阶段。
常见的有哪些拥塞控制算法?Reno、New Reno、 Cubic、BBR
拥塞控制算法--Reno算法,上面已经讲解过了,就是慢启动、拥塞避免、拥塞发生、快速恢复。
拥塞控制算法-New Reno算法:
NewReno是基于Reno的改进版本,主要是改进了快速恢复算法。
Reno提出的快速恢复算法提高了包丢失后的吞吐量和健壮性,但缺陷是它只考虑了只丢失一个包的情形,只要丢失了一个包,就被认为是发生了一次拥塞。在实际的网络中,一旦发生拥塞,会丢弃大量的包。如果采用Reno算法,它会认为网络中发生了多次拥塞,则会多次将cwnd和ssthresh减半,造成吞吐量极具下降,当发送窗口小于3时,将无法产生足够的ACK来触发快重传而导致超时重传,超时重传的影响是非常大的。
在只丢失一个数据包的情况下,NewReno和Reno的处理方法是一致的,而在同一个时间段丢失了多个包时,NewReno做出了改进。Reno快速恢复算法中,发送方只要收到一个新的ACK就会退出快速恢复状态而进入拥塞避免阶段,NewReno算法中,只有当所有丢失的包都重传并收到确认后才退出。在NewReno中,添加了恢复应答判断功能,使得TCP终端可以区分一次拥塞丢失多个包还是发生了多次拥塞。
下图是Reno算法的吞吐曲线。

拥塞控制算法--
Cubic算法CUBIC是当前Linux系统上默认的拥塞控制算法。它的拥塞控制窗口增长函数是一个三次函数,这样设计的目的是为了在当前的快速和长距离网络环境中有更好的扩展性。当今的因特网朝着速度更快,距离更长的趋势发展,致使针对传统网络设计的TCP拥塞控制算法在性能受到了挑战。上面的网络特性用一个专业名词描述叫做高BDP(bandwidth and delay product),它代表了带宽被完全利用时网络中能容纳的数据包总量。
传统的TCP拥塞控制算法,例如TCP-Reno,TCP-NewReno,TCP-SACK等之所以在新环境下不能充分利用网络带宽,主要是因为在进入拥塞避免阶段后,它们的拥塞窗口每经过一个RTT才加1,拥塞窗口的增长速度太慢,当碰上高带宽环境时,可能需要经历很多个RTT,拥塞窗口才能接近于一个BDP。如果是短流,可能拥塞窗口还没增长到一个BDP,数据流就已经结束了,致使网络带宽浪费和降低用户体验。
cubic窗口增长函数:W (t) = C(t − K) 3 + Wmax.其中C是CUBIC参数,t是离最近一次(丢包)窗口减小的时间,K是窗口从W增加到Wmax所用的时间.在不丢包的情况下,K=(beta*Wmax/C)^(1/3) (通过W(0)=-beta*Wmax得到。
下图是Cubic算法的曲线
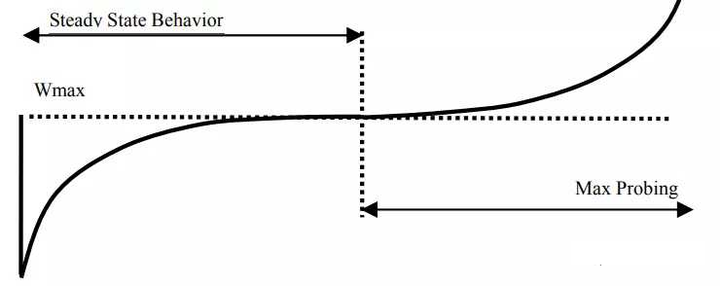
2006年,从2.6.18内核开始,CUBIC取代了BIC-TCP,成为了默认的tcp拥塞算法.
TCP拥塞控制算法--BBR算法,BBR算法是TCP拥塞控制算法的一个里程碑,或者说是一次新的变革。之前写过专门一篇文章来介绍,点击下面连接可以看下,这里不再陈述
十八:TCP常见的网络传输优化手段有哪些?
1. 修改初始拥塞窗口。
在新的RFC6928(2013年)中,初始窗口的上限修改成了如下定义:
min (10*MSS, max (2*MSS, 14600)),内核函数tcp_init_cwnd用于获取初始窗口,如果路由缓存中记录了初始拥塞窗口值,将优先使用记录值。否则,使用宏TCP_INIT_CWND定义的值10。
但是近年来由于国内基建发展迅速,慢启动如果从10开始往上增长,无疑是太慢了。在当前国内环境下,我们有必要改一下这个值,将初始窗口调成32,甚至64,这样的话对于100K以内的资源,在一个RTT内就可以传完。不过请注意,这个值不可以设的过大,不然很容易造成网络拥堵。要“量力而行”,对于客户端和服务端很近并且非西南偏远地区而言,设置成64是问题不大。这个值是经过龙眼本人亲测过的。
另外注意一点,在初始窗口增大到64之后,相应的接收窗口也需要增大到大于64才能产生预想的结果。默认情况下,窗口值由套接口的接收缓存的大小决定,如下在函数sock_init_data中,套接口的接收缓存大小等于sysctl_rmem_default。
2. 开启HyStart
这个参数叫 混合慢启动,基本上要配合初始窗口的修改而进行开启。
在初始窗口参数部分我们了解到,可以适当把初始窗口改成较大的值 以加速慢启动的过程,使拥塞窗口在很短的时间内就可以增长的很快,当然前提就是网络状况良好,不会出现丢包等现象。但是!在现实网络中,你很难判断出当前的网络到底有多好,如果贸然把初始窗口改大,慢启动阶段拥塞窗口过快的增长的话,就势必会出现丢包,一旦出现由于拥塞而丢包,那就不是丢一个包,会出现大量的丢包,此时反而会起到反作用。基于此,HyStart来了!
HyStart:Hybrid Slow Start,它在传统的慢启动算法中加入了判断机制,强制从慢启动转入拥塞避免。从而避免出现大量丢包的现象。
3. 启用tcp_sack
/proc/sys/net/ipv4/tcp_sack启用有选择的应答(1表示启用),通过有选择地应答乱序接收到的报文来提高性能,让发送者只发送丢失的报文段,(对于广域网通信来说)这个选项应该启用,但是会增加对CPU的占用。
后记
十八个常见问题到这里就结束了,这里非常感谢各位的阅读。在学习TCP的过程中,切忌一锅粥一盘棋的方式,一定要分清楚每一个算法到底是解决什么问题的,每一个问题和其他问题到底有什么关联,这些问题的解决方案之间有什么关联。
最后,希望大家能通过这十八个问题对TCP协议有个更深入的认识和了解!