Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators

Paper: https://arxiv.org/abs/2303.13439
Project: https://github.com/Picsart-AI-Research/Text2Video-Zero
原文链接:Text2Video-Zero:Text-to-Image扩散模型是Zero-Shot视频生成器(by 小样本视觉与智能前沿)
目录
文章目录
- Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators
- 01 现有工作的不足?
- 02 文章解决了什么问题?
- 03 关键的解决方案是什么?
- 04 主要的贡献是什么?
- 05 有哪些相关的工作?
- 06 方法具体是如何实现的?
- Zero-shot Text-to-Video 问题表述
- 方法细节
- 1)潜码的运动动态
- 2)重新编程跨帧注意
- 3)背景平滑
- 条件和特定的Text-to-Video
- 视频Instruct-Pix2Pix
- 07 实验结果和对比效果如何?
- 定性评估
- 和Baseline比较
- 1)定量比较
- 2)定性比较
- 08 消融研究告诉了我们什么?
- 09 结论
01 现有工作的不足?
最近的text-to-video生成方法依赖于计算量大的训练,并且需要大规模的视频数据集。
02 文章解决了什么问题?
在本文中,我们引入了zero-shot文本到视频生成的新任务,并通过利用现有文本到图像合成方法(例如stable diffusion)的能力,提出了一种低成本的方法(无需任何训练或优化),使其适用于视频领域。
03 关键的解决方案是什么?
- 利用运动动态生成帧的隐码,使全局场景和背景时间保持一致;
- 在第一帧的基础上使用每一帧的新跨帧注意力重新编程帧级自注意力,以保留上下文、外观和前景对象的身份。
04 主要的贡献是什么?
- Zero-shot文本到视频合成的新问题设置,旨在使文本引导的视频生成和编辑“freely affordable”。我们只使用预训练的文本到图像扩散模型,没有任何进一步的微调或优化。
- 通过在潜码中编码运动动态,并使用新的跨帧注意力重新编程每帧的自注意,两种新的post-hoc技术来强制时间一致的生成。
- 各种各样的应用证明了我们的方法的有效性,包括有条件的和专门的视频生成,以及视频指令-pix2pix,即通过文本指令编辑视频。
05 有哪些相关的工作?
- Text-to-Image Generation
- Text-to-Video Generation
与上述方法不同,我们的方法完全不需要训练,不需要大量计算能力或数十个GPU,这使得每个人都能负担得起视频生成过程。在这方面,Tunea Video[41]最接近我们的工作,因为它将必要的计算减少到只调谐一个视频。然而,它仍然需要优化过程,并且严重依赖于参考视频。
06 方法具体是如何实现的?
Zero-shot Text-to-Video 问题表述
给定一个文本描述τ和一个正整数m∈N,目标是设计一个函数 F \mathcal{F} F,输出视频帧 V ∈ R m x H x W x 3 V \in R^{mxHxWx3} V∈RmxHxWx3(对于预定义的分辨率H×W),它们表现出时间一致性。
为了确定函数 F \mathcal{F} F,不需要对视频数据集进行训练或微调。
我们的问题表述为文本到视频生成提供了一种新的范式。值得注意的是,零样本文本到视频方法自然地利用了文本到图像模型的质量改进。
方法细节
针对naive方法存在的外观不一致和时间不一致的问题,我们提出:
- 引入了潜码 x T 1 , . . . , x T m x_T^1,...,x_T^m xT1,...,xTm之间的运动动态,以保持全局场景时间一致。
- 使用跨帧注意机制来保持前景对象的外观和身份。
整体框架如图2所示。
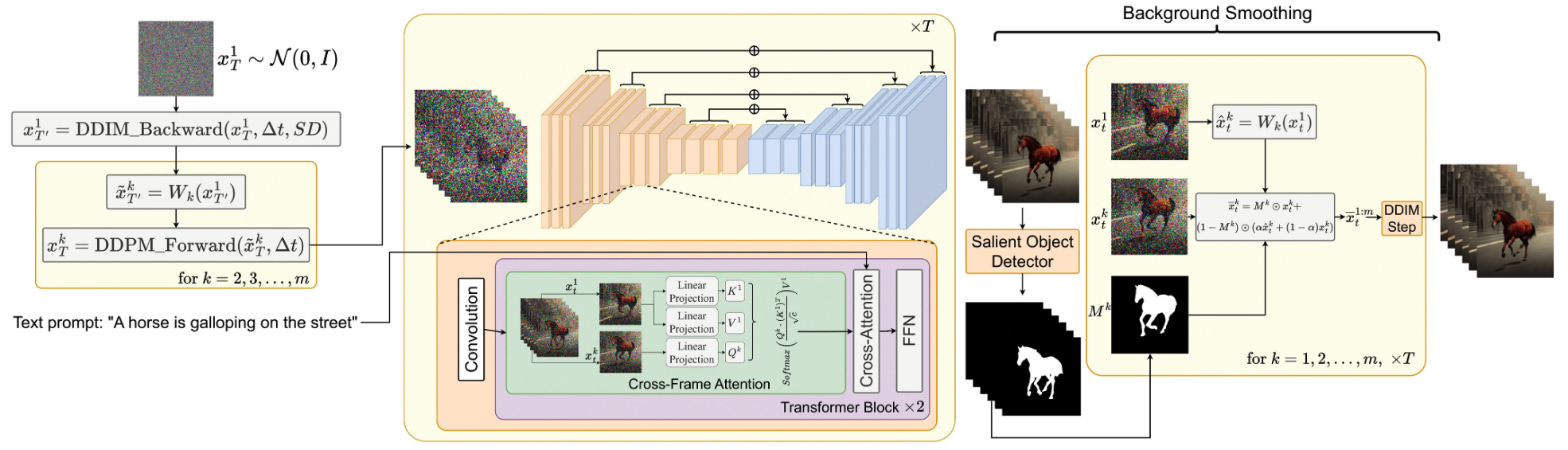
1)潜码的运动动态
我们通过执行以下步骤来构造潜码 x T 1 : m x_T^{1:m} xT1:m,而不是独立的从标准高斯分布随机采样它们(也参见算法1和图2)。
- 随机采样第一帧的潜码 x T 1 x_T^1 xT1 ~ N ( 0 , 1 ) N(0,1) N(0,1).
- 使用SD模型,在 x T 1 x_T^1 xT1上执行∆t步 DDIM后向传播,得到对应的潜码 x T ′ 1 x_{T'}^1 xT′1,其中 T ′ = T − Δ t T' = T - \Delta t T′=T−Δt.
- 为全局场景和摄像机运动定义一个方向 δ = ( δ x , δ y ) ∈ R 2 \delta = (\delta_x,\delta_y) \in R^2 δ=(δx,δy)∈R2。默认 δ \delta δ可以是主对角线方向,也就是 δ x = δ y = 1 \delta_x = \delta_y = 1 δx=δy=1。
- 为每一帧 k = 1 , 2 , . . . , m k=1,2,...,m k=1,2,...,m 计算全局平移量 δ k = λ ⋅ ( k − 1 ) δ \delta^k = \lambda \cdot(k-1)\delta δk=λ⋅(k−1)δ,其中 λ \lambda λ是控制全局运动的超参数。
- 构造运动平移流,最后的序列表示为 x ~ T ′ 1 : m \tilde{x}_{T'}^{1:m} x~T′1:m,其中 W k ( ⋅ ) W_k(\cdot) Wk(⋅)是通过向量 δ k \delta^k δk平移的翘曲操作.
![]()
- 在2-m帧上执行 Δ t \Delta t Δt步DDPM前向传播,得到对应的潜码 x T 2 : m x_T^{2:m} xT2:m.

2)重新编程跨帧注意
我们使用跨帧注意机制来保存有关(特别是)前景对象的外观,形状和身份在整个生成视频的信息。
为了利用跨帧注意力,同时在不重新训练的情况下利用预训练的SD,我们用跨帧注意替换它的每个自注意层,每一帧的注意都在第一帧上。
注意力公式:
![]()
在我们的方案中,每个注意力层接收m个输入,因此,线性注入层分别产生m个Q,K,V。
因此,我们可以用第一帧的值替换到其他2-m帧的值,实现跨帧注意力:
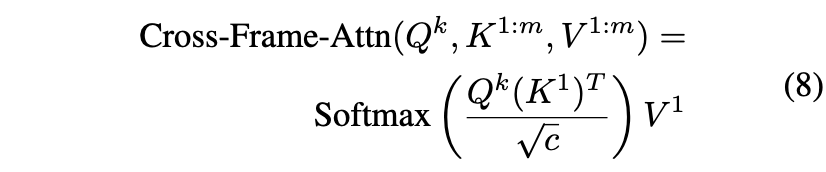
通过使用跨帧注意力,物体和背景的外观和结构以及身份从第一帧延续到后续帧,显著增加了生成帧的时间一致性(见图10及其附录,图16,20,21)。
3)背景平滑
在之前工作的基础上,我们对解码后的图像应用显著目标检测(一种in-house解决方案)[39],获得每帧k对应的前景掩码 M k M^k Mk。然后根据 W k W_k Wk定义的所使用的运动动态对 x t 1 x_t^1 xt1进行变形,并将结果表示为 x ^ t k : = W k ( x t 1 ) \hat{x}_t^k:=W_k(x_t^1) x^tk:=Wk(xt1)。
背景平滑是通过实际潜码 x t k x_t^k xtk与背景上扭曲的潜码 x ^ t k \hat{x}_t^k x^tk的凸组合来实现的,即:
![]()
其中
α
\alpha
α是超参数(实验中取0.6)。当没有提供指导时,我们在从文本生成视频时使用背景平滑。关于背景平滑的消融研究,见附录第6.2节。
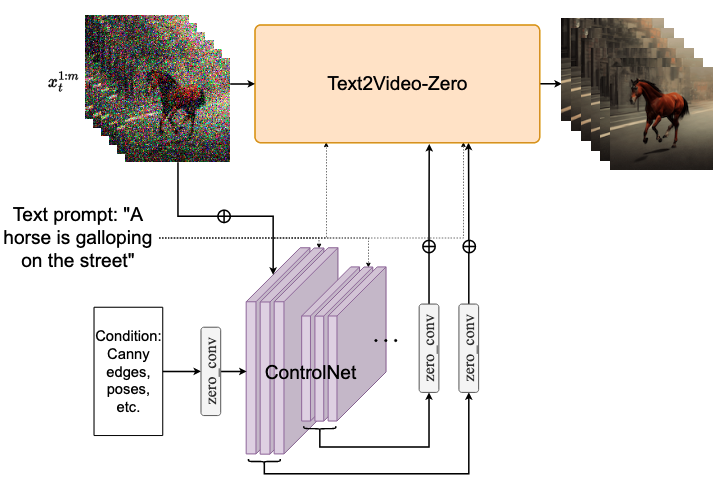
条件和特定的Text-to-Video
为了指导我们的视频生成过程,我们将我们的方法应用到基本的扩散过程中,即用运动信息来丰富潜码 x T 1 : m x_{T}^{1:m} xT1:m,并将UNet中的自注意转化为跨帧注意。在采用UNet进行视频生成任务的同时,在每帧潜码上应用ControlNet预训练的每帧复制分支,并将ControlNet分支输出添加到UNet的skip-connections。
视频Instruct-Pix2Pix
随着文字引导图像编辑方法的兴起,如Prompt2Prompt [9], directive - pix2pix [2], SDEdit[19]等,文字引导视频编辑方法出现了[1,16,41]。虽然这些方法需要复杂的优化过程,但我们的方法可以在视频领域采用任何基于sd的文本引导图像编辑算法,而无需任何训练或微调。在这里,我们采用文本引导的图像编辑方法instruction-pix2pix,并将其与我们的方法相结合。更准确地说,我们将directive-pix2pix中的自注意机制根据公式8改为跨帧注意力。
我们的实验表明,这种自适应显著提高了编辑视频的一致性(见图9).
07 实验结果和对比效果如何?
定性评估
在文本到视频的情况下,我们观察到它生成了与文本提示对齐良好的高质量视频(参见图3和附录)。例如,画中的熊猫自然地走在街上。同样地,使用来自边缘或姿势的额外引导(见图5、图6、图7和附录),可以生成与提示和引导相匹配的高质量视频,具有很好的时间一致性和身份保持性。在视频Instruct-pix2pix(见图1和附录)的情况下,生成的视频相对于输入视频具有高保真度,同时密切遵循指令。




和Baseline比较
1)定量比较
为了显示定量结果,我们评估CLIP评分[10],它表示视频-文本对齐。我们随机选取由CogVideo生成的25个视频,按照我们的方法用相同的提示来合成相应的视频。我们的方法和CogVideo的CLIP得分分别是31.19和29.63。因此,我们的方法略优于CogVideo,尽管后者有94亿个参数,需要在视频上进行大规模训练。
2)定性比较
我们在图8中给出了我们方法的几个结果,并与CogVideo[15]进行了定性比较。这两种方法在整个序列中都表现出良好的时间一致性,保持了目标和背景的同一性。然而,我们的方法显示出更好的文本-视频对齐。例如,虽然我们的方法正确地生成了图8(b)中一个人在阳光下骑自行车的视频,但CogVideo将背景设置为月光。同样在图8(a)中,我们的方法正确地显示了一个人在雪中跑步,而在CogVideo生成的视频中,雪和跑步的人都不清晰可见。
![Fig 8. 我们的方法与CogVideo在文本到视频生成任务上的比较(左为我们的方法,右为CogVideo[15])。更多的比较见附录图12。](https://img-blog.csdnimg.cn/img_convert/452f5764ab30ebcb48406bc41004a079.png)
视频instruction-pix2pix的定性结果以及与每帧directive-pix2pix和Tune-AVideo的视觉对比如图9所示。虽然instruction-pix2pix显示出良好的每帧编辑性能,但它缺乏时间一致性。这一点在描述滑雪者的视频中尤为明显,其中的雪和天空使用了不同的风格和颜色绘制。使用我们的Video instruction-pix2pix方法,这些问题得到了解决,从而在整个序列中实现了时间一致的视频编辑。

虽然Tune-A-Video创建了时间一致的视频生成,但它与指令引导的一致性不如我们的方法,难以创建本地编辑并丢失输入序列的细节。这一点在图9(左侧)所描绘的舞者视频的编辑中变得很明显。与Tune-A-Video相比,我们的方法更好地保留了背景,例如舞者身后的墙几乎保持不变。Tune-A-Video绘制了一堵经过严重修改的墙。此外,我们的方法更忠实于输入细节,例如,Video instruction-pix2pix完全按照提供的姿势绘制舞者(图9左),并显示输入视频中出现的所有滑雪人员(对比图9最后一帧(右)),与Tune-A-Video相比。所有上述的Tune-A-Video的弱点也可以在附录(图23、24)中提供的附加评估中观察到。
08 消融研究告诉了我们什么?
定性结果如图10所示。仅使用基本模型,即没有我们的更改(第一行),无法实现时间一致性。对于不受约束的文本到视频世代来说,这尤其严重。例如,马的外观和位置变化非常快,背景完全不一致。使用我们提出的运动动态(第二行),视频的一般概念在整个序列中得到更好的保存。例如,所有的帧都显示了一匹运动中的马的特写。同样地,女人的外观和中间四个人物的背景(使用带有边缘引导的ControlNet)得到了极大的改善。
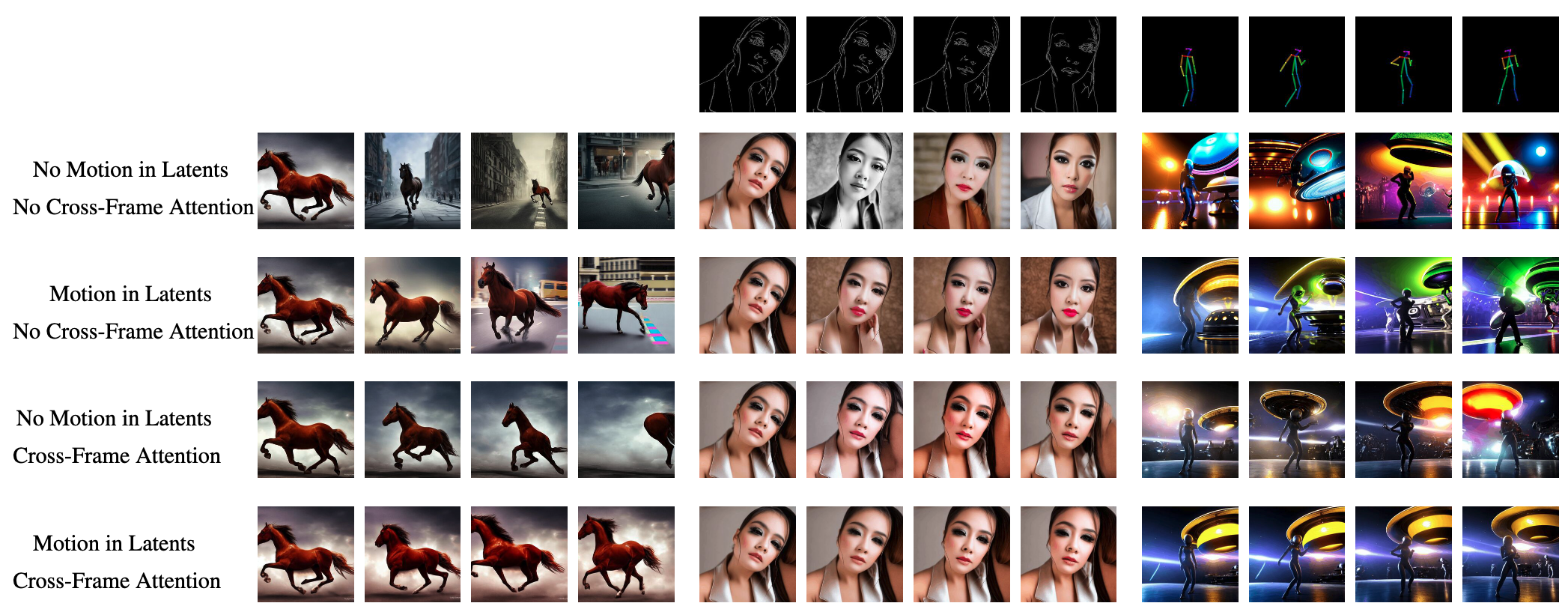
使用我们提出的跨帧注意(第三行),我们看到在所有帧中,对象身份及其外观的保存都得到了改进。最后,通过结合这两个概念(最后一行),我们实现了最佳的时间相干性。例如,我们在最后四列中看到相同的背景图案和关于物体身份的保留,同时在生成的图像之间自然过渡。
09 结论
本文针对Zero-shot文本视频合成问题,提出了一种时间一致视频生成的新方法。我们的方法不需要任何优化或微调,使文本到视频的生成及其应用程序对每个人都负担得起。
我们证明了我们的方法在各种应用中的有效性,包括条件和专业视频生成,以及视频指导-pix2pix,即指导视频编辑。
我们对该领域的贡献包括提出了zero-shot文本到视频合成的新问题,展示了文本到图像扩散模型用于生成时间一致视频的使用,并提供了我们的方法在各种视频合成应用中的有效性的证据。我们相信,我们提出的方法将为视频生成和编辑开辟新的可能性,使每个人都能获得并负担得起。
原文链接:Text2Video-Zero:Text-to-Image扩散模型是Zero-Shot视频生成器(by 小样本视觉与智能前沿)









![[centos] 新买的服务器环境搭建](https://img-blog.csdnimg.cn/2b7abff257734200b18aba815964a8b8.png)