分布式机器学习中,参数服务器(Parameter Server)用于管理和共享模型参数,其基本思想是将模型参数存储在一个或多个中央服务器上,并通过网络将这些参数共享给参与训练的各个计算节点。每个计算节点可以从参数服务器中获取当前模型参数,并将计算结果返回给参数服务器进行更新。
为了保持模型一致性,通常采用下列两种方法:
- 将模型参数保存在一个集中的节点上,当一个计算节点要进行模型训练时,可从集中节点获取参数,进行模型训练,然后将更新后的模型推送回集中节点。由于所有计算节点都从同一个集中节点获取参数,因此可以保证模型一致性。
- 每个计算节点都保存模型参数的副本,因此要定期强制同步模型副本,每个计算节点使用自己的训练数据分区来训练本地模型副本。在每个训练迭代后,由于使用不同的输入数据进行训练,存储在不同计算节点上的模型副本可能会有所不同。因此,每一次训练迭代后插入一个全局同步的步骤,这将对不同计算节点上的参数进行平均,以便以完全分布式的方式保证模型的一致性,即All-Reduce范式
PS架构
在该架构中,包含两个角色:parameter server和worker
parameter server将被视为master节点在Master/Worker架构,而worker将充当计算节点负责模型训练
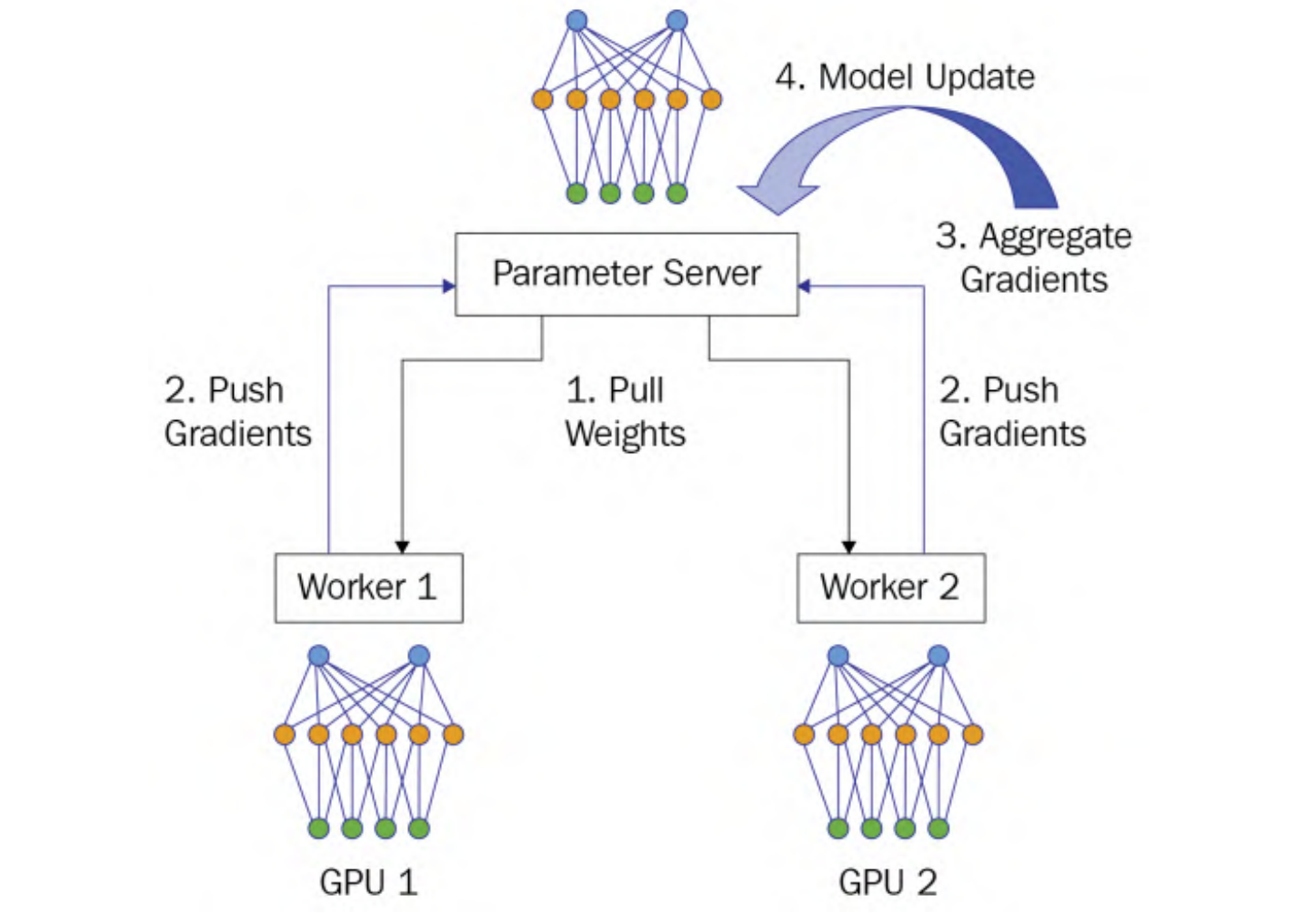
整个系统的工作流程分为4个阶段:
- Pull Weights: 所有worker从参数服务器获取权重参数
- Push Gradients: 每一个worker使用本地的训练数据训练本地模型,生成本地梯度,之后将梯度上传参数服务器
- Aggregate Gradients:收集到所有计算节点发送的梯度后,对梯度进行求和
- Model Update:计算出累加梯度,参数服务器使用这个累加梯度来更新位于集中服务器上的模型参数
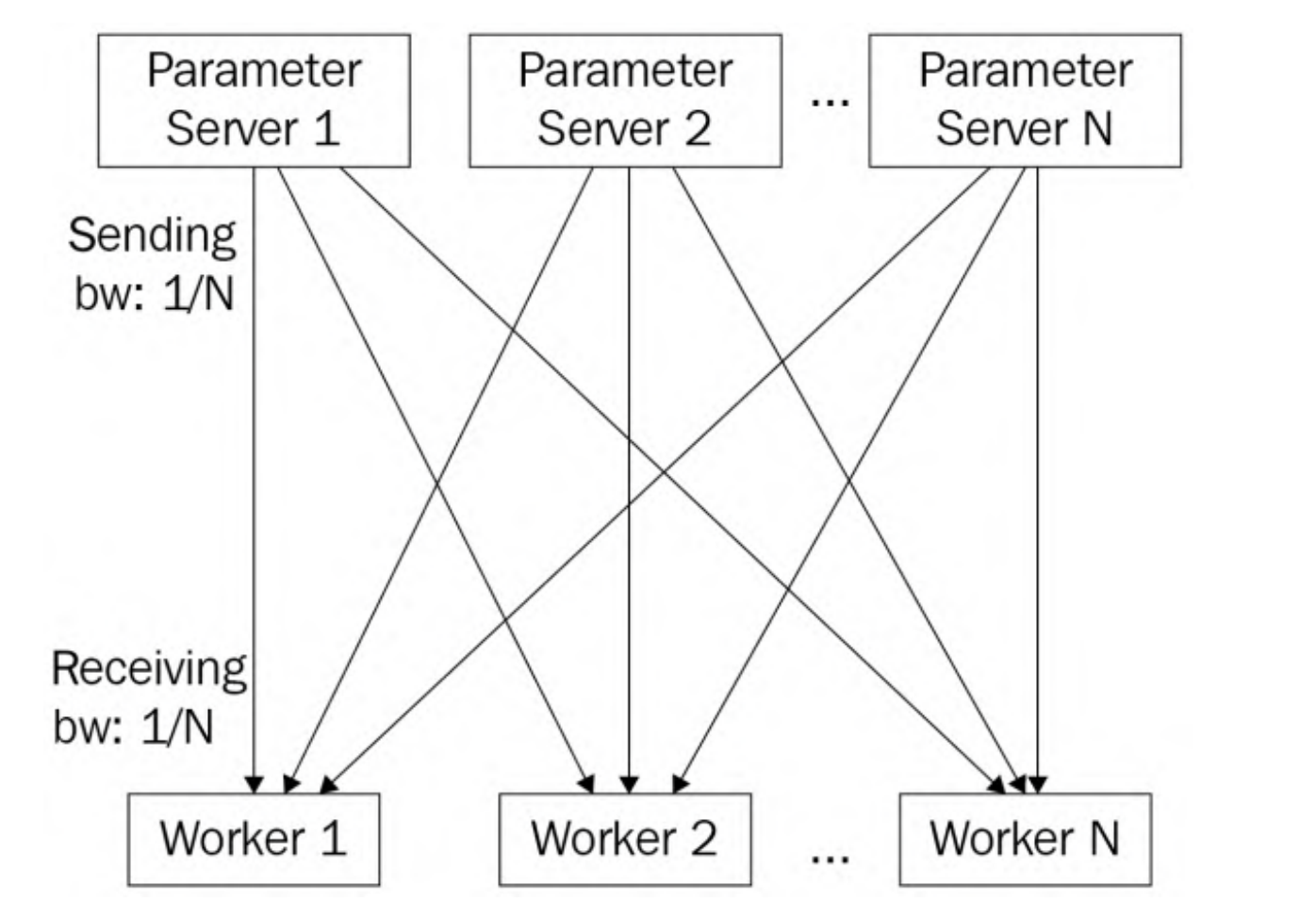
可见,上述的Pull Weights和Push Gradients涉及到通信,首先对于Pull Weights来说,参数服务器同时向worker发送权重,这是一对多的通信模式,称为fan-out通信模式。假设每个节点(参数服务器和工作节点)的通信带宽都为1。假设在这个数据并行训练作业中有N个工作节点,由于集中式参数服务器需要同时将模型发送给N个工作节点,因此每个工作节点的发送带宽(BW)仅为1/N。另一方面,每个工作节点的接收带宽为1,远大于参数服务器的发送带宽1/N。因此,在拉取权重阶段,参数服务器端存在通信瓶颈。
对于Push Gradients来说,所有的worker并发地发送梯度给参数服务器,称为fan-in通信模式,参数服务器同样存在通信瓶颈。
基于上述讨论,通信瓶颈总是发生在参数服务器端,将通过负载均衡解决这个问题
将模型划分为N个参数服务器,每个参数服务器负责更新1/N的模型参数。实际上是将模型参数分片(sharded model)并存储在多个参数服务器上,可以缓解参数服务器一侧的网络瓶颈问题,使得参数服务器之间的通信负载减少,提高整体的通信效率。
代码实现
定义网络结构:如上定义了一个简单的CNN
实现参数服务器:
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
if torch.cuda.is_available():
device = torch.device("cuda:0")
else:
device = torch.device("cpu")
self.conv1 = nn.Conv2d(1,32,3,1).to(device)
self.dropout1 = nn.Dropout2d(0.5).to(device)
self.conv2 = nn.Conv2d(32,64,3,1).to(device)
self.dropout2 = nn.Dropout2d(0.75).to(device)
self.fc1 = nn.Linear(9216,128).to(device)
self.fc2 = nn.Linear(128,20).to(device)
self.fc3 = nn.Linear(20,10).to(device)
def forward(self,x):
x = self.conv1(x)
x = self.dropout1(x)
x = F.relu(x)
x = self.conv2(x)
x = self.dropout2(x)
x = F.max_pool2d(x,2)
x = torch.flatten(x,1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.relu(x)
x = self.fc3(x)
output = F.log_softmax(x,dim=1)
return output如上定义了一个简单的CNN
实现参数服务器:
class ParamServer(nn.Module):
def __init__(self):
super().__init__()
self.model = Net()
if torch.cuda.is_available():
self.input_device = torch.device("cuda:0")
else:
self.input_device = torch.device("cpu")
self.optimizer = optim.SGD(self.model.parameters(),lr=0.5)
def get_weights(self):
return self.model.state_dict()
def update_model(self,grads):
for para,grad in zip(self.model.parameters(),grads):
para.grad = grad
self.optimizer.step()
self.optimizer.zero_grad()get_weights获取权重参数,update_model更新模型,采用SGD优化器
实现worker:
class Worker(nn.Module):
def __init__(self):
super().__init__()
self.model = Net()
if torch.cuda.is_available():
self.input_device = torch.device("cuda:0")
else:
self.input_device = torch.device("cpu")
def pull_weights(self,model_params):
self.model.load_state_dict(model_params)
def push_gradients(self,batch_idx,data,target):
data,target = data.to(self.input_device),target.to(self.input_device)
output = self.model(data)
data.requires_grad = True
loss = F.nll_loss(output,target)
loss.backward()
grads = []
for layer in self.parameters():
grad = layer.grad
grads.append(grad)
print(f"batch {batch_idx} training :: loss {loss.item()}")
return gradsPull_weights获取模型参数,push_gradients上传梯度
训练
训练数据集为MNIST
import torch
from torchvision import datasets,transforms
from network import Net
from worker import *
from server import *
train_loader = torch.utils.data.DataLoader(datasets.MNIST('./mnist_data', download=True, train=True,
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))])),
batch_size=128, shuffle=True)
test_loader = torch.utils.data.DataLoader(datasets.MNIST('./mnist_data', download=True, train=False,
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,),(0.3081,))])),
batch_size=128, shuffle=True)
def main():
server = ParamServer()
worker = Worker()
for batch_idx, (data,target) in enumerate(train_loader):
params = server.get_weights()
worker.pull_weights(params)
grads = worker.push_gradients(batch_idx,data,target)
server.update_model(grads)
print("Done Training")
if __name__ == "__main__":
main()来源:分布式机器学习(Parameter Server) - N3ptune - 博客园 (cnblogs.com)







![[centos] 新买的服务器环境搭建](https://img-blog.csdnimg.cn/2b7abff257734200b18aba815964a8b8.png)