动态规划(DP)是一种在多项式时间内解决某些特定类型问题的技术。动态规划解决方案比指数蛮力法更快,并且可以很容易地证明其正确性。
动态规划主要是对普通递归的优化。只要我们看到一个递归解决方案重复调用相同的输入,我们就可以使用动态规划来优化它。这个想法是简单地存储子问题的结果,以便我们不必在以后需要时重新计算它们。这种简单的优化将时间复杂度从指数降低到多项式。

动态规划算法的特点
- 一般来说,动态规划(DP)是解决某类问题的最强大的技术之一。
- 有一个优雅的方式来制定的方法和一个非常简单的思维过程,编码部分是非常容易的。
- 从本质上讲,这是一个简单的想法,在用给定的输入解决问题后,将结果保存为将来使用的参考,因此您不必重新解决它。简单地说“记住你的过去” 😃。
- 如果给定的问题可以分解成更小的子问题,而这些更小的子问题又可以分解成更小的子问题,这对DP来说是一个很大的提示,在这个过程中,你会看到一些重叠的子问题。
- 此外,子问题的最优解有助于给定问题的最优解(称为最优子结构属性)。
- 子问题的解决方案存储在一个表或数组(memoization)或自底向上的方式(制表),以避免冗余计算。
- 问题的解可以由子问题的解构造而成。
- 动态规划可以使用递归算法来实现,其中子问题的解被递归地找到,或者使用迭代算法来实现,其中通过以特定顺序处理子问题来找到解。
动态规划遵循以下原理:
- 描述最优解的结构,即建立解决方案的数学模型。
- 递归定义最优解的值。
- 使用自底向上的方法,计算每个可能的子问题的最优解的值。
- 使用上一步计算的信息构造原始问题的最优解。
应用领域
动态规划用于解决优化问题。它被用来解决许多现实生活中的问题,例如,
(i)做一个改变问题
(ii)背包问题
(iii)最优二叉查找树
动态规划算法和递归有什么区别?
- 在动态规划中,问题是通过将它们分解为较小的问题来解决较大的问题,而递归是当函数被调用并自行执行时。虽然动态规划可以在不使用递归技术的情况下运行,但由于动态规划的目的是优化和加速过程,因此程序员通常使用递归技术来有效地加速和转向过程。
- 当函数可以通过调用自身来执行特定任务时,接收递归函数的名称。为了执行和完成工作,该函数在必须执行时调用自身。
- 使用动态规划,你可以将问题分解成更小的部分,称为子问题,来解决它。动态规划涉及第一次解决问题,然后使用记忆存储解决方案。
- 因此,两种技术之间的主要区别在于其预期用途;递归用于使函数自动化,而动态规划是用于解决问题的优化技术。
- 递归函数识别何时需要它们,执行自己,然后停止工作。当函数识别出需要它的时刻时,它调用自身并被执行;这被称为递归情况。因此,一旦任务完成,函数就必须停止,这称为基本情况。
- 通过建立状态,动态规划识别问题,并将其划分为子问题,以解决整个场景。在解决这些子问题或变量之后,程序员必须在它们之间建立数学关系。最后但并非最不重要的是,这些解决方案和结果存储为算法,因此将来可以访问它们,而不必再次解决整个问题。
解决动态规划问题的技巧
-
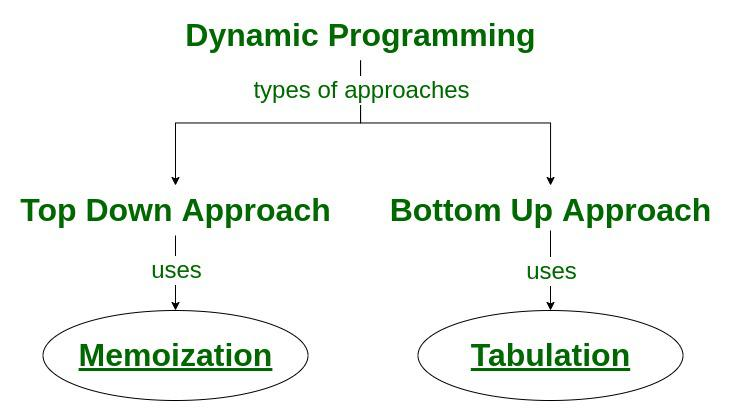
自上而下(记忆化):
分解给定的问题,以便开始解决它。如果您看到问题已经解决,请返回保存的答案。如果还没有解决,解决它并保存它。这通常很容易想到,也很直观,这被称为记忆化。 -
自下而上(动态规划):
分析问题,看看子问题是按什么顺序解决的,然后从琐碎的子问题开始解决给定的问题。这个过程确保子问题在主问题之前得到解决。这被称为动态规划。
如何解决动态规划问题?
要动态地解决问题,我们需要检查两个必要条件:
-
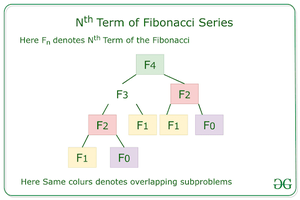
重叠子问题:当实际问题需要重复求解同一子问题时。该问题被称为具有重叠子问题属性。
-
最佳子结构特性:如果给定问题的最优解可由其子问题的最优解求得,则称该问题具有最优子结构性质。
解决动态规划问题的步骤
- 确定它是否是一个动态规划问题。
- 用最小参数确定状态表达式。
- 制定状态和转换关系。
- 做制表(或记忆)。
以下是制表和记忆的比较
记忆化:
- 自上而下方法
- 缓存函数调用的结果
- 递归实现
- 非常适合于具有相对较小的输入集的问题
- 当子问题有重叠的子问题时使用
制表:
- 自下而上的方法
- 将子问题的结果存储在表中
- 迭代实现
- 非常适合具有大量输入的问题
- 当子问题不重叠时使用
1) 如何将问题归类为动态规划算法问题?
- 通常,所有需要最大化或最小化某些数量的问题或计数问题,即在某些条件下对布置进行计数或某些概率问题,都可以通过使用动态规划来解决。
- 所有的动态规划问题都满足重叠子问题的性质,大多数经典的动态规划问题也满足最优子结构的性质。一旦我们在一个给定的问题中观察到这些属性,请确保它可以使用动态规划来解决。
2)决定状态:
动态规划的问题主要与状态及其转换有关。最基本的阶段必须非常小心地执行,因为状态转换取决于您选择的状态定义。
状态是可用于具体描述给定挑战中的给定位置或站立的特征的集合。为了最小化状态空间,这组参数必须尽可能紧凑。
3)在状态之间建立关系:
动态规划挑战中最难的部分就是这一步,它需要大量的直觉、观察和训练。
示例: 给定3个数字{1,3,5},任务是告诉我们可以使用给定的三个数字的总和来形成数字N的方式的总数。(允许重复和不同的布置)。
形成6的方式的总数是:8
1+1+1+1+1+1
1+1+1+3
1+1+3+1
1+3+1+1
3+1+1+1
3+3
1+5
5+1
以下是解决问题的步骤:
- 我们为给定的问题选择一个状态。
- N将被用作状态的决定因素,因为它可以用于识别任何子问题。
- DP状态将类似于状态(N),其中状态(N)是使用1、3和5创建N所需的布置的总数。确定任意两个状态之间的转换关系。
- 我们现在必须计算状态(N)。
3.1)如何计算状态?
因为我们只能用1、3或5来构成给定的数N。假设我们知道N = 1,2,3,4,5,6的结果
状态(n = 1)、状态(n = 2)、状态(n = 3)…………状态(n = 6)
现在,我们希望知道状态(n = 7)的结果。看,我们只能加1,3和5。现在我们可以通过以下3种方式得到总数为7的结果:
- 向所有可能的状态组合加1(n = 6)
例如: [ (1+1+1+1+1+1) + 1]
[ (1+1+1+3) + 1]
[ (1+1+3+1) + 1]
[ (1+3+1+1) + 1]
[ (3+1+1+1) + 1]
[ (3+3) + 1]
[ (1+5) + 1]
[ (5+1) + 1]- 对所有可能的状态组合加3(n = 4);
[(1+1+1+1) + 3]
[(1+3) + 3]
[(3+1) + 3]- 对所有可能的状态组合加5(n = 2)
[ (1+1) + 5]
现在,仔细想想,并满足上述三种情况是涵盖所有可能的方式,形成总和为7;
因此,我们可以说,结果为
状态⑺ =状态⑹ +状态⑷ +状态⑵
或
状态⑺ =状态(7-1)+状态(7-3)+状态(7-5)
总的来说
状态(n)=状态(n-1)+状态(n-3)+状态(n-5)
以下是上述方法的python实现:
# Python program to Returns the number of arrangements to form 'n'
def solve(n):
# Base case
if(n < 0):
return 0
if(n == 0):
return 1
return solve(n-1)+solve(n-3)+solve(n-5)
时间复杂度:O(3^n)。 因为在每个阶段我们需要做三个决策,树的高度是n的数量级。
空间复杂度:O(n)。由于递归调用堆栈而使用了额外的空间。
上面的代码似乎是指数级的,因为它一次又一次地计算相同的状态。所以,我们只需要添加记忆。
4)为状态添加记忆或制表
基于动态规划的解决方案的最简单部分是这样的。简单地存储状态解将允许我们在下一次需要状态时从内存中访问它。
添加记忆到上述代码:
# Initialize to -1
dp = []
# This function returns the number of
# arrangements to form 'n'
def solve(n):
# base case
if n < 0:
return 0
if n == 0:
return 1
# Checking if already calculated
if dp[n] != -1:
return dp[n]
# Storing the result and returning
dp[n] = solve(n-1) + solve(n-3) + solve(n-5)
return dp[n]
时间复杂度:O(n),因为我们只需要进行3n次函数调用,并且不会有重复的计算,因为我们会返回以前计算的结果。
空间复杂度:O(n)
如何通过实例解决动态规划问题?
问题:让我们找出斐波那契数列的第n项。斐波那契数列是一系列的数字,其中每个数字是前两个数字的总和。例如,0、1、1、2、3等。这里,每个数字是前面两个数字的总和。
朴素方法:找到第n个斐波那契数的基本方法是使用递归。
下面是上述方法的实现:
# Function to find nth fibonacci number
def fib(n):
if (n <= 1):
return n
x = fib(n - 1)
y = fib(n - 2)
return x + y
n = 5;
# Function Call
print(fib(n))
'''
5
'''
复杂性分析:
时间复杂度: O(2^n)
- 这里,对于每个n,我们需要递归调用fib(n - 1)和fib(n - 2)。对于fib(n - 1),我们将再次递归调用fib(n - 2)和fib(n - 3)。类似地,对于fib(n - 2),递归调用fib(n - 3)和fib(n - 4),直到我们到达基本情况。
- 在每个递归调用期间,我们执行常量工作(k)(将先前的输出相加以获得当前输出)。我们在每个级别执行2nK工作(其中n = 0,1,2,…)。由于n是达到1所需的调用数,因此我们在最后一级执行2n-1 k。总功可计算为:
- 如果我们画出斐波纳契递归的递归树,那么我们发现树的最大高度将是n,因此斐波纳契递归的空间复杂度将是O(n)。
有效方法:由于它是一个非常可怕的复杂性(指数),因此我们需要用一种有效的方法来优化它。(回忆)
让我们看看下面的例子,寻找第5个斐波那契数。
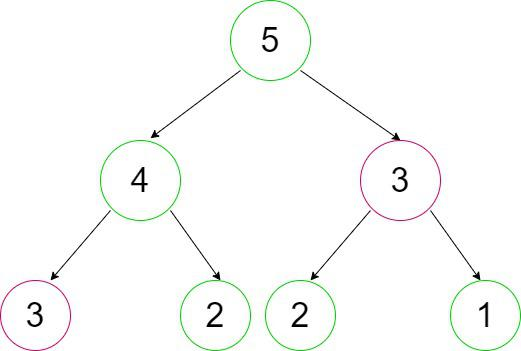
观察结果:
- 整个程序重复递归调用。如上图所示,为了计算fib(4),我们需要fib(3)的值(第一次递归调用fib(3)),为了计算fib(5),我们再次需要fib(3)的值(第二次类似的递归调用fib(3))。
- 这两个递归调用都显示在上面的大纲圆圈中。
- 类似地,还有许多其他的我们正在重复递归调用的对象。
- 递归通常涉及重复的递归调用,这增加了程序的时间复杂度。
- 通过存储以前遇到的值的输出(最好是数组,因为可以最有效地遍历和提取这些值),我们可以克服这个问题。下次我们对这些值进行递归调用时,我们将使用它们已经存储的输出,而不是重新计算它们。
- 通过这种方式,我们可以提高代码的性能。记忆化是存储每个递归调用的输出以供以后使用的过程,防止代码再次计算它。
记忆方式:在我们的例子中,为了实现这一点,我们将简单地将答案数组初始化为-1。当我们进行递归调用时,我们将首先检查存储在对应于该位置的答案数组中的值是否为-1。值-1表示我们还没有计算它,必须递归计算它。输出必须存储在答案数组中,以便下次遇到相同的值时,可以直接从答案数组中使用。
现在,在该记忆过程中,考虑上述斐波那契数示例,可以观察到唯一调用的总数将至多仅为(n + 1)。
# Helper Function
def fibo_helper(n, ans):
# Base case
if (n <= 1):
return n
# To check if output already exists
if (ans[n] is not -1):
return ans[n]
# Calculate output
x = fibo_helper(n - 1, ans)
y = fibo_helper(n - 2, ans)
# Saving the output for future use
ans[n] = x + y
# Returning the final output
return ans[n]
def fibo(n):
ans = [-1]*(n+1)
# Initializing with -1
#for (i = 0; i <= n; i++) {
for i in range(0,n+1):
ans[i] = -1
return fibo_helper(n, ans)
# Code
n = 5
# Function Call
print(fibo(n))
时间复杂度:O(n)
空间复杂度:O(n)
上述方法的优化
- 在上面的代码中,我们可以看到任何Fibonacci数的当前状态仅取决于前两个数字
- 因此,使用此观察,我们可以得出结论,我们不需要存储大小为n的整个表,而是可以仅存储前两个值
- 这样我们就可以优化上面代码中的空间复杂度O(n)到O(1)
# Python code for the above approach
# Function for calculating the nth Fibonacci number
def fibo(n):
prevPrev, prev, curr = 0, 1, 1
# Using the bottom-up approach
for i in range(2, n+1):
curr = prev + prevPrev
prevPrev = prev
prev = curr
# Returning the final answer
return curr
# Drivers code
n = 5
# Function Call
print(fibo(n))
关于动态规划算法的常见问题:
1)动态规划只是递归吗?
动态规划和递归是完全不同的东西。虽然动态规划可以使用递归技术,但递归本身与动态规划没有任何相似之处。动态规划涉及将问题分解为更小的子问题,存储这些子问题的解以避免冗余计算,并使用这些解来构造整体解。另一方面,递归是一种通过将问题分解为更小的子问题并递归求解来解决问题的技术。
2)动态规划是如何工作的?
动态规划(DP)是一种在多项式时间内解决某些特定类型问题的技术。动态规划解决方案比指数蛮力法更快,并且可以很容易地证明其正确性。动态规划的工作原理是将问题分解为更小的子问题,独立地解决每个子问题,并使用这些子问题的解决方案来构建整体解决方案。子问题的解决方案存储在一个表或数组(memoization)或自底向上的方式(制表),以避免冗余计算。
3)贪婪算法与动态规划有何相似之处?
贪婪算法类似于动态规划,因为它们都是优化工具。动态规划和贪婪算法都用于优化问题。然而,虽然动态规划将问题分解为更小的子问题并独立地解决它们,但贪婪算法在每一步都进行局部最优选择,希望找到全局最优解。
4)什么是动态规划的基础?
使用动态规划可以更快地解决子问题,动态规划只不过是递归和记忆,从而降低代码的复杂性并使其更快。以下是基本要点:
- 把问题分解成更小的子问题。
- 独立解决每个子问题。
- 存储子问题的解以避免冗余计算。
- 使用子问题的解来构造整体解。
- 使用最优性原则确保解决方案是最优的。
5)动态规划的优点是什么?
动态规划具有能够找到局部和全局最优解的优点。此外,可以利用实践经验来受益于动态规划的更高效率。然而,动态规划并没有一个单一的、公认的范式,在解决问题时可能会出现其他情况。动态规划算法保证在一组可能的解中找到最优解,只要问题满足最优性原则。子问题的解决方案可以存储在一个表中,该表可以重复用于类似的问题。动态规划可以应用于广泛的问题,包括优化、序列比对和资源分配。
结论
总之,动态规划是一种用于优化问题的强大的问题解决技术。动态规划是递归的一种上级形式,它克服了递归的局限性。它涉及将问题分解为更小的子问题,独立地解决每个子问题,并使用这些子问题的解决方案来构建整体解决方案。动态规划算法的关键特征包括重叠子问题、最优子结构、记忆或制表,以及使用迭代或递归方法。
动态规划与其他解决问题的技术相比有几个优点,包括效率、简单性、灵活性、最优性、清晰性和代码可重用性。它不仅仅是递归,尽管它可以使用递归算法来实现。动态规划与贪婪算法的不同之处在于,它将问题分解为更小的子问题,独立地解决每个子问题,并使用子问题的解来构造整体解。
动态规划的基础包括将问题分解为更小的子问题,独立地解决每个子问题,存储子问题的解决方案以避免冗余计算,使用子问题的解决方案来构建整体解决方案,并使用最优性原则来确保解决方案是最优的。 然而,DP有时可能很难理解,这使得它成为编码面试的一个很受欢迎的选择。了解DP功能如何工作对每个人都很有用,无论他们是专业人士还是准备实习的学生。
总体而言,动态规划是解决复杂优化问题的有价值的工具,可以带来更高效和有效的解决方案。