一、HashMap中的死链问题
多个线程对hashmap进行扩容时需要将原有数据转移到新的table数组中,这个过程中会重新计算每个元素对应的数组下标从而改变元素的next指针,而另一个线程重复对该链表进行迁移时可能会导致循环链表的产生
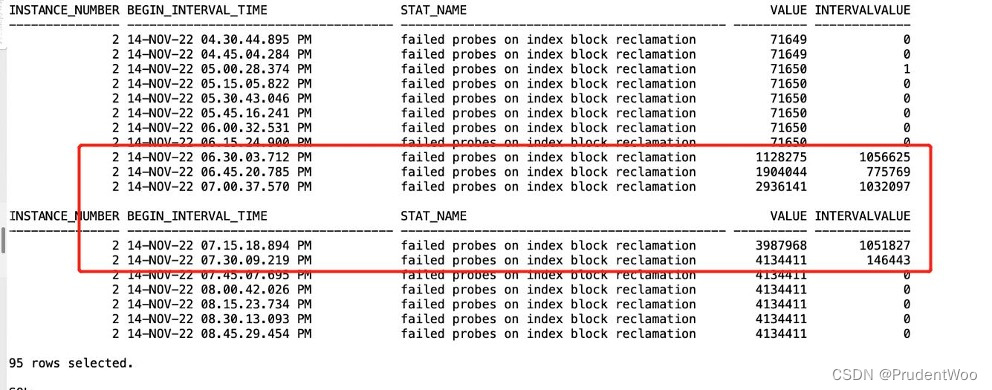
原始链表,格式:[下标] (key,next)
[1] (1,35)->(35,16)->(16,null)
线程 a 执行到 1 处 ,此时局部变量 e 为 (1,35),而局部变量 next 为 (35,16) 线程 a 挂起
线程 b 开始执行
第一次循环
[1] (1,null)
第二次循环
[1] (35,1)->(1,null)
第三次循环
[1] (35,1)->(1,null)
[17] (16,null)
切换回线程 a,此时局部变量 e 和 next 被恢复,引用没变但内容变了:e 的内容被改为 (1,null),而 next 的内
容被改为 (35,1) 并链向 (1,null)
第一次循环
[1] (1,null)
第二次循环,注意这时 e 是 (35,1) 并链向 (1,null) 所以 next 又是 (1,null)
[1] (35,1)->(1,null)
第三次循环,e 是 (1,null),而 next 是 null,但 e 被放入链表头,这样 e.next 变成了 35 (2 处)
[1] (1,35)->(35,1)->(1,35)
已经是死链了
二、JDK8-ConcurrentHashMap
ConcurrentHashMap是一种线程安全的hashmap,那么很多同学就会有疑问,hashtable不也是线程安全的嘛?确实,hashtable也是一种线程安全的hashmap,但是它实现线程安全的方式过于简单粗暴,直接用synchornized修饰方法,故效率很低。而ConcurrentHashMap则不同,它在方法内部的很多地方使用cas的方式进行并发控制,而不是简单粗暴的加锁,大大提高了并发性能
额外提一句,JUC包下提供了许多并发安全的容器,它们的前缀大概有如下几种,我们来分别讨论它们的特性。
包含三类关键词:
Blocking、CopyOnWrite、Concurrent
- Blocking 大部分实现基于锁,并提供用来阻塞的方法
- CopyOnWrite 之类容器修改开销相对较重
- Concurrent 类型的容器
- 内部很多操作使用 cas 优化,一般可以提供较高吞吐量
- 弱一致性
- 遍历时弱一致性,例如,当利用迭代器遍历时,如果容器发生修改,迭代器仍然可以继续进行遍
历,这时内容是旧的。对于非安全容器来讲,使用 fail-fast 机制也就是让遍历立刻失败,抛出ConcurrentModificationException,不再继续遍历 - 求大小弱一致性,size 操作未必是 100% 准确
- 读取弱一致性
- 遍历时弱一致性,例如,当利用迭代器遍历时,如果容器发生修改,迭代器仍然可以继续进行遍
重要属性
// 默认为 0
// 当初始化时, 为 -1
// 当扩容时, 为 -(1 + 扩容线程数)
// 当初始化或扩容完成后,为 下一次的扩容的阈值大小
private transient volatile int sizeCtl;
// 整个 ConcurrentHashMap 就是一个 Node[]
static class Node<K,V> implements Map.Entry<K,V> {}
// hash 表
transient volatile Node<K,V>[] table;
// 扩容时的 新 hash 表
private transient volatile Node<K,V>[] nextTable;
// 扩容时如果某个 bin 迁移完毕, 用 ForwardingNode 作为旧 table bin 的头结点
static final class ForwardingNode<K,V> extends Node<K,V> {}
// 用在 compute 以及 computeIfAbsent 时, 用来占位, 计算完成后替换为普通 Node
static final class ReservationNode<K,V> extends Node<K,V> {}
// 作为 treebin 的头节点, 存储 root 和 first
static final class TreeBin<K,V> extends Node<K,V> {}
// 作为 treebin 的节点, 存储 parent, left, right
static final class TreeNode<K,V> extends Node<K,V> {
构造器
可以看到实现了懒惰初始化,在构造方法中仅仅计算了 table 的大小,以后在第一次使用时才会真正创建
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
// tableSizeFor 仍然是保证计算的大小是 2^n, 即 16,32,64 ...
int cap = (size >= (long)MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
get流程
由于该方法不涉及写操作因此没有保证并发安全的措施,整体流程与HashMap的get方法基本一致
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
//保证返回的结果为正数
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
//eh为头节点的hash值
if ((eh = e.hash) == h) { //校验头结点的hash值与key的hash值是否相等
//若key与头结点key相同则返回头结点的val
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0) //头结点的hash<0则表示该桶已经转化成了红黑树
return (p = e.find(h, key)) != null ? p.val : null;
//若头结点的hash与key的hash不等且链表不是红黑树时遍历该链表
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
put流程
put方法中使用cas进行优化,当添加的节点为头结点时使用cas的方式,当需要在链表或红黑树中进行添加或更改时,才会用synchornized锁住该链表的头结点,而不是整个方法,大大提高了并发度
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
// f 是链表头节点
// fh 是链表头结点的 hash
// i 是链表在 table 中的下标
Node<K,V> f; int n, i, fh;
//若tab为null则创建table
if (tab == null || (n = tab.length) == 0)
tab = initTable(); //内部使用cas和双重检查机制保证创建table的并发安全
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { //若对应位置头结点为null则用cas添加头结点
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED) //若头结点的hash为MOVED,表示hash表正在扩容,则帮助一块扩容
tab = helpTransfer(tab, f);
else { //头结点不为null则锁住表头节点
V oldVal = null;
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) { // fh>0,遍历链表找到合适的位置添加或更新node
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) { //否则判断该桶是否转化成红黑树
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// 如果链表长度 >= 树化阈值(8), 进行链表转为红黑树
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null) //oldval不为null说明是更新操作而不是添加
return oldVal;
break;
}
}
}
//size+1
addCount(1L, binCount);
return null;
}
addCount方法
采用LongAddr的思想,多个CountCell来分摊并发压力,使用cas进行加法操作保证线程安全
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
//若cells不为null 或 对BaseCount进行cas累加失败
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
//若cells不为null且对当前线程对应的cell不为null时,对该cell进行cas累加
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
//对该cell累加失败则创建cell
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
//当s>=sizeCtl时,需要对其进行扩容
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
// newtable 已经创建了,帮忙扩容
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
//需要扩容,newtable还不存在
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
总结

三、JDK7-ConcurrentHashMap
它维护了一个 segment 数组,每个 segment 对应一把锁
- 优点:如果多个线程访问不同的 segment,实际是没有冲突的,这与 jdk8 中是类似的
- 缺点:Segments 数组默认大小为16,这个容量初始化指定后就不能改变了,并且不是懒惰初始化
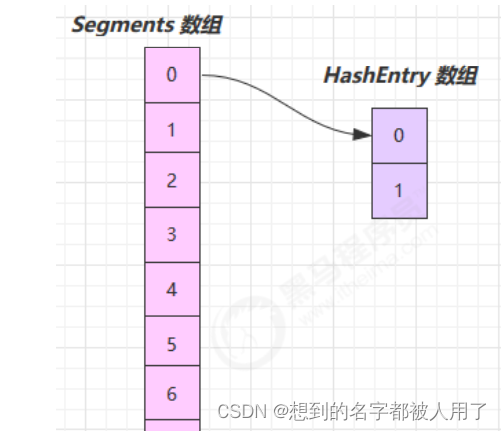
每个segment元素内部维护着一个HashTble,这些HashTable是懒加载的
put流程
jdk8中put内部使用synchornized是对元素所在链表的表头元素上锁,而JDK7中每个segment元素继承ReentrantLock,put时会对该segment进行上锁,而segment维护了一个HashTble,锁的粒度比jdk8中更大,并发度比jdk8的实现要低

segment.put


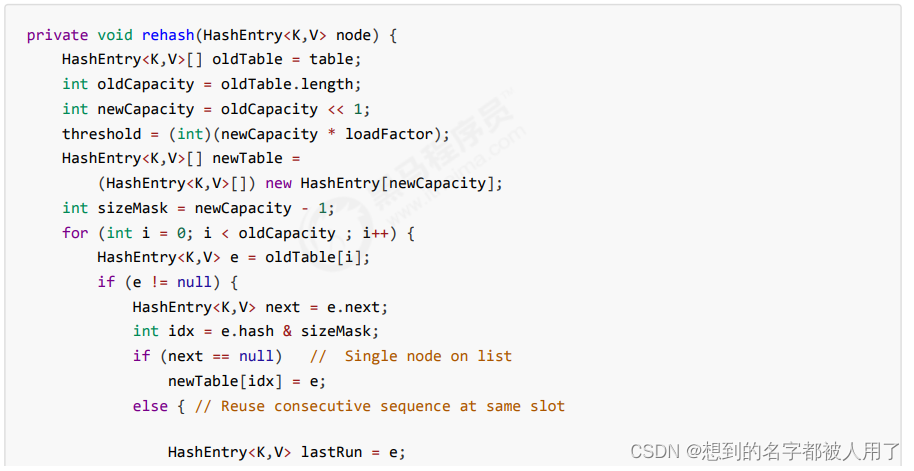
rehash 扩容流程
发生在 put 中,因为此时已经获得了锁,因此 rehash 时不需要考虑线程安全

get流程
get没有保证并发安全的措施,大概分为两个步骤:1. 通过key的hash值找到对应的segment。 2. 在segment中的hashtable中找到对应位置

size
JDK8中没有任何措施保证size的一致性,而jdk7中分别对每个segment进行上锁保证并发安全。









![[附源码]Python计算机毕业设计Django疫情背景下社区互助服务系统](https://img-blog.csdnimg.cn/449db978e87f48a89a01a2c2b26c2600.png)