目录
- 前言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- Python 环境
- OpenCV环境
- 模块实现
- 1. 视频读取及处理
- 2. 色素块识别与替换
- 3. 视频合成
- 4. 操作系统上的实现
- 系统测试
- 工程源代码下载
- 其它资料下载

前言
本项目利用 OpenCV 提供的轻量、高效的 C++类和 Python 接口,实现了将视频逐帧转换成字符画的功能。通过这个项目,我们可以按照原始格式将图像转换成字符画,并将其应用于视频字符化的场景。
我们使用 OpenCV 提供的功能,将视频文件逐帧读取为图像。然后,我们使用字符集合来代表不同灰度级别的像素值。通过计算每个像素的灰度值,并将其映射到相应的字符,我们可以将图像转换成字符画。
这个项目具有很高的应用价值和趣味性。字符画视频可以应用于艺术创作、视频编辑、社交媒体分享等领域。它可以为视频带来独特的风格和美感,同时也展示了字符处理和图像转换的技术魅力。无论是在个人创作还是商业应用中,视频字符化都可以为用户带来全新的视觉体验。
总体设计
本部分包括系统整体结构图和系统流程图。
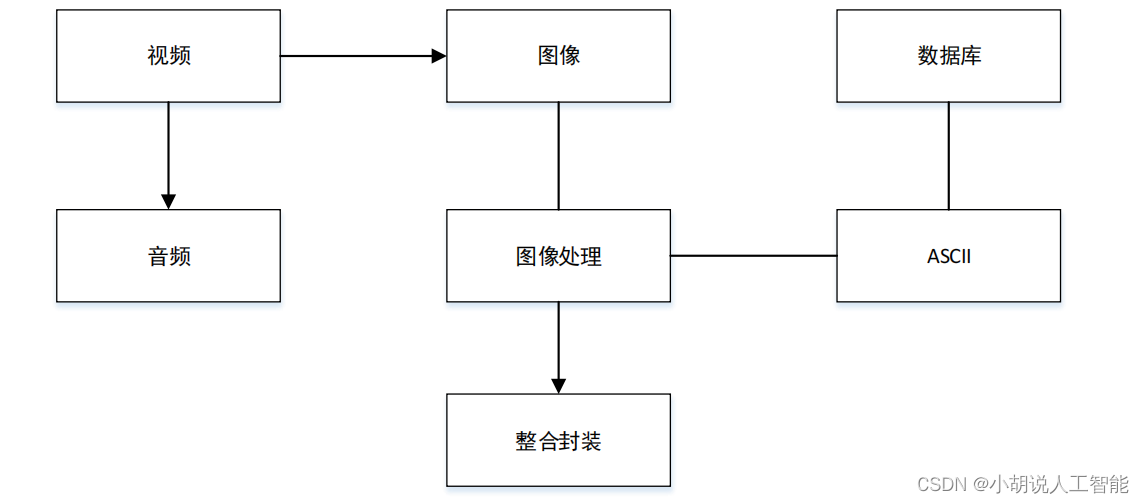
系统整体结构图
系统整体结构如图所示。
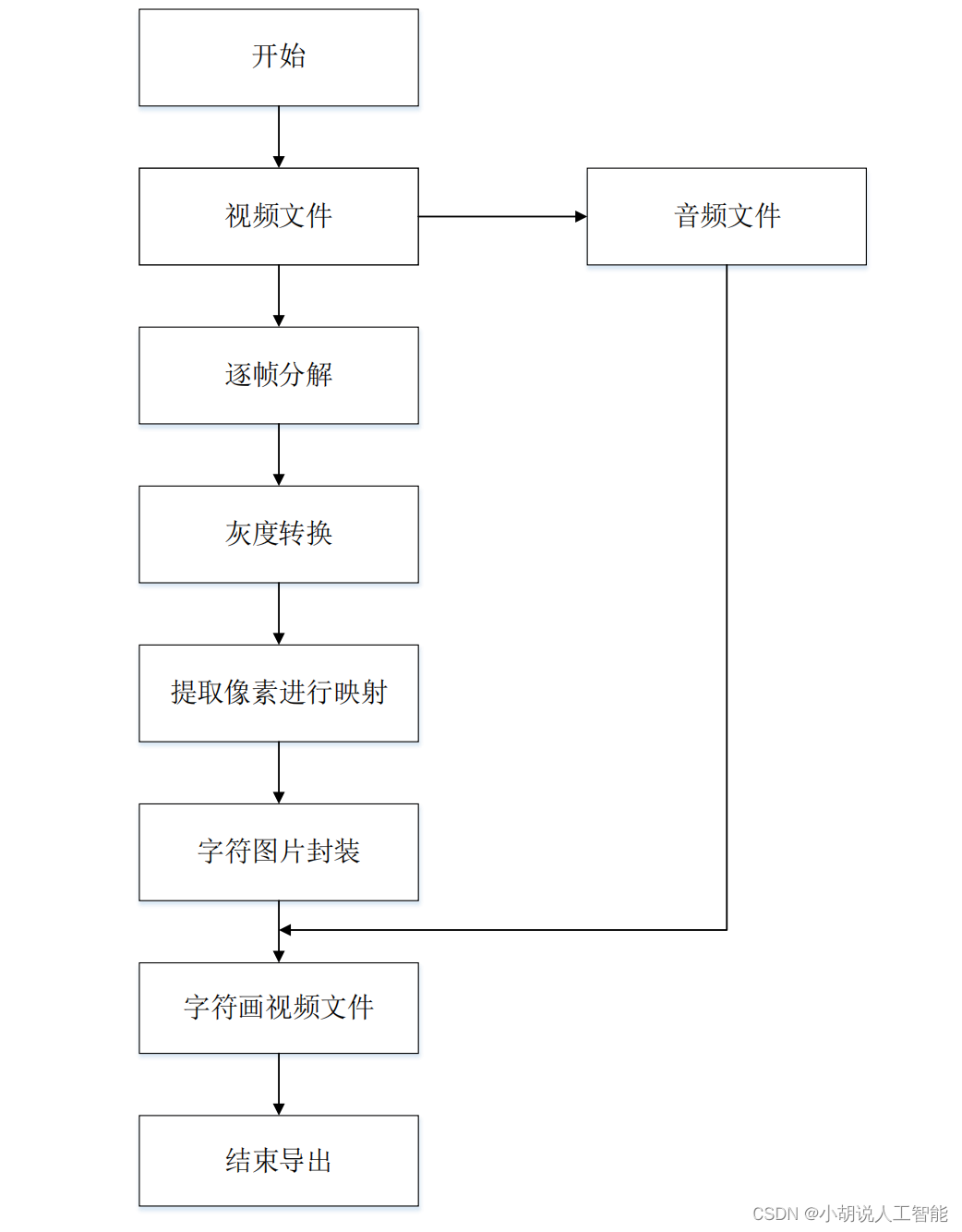
系统流程图
系统流程如图所示。
运行环境
本部分包括 Python 和 OpenCV 环境。
Python 环境
需要 Python 3.6 及以上配置,在 Windows 环境下载 Anaconda 完成 Python 所需的配置,
下载地址:https://www.anaconda.com/,也可以下载虚拟机在 Linux 环境下运行代码。
OpenCV环境
在 OpenCV 官方网站 https://opencv.org/下载最新且完整的源码以及大部分 release 版
本源码,链接:https://opencv.org/releases.htm。
也可以直接使用下面命令安装:
pip3 install -i https://mirror.aliyun.com/pypi/simple opencv-python==3.4.2.16
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv-contrib-python==3.4.2.16
模块实现
本项目包括 4 个模块:视频读取及处理、色素块识别与替换、视频合成、操作系统上的实现,下面分别给出各模块的功能介绍及相关代码。
1. 视频读取及处理
本部分主要由 OpenCV 的视频导入为主,在代码头部位置引入对应的模块。
import cv2
import os
show_heigth = 30
show_width = 80
#同时在python prompt中导入OpenCV的库文件
Pip3 install opencv-python
#导入完成后输入pip install进行模块的检查
>>> import cv2
>>> print( cv2.__version__ )
#模块完成后开始视频读取
vc = cv2.VideoCapture(r"C:\Users\Robert\Desktop\01.mp4")
if vc.isOpened():
rval , frame = vc.read()
else:
rval = False
2. 色素块识别与替换
本部分主要由公式计算、色素块提取及 ASCII 码替换组成。
1)公式计算
图像转字符画需要先将图像转为灰度图,公式:gray = 0.2126 * r + 0.7152 * g + 0.0722 * b,matplotlib 图像的色彩排序是 RGB(opencv 是 BGR),不用库函数,可以使用以下代码实现灰度转换。
for pixel_line in gray:
for pixel in pixel_line:
text += ascii_char[int(pixel / 256 * char_len )]
text += "\n"
outputList.append(text)
frame_count = frame_count + 1
2)色素块提取
确定公式后对色素块提取。
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) #使用opencv转化成灰度图
gray = cv2.resize(gray,(show_width,show_heigth))#resize灰度图
text = ""
#具体函数相关代码
template <typename Cvt>
class CvtColorLoop_Invoker : public ParallelLoopBody #定义色素块的类
{
typedef typename Cvt::channel_type _Tp;
public:
CvtColorLoop_Invoker(const Mat& _src, Mat& _dst, const Cvt& _cvt) :
ParallelLoopBody(), src(_src), dst(_dst), cvt(_cvt)
{
}
virtual void operator()(const Range& range) const #给予区块对应的值
{
const uchar* yS = src.ptr<uchar>(range.start);
uchar* yD = dst.ptr<uchar>(range.start);
for( int i = range.start; i < range.end; ++i, yS += src.step, yD += dst.step ) #对原色素块加以循环,实现边际算法
cvt((const _Tp*)yS, (_Tp*)yD, src.cols);
}
private: #将原函数代入总值内
const Mat& src;
Mat& dst;
const Cvt& cvt;
const CvtColorLoop_Invoker& operator= (const CvtColorLoop_Invoker&);
};
3)ASCII码替换
得到色素块对应值后进行相应的替换,输入ASCII码库。
ascii_char = list("$@B%8&WM#*oahkbdpqwmZO0QLCJUYXzcvunxrjft/\|()1{}[]?-_+~<>i!lI;:,\"^`'. ")
#在输入完成后进行替换
for pixel in pixel_line: #字符串拼接
text += ascii_char[int(pixel / 256 * char_len )]
text += "\n"
3. 视频合成
完成视频读取、处理、色素块识别与替换,将处理完成的图片进行逐帧拼接,方案如下:
1)使用 CMD 快速循环图片
使用循环函数实现图片的快速切换,将生成的 ASCII 码进行拼接,通过视觉暂留产生视频的表现形式。
frame_count = 0
outputList = [] #初始化输出列表
while rval: #循环读取视频帧
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) #使用OpenCV转化成灰度图
gray = cv2.resize(gray,(show_width,show_heigth))#resize灰度图
text = ""
for pixel_line in gray:
for pixel in pixel_line: #字符串拼接
text += ascii_char[int(pixel / 256 * char_len )]
text += "\n"
outputList.append(text)
frame_count = frame_count + 1
if frame_count % 100 == 0:
print("已处理" + str(frame_count) + "帧")
rval, frame = vc.read()
print("处理完毕")
for frame in outputList:
os.system("cls") #清屏
print(frame)
print()
print()
完成后进入CMD中运行并在Python prompt中显示。
CD C://users/Robert/Desktop/
Python 01.py
2)生成相应视频文件
得到 ASCII 码字符集后通过 OpenCV 自带图片视频转化工具实现视频的生成。
def imgs_to_chars(imgs, frames_count): #定义视频合成的帧
video_chars, i = [], 0
for img in imgs: #实现画面的切换
i += 1
video_chars.append(img_to_chars(img, i/frames_count))
return video_chars
""" 测试 imgs_to_chars
if __name__ == "__main__":
imgs = Video_to_imgs("BadApple.mp4", (64, 48)) #导入视频的存储位置
video_chars = imgs_to_chars(imgs)
assert len(video_chars) > 10
"""
def play_video(video_chars, frame_rate, frames_count): #定义视频的播放方案
import time
import curses
width,height = len(video_chars[0][0]), len(video_chars[0])#获取文件尺寸
stdscr = curses.initscr()
curses.start_color() #定义开始的色素块
try:
stdscr.resize(height, width * 2)
for pic_i in range(len(video_chars)):
for line_i in range(height): #打印当前帧
stdscr.addstr(line_i, 0, video_chars[pic_i][line_i], curses.COLOR_WHITE) #打印显示,并将字符调整为白色
stdscr.refresh()
time.sleep(1 / frame_rate)
finally:
curses.endwin()
print("播放完毕")
return
通过比较得出方法一的运行速度高于方法二,同时节省了模块的调用,所以使用第一种方案进行视频的获取。
4. 操作系统上的实现
本部分包括确定文件地址与格式要求。
1)确定文件地址
代码中明确了文件的对应地址。
vc = cv2.VideoCapture(r"C:\Users\Robert\Desktop\01.mp4")#加载一个视频
if vc.isOpened(): #判断是否正常打开
rval , frame = vc.read()
else:
rval = False
#在实际运用时只需要修改对应地址即可
def get_video_chars(video_path, size, seconds):
video_dump = get_file_name(video_path) + ".pickle" #实现视频的帧数循环
if has_file(".", video_dump):
print("正在读取")
video_chars, fps, frames_count = load(video_dump)
else:
print("正在加载,请稍等")
imgs, fps, frames_count = Video_to_imgs(video_path, size, seconds)
video_chars = imgs_to_chars(imgs, frames_count)
dump([video_chars, fps, frames_count], video_dump)
print("加载完成")
return video_chars, fps, frames_count
if __name__ == "__main__":
try:
video_path = sys.argv[1]
except:
video_path = ""
if video_path == "":
video_path = input("输入视频地址:")
main(video_path)
exit()
2)格式要求
根据 OpenCV 的要求得出相应的格式。推荐 MP4 与 MKV,分辨率可以根据窗体进行自动调节。文件大小并不影响代码的运行速度,鉴于是逐帧提取,时长由影视文件长度决定。
MPEG-4 包含 MPEG-1 及 MPEG-2 的绝大部分功能及其他格式的长处,加入并扩充对虚拟现实模型语言(VRML、VirtualReality Modeling Language)的支持,面向对象的合成档案(包括音效、视讯及 VRML 对象)、数字版权管理(DRM)及其他互动功能。
Matroska 多媒体容器(Multimedia Container)是开放标准容器和文件格式、多媒体封装格式,能够在一个文件中容纳无限数量的视频、音频、图片或字幕轨道。所以不是压缩格式,而是 Matroska 定义的一种多媒体容器文件。其目标是作为一种统一格式保存常见的电影、电视节目等多媒体内容。
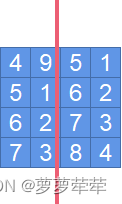
系统测试
如图所示,通过对代码 ASCII 转化,识别出的图片可以辨别出原图。鉴于该代码主要是针对视频运行,更多的是对视频效果的参考。

工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。