目录
1、训练、验证、测试集
2、偏差、方差
3、正则化
4、dropoout正则化
5、其他正则化方法
6、归一化输入
7、梯度消失和梯度爆炸
8、梯度的数值逼近
9、梯度检验
1、训练、验证、测试集
(1)、早期机器学习领域普遍认可的最好的实践方法:机器学习发展的小数据量时代,常见做法
是将所有数据三七分,就是人们常说的 70%验证集,30%测试集,如果没有明确设置验证集也可
以按照 60%训练,20%验证和 20%测试集来划分
2、偏差、方差
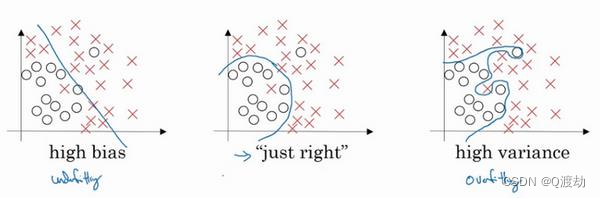
(1)、欠拟合(高偏差)指机器学习模型在训练数据集上的表现较差,无法很好地拟合数据。这
通常是因为模型的复杂度过低,无法捕捉到数据中的关键特征,或者在训练过程中没有足够的学习
时间。在欠拟合的情况下,模型往往不能很好地预测新的数据,因为它不能很好地适应训练数据集
中的变化和噪音。欠拟合问题可以通过增加模型的复杂度、增加训练数据的数量或增加训练时间来
解决。
3、正则化
(1)、L1正则化

(2)、L2正则化:2𝑚 乘以𝑤范数的平方,𝑤欧几里德范数的平方等于𝑤𝑗(𝑗 值从 1 到𝑛𝑥)平方的
和,也可 表示为𝑤𝑇𝑤,也就是向量参数𝑤 的欧几里德范数(2 范数)的平方,此方法称为𝐿2正则
化。 因为这里用了欧几里德法线,被称为向量参数𝑤的𝐿2范数
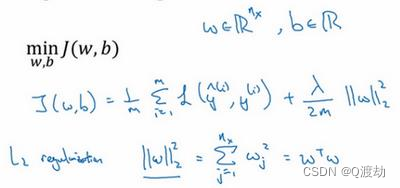
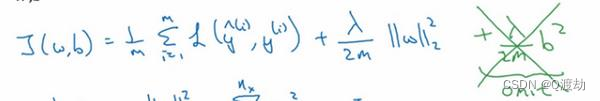
(3)、在神经网络中实现L2正则化
神经网络含有一个成本函数,该函数包含𝑊[1],𝑏 [1]到𝑊[𝑙],𝑏 [𝑙]所有参数,字母𝐿是神经 网络所含的层数,因此成本函数等于𝑚个训练样本损失函数的总和乘以 1 /𝑚,正则项为![]() ,
,
称||𝑊[𝑙] || 2为范数平方,这个矩阵范数||𝑊[𝑙] || 2(即平方范数),被定义 为矩阵中所有元素的平
方求和
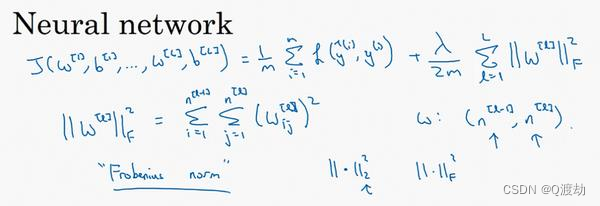

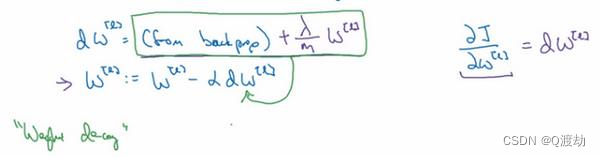
(4)、该如何使用该范数实现梯度下降呢?

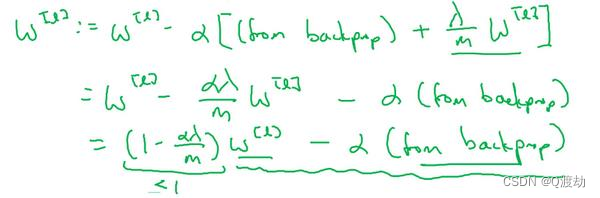
(5)、为什么正则化有利于预防过拟合呢?为什么它可以减少方差问题?
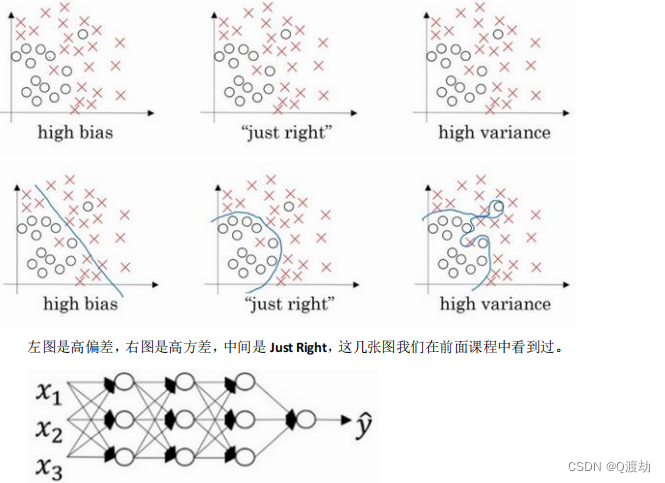
- 高方差是指模型在训练集上表现良好,但在测试集上表现较差的情况,这通常表明模型过于复杂,过度拟合了训练数据。 正则化是一种广泛使用的减小过拟合的方法,它通过在模型损失函数中添加额外的约束条件来限制模型的复杂度。这些约束条件通常以惩罚项的形式出现,例如L1正则化或L2正则化,它们会使得模型参数的值偏向于较小的值。 正则化有利于预防过拟合,因为它限制了模型的复杂度,使得模型更加简单,更易于泛化到未见过的数据上。正则化对于减少方差问题也很有效,因为它有助于减小模型参数的值,从而减少了模型在训练数据中的波动,使得模型更加稳定。正则化可以被视为一种牺牲一定的训练集精度以换取更好的泛化能力的方式。
- 直观上理解就是如果正则化𝜆设置得足够大,权重矩阵𝑊被设置为接近于 0 的值,直观 理解就是把多隐藏单元的权重设为 0,于是基本上消除了这些隐藏单元的许多影响。如果是 这种情况,这个被大大简化了的神经网络会变成一个很小的网络,小到如同一个逻辑回归单 元,可是深度却很大,它会使这个网络从过度拟合的状态更接近左图的高偏差状态。
-
但是 𝜆 会存在一个中间值,于是会有一个接近 “ Just Right ” 的中间状态。直观理解就是 𝜆 增加到足够大, 𝑊 会接近于 0 ,实际上是不会发生这种情况的,我们尝试消除或至少减少许多隐藏单元的影响,最终这个网络会变得更简单,这个神经网络越来越接近逻辑回归,我们直觉上认为大量隐藏单元被完全消除了,其实不然,实际上是该神经网络的所有隐藏单元依然存在,但是它们的影响变得更小了。神经网络变得更简单了,貌似这样更不容易发生过拟合,因此我不确定这个直觉经验是否有用,不过在编程中执行正则化时,你实际看到一些方差减少的结果
4、dropoout正则化
- Dropout正则化是一种常用的神经网络正则化方法,它可以在训练过程中随机地将一些神经元的输出置为0,以防止过度拟合。具体地,Dropout在每次迭代中以一定的概率随机丢弃一些神经元,这样在训练过程中,每个神经元都有可能被丢弃,从而强制网络去学习多个独立的子模型。在测试过程中,所有的神经元都会被保留,但是每个神经元的输出会被乘以一个训练中的缩放因子,以保持总体输出的期望值不变。
- Dropout正则化可以有效地降低神经网络的过拟合程度,因为它迫使网络去学习多个独立的子模型,从而增加了网络的鲁棒性和泛化能力。此外,Dropout还可以使得网络的训练更加高效,因为它可以降低神经元之间的耦合程度,从而减少了对于任何一个神经元的梯度更新的依赖。
- 需要注意的是,Dropout正则化通常需要对网络超参数进行调节,例如丢弃率、缩放因子等。通常建议在应用Dropout时,根据实际情况进行超参数的调整,以获得最佳的效果。
5、其他正则化方法
6、归一化输入
(1)、提高模型的收敛速度和稳定性。当输入数据的值域差异较大时,需要更多的迭代次数才能使模型收敛,而且模型的收敛速度也很慢。归一化可以缩小输入数据的值域,使得模型更容易收敛。
(2)、避免特征权重的影响。当输入特征的值域差异很大时,某些特征可能会被赋予过高的权重,从而影响模型的泛化性能。归一化可以消除这种影响,使得所有特征都处于同一数量级。
(3)、提高模型的泛化能力。当输入数据的值域差异很大时,模型在训练集上可能会出现很高的拟合效果,但在测试集上的表现很差。归一化可以消除这种差异,提高模型的泛化能力。
7、梯度消失和梯度爆炸
(1)、梯度消失和梯度爆炸都是指在神经网络训练中,梯度值出现的问题
(2)、梯度消失是指在神经网络的反向传播中,梯度值逐渐变小,直到变得非常小,甚至接近于
零。这种情况通常发生在深层网络中,因为每次反向传播都需要求解多个激活函数的导数,而激活
函数的导数通常在接近于0的区域取值,因此在多个层级上累积,就会导致梯度值逐渐变小,最终
无法对神经网络的权重进行有效的更新,从而影响模型的性能。
(3)、梯度爆炸是指在神经网络的反向传播中,梯度值逐渐变大,直至变得非常大,甚至超过了
计算机能够处理的范围,导致算法不收敛或者无法更新网络权重。这种情况通常发生在网络中存在
大量的权重共享或者层数较多时,因为这样会导致梯度值的指数级增长,使得网络无法进行有效的训练。
(4)、为了避免梯度消失和梯度爆炸的问题,可以使用一些技巧来稳定神经网络的训练,例如:
8、梯度的数值逼近
9、梯度检验
(1)、梯度检验是一种用于验证计算出的梯度是否正确的方法。它通过比较数值逼近梯度和解析
梯度之间的差异来判断计算出的梯度是否准确。
(2)、梯度检验的优点是可以帮助我们在实现梯度计算时发现错误,避免因为梯度计算错误而导
致模型训练失败。缺点是梯度检验需要更多的计算资源,而且由于数值逼近梯度和解析梯度的计算
方法不同,两者之间的差异可能会导致计算误差。