6月份是火热的夏天,各种火热的 AI 产品也在密集的更新,天越热,大家是干得热火朝天,卷出了新高度。
前有现在大火的 ChatGPT,ChatGPT 更新:大杀器!函数调用示范,ChatGPT 3.5/4 双双升级:更长,更便宜,更开放,更可控
接着有画图神器 Midjourney,制作看大片一样的推拉镜头效果,刚一个月AI绘图神器 Midjourney 又又更新了
现在有咱们中国自己的开源大模型 ChatGLM-6B 的官宣了更新内容:

ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 引入了如下新特性:
更强大的性能:基于 ChatGLM 初代模型的开发经验,我们全面升级了 ChatGLM2-6B 的基座模型。ChatGLM2-6B 使用了 GLM 的混合目标函数,经过了 1.4T 中英标识符的预训练与人类偏好对齐训练,评测结果显示,相比于初代模型,ChatGLM2-6B 在 MMLU(+23%)、CEval(+33%)、GSM8K(+571%) 、BBH(+60%)等数据集上的性能取得了大幅度的提升,在同尺寸开源模型中具有较强的竞争力。
更长的上下文:基于 FlashAttention 技术,我们将基座模型的上下文长度(Context Length)由 ChatGLM-6B 的 2K 扩展到了 32K,并在对话阶段使用 8K 的上下文长度训练,允许更多轮次的对话。但当前版本的 ChatGLM2-6B 对单轮超长文档的理解能力有限,我们会在后续迭代升级中着重进行优化。
更高效的推理:基于 Multi-Query Attention 技术,ChatGLM2-6B 有更高效的推理速度和更低的显存占用:在官方的模型实现下,推理速度相比初代提升了 42%,INT4 量化下,6G 显存支持的对话长度由 1K 提升到了 8K。
更开放的协议:ChatGLM2-6B 权重对学术研究完全开放,在获得官方的书面许可后,亦允许商业使用。如果您发现我们的开源模型对您的业务有用,我们欢迎您对下一代模型 ChatGLM3 研发的捐赠。
算力是制约大模型的一个重要硬件资源,更好的性能说明可以用更少的钱办更多的事。
这次的更新,一口气扩展到了32K。ChatGPT 更新之后才从4K扩展到了16K,咱们一步到位干到32K,我觉得绝大部分场景够用了。
更高效的推理,说明人工智能思考的速度更快了。大模型本质上就是在计算一个词后面跟着另外一个词的概率,算得快,更高效的推理,代表了更快的响应速度,用户体验更好了。
这么好的大模型,完全允许我们拿过来商用,实在是良心企业,造福一方之举。
总之一句话:咱们的国产大模型变得又快又好又开放。
顺便贴两个网页版本和命令行版本运行的界面,方便朋友们了解。
命令行:
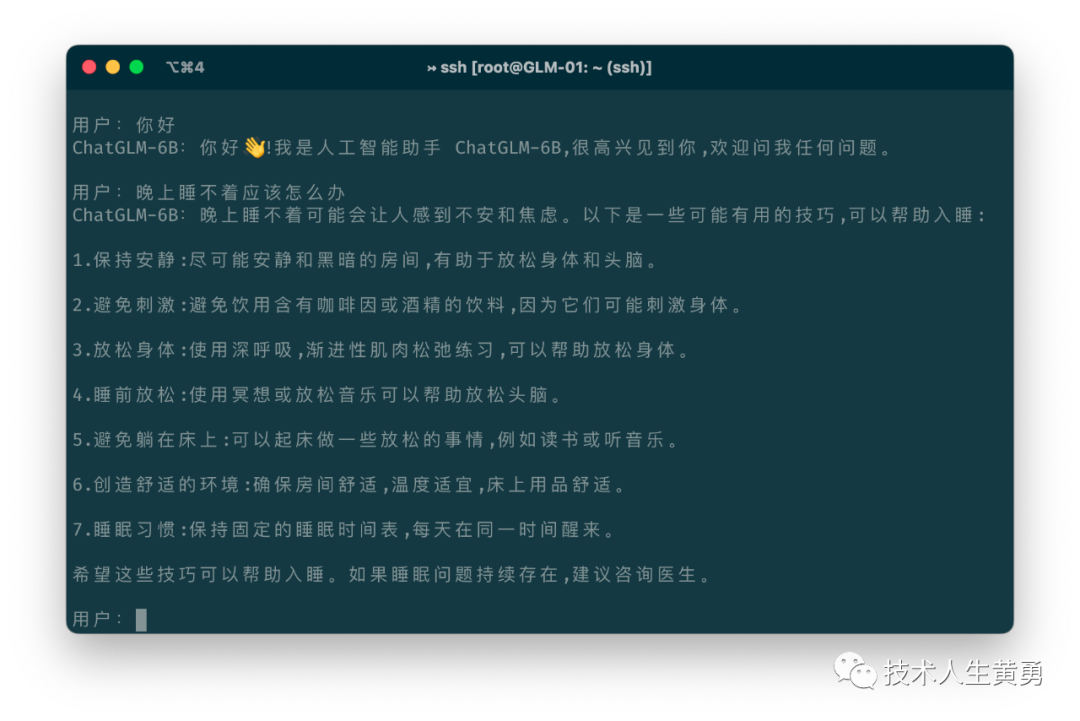
网页版:
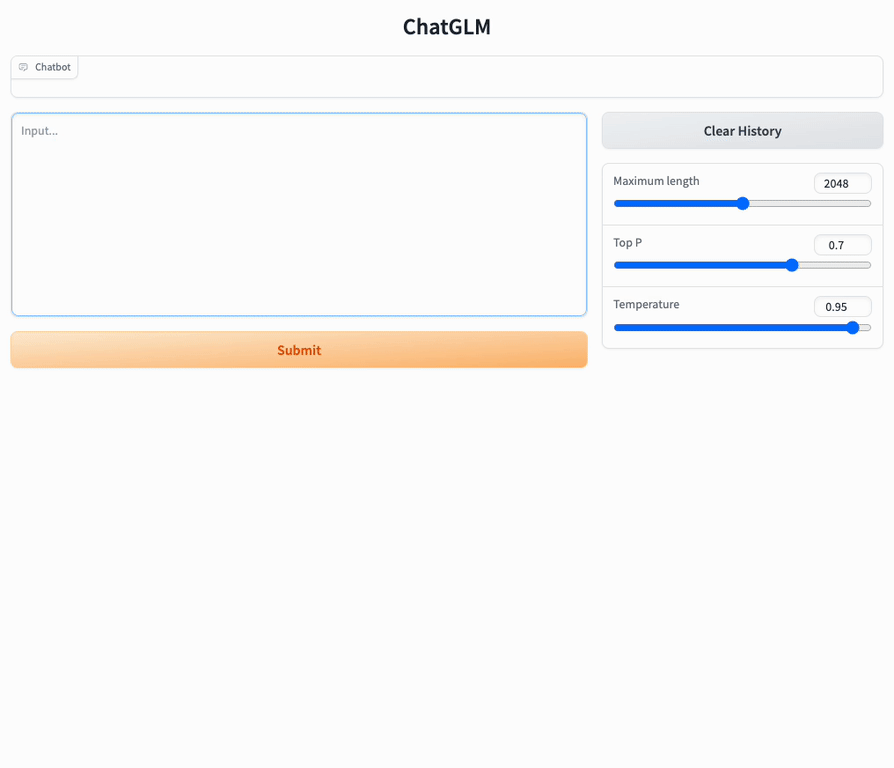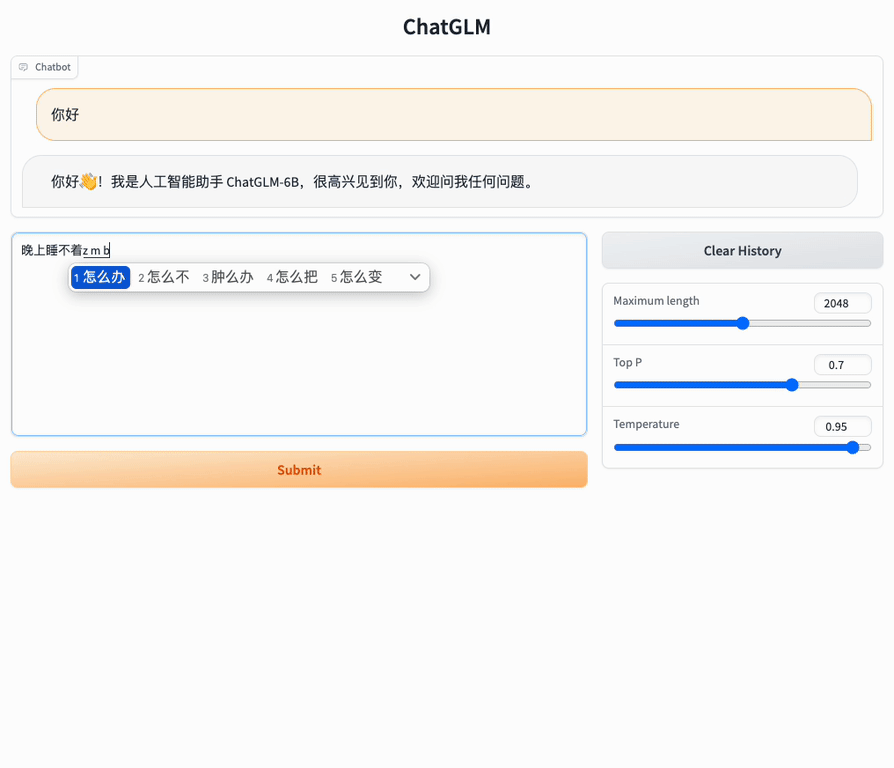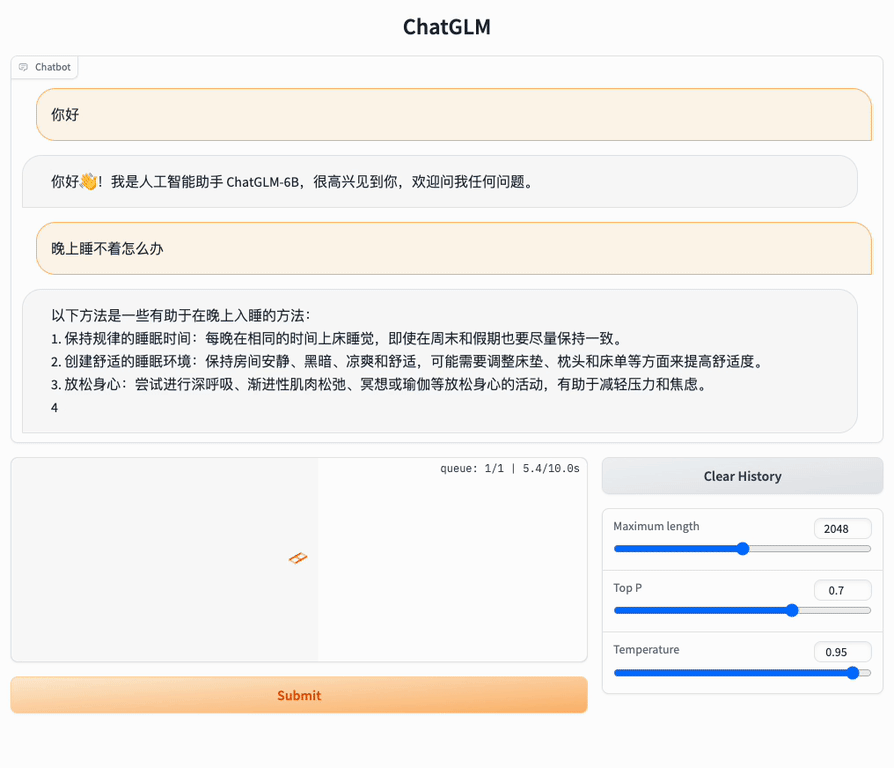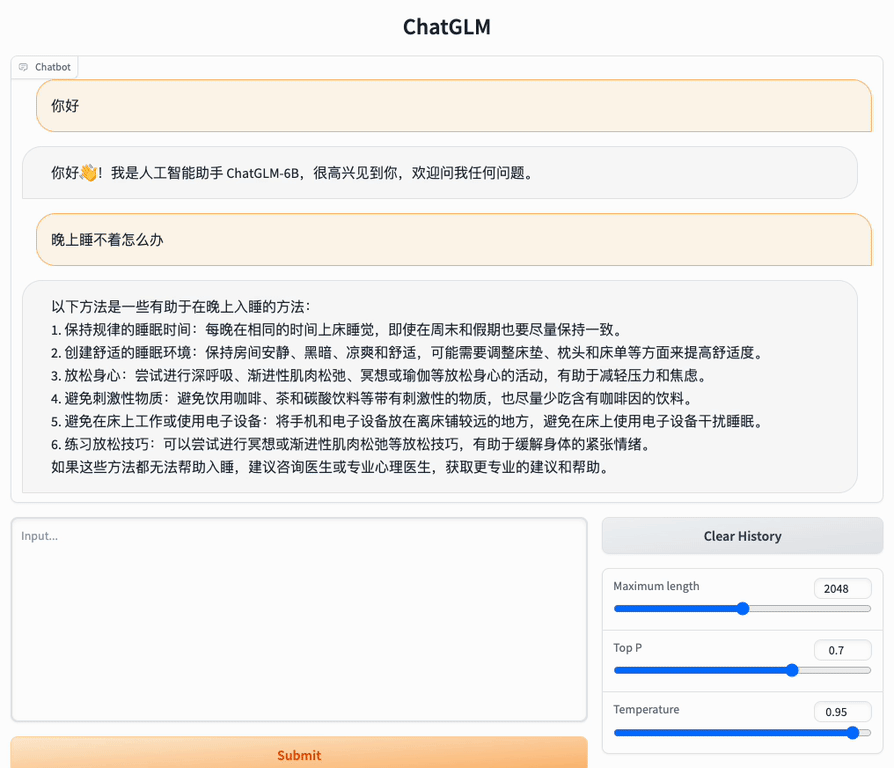
我准备按官方的说明手册,搭一个网页的版本,届时请朋友们试用。
对更多细节感兴趣的朋友,可以去官网申请使用,也可以去 Github 上下载源码搭建一个自己的大模型试试。
官网地址:https://chatglm.cn/
Github:
https://github.com/THUDM/ChatGLM2-6B
(临时插播:正要发出文章之前,收到通过申请试用的短信,官方效率挺高!试用后,再给朋友们写一些介绍)
关注我,免费领取九大类别,数百篇 AI 学习资源。
一起学习 ChatGPT,掌握 AI 工具,不被时代淘汰。
关于注册 ChatGPT,体验 Midjourney,搭建 Stable Diffusion,私有知识库部署等等问题和建议都可以在公众号上联系我。