论文地址:微型循环U-Net实时降噪和去混响
论文代码:
- https://github.com/YangangCao/TRUNet
- https://github.com/amirpashamobinitehrani/tinyrecurrentunet
引用格式:Choi H S, Park S, Lee J H, et al. Real-Time Denoising and Dereverberation wtih Tiny Recurrent U-Net[C]//ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021: 5789-5793.
摘要
现代基于深度学习的模型在语音增强任务中表现出了显著的改进。然而,对于现实世界的应用程序来说,最先进的模型的参数数量往往过于庞大,无法部署到设备上。为此,我们提出了微型循环U-Net(Tiny Recurrent U-Net,TRU-Net),这是一个轻量级的在线推理模型,与当前最先进的模型性能相匹配。TRU-Net的量化版本大小为362k字节,小到可以部署在边缘设备上。此外,我们将小尺寸模型与一种新的掩码方法(phase-aware β-sigmoid mask)相结合,它可以同时去噪和去everberation。客观和主观评估的结果表明,我们的模型可以在基准数据集上使用更少的参数达到与当前最先进的模型竞争的性能。
关键词:实时语音增强,轻量级网络,去噪,去混响
1 引言
在本文中,我们专注于开发一个基于深度学习的语音增强模型,该模型适用于现实世界的应用,满足以下条件:
1、一个小而快速的模型,可以尽可能减少单帧实时因子(RTF),同时保持与最先进的深度学习网络的竞争性能,
2、一个可以同时进行去噪和解噪的模型。
为了解决第一个问题,我们的目标是改进一种流行的神经结构(U-Net[1]),它已经证明在语音增强任务中具有卓越的性能[2,3,4]。以往使用U-Net进行源分离的方法不仅在频率维度上应用卷积,而且在时间维度上也应用卷积。U-Net的这种非因果性质增加了计算复杂性,因为需要对过去和未来帧进行额外的计算来推断当前的框架。因此,它不适用于需要实时处理当前帧的在线推理场景。此外,时间维度使得网络计算效率低下,因为在U-Net的编码和解码路径中相邻帧之间都存在冗余计算。为了解决这一问题,我们提出了一种适用于在线语音增强的神经网络结构——微型循环U-Net (Tiny Recurrent U-Net, TRU-Net)。该体系结构旨在实现频率维度和时间维度计算的有效解耦,从而使网络足够快,能够实时处理单个帧。该网络的参数数量仅为0.38M,不仅可以部署在笔记本电脑上,还可以部署在移动设备上,甚至可以部署在结合量化技术[5]的嵌入式设备上。TRU-Net的详细信息在第2节中有更多的描述。
接下来,为了同时抑制噪声和混响,我们提出了一种相位感知 B-sigmoid 掩码 (PHM)。 所提出的 PHM 受到 [6] 的启发,其中作者建议通过从三角函数的角度重用估计的幅度掩码值来估计相位。 PHM 与 [6] 中的方法的主要区别在于 PHM 旨在尊重混合、目标源和剩余部分之间的三角关系,因此估计的目标源和剩余部分的总和始终相等 到混合物。 我们通过同时生成两个不同的 PHM 将该属性扩展到四边形,这使我们能够有效地处理去噪和去混响。 我们将在第 3 节中更详细地讨论 PHM。
2 Tiny循环U-Net
2.1 PCEN特征作为输入
语谱图可能是许多语音增强模型中最流行的输入特性。每通道能量归一化(PCEN)[7]结合了动态范围压缩和自动增益控制,在应用于频谱图[8]时降低了前景响度的方差并抑制了背景噪声。PCEN也适用于在线推理场景,因为它包括一个时间积分步骤,它本质上是一个一阶无限脉冲响应滤波器,仅依赖于前一个输入帧。在这项工作中,我们采用可训练版本的PCEN。
2.2 网络结构
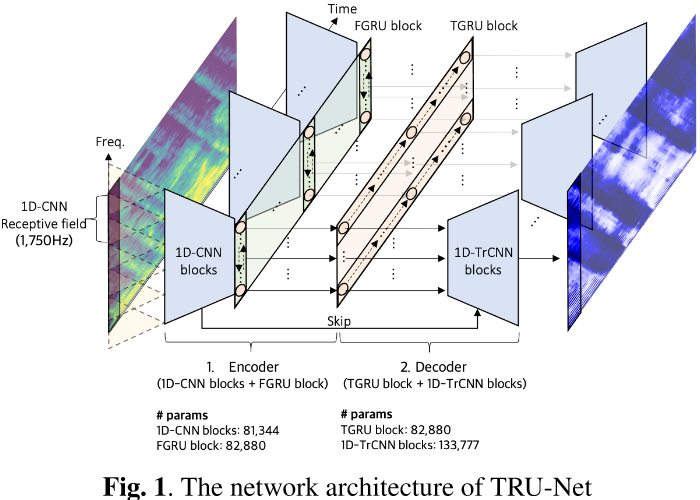
TRU-Net 基于 U-Net 架构,只在频率维度上卷积,在时间维度上不卷积。因此,它可以被认为是一个频率轴的U-Net,瓶颈层是一维卷积神经网络(cnn)和循环神经网络。编码器由一维卷积神经网络 (1D-CNN) 块和频率维度门控循环单元 (FGRU) 块组成。每个 1D-CNN 块都是类似于 [9] 的点卷积和深度卷积(就是深度可分离卷积),除了第一层使用标准卷积操作而没有前面的pointwise convolution。为了节省网络大小,我们使用了六个 1D-CNN 块,它们使用跨步卷积将频率维度大小从 256 下采样到 16。这会导致可能对网络性能有害的小感受野 (1,750Hz)。为了增加感受野,我们沿频率维度使用双向 GRU 层 [10],而不是堆叠更多的 1D-CNN 块。也就是说,来自 1D-CNN 块的 16 个向量序列被传递到双向 GRU 以增加感受野并沿频率维度共享信息(译者:双向GRU可以增加感受野?头一次听,表述有问题)。我们将此频率维度双向 GRU 层称为 FGRU 层。在 FGRU 层之后使用pointwise convolution、BN 和 ReLU,组成一个 FGRU 块。我们为每个前向和后向 FGRU 单元使用了 64 个hidden size。
解码器由时间维度门控循环单元 (TGRU) 块和一维转置卷积神经网络 (1D-TrCNN) 块组成。编码器的输出被传递到单向 GRU 层以沿时间维度聚合信息。我们称这个 GRU 层为 TGRU 层。一个pointwise convolution、BN 和 ReLU 在 TGRU 层之后,组成一个 TGRU 块。我们为 TGRU 单元使用了 128 个隐藏维度。最后,使用 1D-TrCNN 块将 TGRU 块的输出上采样到原始频谱图大小。 1D-TrCNN 块接受两个输入(1. 前一层输出,2. 来自同一层次结构的编码器的跳跃连接),并按如下方式对它们进行上采样。首先,使用pointwise convolution将两个输入连接起来并投影到更小的通道大小(192 -> 64)。然后,使用一维转置卷积对压缩信息进行上采样。与通常的 U-Net 实现相比,此过程节省了参数的数量和计算量,其中两个输入立即连接并使用转置卷积操作进行上采样。请注意,我们没有对 1D-TrCNN 块使用深度卷积,因为我们根据经验观察到它在解码阶段使用时会显着降低性能。
编码器和解码器中使用的每个卷积操作后面都是 BN 和 ReLU。 我们将卷积配置表示如下,l-th: (k, s, c) ,其中 l, k, s, c 分别表示层索引、内核大小、步幅和输出通道。 编码器和解码器的详细配置如下,Encoder Config= f1-th: (5,2,64), 2-th: (3,1,128), 3-th: (5,2,128), 4-th: (3,1,128), 5-th: (5,2,128), 6-th: (3,2,128)}, Decoder Config = f1-th: (3,2,64), 2-th: (5,2, 64), 3-th: (3,1,64), 4-th: (5,2,64), 5-th: (3,1,64), 6-th: (5,2,10) G。 请注意,pointwise convolution操作共享相同的输出通道配置,除了 k 和 s 均为 1。TRU-Net 概述以及用于 1D-CNN 块、FGRU 块、TGRU 块和 1DTrCNN 块的参数数量 如图 1 所示。
3 单级去噪和去混响
带混响和噪声的信号$x$通常被建模为加性噪声$y^{(n)}$和混响源$\tilde{y}$的和,其中$\tilde{y}$是房间脉冲响应(RIR) $h$与$y$的卷积结果,如下所示:
$$公式1:x=\tilde{y}+y^{(n)}=h \circledast y+y^{(n)}$$
更具体地说,我们可以把$h$分解成两部分。第一,直接路径部分$h^{(d)}$,其中不包括反射路径,第二,反射路径$h(r)$,如下所示:
$$公式2:x=h^{(d)} \circledast y+h^{(r)} \circledast y+y^{(n)}=y^{(d)}+y^{(r)}+y^{(n)}$$
式中,$y(d)$和$y(r)$分别表示直接路径源和混响。在这个设置中,我们的目标是将x分成三个元素$y^{(d)}, y^{(r)}和y^{(n)}$。短时傅里叶变换(STFT)计算得到的每个对应的时间频率表示记为$X_{t,f}, Y_{t,f}^{(d)}, Y_{t,f}^{(r)}, Y_{t,f}^{(n)}$,估计值用$\hat{·}$表示。
3.1 相位感知$\beta$-sigmoid mask
所提出的相位感知$\beta$-sigmoid掩码(PHM)是一种复数掩码,能够系统地将估计的复数值的和,恰好等于混合值,$X_{t,f}=Y_{t,f}^{(k)}+Y_{t,f}^{(-k)}$。PHM 将 STFT 域中的混合$X_{t,f}$以一对余(one vs rest)的方法分成两部分,即信号$Y_{t,f}^{(k)}$和其余信号的和$Y_{t,f}^{(-k)}=X_{t,f}-Y_{t,f}^{(k)}$,其中索引$k$可以是我们设置中的直接路径源 (d)、混响 (r) 和噪声 (n) 之一,$k \in {d,r,n}$。 复数掩码$M_{t,f}^{(k)}\in C$估计感兴趣源$k$的幅度和相位值。
计算 PHM 需要两个步骤。首先,网络用sigmoid函数$\sigma ^{(k)}(z_{t,f})$乘以系数$\beta_{t,f}$ 输出两个掩码$|M_{t,f}^{(k)}|$和$|M_{t,f}^{(-k)}|$的幅度部分,$|M_{t,f}^{(k)}|=\beta_{t,f}·\sigma^{(k)}(z_{t,f})=\beta_{t,f}·(1+e^{-(z_{t,f}^{(k)}-z_{t,f}^{(-k)})})^{-1}$,其中$z_{t,f}^{(k)}$是神经网络函数$\psi^{(k)}(\phi)$最后一层的输出,$\phi$是最后一层之前的网络层组成的函数。$M_{t,f}^{(k)}$用作估计源$k$的幅度掩码,其值范围从0到$\beta_{t,f}$。$\beta_{t,f}$的作用是设计一个接近最优值且幅度范围灵活的掩码,以便与常用的 sigmoid 掩码不同,值没有介于 0 和 1 之间。另外,因为复数掩码$|M_{t,f}^{(k)}|$和$|M_{t,f}^{(-k)}|$之和必须组成一个三角形,所以设计一个满足三角不等式的掩码是合理的,即$|M_{t,f}^{(k)}|+|M_{t,f}^{(-k)}|\geq 1$且$|M_{t,f}^{(k)}|-|M_{t,f}^{(-k)}|\leq 1$。为了解决第一个不等式,我们设计网络从最后一层输出$\beta_{t,f}$,具有如下的 softplus 激活函数,$\beta_{t,f}=1+softplus((\psi_{\beta}(\phi ))_{t,f})$,其中表示要输出的附加网络层$\beta_{t,f}$。第二个不等式可以通过将$\beta_{t,f}$的上界裁剪为$1/|\sigma ^{(k)}(z_{t,f})-\sigma ^{(-k)}(z_{t,f})|$来满足。
一旦确定了幅度掩码,我们就可以构造一个相位掩码$e^{j\theta_{t,f}^{(k)}}$。 给定三角形三个边的幅值,我们可以计算混合物和源$k$之间的绝对相位差$\theta_{t,f}^{(k)}$的余弦值,$cos(\triangle \theta _{t,f}^{(k)})=(1+|M_{t,f}^{(k)}|^2-|M_{t,f}^{(-k)}|^2)/(2|M_{t,f}^{(k)}|)$。 然后,为相位掩码估计用于相位校正的旋转方向$\xi_{t,f}\in \{1,-1\}$(顺时针或逆时针)如下,$e^{j\theta_{t,f}^{(k)}}=cos(\triangle \theta _{t,f}^{(k)})+j\xi_{t,f}sin(\triangle \theta _{t,f}^{(k)})$。 使用两类直通 Gumbel-softmax 估计器来估计$\xi_{t,f}$[11]。$M_{t,f}^{(k)}$定义如下,$M_{t,f}^{k}=|M_{t,f}^{(k)}|·e^{j\theta _{t,f}^{(k)}}$。 最后,$M_{t,f}^{(k)}$乘以$X_{t,f}$来估计源$k$如下,$\hat{Y}_{t,f}^{k}=M_{t,f}^{(k)}·X_{t,f}$。
3.2 从一个四边形的角度掩码
因为我们希望同时提取直接源和混响源,所以分别使用两对PHM。第一对掩码,$M_{t,f}^{(d)}$和$M_{t,f}^{(-d)}$,分别将混合物分离为直接源和其余组分。第二对掩码,$M_{t,f}^{(n)}$和$M_{t,f}^{(-n)}$,将混合物分离为噪声和混响源。由于PHM保证了混合组分和分离组分在复杂STFT域中构造一个三角形,分离结果可以从一个四边形的角度来看,如图2所示。在这种情况下,由于三个边和两个边角已经由两对phm确定,所以四边形的第四个边$M_{t,f}^{(r)}$是唯一确定的。
3.3 多尺度目标
近年来,多尺度谱图(MSS)损耗函数已成功应用于一些音频合成研究中[12,13]。我们不仅将这种多尺度方案纳入了频谱域,而且也纳入了类似于[14]的波形域。
学习最大化余弦相似度可以被视为最大化信号失真比(SDR)[2]。估计信号$\hat{y}^{(k)}\in R^N$与ground truth信号$y^{(k)}\in R^N$之间的余弦相似损失C定义为:$C(y^{(k)},\hat{y}^{(k)})=-\frac{<y^{(k)},\hat{y}^{(k)}>}{||y^{(k)}||·||\hat{y}^{(k)}||}$,其中$N$表示信号的时间维数,$k$表示信号类型($k\in \{d,r,n\}$)。考虑切片信号$y_{\frac{N}{M}(i-1):\frac{N}{M}i}^{(k)}$,其中$i$表示段索引,$M$表示段数。切信号,正常化的准则,每个切段被认为是一个单元计算$C$。因此,我们假设是很重要的选择一个合适的区段长度单位$\frac{N}{M}$时计算$C$。在我们的例子中,我们使用多个设置段长度的$g_i=\frac{N}{M_j}$如下:
$$公式3:\mathcal{L}_{w a v}^{(k)}=\sum_{j} \frac{1}{M_{j}} \sum_{i=1}^{M_{j}} C\left(\boldsymbol{y}_{\left[g_{j}(i-1): g_{j} i\right]}^{(k)}, \hat{\boldsymbol{y}}_{\left[g_{j}(i-1): g_{j} i\right]}^{(k)}\right)$$
其中$M_j$为切片段数。在我们的例子中,$g_i$的集合选择如下:$g_i\in \{4064, 2032, 1016, 508\}$。
接下来,谱域上的多尺度损耗定义如下
$$公式4:\mathcal{L}_{s p e c}^{(k)}=\sum_{i}\left\|\left|\operatorname{STFT}_{i}\left(\boldsymbol{y}^{(k)}\right)\right|^{0.3}-\left|\operatorname{STFT}_{i}\left(\hat{\boldsymbol{y}}^{(k)}\right)^{0.3}\right|\right\|^{2}$$
式中$i$为$STFT_i$的FFT大小。与原始MSS损失的唯一区别是,我们将log变换替换为幂律压缩,因为在之前的语音增强研究中已经成功地使用了幂律压缩[15,16]。我们使用STFT的FFT大小(1024,512,256),重叠率为75%。最终损耗函数的定义是将所有分量相加,如下所示:$L_{final}=\sum_{k\in \{d,r,n\}}L_{wav}^{(k)}+L_{spec}^{(k)}$。
4 实验
4.1 复现细节
由于我们的目标是同时进行去噪和去混响,所以我们使用热室声学[20]来模拟一个随机采样吸收、房间大小、声源位置和麦克风距离的人工混响。我们使用了2秒的语音和噪声段,并将它们混合成均匀分布的信噪比(SNR),范围从-5 dB到25 dB。输入特征被用作对数幅谱图、PCEN谱图和解调相位的实/虚部分的通道级联。我们使用了AdamW优化器[21],当连续三个阶段验证分数没有提高时,学习速度降低了一半。初始学习速率设置为0.0004。窗口大小和跳大小分别设置为512 (32ms)和128 (8ms)。
我们还将提出的模型量化为INT8格式,并将模型大小与之前的作品进行了比较。我们的量化模型实验的目的是减少模型尺寸和计算成本的嵌入式环境。我们采用[5]中提出的量化数计算流程来量化神经网络。此外,采用均匀量化并将零点限制为0的均匀对称量化方案[22]实现了高效的硬件实现。在实验中,神经网络的所有层次都采用量化的权值、激活和输入进行处理;只有偏差值以完全精度表示。其他处理步骤,如特征提取和掩码,是在完全精确的计算。对于编码器层和解码器层,我们观察训练过程中中间张量的尺度统计。然后,在推理过程中,我们使用观察到的最小值和最大值的平均值来固定激活的尺度。由于每个时间步长内部激活的动态范围较大,只有GRU层在推理时间内被动态量化。
4.2 消融实验
为了验证PCEN、多尺度目标和FGRU块的效果,我们分别使用CHiME2训练集和发展集对模型进行训练和验证。在CHiME2实验装置上进行消融研究。TRU-Net-A表示所提出的方法。TRU-Net-B表示没有多尺度目标训练的模型。TRU-Net-C表示没有经过PCEN特征训练的模型。TRU-Net-D表示没有FGRU块训练的模型。我们使用最初的SDR[23]来将我们的模型与其他模型进行比较。结果如表2所示。很明显,所有提出的方法都有助于性能的提高。注意,FGRU块对性能有很大的贡献。我们还使用CHiME2测试集将提出的模型与其他模型进行了比较。该模型的性能不仅优于最近的轻量级模型Tiny- LSTM (TLSTM)及其修剪版本(PTLSTM)[24],而且优于大型模型[16]。
4.3 降噪结果
通过在大规模DNS-challenge数据集[25]和内部采集数据集上对模型进行训练,进一步验证了模型的去噪性能。它在两个非盲DNS开发集上进行了测试,1)合成剪辑无混响(合成无混响)和2)合成剪辑有混响(合成有混响)。我们将我们的模型与最近的模型[3,4,17,18,19]进行了比较,这些模型是在2020年Interspeech dns挑战赛上提交的。采用6个评价指标:PESQ、cbac、COVL、CSIG、SI-SDR和STOI[26, 27, 28, 29]。请注意,尽管建议使用ITU-T P862.2宽频带版本的PESQ (PESQ2),但少数研究使用ITU-T P862.1 (PESQ1)报告了他们的得分。因此,我们使用两个PESQ版本将我们的模型与其他模型进行比较。结果如表1所示。我们可以看到,TRU-Net显示了最好的性能在合成没有混响设置,而有最小的参数数目。在合成混响集,使用比其他模型更少的数量级参数,TRU-Net显示了竞争性能。
4.4 去混响结果
在包含3000个音频文件的WHAMR数据集的最小子集上测试了同时去噪和去everberation的性能。WHAMR数据集由噪声混响混合和直接源作为地面真实值组成。试验采用表1中的TRU-Net模型(FP32和INT8)。我们在表3中展示了我们模型的去噪和去everberation性能,以及在相同的WHAMR数据集上测试的另外两个模型。与其他基线模型相比,我们的模型取得了最好的效果,表明了TRU-Net在同时去噪和去everberation任务中的参数效率。
4.5 听力测试结果
使用表1中提出的模型(TRU-Net (FP32)),我们参加了2021年ICASSP DNS挑战Track 1[25]。为了获得更好的感知质量,我们将估计的直接源和混响源混合在15 dB,并应用零延迟动态范围压缩(DRC)。在2.7 GHz Intel i5-5257U和2.6 GHz Intel i7-6700HQ处理器上,处理单帧(包括FFT、iFFT和DRC)的平均计算时间分别为1.97 ms和1.3 ms。TRU-Net的前瞻是0毫秒。听力测试基于ITU-T P.808进行。结果如表4所示。该模型在各种语音集上进行了测试,包括唱歌的声音、音调语言、非英语(包括音调)、英语和情感演讲。结果表明,与基线模型NSnet2[30]相比,TRU-Net具有更好的性能。
5 与先前工作的关系
由于混合信号相位复用的次优性,近年来相位感知语音增强技术受到越来越多的关注。虽然这些工作大多试图通过相位掩码或附加网络来估计干净相位,但实际上可以利用余弦定理[31]来计算混合物和源之间的绝对相位差。受此启发,[6]提出了一种用于语音分离的绝对相位差旋转方向估计方法。
TRU-Net中使用的FGRU和TGRU与[32]中的工作类似。他们在频率维度和时间维度上使用双向长短期记忆(bi-LSTM)网络,并结合基于2d - cnn的U-Net。不同之处是,我们使用bi-LSTM来提高[32]的性能,而我们使用FGRU和单向TGRU来更好地处理在线推理场景,并结合提出的基于一维cnn(频率维度)的轻量级U-Net。
6 结论
在这项工作中,我们提出了TRU-Net,这是一个专门为在线推理应用设计的高效的神经网络架构。结合提出的PHM,我们成功地演示了单级去噪和实时去everberation。我们还表明,使用PCEN和多尺度目标进一步提高了性能。实验结果表明,我们的模型与具有大量参数的最新模型具有相当的性能。在未来的工作中,我们计划在一个过参数化模型上使用现代剪枝技术来开发一个大稀疏模型,在相同的参数数量下,它可能比小稠密模型提供更好的性能。
7 参考文献
[1] Olaf Ronneberger, Philipp Fischer, and Thomas Brox, U-net: Convolutional networks for biomedical image segmentation, in Proc. MICCAI, 2015, pp. 234 241.
[2] Hyeong-Seok Choi, Jang-Hyun Kim, Jaesung Huh, Adrian Kim, Jung-Woo Ha, and Kyogu Lee, Phase-aware speech enhancement with deep complex u-net, arXiv preprint arXiv:1903.03107, 2019.
[3] Umut Isik, Ritwik Giri, Neerad Phansalkar, Jean-Marc Valin, Karim Helwani, and Arvindh Krishnaswamy, Poconet: Better speech enhancement with frequency-positional embeddings, semi-supervised conversational data, and biased loss, in Proc. INTERSPEECH, 2020.
[4] Yanxin Hu, Yun Liu, Shubo Lv, Mengtao Xing, Shimin Zhang, Yihui Fu, Jian Wu, Bihong Zhang, and Lei Xie, Dccrn: Deep complex convolution recurrent network for phase-aware speech enhancement, in Proc. INTERSPEECH, 2020.
[5] Benoit Jacob, Skirmantas Kligys, Bo Chen, Menglong Zhu, Matthew Tang, Andrew Howard, Hartwig Adam, and Dmitry Kalenichenko, Quantization and training of neural networks for efficient integer-arithmetic-only inference, in Proc. CVPR, 2018, pp. 2704 2713.
[6] Zhong-QiuWang, Ke Tan, and DeLiangWang, Deep learning based phase reconstruction for speaker separation: A trigonometric perspective, in Proc. ICASSP, 2019, pp. 71 75.
[7] YuxuanWang, Pascal Getreuer, Thad Hughes, Richard F Lyon, and Rif A Saurous, Trainable frontend for robust and far-field keyword spotting, in Proc. ICASSP, 2017, pp. 5670 5674.
[8] Vincent Lostanlen, Justin Salamon, Mark Cartwright, Brian McFee, Andrew Farnsworth, Steve Kelling, and Juan Pablo Bello, Per-channel energy normalization: Why and how, IEEE Signal Processing Letters, vol. 26, no. 1, pp. 39 43, 2018.
[9] Andrew G Howard, Menglong Zhu, Bo Chen, Dmitry Kalenichenko, Weijun Wang, Tobias Weyand, Marco Andreetto, and Hartwig Adam, Mobilenets: Efficient convolutional neural networks for mobile vision applications, arXiv preprint arXiv:1704.04861, 2017.
[10] Kyunghyun Cho, Bart van Merri enboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshuas Bengio, Learning phrase representations using RNN encoder decoder for statistical machine translation, in Proc. EMNLP, 2014, pp. 1724 1734.
[11] Eric Jang, Shixiang Gu, and Ben Poole, Categorical reparameterization with gumbel-softmax, in Proc. ICLR, 2017.
[12] Xin Wang, Shinji Takaki, and Junichi Yamagishi, Neural source-filter-based waveform model for statistical parametric speech synthesis, in Proc. ICASSP, 2019, pp. 5916 5920.
[13] Jesse Engel, Lamtharn (Hanoi) Hantrakul, Chenjie Gu, and Adam Roberts, Ddsp: Differentiable digital signal processing, in Proc. ICLR, 2020.
[14] Jian Yao and Ahmad Al-Dahle, Coarse-to-Fine Optimization for Speech Enhancement, in Proc. INTERSPEECH, 2019, pp. 2743 2747.
[15] Hakan Erdogan and Takuya Yoshioka, Investigations on data augmentation and loss functions for deep learning based speech-background separation. , in INTERSPEECH, 2018, pp. 3499 3503.
[16] Kevin Wilson, Michael Chinen, Jeremy Thorpe, Brian Patton, John Hershey, Rif A Saurous, Jan Skoglund, and Richard F Lyon, Exploring tradeoffs in models for low-latency speech enhancement, in IWAENC, 2018, pp. 366 370.
[17] Yangyang Xia, Sebastian Braun, Chandan KA Reddy, Harishchandra Dubey, Ross Cutler, and Ivan Tashev, Weighted speech distortion losses for neural-network-based real-time speech enhancement, in Proc. ICASSP, 2020, pp. 871 875.
[18] Nils L Westhausen and Bernd T Meyer, Dual-signal transformation lstm network for real-time noise suppression, in Proc. INTERSPEECH, 2020.
[19] Yuichiro Koyama, Tyler Vuong, Stefan Uhlich, and Bhiksha Raj, Exploring the best loss function for dnn-based lowlatency speech enhancement with temporal convolutional networks, arXiv preprint arXiv:2005.11611, 2020.
[20] Robin Scheibler, Eric Bezzam, and Ivan Dokmani c, Pyroomacoustics: A python package for audio room simulation and array processing algorithms, in Proc. ICASSP, 2018, pp. 351 355.
[21] Sashank J. Reddi, Satyen Kale, and Sanjiv Kumar, On the convergence of adam and beyond, in Proc. ICLR, 2018.
[22] Raghuraman Krishnamoorthi, Quantizing deep convolutional networks for efficient inference: A whitepaper, arXiv preprint arXiv:1806.08342, 2018.
[23] Emmanuel Vincent, R emi Gribonval, and C edric F evotte, Performance measurement in blind audio source separation, IEEE transactions on audio, speech, and language processing, vol. 14, no. 4, pp. 1462 1469, 2006.
[24] Igor Fedorov, Marko Stamenovic, Carl Jensen, Li-Chia Yang, Ari Mandell, Yiming Gan, Matthew Mattina, and Paul N Whatmough, Tinylstms: Efficient neural speech enhancement for hearing aids, in Proc. INTERSPEECH, 2020.
[25] Chandan KA Reddy, Harishchandra Dubey, Vishak Gopal, Ross Cutler, Sebastian Braun, Hannes Gamper, Robert Aichner, and Sriram Srinivasan, Icassp 2021 deep noise suppression challenge, arXiv preprint arXiv:2009.06122, 2020.
[26] ITU-T Recommendation, Perceptual evaluation of speech quality (pesq): An objective method for end-to-end speech quality assessment of narrow-band telephone networks and speech codecs, Rec. ITU-T P. 862, 2001.
[27] Philipos C Loizou, Speech enhancement: theory and practice, CRC press, 2013.
[28] Jonathan Le Roux, ScottWisdom, Hakan Erdogan, and John R Hershey, Sdr half-baked or well done? , in Proc. ICASSP, 2019, pp. 626 630.
[29] Cees H Taal, Richard C Hendriks, Richard Heusdens, and Jesper Jensen, A short-time objective intelligibility measure for time-frequency weighted noisy speech, in Proc. ICASSP, 2010, pp. 4214 4217.
[30] Sebastian Braun and Ivan Tashev, Data augmentation and loss normalization for deep noise suppression, in International Conference on Speech and Computer, 2020, pp. 79 86.
[31] Pejman Mowlaee, Rahim Saeidi, and Rainer Martin, Phase estimation for signal reconstruction in single-channel source separation, in Thirteenth Annual Conference of the International Speech Communication Association, 2012.
[32] Tomasz Grzywalski and Szymon Drgas, Using recurrences in time and frequency within u-net architecture for speech enhancement, in Proc. ICASSP, 2019, pp. 6970 6974.