目录
- 一、Scala的安装
- 二、Spark的安装
- 1、Spark的几个版本的意思
- 2、Spark的最新版本:[Spark最新版](https://spark.apache.org/downloads.html)
- 3、安装Spark
- 4、下载winutils
在我们安装Spark之前,由于Spark基于Scala的,所以我们需要先安装Scala。
一、Scala的安装
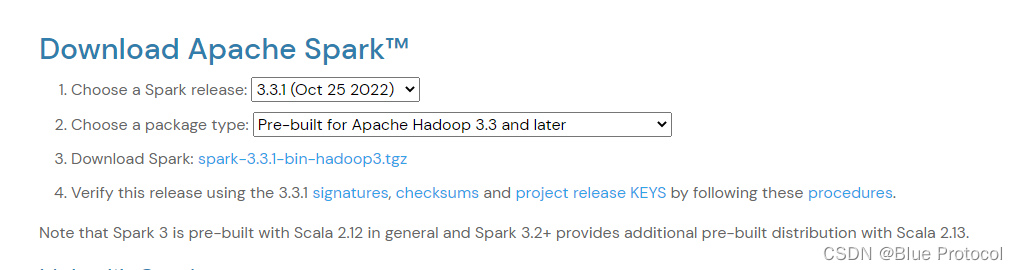
,这里先说明一下Spark与Scala版本之间的问题,在Spark的官网中有这样一句话:Note that Spark 3 is pre-built with Scala 2.12 in general and Spark 3.2+ provides additional pre-built distribution with Scala 2.13.
这个看一下就懂了,如果我们安装Spark3版本的我们需要先安装Scala 2.12,而Spark 3.2+的需要使用Scala 2.13.
1、先给出Scala的官网,在这里可以下载所有版本的Scala All Version,由于我们下载的Spark是spark-3.1.3-bin-hadoop3.2版本的,所以这里下载的Scala版本是2.12版本,既Scala 2.12.17,然后解压到一个指定的文件夹,如:D:\Environment\scala-2.12.17
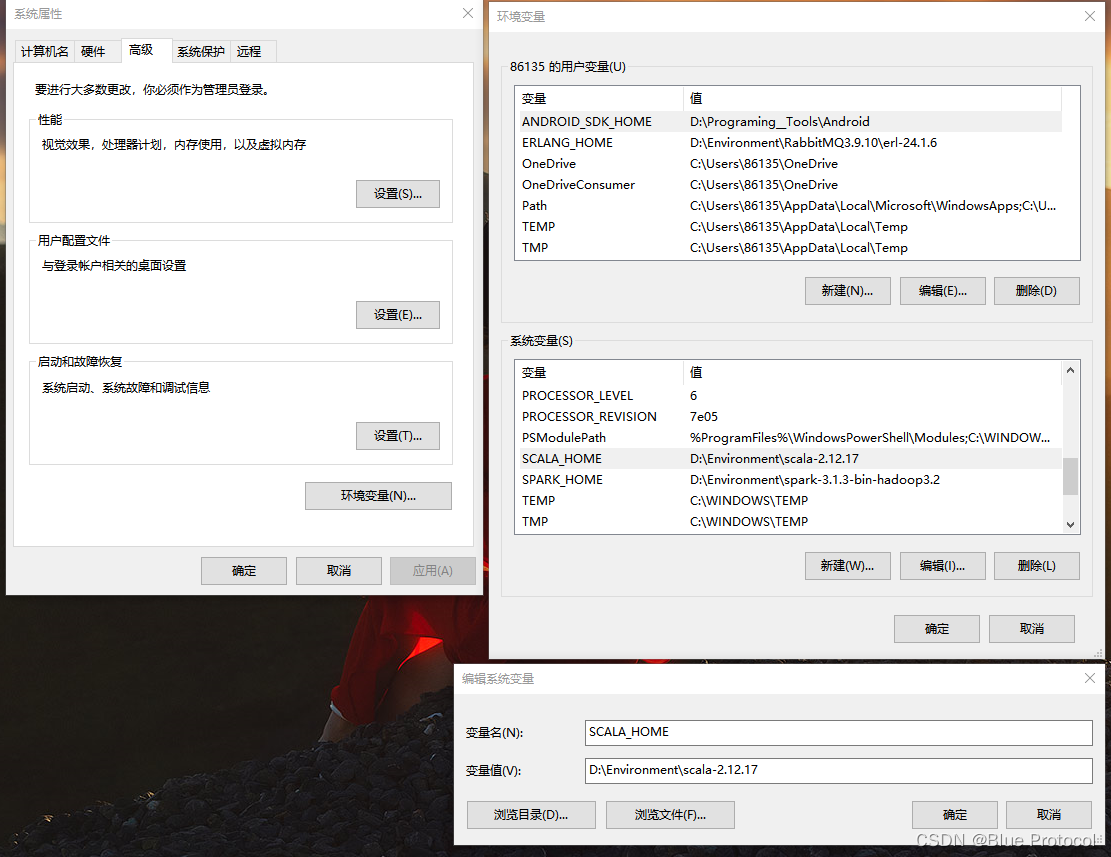
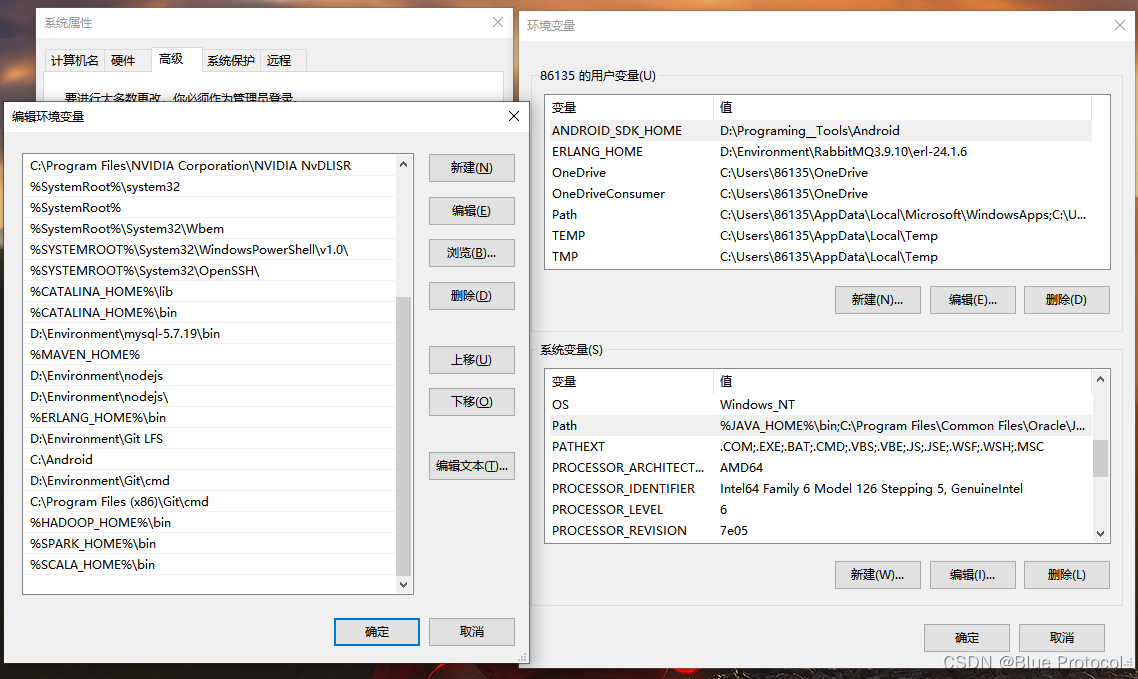
2、配置环境变量:在我的电脑中的高级系统设置中我们在系统变量(s)中新建一个系统变量,变量名:SCALA_HOME,变量值:D:\Environment\scala-2.12.17
3、然后在系统变量(s)的Path中新建一个%SCALA_HOME%\bin
4、打开控制台,输入scala即可

二、Spark的安装
安装Spark之前,我们先来看一下Spark的几个版本的意思
Spark官网中:Spark All Version
我们以我们的Spark3.1.3为例子
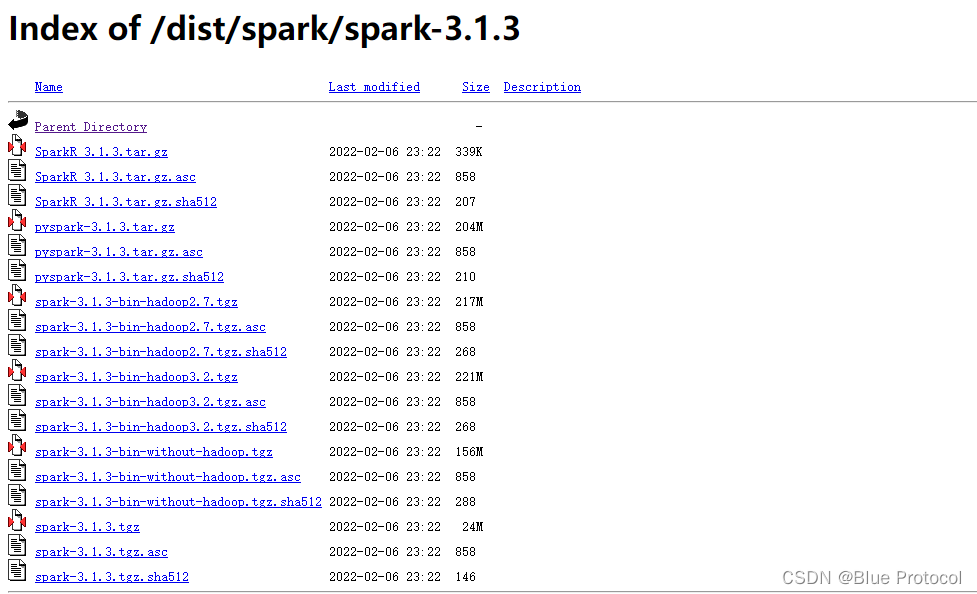
1、Spark的几个版本的意思
- SparkR是R语言的版本
- spark-bin-hadoop 包含hadoop;包含默认的scala版本(spark基于scala,scala基于jvm)
- spark-bin-without-hadoop
不包含hadoop,需要用户自己单独安装hadoop并设置spark到hadoop的关联关系;包含默认的scala版本。 - spark-bin-without-hadoop-scala-2.11 不包含hadoop,包含特定版本(2.11)的scala。
- 话说回来,为什么没有带hadoop和特定版本的scala。
- spark-tgz这是源码。
2、Spark的最新版本:Spark最新版
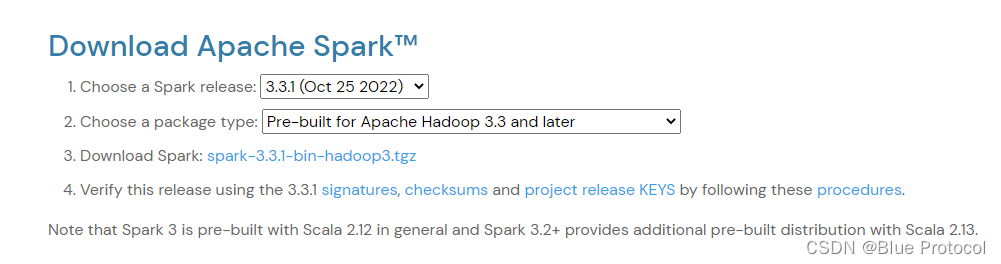
这个看一下就懂了,如果我们安装Spark3版本的我们需要先安装Scala 2.12,而Spark 3.2+的需要使用Scala 2.13.
3、安装Spark
1、下载spark-3.1.3-bin-hadoop3.2版本,,然后解压到一个指定的文件夹,如:D:\Environment\spark-3.1.3-bin-hadoop3.2
2、配置环境变量:在我的电脑中的高级系统设置中我们在系统变量(s)中新建一个系统变量,变量名:SPARK_HOME,变量值:D:\Environment\spark-3.1.3-bin-hadoop3.2
3、然后在系统变量(s)的Path中新建一个%SPARK_HOME%\bin
其实步骤和安装Scala是一样的,只是Spark的还不能进行版本测试。
4、下载winutils
1、为什么要使用winutils这个东西,首先我们先给出它的GitHub地址:Winutils Github,然后看看GitHub里面的内容,如下图:
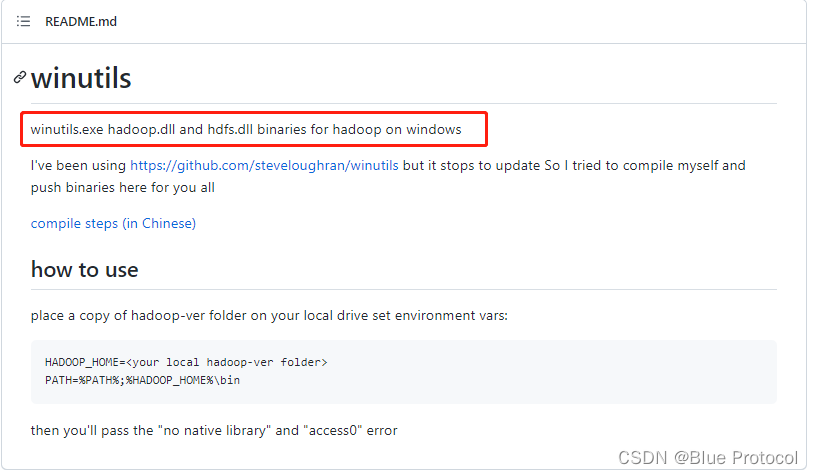
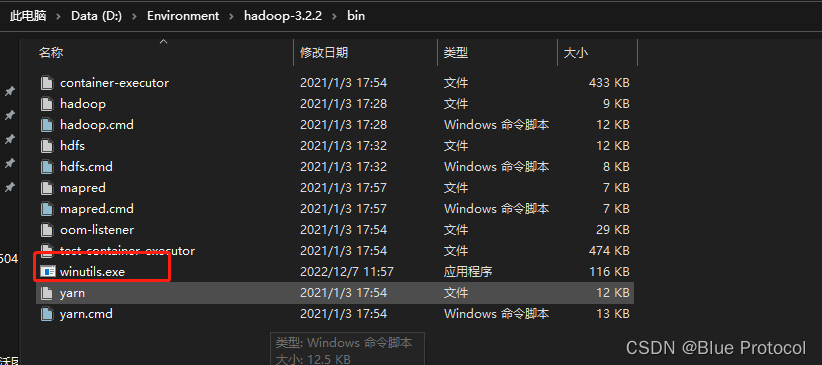
我们下载与我们hadoop对应版本的,如hadoop-3.2.2,然后把这个路径下的D:\Environment\winutls\winutils\hadoop-3.2.2\bin一个文件winutils.exe复制到我们的hadoop-3.2.2的bin目录下,如下图:
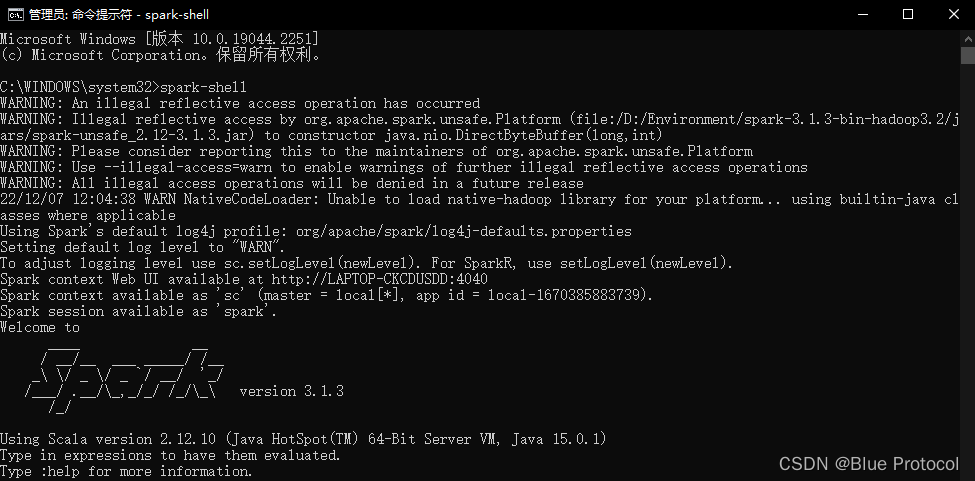
然后这样我们就安装完成了,之后我们打开我们的cmd,输入spark-shell即可,如下图:






![[附源码]Python计算机毕业设计Django医疗器械公司公告管理系统](https://img-blog.csdnimg.cn/7789bc464343494abcbda4f489ed4ed7.png)