文章目录
- 基础介绍:
- 实现思路:
- 详细介绍
- 1. 聊天机器人发展历程:
- 2. embedding_attention_seq2seq接口:
- 3. 训练模型:
- 4. Python编程实现完整的聊天机器人:
- 补充内容:
- 环境搭建与关键技术
- 环境搭建
- 关键技术
- 代码实现
- 总结与心得
基础介绍:
基于TensorFlow的聊天机器人主要使用机器深度学习方法,其中最常用的模型是seq2seq+Attention模型。这种模型可以实现从源语句到目标语句的自动翻译或者生成。在聊天机器人中,可以将用户的问题作为源语句,将机器人生成的回答作为目标语句,通过模型的训练和学习来构建一个智能的对话机器人。
首先,使用jieba中文分词框架对汉字文本进行分词是为了将句子切分成可处理的词语。这可以帮助模型更好地理解句子的语义,同时还可以减少输入数据的维度。分词后,每个词语都会被编入ID编号,以便模型能够处理。
然后,通过大量数据的训练与学习,模型可以逐渐学习到语言的规律和概念。可以使用一个包含问答对的语料库来训练模型,这样模型就能学会将问题和相应的答案联系起来。在训练过程中,可以使用反向传播算法和优化器来调整模型参数,使得模型能够产生正确的回答。
在训练完成后,聊天机器人就可以用于实际对话了。当用户输入一个问题时,机器人会将其分词并转换成ID编码的形式,然后将其输入模型。模型会经过前向传播,计算出一个概率分布,表示可能的回答。通过选择概率最高的回答,机器人就可以生成相应的答案并返回给用户。
其中,为了提高模型的效果,引入Attention机制是非常重要的。Attention机制能够帮助模型在生成每个词语时,更加注重相关的上下文信息,从而提升模型的语义理解和回答质量。
此外,为了丰富语料库并提高模型的泛化能力,可以不仅仅使用问答对作为训练数据,还可以包含其他类型的对话,如闲聊、常见问题等。这样可以使得机器人对各种类型的问题都具备一定的应答能力。
总之,利用深度学习模型进行训练和学习,以实现人机对话的自动匹配和回答。通过适当的数据预处理、分词编码、模型构建和优化,以及引入Attention机制,可以让聊天机器人具备更好的对话能力和语义理解能力。
实现思路:
1、数据预处理:将语料库中的问题和答案进行分词,可以使用jieba中文分词工具对汉字文本进行分词处理。分词后的每个词语都会被映射为一个唯一的ID编号,以便模型能够处理。
2、模型构建:使用TensorFlow框架搭建基于机器深度学习的对话机器人模型,采用seq2seq+Attention模型。Seq2seq模型由编码器(Encoder)和解码器(Decoder)组成,编码器将输入的问题序列转换为一个固定长度的向量表示,解码器使用这个向量进行生成回答。
3、训练数据准备:使用大量的问答对数据作为训练集,其中问题作为输入序列,答案作为目标序列。可以通过爬取互联网上的问答社区或使用已有的开放数据集来获取训练数据。
4、模型训练:将准备好的训练数据输入模型进行训练,使用反向传播算法和优化器来调整模型参数,使得模型能够生成正确的回答。可以设置合适的损失函数,如交叉熵损失函数,来评估模型的输出与真实答案之间的差距,并优化模型。
5、匹配与生成回答:当用户输入一个问题时,对输入语句进行分词处理,并将分词后的序列输入已经训练好的模型。模型通过编码器将问题的序列转换为一个向量表示,然后解码器使用这个向量进行生成回答。在解码器的过程中,Attention机制可以帮助模型关注相关的上下文信息,提高回答的质量和准确性。
6、模型评估和改进:通过人工评估和测试集评估等方式对模型进行评估,根据评估结果进行模型的改进和优化。可以根据实际应用场景的需求,调整模型的超参数、损失函数等,来提升机器人的回答能力和智能水平。
详细介绍
1. 聊天机器人发展历程:
-
第一代:基于规则的聊天机器人,通过编写预先定义的规则和模式匹配来生成回答。这些规则是手动编写的,无法涵盖所有可能的对话情况,且难以处理复杂的自然语言。
-
第二代:统计方法的聊天机器人,引入了机器学习技术,通过统计方法建模和训练,例如使用n-gram模型进行语言建模,并使用最大似然估计来生成回答。虽然在某些程度上可以提高对话的流畅度,但缺乏理解语义和上下文的能力,生成的回答可能不准确。
-
第三代:基于深度学习的聊天机器人,采用神经网络模型进行建模和训练。其中,seq2seq(Sequence-to-Sequence)模型是一种常见的模型结构,它由编码器(Encoder)和解码器(Decoder)组成,通过将输入序列映射为一个固定长度的向量表示,再将该向量作为解码器的初始状态,生成输出序列。为了关注输入序列中的相关信息并提高回答的质量,引入了Attention机制。
2. embedding_attention_seq2seq接口:
- embedding_attention_seq2seq是TensorFlow中的接口,用于构建seq2seq+Attention模型。
- 接口的参数主要包括encoder_inputs、decoder_inputs和attention_states等。
- encoder_inputs表示编码器的输入序列,decoder_inputs表示解码器的输入序列,attention_states表示用于计算Attention权重的向量表示。
- 其他常用参数包括num_encoder_symbols、num_decoder_symbols、embedding_size、num_heads等,用于指定词汇表大小、词向量维度、注意力头数等。
3. 训练模型:
(1) 中文分词:使用jieba库对中文文本进行分词处理,将句子切分为词语序列。
(2) 获取训练集函数:根据应用场景,可以从互联网上爬取问答数据或使用现有的开放数据集作为训练集。将问答数据转换为模型所需的格式,并划分为训练集和验证集。
(3) 获取句子id函数:使用词汇表将分词后的句子转换为句子ID序列,方便模型进行处理。
(4) 预测函数:定义模型的推理阶段,通过编码器和解码器进行序列生成并生成回答。
(5) 优化参数:选择合适的损失函数(如交叉熵损失函数)、优化器(如Adam优化器)和超参数,进行模型的训练和优化。
4. Python编程实现完整的聊天机器人:
- 基于以上所述的步骤,可以使用Python编程语言搭建一个聊天机器人的系统。
- 通过引入jieba库进行中文分词,搭建seq2seq+Attention模型,并使用TensorFlow提供的接口进行模型训练和预测。
- 在编码过程中,可以结合实际需求,对模型进行适当的优化和改进,例如增加更多的训练数据、调整模型结构和超参数等。
- 最后,进行系统调试,确保机器人能够对用户提出的问题做出准确、合理的回答,并具备一定的智能水平。
补充内容:
为了扩展和丰富聊天机器人的功能,可以考虑以下一些方面:
- 实体识别:引入实体识别技术,从问句中提取出关键信息,以便更精准地回答用户的问题。
- 意图识别:将用户的问题进行意图分类,从而能更好地理解用户的需求并给出相应的回答。
- 对话管理:通过引入对话管理技术,使得聊天机器人能够进行多轮对话,记住上下文信息并进行连贯的交流。
- 多模态处理:结合文本、图片、语音等多种输入方式,使得聊天机器人能够处理多样化的用户输入。
- 领域适应:根据具体的应用场景,对聊天机器人进行领域适应,提供更专业和针对性的回答。
- 用户反馈机制:增加用户反馈机制,不断收集用户的评价和建议,以便优化和改善聊天机器人的性能。
环境搭建与关键技术
环境搭建
使用python3.6的python解释器,tensorflow version = 1.14,tensorflow的embedding_attention_seq2seq,使用LSTM神经网络,采用AdamOptimizer优化器、jieba中文分词等。其中各项的安装与搭建过程如下所示:
- 安装Anaconda(包管理器和环境管理器):
Anaconda 附带了一大批常用数据科学包,它附带了 conda、Python 和 150 多个科学包及其依赖项。因此你可以立即开始处理数据。在数据分析中,会用到很多第三方的包,而conda(包管理器)可以很好的帮助你在计算机上安装和管理这些包,包括安装、卸载和更新包。
(1)Anaconda安装配置步骤及说明:
- a.进入官网,点击Download;
- b.选择自己电脑合适的版本进行下载(选择2020.11版本的64位);
- c.按照自己的下载路径找到安装程序,并点击该安装程序进行安装;
- d.按照提示按默认选项进行安装,最后点击finish完成安装;
- e.打开“系统属性-高级-环境变量-user的用户变量-选择Path-编辑进行环境配置,在变量值后面依次添加自己安装的路径如下:

- f.点击确定,最后完成环境的配置。
- g.点击开始打开Anaconda prompt(Anaconda3)后进如Anaconda3的终端,进行换国内镜像源,在命令行输入如下命令:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
- h.设置搜索时显示通道地址
conda config --set show_channel_urls yes
Anaconda完成安装。
1.利用Anaconda3进行python3.6解释器的安装:
(1)进入Windows系统的cmd界面:然后输入:conda --version检查anaconda的版本,结果如图

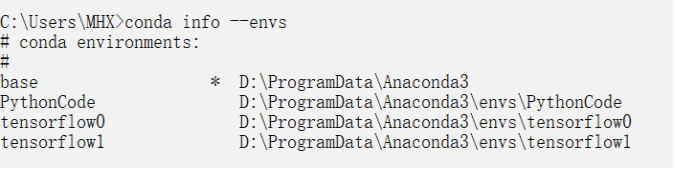
(3)安装python及创建tensorflow环境
(4)用命令conda search --full --name python检查anaconda支持的python版本
(5)安装Python解释器并创建tensorflow0的环境conda create --name tensorflow0 python=3.6;
(6)进入tensorflow0环境命令为:activate tensorflow0
2.在tensorflow0环境中安装tensorflow1.14,
(1)命令为pip install --upgrade --ignore-installed tensorflow,安装成功tensorflow=1.14版本;
(2)验证tensorflow安装成功与否,输入以下代码代码:
import tensorflow as tf
hello = tf.constant(‘hello,tf’)
sess = tf.Session()
print(sess.run(hello))
3.安装配置tensorflow0环境到运行代码的IDE Pycham
(1)下载安装Pycham:进入Pycham官网下载Pycham社区版安装包到本地,点击默认选项进行安装。
(2)添加环境tensorflow0到Pycham

关键技术
Anaconda3在安装后的环境变量配置上注意正确的路径设置,在python版本的选择上一定要注意选择python3.6版本,原因是最新版本不能安装tensorflow1.14版本,正确选择tensorflow版本是程序运行成功与否的关键因素,由于基于tensorflow的机器学习主要参考的是google公司的,其大多算法框架以及接口都和tensorflow2的不兼容,本人在tensorflow的选择和下载上遇到了很多困难,环境的搭建一定是基于python3.6和Tensorflow1.14版本的,其他需要的jieba中文分词库和seq2seq、以及numpy库的时候都是比较简单的操作,具体是在Terminal中输入以下命令即可成功安装。
安装numpy库的命令:pip install numpy
安装jieba库的命令:pip install jieba
安装seq2seq库的命令:pip install seq2seq
代码实现
1.取词编号:
# coding:utf-8
import sys
import jieba
from numpy import unicode
class WordToken(object):
def __init__(self):
# 最小起始id号, 保留的用于表示特殊标记
self.START_ID = 4
self.word2id_dict = {}
self.id2word_dict = {}
def load_file_list(self, file_list, min_freq):
"""
加载样本文件列表,全部切词后统计词频,按词频由高到低排序后顺次编号
并存到self.word2id_dict和self.id2word_dict中
"""
words_count = {}
for file in file_list:
with open(file, 'r',encoding='utf-8') as file_object:
for line in file_object.readlines():
line = line.strip()
seg_list = jieba.cut(line)
for str in seg_list:
if str in words_count:
words_count[str] = words_count[str] + 1
else:
words_count[str] = 1
sorted_list = [[v[1], v[0]] for v in words_count.items()]
sorted_list.sort(reverse=True)
for index, item in enumerate(sorted_list):
word = item[1]
if item[0] < min_freq:
break
self.word2id_dict[word] = self.START_ID + index
self.id2word_dict[self.START_ID + index] = word
return index
def word2id(self, word):
if not isinstance(word, unicode):
print ("Exception: error word not unicode")
sys.exit(1)
if word in self.word2id_dict:
return self.word2id_dict[word]
else:
return None
def id2word(self, id):
id = int(id)
if id in self.id2word_dict:
return self.id2word_dict[id]
else:
return None
2.训练:
# coding:utf-8
import sys
import jieba
from numpy import unicode
class WordToken(object):
def __init__(self):
# 最小起始id号, 保留的用于表示特殊标记
self.START_ID = 4
self.word2id_dict = {}
self.id2word_dict = {}
def load_file_list(self, file_list, min_freq):
"""
加载样本文件列表,全部切词后统计词频,按词频由高到低排序后顺次编号
并存到self.word2id_dict和self.id2word_dict中
"""
words_count = {}
for file in file_list:
with open(file, 'r',encoding='utf-8') as file_object:
for line in file_object.readlines():
line = line.strip()
seg_list = jieba.cut(line)
for str in seg_list:
if str in words_count:
words_count[str] = words_count[str] + 1
else:
words_count[str] = 1
sorted_list = [[v[1], v[0]] for v in words_count.items()]
sorted_list.sort(reverse=True)
for index, item in enumerate(sorted_list):
word = item[1]
if item[0] < min_freq:
break
self.word2id_dict[word] = self.START_ID + index
self.id2word_dict[self.START_ID + index] = word
return index
def word2id(self, word):
if not isinstance(word, unicode):
print ("Exception: error word not unicode")
sys.exit(1)
if word in self.word2id_dict:
return self.word2id_dict[word]
else:
return None
def id2word(self, id):
id = int(id)
if id in self.id2word_dict:
return self.id2word_dict[id]
else:
return None
3.测试:
# coding:utf-8
import sys
import numpy as np
import tensorflow as tf
from tensorflow.contrib.legacy_seq2seq.python.ops import seq2seq
import word_token
import jieba
import random
# 输入序列长度
input_seq_len = 5
# 输出序列长度
output_seq_len = 5
# 空值填充0
PAD_ID = 0
# 输出序列起始标记
GO_ID = 1
# 结尾标记
EOS_ID = 2
# LSTM神经元size
size = 8
# 初始学习率
init_learning_rate = 1
# 在样本中出现频率超过这个值才会进入词表
min_freq = 10
wordToken = word_token.WordToken()
# 放在全局的位置,为了动态算出num_encoder_symbols和num_decoder_symbols
max_token_id = wordToken.load_file_list(['./samples/question', './samples/answer'], min_freq)
num_encoder_symbols = max_token_id + 5
num_decoder_symbols = max_token_id + 5
def get_id_list_from(sentence):
sentence_id_list = []
seg_list = jieba.cut(sentence)
for str in seg_list:
id = wordToken.word2id(str)
if id:
sentence_id_list.append(wordToken.word2id(str))
return sentence_id_list
def get_train_set():
global num_encoder_symbols, num_decoder_symbols
train_set = []
with open('samples/question', 'r', encoding='utf-8') as question_file:
with open('samples/answer', 'r', encoding='utf-8') as answer_file:
while True:
question = question_file.readline()
answer = answer_file.readline()
if question and answer:
question = question.strip()
answer = answer.strip()
question_id_list = get_id_list_from(question)
answer_id_list = get_id_list_from(answer)
if len(question_id_list) > 0 and len(answer_id_list) > 0:
answer_id_list.append(EOS_ID)
train_set.append([question_id_list, answer_id_list])
else:
break
return train_set
def get_samples(train_set, batch_num):
raw_encoder_input = []
raw_decoder_input = []
if batch_num >= len(train_set):
batch_train_set = train_set
else:
random_start = random.randint(0, len(train_set)-batch_num)
batch_train_set = train_set[random_start:random_start+batch_num]
for sample in batch_train_set:
raw_encoder_input.append([PAD_ID] * (input_seq_len - len(sample[0])) + sample[0])
raw_decoder_input.append([GO_ID] + sample[1] + [PAD_ID] * (output_seq_len - len(sample[1]) - 1))
encoder_inputs = []
decoder_inputs = []
target_weights = []
for length_idx in range(input_seq_len):
encoder_inputs.append(np.array([encoder_input[length_idx] for encoder_input in raw_encoder_input], dtype=np.int32))
for length_idx in range(output_seq_len):
decoder_inputs.append(np.array([decoder_input[length_idx] for decoder_input in raw_decoder_input], dtype=np.int32))
target_weights.append(np.array([
0.0 if length_idx == output_seq_len - 1 or decoder_input[length_idx] == PAD_ID else 1.0 for decoder_input in raw_decoder_input
], dtype=np.float32))
return encoder_inputs, decoder_inputs, target_weights
def seq_to_encoder(input_seq):
"""从输入空格分隔的数字id串,转成预测用的encoder、decoder、target_weight等
"""
input_seq_array = [int(v) for v in input_seq.split()]
encoder_input = [PAD_ID] * (input_seq_len - len(input_seq_array)) + input_seq_array
decoder_input = [GO_ID] + [PAD_ID] * (output_seq_len - 1)
encoder_inputs = [np.array([v], dtype=np.int32) for v in encoder_input]
decoder_inputs = [np.array([v], dtype=np.int32) for v in decoder_input]
target_weights = [np.array([1.0], dtype=np.float32)] * output_seq_len
return encoder_inputs, decoder_inputs, target_weights
def get_model(feed_previous=False):
"""构造模型
"""
learning_rate = tf.Variable(float(init_learning_rate), trainable=False, dtype=tf.float32)
learning_rate_decay_op = learning_rate.assign(learning_rate * 0.9)
encoder_inputs = []
decoder_inputs = []
target_weights = []
for i in range(input_seq_len):
encoder_inputs.append(tf.placeholder(tf.int32, shape=[None], name="encoder{0}".format(i)))
for i in range(output_seq_len + 1):
decoder_inputs.append(tf.placeholder(tf.int32, shape=[None], name="decoder{0}".format(i)))
for i in range(output_seq_len):
target_weights.append(tf.placeholder(tf.float32, shape=[None], name="weight{0}".format(i)))
# decoder_inputs左移一个时序作为targets
targets = [decoder_inputs[i + 1] for i in range(output_seq_len)]
cell = tf.contrib.rnn.BasicLSTMCell(size)
# 这里输出的状态我们不需要
outputs, _ = seq2seq.embedding_attention_seq2seq(
encoder_inputs,
decoder_inputs[:output_seq_len],
cell,
num_encoder_symbols=num_encoder_symbols,
num_decoder_symbols=num_decoder_symbols,
embedding_size=size,
output_projection=None,
feed_previous=feed_previous,
dtype=tf.float32)
# 计算加权交叉熵损失
loss = seq2seq.sequence_loss(outputs, targets, target_weights)
# 梯度下降优化器
opt = tf.train.GradientDescentOptimizer(learning_rate)
# 优化目标:让loss最小化
update = opt.apply_gradients(opt.compute_gradients(loss))
# 模型持久化
saver = tf.train.Saver(tf.global_variables())
return encoder_inputs, decoder_inputs, target_weights, outputs, loss, update, saver, learning_rate_decay_op, learning_rate
def train():
"""
训练过程
"""
train_set = get_train_set()
with tf.Session() as sess:
encoder_inputs, decoder_inputs, target_weights, outputs, loss, update, saver, learning_rate_decay_op, learning_rate = get_model()
# 全部变量初始化
sess.run(tf.global_variables_initializer())
# 训练很多次迭代,每隔10次打印一次loss,可以看情况直接ctrl+c停止
previous_losses = []
for step in range(50000):
sample_encoder_inputs, sample_decoder_inputs, sample_target_weights = get_samples(train_set, 1000)
input_feed = {}
for l in range(input_seq_len):
input_feed[encoder_inputs[l].name] = sample_encoder_inputs[l]
for l in range(output_seq_len):
input_feed[decoder_inputs[l].name] = sample_decoder_inputs[l]
input_feed[target_weights[l].name] = sample_target_weights[l]
input_feed[decoder_inputs[output_seq_len].name] = np.zeros([len(sample_decoder_inputs[0])], dtype=np.int32)
[loss_ret, _] = sess.run([loss, update], input_feed)
if step % 10 == 0:
print ('step=', step, 'loss=', loss_ret, 'learning_rate=', learning_rate.eval())
if len(previous_losses) > 5 and loss_ret > max(previous_losses[-5:]):
sess.run(learning_rate_decay_op)
previous_losses.append(loss_ret)
# 模型持久化
saver.save(sess, './model/demo')
def predict():
"""
预测过程
"""
with tf.Session() as sess:
encoder_inputs, decoder_inputs, target_weights, outputs, loss, update, saver, learning_rate_decay_op, learning_rate = get_model(feed_previous=True)
saver.restore(sess, './model/demo')
sys.stdout.write("> ")
sys.stdout.flush()
input_seq = sys.stdin.readline()
while input_seq:
input_seq = input_seq.strip()
input_id_list = get_id_list_from(input_seq)
if (len(input_id_list)):
sample_encoder_inputs, sample_decoder_inputs, sample_target_weights = seq_to_encoder(' '.join([str(v) for v in input_id_list]))
input_feed = {}
for l in range(input_seq_len):
input_feed[encoder_inputs[l].name] = sample_encoder_inputs[l]
for l in range(output_seq_len):
input_feed[decoder_inputs[l].name] = sample_decoder_inputs[l]
input_feed[target_weights[l].name] = sample_target_weights[l]
input_feed[decoder_inputs[output_seq_len].name] = np.zeros([2], dtype=np.int32)
# 预测输出
outputs_seq = sess.run(outputs, input_feed)
# 因为输出数据每一个是num_decoder_symbols维的,因此找到数值最大的那个就是预测的id,就是这里的argmax函数的功能
outputs_seq = [int(np.argmax(logit[0], axis=0)) for logit in outputs_seq]
# 如果是结尾符,那么后面的语句就不输出了
if EOS_ID in outputs_seq:
outputs_seq = outputs_seq[:outputs_seq.index(EOS_ID)]
outputs_seq = [wordToken.id2word(v) for v in outputs_seq]
print (" ".join(outputs_seq))
else:
print ("你觉得呢")
sys.stdout.write("> ")
sys.stdout.flush()
input_seq = sys.stdin.readline()
if __name__ == "__main__":
#训练:
#train()
#测试对话:
predict()
总结与心得
基于OneAPI工具分析包TensorFlow的主要机器深度学习框架,使用seq2seq+Attention模型的聊天机器人,通过jieba中文分词框架对汉字文本语句进行分词,然后对分词结果进行编号。接着,通过大量的数据训练和学习,生成一个模型,使其能够实现基本的人机对话功能。
这样的聊天机器人能够自动识别输入的聊天句子,并匹配相应的问题答案。它通过对大量语料库文本词汇进行训练,能够根据输入的问题生成相应的回答。
使用这样的聊天机器人可以获得一些总结和新的体会,例如:
- 语言理解与生成:通过机器深度学习,模型可以理解人类语言并生成相应的回答。这种技术在自然语言处理领域具有广泛的应用前景。
- 上下文感知:seq2seq+Attention模型能够记住对话的上下文信息,从而在多轮对话中保持连贯性,并给出更准确的回答。
- 多模态处理:通过使用OneAPI工具分析包TensorFlow,结合其他技术如图像处理、语音处理等,可以实现多模态的输入和输出,提供更丰富的对话体验。
- 预训练模型:通过大量的训练与学习,聊天机器人可以具备一定的智能水平,能够回答各种类型的问题,并根据不同领域的语料库进行适应性调整。
- 应用场景拓展:聊天机器人可以广泛应用于客服、智能助手、问答系统等领域,为用户提供便捷的人机交互体验。
总之,基于OneAPI工具分析包TensorFlow的聊天机器人利用深度学习技术和seq2seq+Attention模型,经过大量数据的训练与学习,实现了基本的人机对话功能。它可以自动识别用户的输入,并给出相应的回答。这样的机器人在语言理解与生成、上下文感知、多模态处理和预训练模型方面取得了令人满意的效果,为各种应用场景提供了丰富的可能性。