系列文章目录
第一章 AlexNet网络详解
第二章 VGG网络详解
第三章 GoogLeNet网络详解
第四章 ResNet网络详解
第五章 ResNeXt网络详解
第六章 MobileNetv1网络详解
第七章 MobileNetv2网络详解
第八章 MobileNetv3网络详解
第九章 ShuffleNetv1网络详解
第十章 ShuffleNetv2网络详解
第十一章 EfficientNetv1网络详解
第十二章 EfficientNetv2网络详解
第十三章 Transformer注意力机制
第十四章 Vision Transformer网络详解
第十五章 Swin-Transformer网络详解
第十六章 ConvNeXt网络详解
第十七章 RepVGG网络详解
第十八章 MobileViT网络详解
文章目录
- 0. 摘要
- 1. 前言
- 2.
- 1.
- 2.
- 总结
干货集锦

0、摘要
本文介绍了一种新的视觉Transformer,称为Swin Transformer,它具备作为计算机视觉通用骨干网的能力。将Transformer从语言领域转换到视觉领域面临的挑战来自两个领域的差异,如视觉实体的尺度变化较大以及图像中像素的分辨率相对于文本中的单词高得多。为了解决这些差异,我们提出了一种分层Transformer,其表示是通过Shifted 窗口计算得出的。该Shifted 窗口方案通过将自注意计算限制在非重叠的本地窗口上,同时允许窗口连接,从而带来更高的效率。这种分层架构具有在不同尺度下建模的灵活性,并且与图像尺寸呈线性计算复杂度。Swin Transformer的这些品质使其适用于广泛的视觉任务,包括图像分类(在ImageNet-1K上的87.3 top-1准确率)以及密集预测任务,例如目标检测(在COCO testdev上的58.7 box AP和51.1 mask AP)和语义分割(在ADE20K val上的53.5 mIoU)。其性能大大超过了以前的技术水平,COCO上的+2.7 box AP和+2.6 mask AP以及ADE20K上的+3.2 mIoU,这证明了基于Transformer的模型作为视觉骨干网的潜力。分层设计和Shifted 窗口方法对于所有MLP体系结构也是有利的。代码和模型可在<a href="https://github.com/microsoft/Swin-Transformer%E5%85%AC%E5%BC%80%E8%8E%B7%E5%BE%97%E3%80%82">https://github.com/microsoft/Swin-Transformer公开获得。</a></p>
1、前言
1.引言 在计算机视觉中,建模一直由卷积神经网络(CNNs)主导。从AlexNet [39]开始,通过*等量贡献。†在MSRA的实习生。‡联系人。图1。(a)提出的Swin Transformer通过合并更深层次的图像块(显示为灰色),建立分层特征映射,并且由于只计算每个局部窗口内的自我关注而对输入图像大小具有线性计算复杂度。因此,它可以成为图像分类和密集识别任务的通用骨干。(b)相比之下,以前的视觉Transformer [20]产生单个低分辨率的特征图,并且由于全局自我注意力计算而对输入图像大小具有二次计算复杂度。更大规模[30,76],更广泛的连接[34]和更复杂的卷积形式[70,18,84]的使用。随着CNN作为各种视觉任务的骨干网络,这些架构进步已经带来了广泛提高整个领域的性能改进。另一方面,自然语言处理(NLP)中的网络架构演变经历了不同的路径,今天普遍的架构是Transformer [64]。Transformer专为序列建模和变换任务设计,其注意力机制可以对数据中的长距离依赖进行建模。它在语言领域的巨大成功促使研究人员研究其在计算机视觉中的适应性,在某些任务中最近展示了有希望的结果,特别是图像分类[20]和联合视觉语言建模[47]。
"Transformer efficient in handling high-resolution images.' 在本文中,我们试图扩展Transformer的适用性,使其能够像NLP一样为计算机视觉提供通用骨干支持,就像CNN在视觉中做的那样。我们观察到,在将其在语言领域的高性能转移到视觉领域方面存在重大挑战,这可以通过两种模式的差异来解释。其中之一是规模的差异。不像在语言Transformer中用作处理基本元素的单词标记,视觉元素可以在规模上大相径庭,这是在任务如目标检测中得到关注的问题。在现有的基于Transformer的模型中,标记都是固定规模的属性,这对于这些视觉应用是不合适的。另一个差异是图像中像素的分辨率比文本段落中的单词高得多。存在许多视觉任务(例如语义分割),需要在像素级进行密集预测,这对于高分辨率图像上的Transformer来说是不可行的,因为其自我关注的计算复杂性与图像大小的平方成正比。为了克服这些问题,我们提出了一个通用的Transformer骨干,称为Swin Transformer,它构建了分层特征图,并具有图像大小的线性计算复杂性。如图1(a)所示,Swin Transformer通过从小的补丁(用灰色轮廓)开始并逐渐在更深的Transformer层中合并相邻的补丁来构建分层表示。有了这些分层特征图,Swin Transformer模型可以方便地利用用于密集预测的先进技术,如特征金字塔网络(FPN)[42]或U-Net [51]。通过在非重叠窗口内计算自我注意力来实现线性计算复杂度,这些窗口将图像分成分区(用红线轮廓)。每个窗口中的补丁数量是固定的,因此复杂度与图像大小成线性关系。这些优点使Swin Transformer在处理高分辨率图像方面非常有效。
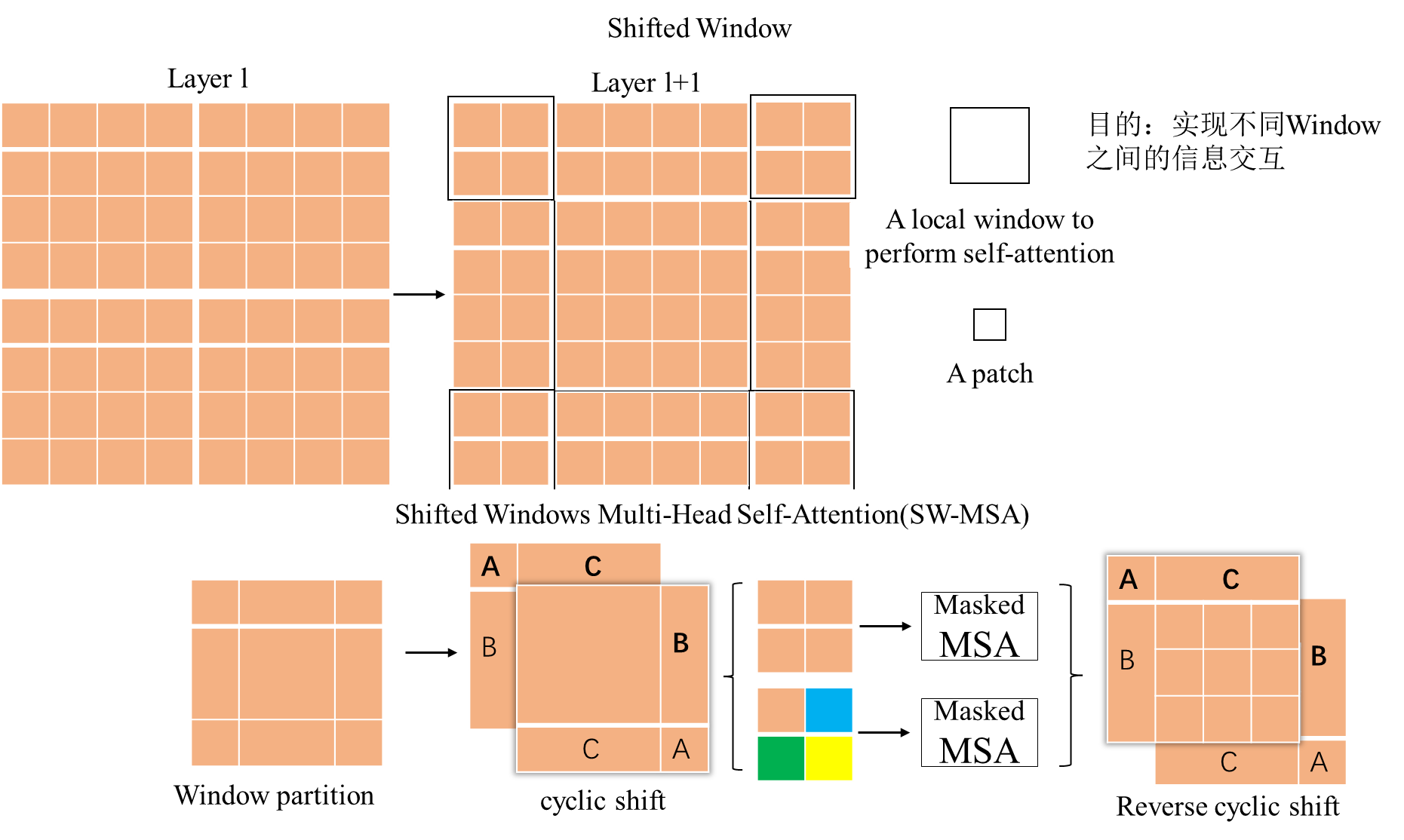
Swin Transformer的一个关键设计元素是其在连续的自注意力层之间移动窗口划分,如图2所示。移动的窗口桥接了前一层的窗口,提供了它们之间的连接,显著增强了建模能力(参见表4)。这种策略在实际世界的延迟方面也非常有效:窗口内的所有查询补丁共享相同的键集1,这有助于硬件中的内存访问。相比之下,早期基于滑动窗口的自注意力方法[33,50]由于不同查询像素的不同键集,在一般硬件上存在较低的延迟。我们的实验表明,所提出的移动窗口方法比滑动窗口方法具有更低的延迟,但建模能力相似(参见表5和表6)。移动窗口方法也对所有MLP架构[61]有益。
所提出的Swin Transformer在图像分类、目标检测和语义分割的识别任务上都取得了强大的表现。在三个任务上,它表现优于ViT /DeiT模型[20,63]和ResNe(X)t模型[30,70],并具有相似的延迟。在COCO测试集上,它的盒子AP和掩模AP分别为58.7和51.1,超过了以前的最新结果,盒子AP增加了2.7(Copy-paste [26]没有外部数据),而掩模AP增加了2.6(DetectoRS [46])。在ADE20K语义分割中,它在val集上获得了53.5 mIoU,较之前的最新成果(SETR [81])提高了3.2 mIoU。在ImageNet-1K的图像分类中,它也达到了87.3%的top-1准确率。我们相信,计算机视觉和自然语言处理领域的统一架构可以使两个领域受益,因为它将有助于视觉和文本信号的联合建模,两个领域的建模知识可以更深入地共享。我们希望Swin Transformer在各种视觉问题上的优异表现可以在社区中深化这种信念,并鼓励视觉和语言信号的统一建模。
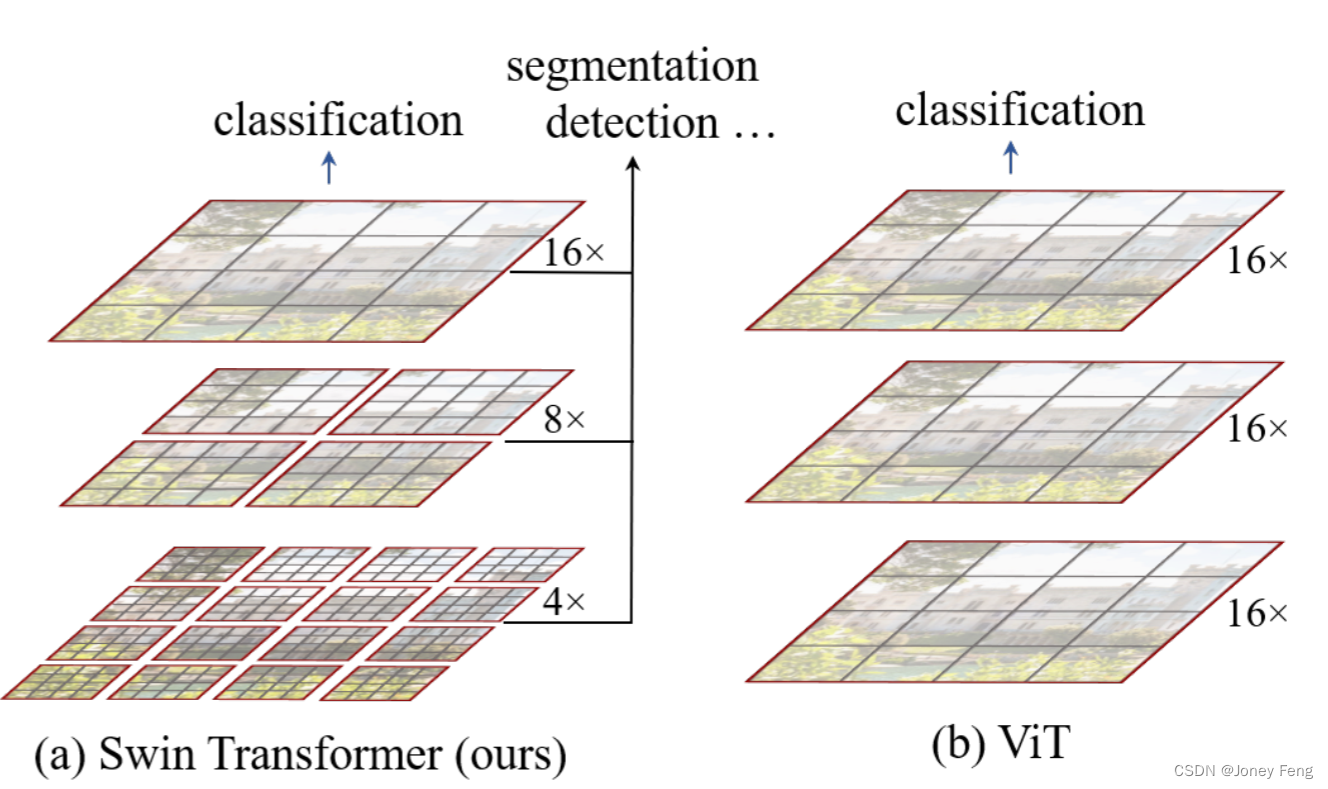
(图1.(a)所提出的Swin Transformer通过合并深层中的图像块(灰色部分),构建了分层的特征图,并由于仅在每个局部窗口(红色部分)内计算自注意力,因此具有线性计算复杂度,可用作图像分类和密集识别任务的通用骨干。(b)相比之下,之前的Vision Transformer [20]产生单个低分辨率的特征图,并且由于全局自注意力的计算而对输入图像大小具有二次计算复杂度)
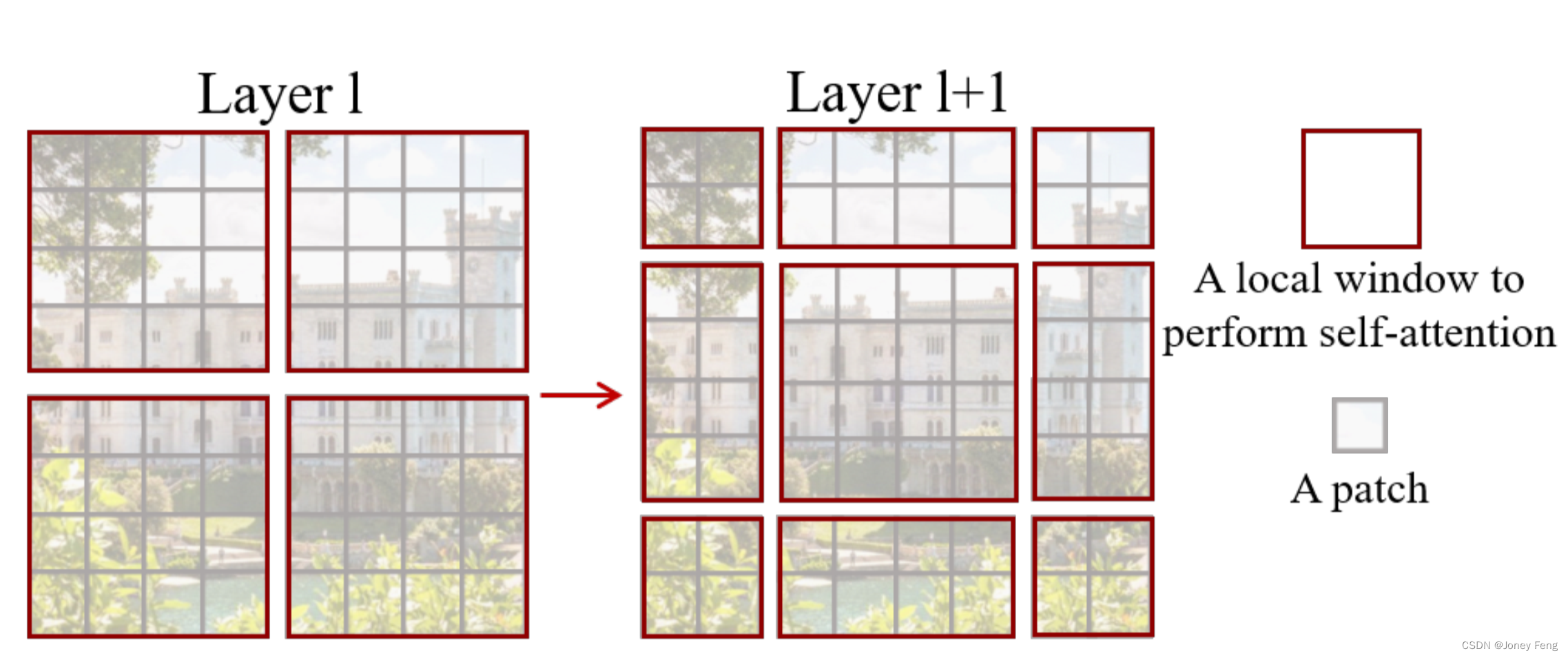
(图2.在提出的Swin Transformer体系结构中计算自注意力的移动窗口方法的图示。在层l(左侧),采用常规的窗口分割方案,在每个窗口内计算自注意力。在下一层l+1(右侧),窗口分割发生了移动,产生了新的窗口。新窗口中的自注意力计算跨越了层l中先前窗口的边界,提供了它们之间的连接)
2.正文分析
2相关工作
卷积神经网络(CNN)和其变体被广泛应用于计算机视觉的标准网络模型。尽管 CNN 已经存在了几十年 [40],但直到 AlexNet [39] 的引入,CNN 才开始流行起来。此后,一些更深层次和更有效的卷积神经网络架构被提出,进一步推动了计算机视觉中深度学习浪潮的发展,例如 VGG [52]、GoogleNet [57]、ResNet [30]、DenseNet [34]、HRNet [65] 和 EfficientNet [58] 等。除了这些架构上的进展之外,还有很多工作致力于改进单个卷积层,比如深度卷积 [70] 和可变形卷积 [18, 84]。虽然 CNN 及其变体仍然是计算机视觉应用中的主要骨干架构,但我们强调 Transformer 等架构在视觉和语言之间实现统一建模的巨大潜力。我们的工作在几个基本的视觉识别任务上取得了强大的表现,我们希望它能促进建模的转变。
自注意力骨干架构。
在NLP领域中,由于自注意力层和Transformer架构的成功,一些研究采用自注意力层替换一些或所有流行的ResNet卷积层[33,50,80]。在这些研究中,自注意力在每个像素的局部窗口内计算以加快优化[33],并且它们实现了略微更好的精度/ FLOPs权衡比对应的ResNet架构。但是,它们昂贵的内存访问导致它们的实际延迟显着大于卷积网络[33]。我们提出在连续层之间移动窗口,这允许在通用硬件上实现更高效。
自注意力/Transformer来补充卷积神经网络
另一条路线是通过添加自注意力层或变压器来增强标准的CNN架构。自注意力层可以通过提供编码远程依赖或异构交互的功能来补充骨干网络[67,7,3,71,23,74,55]或头网络[32,27]。更近期地,编码器-解码器设计中的Transformer已被应用于目标检测和实例分割任务[8,13,85,56]。我们的工作探索了将Transformer适应于基本的视觉特征提取,并且与这些工作是互补的。
基于Transfoemer的视觉骨架
最与我们的工作相关的是Vision Transformer(ViT)[20]及其后续工作[63、72、15、28、66]。ViT的开创性工作直接将变形金刚架构应用于非重叠的中等大小图像块以进行图像分类。相比卷积网络,它在图像分类上实现了令人印象深刻的速度-精度权衡。虽然ViT需要大规模的训练数据集(即JFT-300M)才能表现良好,但DeiT [63]引入了几种训练策略,使得ViT在使用较小的ImageNet-1K数据集时也能够有效。ViT在图像分类上的结果令人鼓舞,但是由于其分辨率较低的特征映射以及随着图像尺寸的增加呈二次增加的复杂性,其架构不适用于用作密集视觉任务的通用骨干网络或当输入图像分辨率较高时。有一些工作将ViT模型应用于对象检测和语义分割的密集视觉任务中,通过直接上采样或反卷积,但性能相对较低[2、81]。与我们的工作同时进行的一些工作对ViT架构进行了修改,以实现更好的图像分类结果。从经验上讲,我们发现我们的Swin Transformer架构在这些方法中实现了最佳的速度-精度权衡,即使我们的工作重点是通用性能而不是特定的分类。另一项同时进行的工作[66]探索了在变形Transformer上构建多分辨率特征映射的类似思路。它的复杂性仍然是随图像大小而呈二次增加的,而我们的复杂性是线性的,并且还是局部操作的,已被证明对建模视觉信号的高相关性有益[36、25、41]。我们的方法既高效又有效,在COCO对象检测和ADE20K语义分割方面实现了最先进的准确性。
3.方法
3.1.总体结构
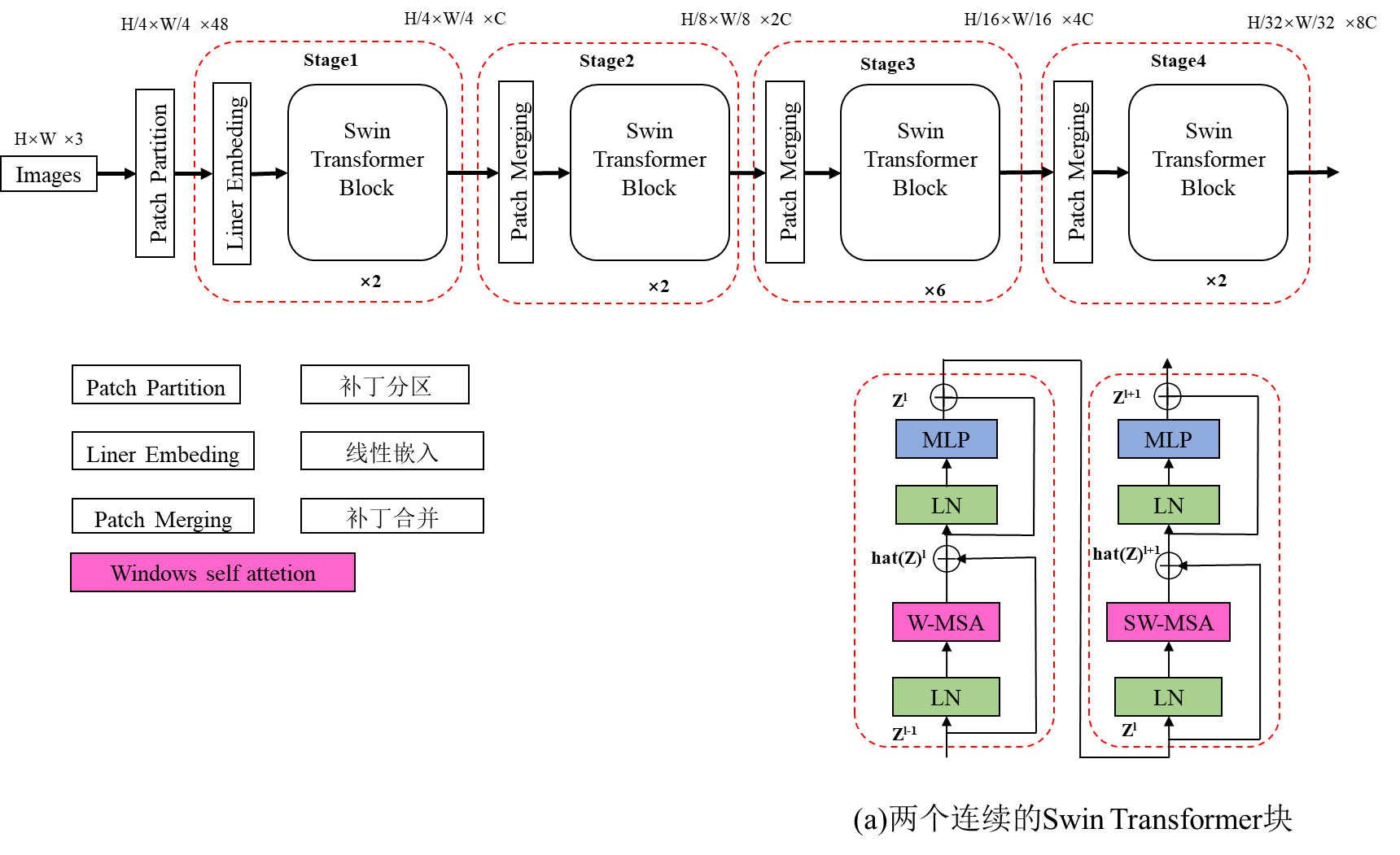
Swin Transformer 的总体结构概述如图 3 所示,展示了微型版本(SwinT)。它首先通过补丁分割模块(例如 ViT)将输入的 RGB 图像分割成不重叠的补丁。每个补丁被视为一个“令牌”,其特征被设置为原始像素 RGB 值的连接。在我们的实现中,我们使用 4×4 的补丁大小,因此每个补丁的特征维度为 4×4×3=48。在这个原始值特征上应用线性嵌入层,将其投影到任意维度(表示为 C)。这些补丁令牌上应用几个具有修改的自我关注计算的 Transformer 块(Swin Transformer 块)。Transformer 块保持令牌数量(H×W),以及与线性嵌入一起被称为“第一阶段”。
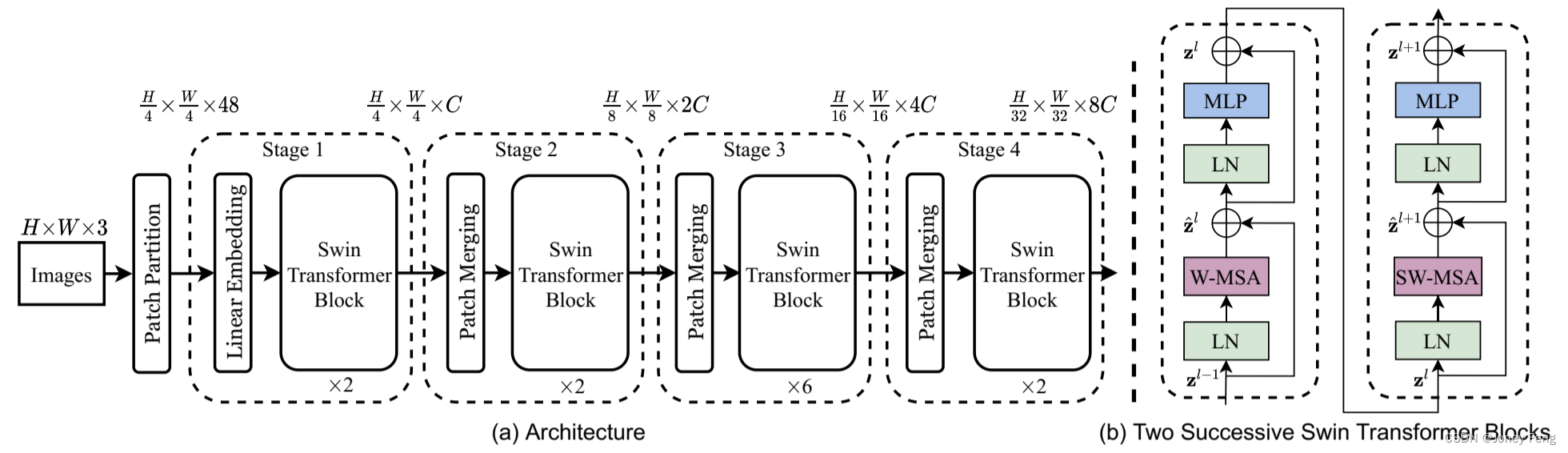
(图3.(a)Swin Transformer(Swin-T)的架构;(b)两个连续的Swin Transformer块(使用公式(3)表示符号)。W-MSA和SW-MSA是具有常规和移位窗口配置的多头自注意力模块)
Swin Transformer模块.Swin Transformer是通过将Transformer块中的标准多头自注意(MSA)模块替换为基于移位窗口的模块(在第3.2节中描述),并保持其他层不变来构建的。如图3(b)所示,Swin Transformer模块由基于移位窗口的MSA模块组成,后跟一个2层MLP,中间使用GELU非线性激活函数。在每个MSA模块和每个MLP之前应用LayerNorm(LN)层,并在每个模块之后应用剩余连接。
3.2. 移动窗口自注意力机制
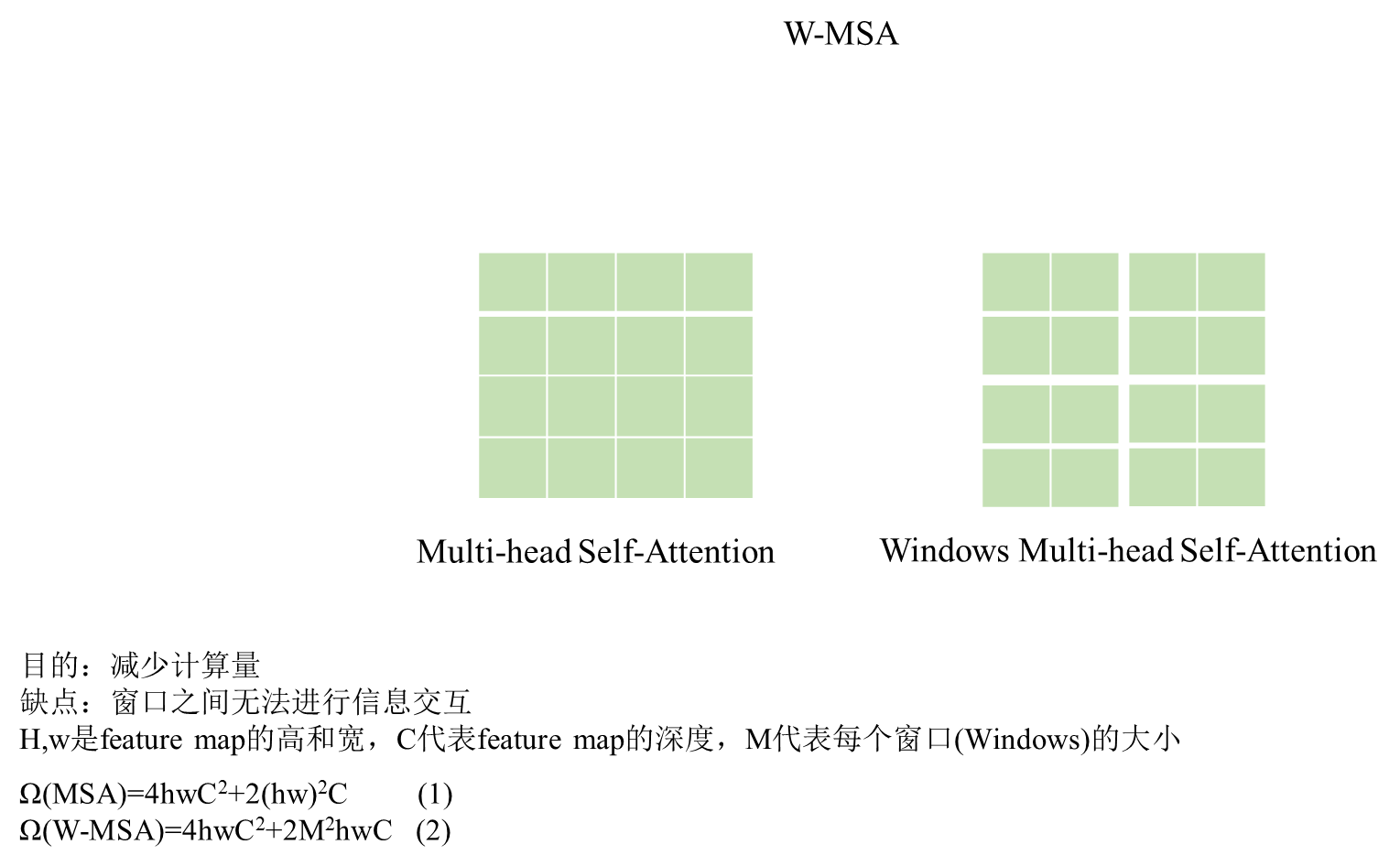
标准的Transformer架构[64]以及其适用于图像分类[20]的改进都使用全局自注意力机制,其中计算每个标记与所有其他标记之间的关系。全局计算会导致与标记数呈二次复杂度相关的计算量,这使得它对于许多需要用大量标记进行密集预测或表示高分辨率图像的视觉问题不适用。为了有效建模,我们提出在局部窗口内计算自注意力。这些窗口被布置为以不重叠的方式平均分割图像。假设每个窗口包含M×M个补丁,则在h×w个补丁的图像上计算全局多头自注意力模块(MSA)和基于窗口的模块的计算复杂度分别为: Ω(MSA)=4hwC2+2(hw)2C; (1) Ω(W-MSA)=4hwC2+2M2hwC; (2)<br>其中前者与补丁数hw的平方成二次复杂度相关,后者则在M固定时(默认为7)与补丁数hw成线性复杂度相关。对于大量补丁数hw,全局自注意力计算通常是无法承受的,而基于窗口的自注意力是可扩展的。
在连续的块中进行移位窗口划分 基于窗口的自注意力模块缺乏窗口间的连接,这限制了其建模能力。为了在保持非重叠窗口高效计算的同时引入窗口间的连接,我们提出了一种移位窗口划分方法,该方法在连续的Swin Transformer块中交替使用两种划分配置。如图2所示,第一个模块使用常规的窗口划分策略,从左上像素开始,将8×8的特征图均匀划分为2×2的大小为4×4(M = 4)的窗口。然后,下一个模块采用一个从前一层偏移的窗口配置,通过将窗口从常规划分的窗口移位bM2c;bM2c像素来实现。通过移位窗口划分方法,连续的Swin Transformer块按如下方式计算z ^ l = W-MSALN zl−1+ zl−1; zl = MLPLN z ^ l + z ^ l; z ^l+1 = SW-MSA LN zl + zl; zl+1 = MLP LN z ^ l+1 + z ^ l+1;(3)其中 z ^ l 和 zl 分别表示块l的(S)WMSA模块和MLP模块的输出特征;W-MSA和SW-MSA分别表示使用常规和移位窗口划分配置的基于窗口的多头自我注意力。移位窗口划分方法引入了相邻非重叠窗口的连接,在图像分类、目标检测和语义分割中被发现是有效的,如表4所示。
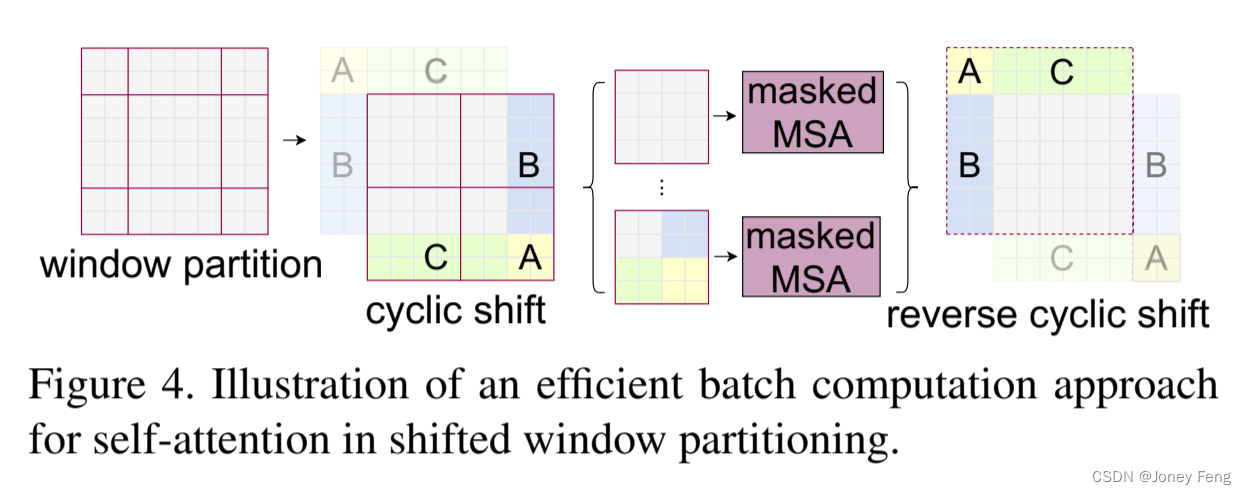
(图4.自注意力中移位窗口分区的高效批处理计算方法的示意图)
为了实现平移配置的高效批处理计算,平移窗口分区存在一个问题,那就是将生成更多的窗口,从dMhe ×dMwe到(dMhe+1)×(dMwe+1),而其中一些窗口的大小将小于M×M4。一种朴素的解决方案是将较小的窗口填充到M×M的大小,并在计算注意力时屏蔽填充值。当常规分区中的窗口数较少时,例如2×2,这种朴素解决方案将导致计算量的增加相当大(从2×2到3×3,增加了2.25倍)。因此,我们提出了一种更为高效的批处理计算方法,通过向左上方循环移位,如图4所示。通过此位移,一个批量窗口可能由多个在特征图中不相邻的子窗口组成,因此使用遮罩机制将自我关注计算限制在每个子窗口内。通过循环位移,批量窗口的数量保持与常规窗口分区相同,因此也是高效的。此方法的低延迟在表5中展示。
在计算自注意力时,我们遵循[49,1,32,33],通过为每个头部计算相似性时包含相对位置偏差 B2RM2×M2:Attention(Q;K;V)=SoftMax(QKT=pd+B)V;(4)其中 Q;K;V 2RM2×d 是查询、键和值矩阵;d 是查询/键维度;M2 是窗口中补丁的数量。由于每个轴上的相对位置在范围[−M +1;M−1]内,我们将一个更小尺寸的偏差矩阵 B^2R(2M−1)×(2M−1) 参数化,B 中的值取自 B^。我们发现,相对于没有这个偏差项或使用绝对位置嵌入的对照方法,使用学习到的相对位置偏差可以显著提高性能,如表 4 所示。在输入中进一步添加绝对位置嵌入,如 [20] 中所示,会略微降低性能,因此没有采用。预训练中学习到的相对位置偏差还可通过双三次插值[20,63]用于初始化具有不同窗口大小的模型的微调。
3.3.架构变体我们构建了 Swin-B 作为基本模型,其模型大小和计算复杂度与 ViTB/DeiT-B 类似。我们还引入了 Swin-T、Swin-S 和 Swin-L,它们是大小约为基本模型 0.25×、0.5× 和 2× 的版本。请注意,Swin-T 和 Swin-S 的复杂度类似于 ResNet-50(DeiT-S) 和 ResNet-101。默认情况下,窗口大小设置为 M=7。每个头部的查询维度为 d=32,每个 MLP 的扩展层为 α=4,对于所有实验,这些模型变体的架构超参数为:• Swin-T:C=96,层数=f2;2;6;2g [...]
4.实验 我们在ImageNet-1K图像分类[19]、COCO目标检测[43]和ADE20K语义分割[83]上进行实验。接下来,我们首先将所提出的Swin Transformer架构与前文提到的三个任务的最新技术进行比较。然后,我们对Swin Transformer的重要设计元素进行研究。
4.1.在ImageNet-1K上进行图像分类 测试设置:对于图像分类,我们在ImageNet-1K [19]上对所提出的Swin Transformer进行基准测试,其中包含来自1,000个类别的1.28M训练图像和50K验证图像。采用单个剪裁的top-1精度进行报告。我们考虑两个训练设置:
•常规的ImageNet-1K训练。这个设置主要遵循[63]。我们使用AdamW [37]优化器进行300个epoch的训练,使用余弦衰减学习率调度程序和20个epoch的线性热身。使用一个batch size为1024,一个初始学习率为0.001,一个权重衰减为0.05。我们在训练中包括[63]的大多数增强和正则化策略,除了重复增强[31]和EMA [45],它们不会增强性能。请注意,这与[63]相反,其中重复增强对于稳定ViT的训练至关重要。 •在ImageNet-22K上预训练并在ImageNet-1K上微调。我们还在更大的ImageNet-22K数据集上进行预训练,该数据集包含1420万张图片和22K个类别。我们使用AdamW优化器进行90个epochs的训练,并使用5个epoch的线性热身的线性衰减学习率调度程序。使用一个batch size为4096,一个初始学习率为0.001,一个权重衰减为0.01。在ImageNet-1K微调中,我们使用batch size为1024,恒定学习率为10-5,权重衰减为10-8,对模型进行30个epoch的训练。
使用常规的ImageNet-1K训练的结果。表1(a)介绍了与其他主干(包括基于Transformer和ConvNet的)使用常规ImageNet-1K训练的比较。与先前最先进的基于Transformer的结构DeiT [63]相比,Swin Transformers在复杂度相似的情况下显着超越了DeiT架构:在2242输入下,Swin-T(81.3%)比DeiT-S(79.8%)高1.5%,在2242/3842输入下,Swin-B(83.3%/84.5%)比DeiT-B(81.8%/83.1%)分别高1.5%/1.4%。与最先进的ConvNets RegNet [48]和EfficientNet [58]相比,Swin Transformer实现了略微更好的速度和准确度折衷。需要注意的是,虽然RegNet [48]和EfficientNet [58]是通过全面的体系结构搜索获得的,但所提出的Swin Transformer是从标准Transformer中适应并具有进一步提高的强大潜力。
基于ImageNet-22K预训练的结果:我们还在ImageNet-22K上对更大容量的Swin-B和Swin-L进行了预训练。在ImageNet-1K图像分类上进行微调的结果显示在表1(b)中。对于Swin-B,ImageNet-22K预训练相较于从头开始训练的ImageNet-1K能获得1.8%∼1.9%的增益。与ImageNet-22K预训练的最佳结果相比,我们的模型在速度和准确性之间实现了明显更好的平衡:Swin-B获得了86.4%的top-1准确率,比有类似推理吞吐量的ViT高出了2.4%(84.7 vs. 85.9 张/秒),并且略低的FLOPs(47.0G vs.55.4G)。更大的Swin-L模型的top-1准确率达到了87.3%,比Swin-B模型高0.9%。
我们将我们的Swin Transformer与标准的Con-vNets(例如ResNe(X)t)和以前的Transformer网络(例如DeiT)进行比较。比较是通过仅更改骨干网络,保持其他设置不变来进行的。需要注意的是,由于Swin Transformer和ResNe(X)t具有分层特征图,因此它们可以直接适用于上述所有框架,而DeiT仅产生单一分辨率的特征图,不能直接应用。为了公平比较,我们遵循[81]使用反卷积层构建DeiT的分层特征图。与ResNe(X)t的比较表2(a)列出了Swin-T和ResNet-50在四个物体检测框架上的结果。我们的Swin-T架构相对于ResNet-50带来了一致的+3.4∼4.2盒AP增益,略大的模型大小、FLOPs和延迟。表2(b)比较了Swin Transformer和ResNe(X)t在不同模型容量下使用级联掩模RCNN。Swin Transformer实现了高达51.9的盒子AP和45.0的掩模AP的高检测精度,这是相对于类似的模型大小、FLOPs和延迟的ResNeXt101-64x4d而言的重大增益,增益值为+3.6盒AP和+3.3掩模AP。在改进的HTC框架上使用更高的基准线52.3盒AP和46.0掩模AP时,Swin Transformer的增益也很高,为+4.1盒AP和+3.1掩模AP(见表2(c))。关于推断速度,虽然ResNe(X)t是由高度优化的Cudnn函数构建的,但我们的架构是使用内置的PyTorch函数实现的,这些函数并没有得到很好的优化。全面的内核优化超出了本文的范围。
4.3.ADE20K设置中的语义分割
ADE20K[83]是一个广泛使用的语义分割数据集,包含150种广泛范围的语义类别。它总共有2.5万张图像,其中2万张用于训练,2千张用于验证,另外3千张用于测试。我们使用mmseg[16]中的UperNet[69]作为我们的基础框架,因为它的高效性。更多细节请参见附录。结果表3列出了不同方法/骨干网络对的mIoU,模型大小(#param),FLOPs和FPS。从这些结果可以看出,与相似计算成本的DeiT-S相比,Swin-S的mIoU更高,达到了+5.3(49.3比44.0)。它还比ResNet-101高+4.4的mIoU,比ResNeSt-101 [78]高+2.4的mIoU。我们的Swin-L模型在ImageNet-22K预训练的情况下,在val集上达到了53.5 mIoU,超过了以前最好的模型+3.2 mIoU(由SETR[81]获得,该模型大小更大)。
4.4.消融试验
在本节中,我们将在ImageNet-1K图像分类,COCO目标检测的级联掩蔽R-CNN和ADE20K语义分割的UperNet上消除建议的Swin Transformer中的重要设计元素。移位窗口 移位窗口方法在三个任务上的消融结果见表4。在ImageNet-1K上,使用移位窗口划分的Swin-T在每个阶段顶部1精度上比单窗口划分构建的对应物高出1.1%,在COCO上的框AP /面膜AP上高出2.8/2.2,在ADE20K上高出2.8 mIoU。结果表明,使用移位窗口在前面的层之间建立连接是有效的。如表5所示,移位前的延迟开销也很小。相对位置偏差 表4显示了不同位置嵌入方法的比较。使用相对位置偏差的Swin-T相对于没有位置编码和使用绝对位置嵌入的模型,可以在ImageNet-1K上提高1.2%/ 0.8%的顶部1精度,在COCO上提高了1.3 / 1.5框AP和1.1 / 1.3面膜AP,并在ADE20K上提高了2.3 / 2.9 mIoU。结果表明,相对位置偏差是有效的。此外,需要注意的是,尽管包括绝对位置嵌入可以提高图像分类的准确性(+0.4%),但它会损害目标检测和语义分割(COCO上的0.2框/面膜AP和ADE20K上的0.6mIoU)。尽管最近的ViT / DeiT模型在图像分类中放弃了平移不变性,尽管长期以来已经显示它对于视觉建模非常重要,但我们发现鼓励某种平移不变性的归纳偏差对于通用视觉建模仍然是可取的,特别是在目标检测和语义分割的密集预测任务中更是如此。
不同的自注意力方法在表5中比较了不同自注意力计算方法和实现的实际速度。我们的循环实现比朴素填充更具硬件效率,特别是在更深的阶段。总体而言,在Swin-T、Swin-S和Swin-B中,它们分别带来了13%、18%和18%的加速。基于提出的移位窗口方法构建的自注意模块在四个网络阶段上,比在朴素/内核实现上滑动窗口的方法高出40.8×/2.5×、20.2×/2.5×、9.3×/2.1×和7.6×/1.8×的效率。总体而言,基于移位窗口构建的Swin Transformer架构在Swin-T、Swin-S和Swin-B中比滑动窗口的变体快4.1/1.5、4.0/1.5、3.6/1.5倍,分别在表格6中比较了它们在三个任务中的准确性,显示它们在视觉建模中的准确性相似。与Performer [14]相比,它是最快的Transformer架构之一(见[60]),所提出的基于移位窗口的自注意力计算和整体Swin Transformer架构略快(见表5),同时在使用Swin-T进行ImageNet-1K时,相较于Performer达到+2.3%的top-1精度(见表6)。
---------------------------------------------------------------------------------------------------------------------------------
A1.详细架构
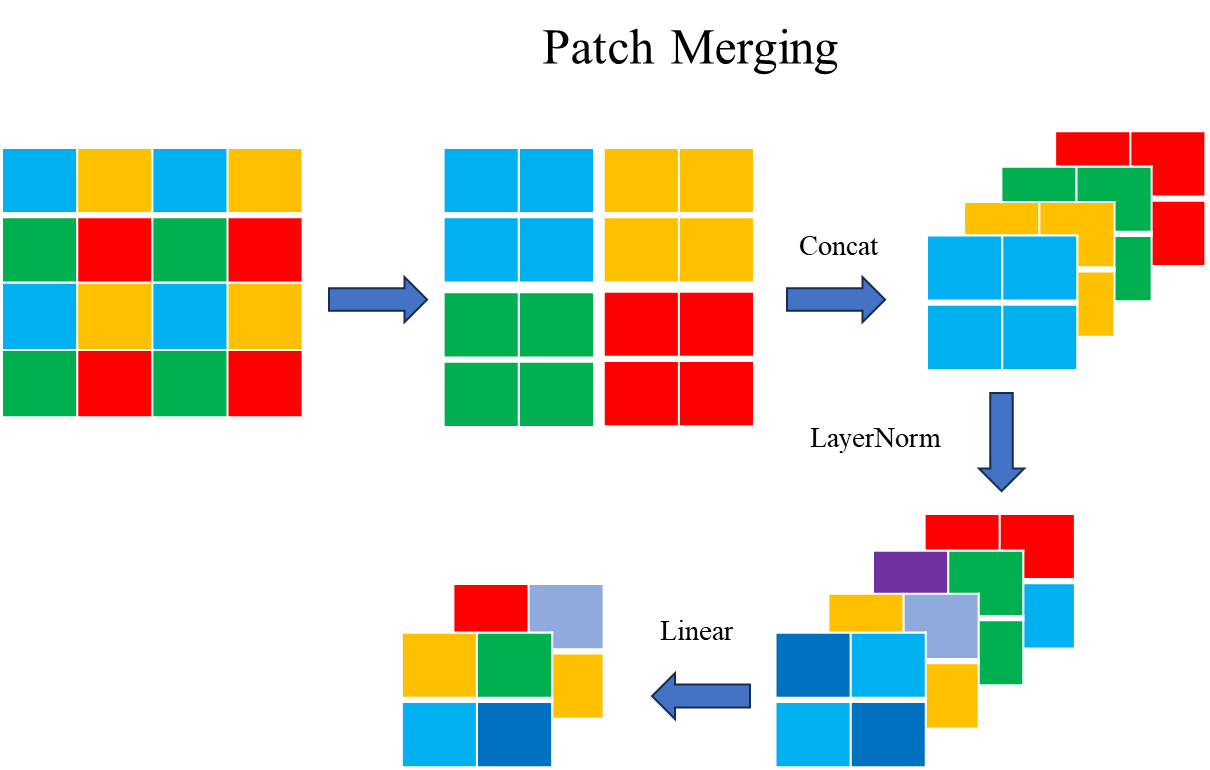
规范详见表7,所有架构都假定输入图像尺寸为224×224。“Concat n ×n”表示合并n×n个相邻特征到一块,这个操作导致特征映射以n的速率降采样。“96-d”表示具有96个输出维度的线性层。“win.sz.7 ×7”表示窗口大小为7×7的多头自注意力模块。
A2.详细实验设置
A2.1.在ImageNet-1K上进行图像分类 图像分类通过在最后一个阶段的输出特征映射上应用全局平均池化层,然后接一个线性分类器来执行。我们发现这种策略与使用ViT [20]和DeiT [63]中的额外类记号一样准确。在评估中,使用单个裁剪报告top-1准确性。 常规ImageNet-1K训练 训练设置主要遵循[63]。对于所有模型变体,我们采用默认的输入图像分辨率2242。对于其他分辨率,例如3842,我们微调以2242分辨率训练的模型,而不是从头开始训练,以减少GPU消耗。
当使用2242输入从头开始训练时,我们使用AdamW [37]优化器进行300次迭代,使用余弦衰减学习率调度器,其中包括20个线性预热周期。使用批量大小为1024,初始学习率为0.001,权重衰减为0.05,最大范数为1的梯度剪裁。我们在训练中包括[63]的大多数增强和正则化策略,包括RandAugment [17]、Mixup [77]、Cutmix [75]、随机擦除 [82]和随机深度 [35],但不包括重复增强 [31]和指数移动平均(EMA)[45],因为它们不能增强性能。注意,这与ViT的训练稳定性密切相关的[63]不同。对于更大的模型,我们采用逐渐增加的随机深度增强,即Swin-T、Swin-S和Swin-B的值分别为0.2、0.3和0.5。对于在输入分辨率更大的情况下的微调,我们使用AdamW [37]优化器进行30次迭代,使用恒定的学习率10−5,权重衰减为10−8,以及与第一阶段相同的数据增强和正则化,除了随机深度的比率设为0.1。ImageNet-22K预训练:我们还对更大的ImageNet-22K数据集进行了预训练,该数据集包含1420万张图像和22K个类别。训练分两个阶段完成。对于第一个阶段采用2242输入,我们使用AdamW优化器进行90次迭代,使用线性衰减学习率调度器,其中包括5个线性预热周期。批量大小为4096,初始学习率为0.001,权重衰减为0.01。在ImageNet-1K微调的第二个阶段,采用2242/3842输入,我们将模型训练30次,批量大小为1024,恒定学习率为10−5,权重衰减为10−8。
'A2.2. COCO 数据集上的目标检测。
为了进行一项消融研究,我们考虑了四种典型的目标检测框架:Cascade Mask R-CNN [29,6]、ATSS [79]、RepPoints v2 [12] 和 Sparse RCNN [56] 在 mmdetection [10] 中。对于这四个框架,我们采用相同的设置:多尺度训练 [8,56](将输入的短边调整为 480 至 800 之间,长边最多为 1333),AdamW [44] 优化器(初始学习率为 0.0001,权重衰减为 0.05,批量大小为 16),以及 3x 日程表(36 个纪元,学习率在第 27 和第 33 个纪元时下降 10 倍)。对于系统级比较,我们采用改进的 HTC [9](标记为 HTC++),并使用 instaboost [22]、更强的多尺度训练 [7] (将输入的短边调整为 400 至 1400 之间,长边最多为 1600),6x 日程表(72 个纪元,学习率在第 63 和第 69 个纪元时以 0.1 为因子下降),softNMS [5],以及附加在最后阶段输出处的额外全局自注意层和 ImageNet-22K 预训练模型作为初始化。我们对所有 Swin Transformer 模型采用 0:2 的随机深度比率。'
'A2.3.ADE20K上的语义分割
ADE20K [83]是一个广泛使用的语义分割数据集,涵盖了150个语义类别。总共有25K个图像,其中20K用于训练,2K用于验证,另外3K用于测试。我们利用mmsegmentation [16]中的UperNet [69]作为基础框架,因为它具有高效率。在训练中,我们采用AdamW [44]优化器,初始学习率为6 x 10−5,权重衰减为0.01,采用线性学习率衰减的调度器,线性热身1,500次迭代。模型在8个GPU上训练,每个GPU有2个图像,总共进行160K次迭代。对于增强,我们采用mmsegmentation中的默认设置,如随机水平翻转,随机比例调整[0.5,2.0]和随机光度失真。对于所有Swin Transformer模型,采用比率为0.2的随机深度。Swin-T、Swin-S采用512×512的标准设置进行训练。Swin-B和Swin-L带有z表示这两个模型在ImageNet-22K上进行了预训练,并以640×640的输入进行训练。在推理中,采用多尺度测试,使用与训练的分辨率比例为[0.5,0.75,1.0,1.25,1.5,1.75]的分辨率。在报告测试分数时,遵循常用做法[71],同时使用训练图像和验证图像进行训练。'
A3.更多实验
A3.1.使用不同输入尺寸的图像分类表8列出了使用2242至3842不同输入图像尺寸的Swin Transformer的表现。一般而言,较大的输入分辨率可以获得更好的top-1准确率,但推理速度较慢。
A3.2. COCO上ResNe(X)t的不同优化器
表9比较了ResNe(X)t骨干网络在COCO对象检测中AdamW和SGD优化器的性能。比较使用了级联掩膜R-CNN框架。尽管SGD通常在级联掩膜R-CNN框架中作为默认优化器使用,但我们通常会发现通过将其替换为AdamW优化器可以提高精度,尤其是对于较小的骨干网络。因此,与提出的Swin Transformer架构相比,我们在ResNe(X)t骨干网络中使用AdamW。
A3.3. Swin MLP-Mixer
我们将所提出的分层设计和移位窗口方法应用于MLP-Mixer架构 [61],并称为Swin-Mixer。表10显示了Swin-Mixer与原始MLPMixer架构MLP-Mixer [61]和后继方法ResMLP [61]的性能对比。Swin-Mixer使用略小的计算预算(10.4G vs. 12.7G)比MLP-Mixer表现显著更好(81.3% vs. 76.4%)。与ResMLP [62]相比,它还具有更好的速度精度平衡。这些结果表明所提出的分层设计和移位窗口方法是通用的。
总结
结论
本文介绍了 Swin Transformer,一种新型的 Vision Transformer,能够生成分层的特征表示,并且在输入图像大小方面具有线性计算复杂度。Swin Transformer 在 COCO 目标检测和 ADE20K 语义分割方面实现了最先进的表现,明显超越了之前的最佳方法。我们希望 Swin Transformer 在不同的视觉问题上强大的表现能够促进视觉和语言信号的统一建模。作为 Swin Transformer 的关键元素,基于偏移窗口的自注意力在视觉问题上被证明是有效和高效的,我们期待探索它在自然语言处理中的应用。