Linux中断处理中的workqueue介绍
- 一、workqueue的作用及在Linux中断处理中的应用
- 1.1、workqueue的概述
- 1.2、workqueue在Linux中断处理中的作用
- 二、workqueue的实现原理
- 2.1、工作队列和工作者线程的关系
- 2.2、工作队列的创建和销毁
- 2.3、工作者线程的创建和销毁
- 2.4、扩展知识:用户态线程的创建
- 2.5、工作者线程如何执行工作队列中的任务
- 三、workqueue的使用方法
- 四、实例分析: 使用workqueue处理网络中断
- 五、workqueue的优缺点对比
- 5.1、优缺点
- 5.2、与tasklet的比较
- 六、总结
一、workqueue的作用及在Linux中断处理中的应用
1.1、workqueue的概述
Linux工作队列(Workqueue)是一个内核中的机制,它可以异步执行一些任务。在Linux内核中,当需要处理一些不是紧急的、需要后台执行的任务时,就会将这些任务加入到工作队列中,然后由内核计划适当的时间来执行这些任务。
工作队列的特点是异步执行,即任务的执行不会阻塞当前进程,而是交给后台线程进行处理。这种方式可以避免阻塞主线程,提高系统的响应速度和并发能力。
工作队列具有多种使用场景,比如定时器事件、网络I/O事件、驱动程序事件等,都可以通过工作队列来异步处理。
1.2、workqueue在Linux中断处理中的作用
workqueue是一种异步执行工作的机制,它可以在Linux中断处理中使用。当内核需要异步执行某些任务时,可以使用workqueue机制。
在Linux中断处理中,有些操作不能直接执行,因为它们可能会阻塞中断处理程序。例如,如果一个中断处理程序需要访问磁盘,那么它可能需要等待磁盘访问完成才能继续执行,这将导致中断处理程序的延迟和性能下降。为了避免这种情况,可以使用workqueue机制。
workqueue机制允许中断处理程序将任务提交给工作队列,在稍后的时间异步执行。这样,中断处理程序可以立即返回,并且不会阻塞其他中断处理程序的执行。工作队列是一组线程,它们可以同时执行多个任务。当工作队列中有任务时,内核会自动调度线程来执行任务。
workqueue机制是一种非常有效的机制,可以帮助内核异步执行任务,提高系统的性能和可靠性。

二、workqueue的实现原理
workqueue通过使用worker线程池来执行延迟性任务,能够提高系统的吞吐量和响应速度,适用于需要进行异步任务调度的场景。
workqueue是Linux系统中用于实现异步任务调度的机制,它允许驱动程序和内核线程安排延迟执行的工作。
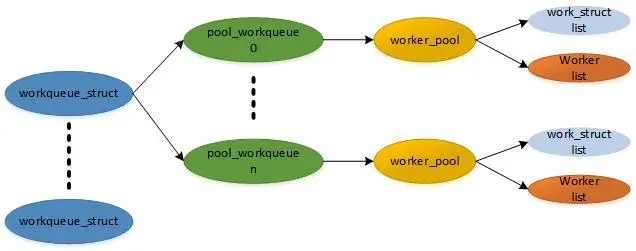
- workqueue由一个或多个worker线程池组成,每个worker线程都会不断地从workqueue中获取需要执行的工作项。
- 当驱动程序或内核模块需要执行一些延迟性的任务时,可以将这些任务封装成工作项(work)并添加到workqueue队列中。
- worker线程在空闲时,从workqueue队列中取出一个工作项,并将其放入自己的私有队列中,等待执行。
- 一旦worker线程完成当前正在执行的工作项,就会从自己的私有队列中取出下一个工作项进行处理。
- 若workqueue队列中没有可用的工作项,则worker线程会等待直到有新的工作项被添加到队列中。
- 在workqueue中,还提供了几种不同的队列类型,如普通队列、高优先级队列和延迟队列等,以满足不同场景下的需求。
2.1、工作队列和工作者线程的关系
工作队列和工作者线程是相互依存的关系,它们通过协同工作来处理系统中的任务。
工作队列是一个先进先出的任务列表,其中包含需要被执行的任务。工作者线程则是实际执行这些任务的线程。当有新的任务添加到工作队列中时,工作者线程会自动从队列中取出任务并执行。
工作者线程通常是由内核创建的,其数量可以根据系统负载情况进行调整。当任务数量增加时,可以增加工作者线程的数量以加快任务处理速度。而当任务数量减少时,可以减少工作者线程的数量以节省系统资源。
2.2、工作队列的创建和销毁
在Linux内核中,工作队列通过struct workqueue_struct结构体来表示。创建和销毁工作队列通常通过以下函数:
- 创建工作队列:create_workqueue(const char *name); 该函数创建并返回一个指向工作队列的指针。参数name是工作队列的名称。
- 销毁工作队列:destroy_workqueue(struct workqueue_struct *wq); 该函数销毁由指针wq所表示的工作队列。
例如,创建和销毁一个名为“my_work”的工作队列:
#include <linux/workqueue.h>
static struct workqueue_struct *my_wq;
static int __init my_module_init(void)
{
my_wq = create_workqueue("my_work");
if (!my_wq)
return -ENOMEM;
// ...
return 0;
}
static void __exit my_module_exit(void)
{
flush_workqueue(my_wq);
destroy_workqueue(my_wq);
// ...
}
module_init(my_module_init);
module_exit(my_module_exit);
2.3、工作者线程的创建和销毁
Linux 内核中的工作者线程是一种特殊的内核线程,用于执行一些异步的、需要花费较长时间或者需要消耗大量 CPU 资源的任务。它们主要用于处理 I/O 操作、网络操作、文件系统缓存等等。
在 Linux 内核中,工作者线程的创建和销毁是由系统自动管理的。当进程请求创建一个工作者线程时,内核会检查当前是否有可用的空闲线程。如果没有,则会创建一个新的线程。当任务完成后,工作者线程会被回收并返回到线程池中,以备下次使用。
为了提高效率,Linux 内核还可以在运行时动态地调整线程池中工作者线程的数量。当系统负载较高时,内核会增加线程池中的线程数量,以处理更多的任务。当负载降低时,内核会减少线程池中的线程数量,以节省资源。
例如,展示如何在 Linux 内核中创建和销毁工作者线程:
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/workqueue.h>
static struct workqueue_struct *my_wq;
typedef struct {
struct work_struct my_work;
int x;
} my_work_t;
static void my_work_handler(struct work_struct *work)
{
my_work_t *my_work = (my_work_t *)work;
printk(KERN_INFO "my_work_handler: x=%d\n", my_work->x);
kfree(my_work);
}
static int __init my_module_init(void)
{
my_work_t *my_work;
/* 创建工作者队列 */
my_wq = create_workqueue("my_queue");
if (!my_wq) {
printk(KERN_ERR "create_workqueue failed!\n");
return -1;
}
/* 创建并提交工作者线程 */
my_work = (my_work_t *)kmalloc(sizeof(my_work_t), GFP_KERNEL);
if (!my_work) {
printk(KERN_ERR "kmalloc failed!\n");
return -1;
}
INIT_WORK((struct work_struct *)my_work, my_work_handler);
my_work->x = 1;
queue_work(my_wq, (struct work_struct *)my_work);
return 0;
}
static void __exit my_module_exit(void)
{
/* 销毁工作者队列 */
flush_workqueue(my_wq);
destroy_workqueue(my_wq);
}
module_init(my_module_init);
module_exit(my_module_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Lion Long");
MODULE_DESCRIPTION("A simple example Linux module.");
例子展示了如何创建一个名为“my_queue”的工作者队列,然后创建一个工作者线程来处理一个名为“my_work”的工作对象。“my_work_handler”函数将打印出传递给工作对象的参数“x”,并释放工作对象的内存。在模块初始化期间,创建工作者队列和工作对象,并提交工作对象到队列中。在模块退出期间,销毁工作者队列。
Linux 内核中的工作者线程是一种非常重要的机制,能够显著提高系统的性能和响应速度。虽然用户无法直接控制工作者线程的创建和销毁,但可以通过一些系统调优技巧来优化工作者线程的使用效果。
2.4、扩展知识:用户态线程的创建
线程创建:
#include <pthread.h>
int pthread_create(pthread_t *thread, const pthread_attr_t *attr,
void *(*start_routine)(void*), void *arg);
该函数用于创建一个新的线程,并将其添加到调用进程中。参数 thread 是指向新线程标识符的指针,参数 attr 是指向线程属性的指针(通常为 NULL),参数 start_routine 是指向线程执行函数的指针,参数 arg 是传递给线程执行函数的参数。
线程销毁:
#include <pthread.h>
void pthread_exit(void *value_ptr);
该函数用于终止当前线程,并返回一个指针值。这个值可以由其他线程通过 pthread_join 函数获取,也可以被忽略。
#include <pthread.h>
int pthread_join(pthread_t thread, void **value_ptr);
该函数用于阻塞当前线程,直到指定的线程 thread 终止。如果指针 value_ptr 不为 NULL,则会将线程的返回值存储在 value_ptr 指向的位置中。
注意:如果线程没有被显式地分离,则它将一直存在于内存中,直到进程结束。因此,在创建线程时,应该考虑是否需要将它们分离或者等待它们的结束。
2.5、工作者线程如何执行工作队列中的任务
Linux 内核的工作者线程会在执行过程中不断地从工作队列中获取任务,并依次执行这些任务。当一个工作对象被提交到工作队列时,它会被添加到工作队列的末尾。工作者线程则会不断从队列的头部取出工作对象,并调用与之关联的处理函数来执行工作。
当工作者线程从工作队列中取出一个工作对象时,它会检查这个对象是否已经被取消或者延迟执行。如果该对象已被取消,则工作者线程会跳过该对象,继续获取下一个对象;如果该对象已被延迟执行,则工作者线程会将其重新添加到工作队列的尾部,以便在稍后重新执行。
值得注意的是,Linux 内核的工作者线程并不保证按照提交顺序依次执行工作对象。这意味着,如果您向工作队列中提交了多个工作对象,那么它们可能会以任意顺序被执行。因此,在编写使用工作者线程的内核代码时,需要注意任务之间的依赖关系,并确保它们能够正确地、无序地执行。
例如,用于向工作队列中添加任务:
#include <linux/workqueue.h>
// 定义工作队列对象
static struct workqueue_struct *my_workqueue;
// 定义工作处理函数
static void my_work_handler(struct work_struct *work) {
// 处理任务
printk(KERN_INFO "Task %d is being executed\n", *(int *)work->data);
msleep(1000);
printk(KERN_INFO "Task %d has completed\n", *(int *)work->data);
}
// 初始化模块
static int __init my_module_init(void) {
int i;
struct work_struct work[3];
// 创建工作队列
my_workqueue = create_singlethread_workqueue("my_workqueue");
// 添加任务到工作队列
for (i=0; i<3; i++) {
INIT_WORK(&work[i], my_work_handler);
work[i].data = &i;
queue_work(my_workqueue, &work[i]);
}
return 0;
}
// 清理模块
static void __exit my_module_exit(void) {
// 删除工作队列
flush_workqueue(my_workqueue);
destroy_workqueue(my_workqueue);
}
module_init(my_module_init);
module_exit(my_module_exit);
在上面的代码中,首先定义了一个工作队列对象my_workqueue,然后定义了一个工作处理函数my_work_handler,该函数会接收一个work_struct结构体指针作为参数。这个函数会输出任务编号、执行任务和任务完成等信息,并且通过msleep(1000)来模拟任务的执行时间。
在初始化模块时,创建了三个工作结构体work[3],并将它们添加到工作队列中。在每个工作结构体的数据字段中,使用指向任务编号的指针来标识每个任务。
最后,在清理模块时,通过调用flush_workqueue函数来确保所有任务都已经被执行完毕,然后再删除工作队列。
当这个内核模块加载到内核中时,它会自动运行并执行其中的代码。在执行过程中,每个任务会被分配给不同的工作者线程来执行,并且输出的信息将会显示在内核日志中。
三、workqueue的使用方法
- 创建工作队列。
- 将工作任务添加到队列中。
- 阻塞等待工作队列完成。
- 取消工作队列中的任务。
四、实例分析: 使用workqueue处理网络中断
处理网络中断时,可以使用workqueue来实现异步处理。
(1)定义一个work结构体,并在其中定义需要执行的回调函数。
struct work_struct my_work;
void my_work_func(struct work_struct *work) {
// 处理网络中断的逻辑代码
}
(2)在中断处理程序中初始化work结构体,并将其添加到workqueue中。
DECLARE_WORK(my_work, my_work_func);
irqreturn_t my_interrupt_handler(int irq, void *dev_id) {
// 中断处理程序的逻辑代码
if (is_network_interrupt()) {
schedule_work(&my_work); // 将work添加到workqueue中
}
return IRQ_HANDLED;
}
(3)定义一个workqueue,并绑定工作队列处理函数。
static struct workqueue_struct *my_wq;
void my_wq_func(struct work_struct *work) {
// 从work中获取需要执行的回调函数,并执行
struct work_struct *my_work = container_of(work, struct work_struct, entry);
my_work_func(my_work);
}
int init_module(void) {
// 初始化workqueue
my_wq = create_singlethread_workqueue("my_wq");
if (!my_wq) {
return -ENOMEM;
}
// 绑定工作队列处理函数
INIT_WORK(&my_work, my_wq_func);
return request_irq(...);
}
通过上述流程,就可以使用workqueue处理网络中断了。当网络中断触发时,中断处理程序会将work添加到workqueue中,然后立即返回,避免中断处理程序长时间阻塞。workqueue会在后台异步处理work,并执行回调函数处理网络中断的逻辑。
五、workqueue的优缺点对比
5.1、优缺点
优点:
- 提高系统的并发处理能力。
- 将操作系统内核和用户空间分离,减少了内核态和用户态之间的频繁切换。
- 让用户态可以访问操作系统内核中的数据结构,简化了驱动程序的开发难度。
- 提供了一个高效的异步通信机制。
缺点:
- 当任务队列阻塞时,可能会导致一些任务延迟执行。
- 无法保证任务的实时性,因为它们是异步执行的。
- 如果队列中的任务太多,可能会占用大量内存,影响系统的稳定性。
- 由于工作队列是内核级别的,因此在编写驱动程序时需要对其进行特殊处理。
5.2、与tasklet的比较
Workqueue和Tasklet都是Linux内核中的一种异步执行机制,但它们的实现方式和使用场景有所不同。
- 实现方式:Workqueue是基于软件IRQ(Interrupt Request)来实现的,而Tasklet是基于底半部处理程序(Bottom Half Handler)来实现的。
- 使用场景:Workqueue适用于需要长时间运行的任务,例如磁盘I/O,网络传输等;而Tasklet适用于需要快速响应的短时间任务,例如设备中断处理,定时器等。
- 调度方式:Workqueue由内核调度程序在后台管理,它们的调度是通过进程调度完成的;而Tasklet的调度则是立即发生的,因此可以更加紧凑地处理任务。
- 稳定性:Workqueue相对于Tasklet更稳定一些,因为它可以通过休眠来避免死锁和竞争条件的问题,而Tasklet则无法休眠。
- 可扩展性:Workqueue可以非常容易地扩展到多个CPU上并行执行,以提高系统的吞吐量;而Tasklet则只能在单个CPU上执行。
Workqueue和Tasklet都有各自的优点和缺点,选择何种机制取决于具体的需求和应用场景。
六、总结
(1)Workqueue是Linux内核中的一种任务调度机制,用于处理异步事件和并发任务。workqueue可以将需要执行的任务放入队列中,并等待系统空闲时进行调度和执行。
(2)在使用Workqueue时,需要注意以下几个问题:
- 内存泄漏:如果没有正确地释放Workqueue占用的内存,可能会导致内存泄漏。例如,在Workqueue中分配了内存,但在工作完成后没有及时释放。
- 并发问题:由于多个任务可以同时在Workqueue上运行,因此可能会出现并发问题,如竞争条件,死锁等。开发人员需要通过锁定机制或其他技术来解决这些问题。
- 优先级问题:根据任务的重要性和紧急程度,开发人员需要调整Workqueue任务的优先级,以确保最重要的任务首先得到执行。
- 性能问题:Workqueue本身也可能成为系统瓶颈,如果Workqueue被大量占用,则可能会对系统的性能产生负面影响。因此,开发人员需要仔细评估Workqueue的使用情况,并进行必要的优化。
- 内核版本问题:Workqueue的实现可能因Linux内核版本的不同而有所不同。因此,应用程序需要考虑自己所运行的内核版本,并相应地编写代码。
(3)workqueue可能会在更多的领域得到应用,例如云计算、人工智能、物联网等,以满足不同行业和领域的需求。