一、论文
- 研究领域:图像分割(3D)
- 论文:Segment Anything in 3D with NeRFs
- Submitted on 24 Apr 2023 (v1), last revised 1 Jun 2023 (this version, v3)
- Computer Vision and Pattern Recognition (cs.CV)
- nvos数据集
- 论文链接
二、论文概要
三、全文翻译
使用NeRFs在3D中分割任何内容
- 摘要
最近,Segment Anything Model(SAM)作为一种强大的视觉基础模型出现,它能够分割2D图像中的任何东西。本文的目的是推广SAM分割三维物体。我们设计了一种高效的解决方案,而不是复制3D中昂贵的数据采集和注释过程,利用神经辐射场(NeRF)作为将多视图2D图像连接到3D空间的廉价和现成的先验。我们将所提出的解决方案称为SA3D,即Segment Anything in 3D。只需要提供手动分割提示(例如,粗糙点),其用于在具有SAM的该视图中生成其2D掩模。接下来,SA3D交替地执行掩模逆绘制和跨视图自提示,以迭代地完成用体素网格构造的目标对象的3D掩模。前者在NeRF学习的密度分布的指导下,将SAM在当前视图中获得的2D掩模投影到3D掩模上;后者提取可靠的提示自动作为SAM的输入从NeRF渲染的2D掩模在另一个视图。我们在实验中表明,SA3D适应各种场景,并在几分钟内实现3D分割。我们的研究提供了一个通用的和有效的方法,以解除2D视觉基础模型到3D,只要2D模型可以稳定地解决提示分割跨多个视图。项目页面位于www.example.com。https://jumpat.github.io/SA3D/.
- 介绍
计算机视觉社区一直在追求可以执行基本任务(例如,在任何场景中并且对于2D或3D图像数据,可以使用图像分割(例如,图像分割)。最近,Segment Anything Model(SAM)[22]出现并吸引了很多关注,因为它能够分割2D图像中的任何东西,但将SAM的能力推广到3D场景仍然大多数未被发现。人们可以选择复制SAM的流水线来收集和半自动注释一大组3D场景,但昂贵的负担似乎是大多数研究小组负担不起的。
选择复制SAM的流水线来收集和半自动注释一大组3D场景,但昂贵的负担似乎是大多数研究小组负担不起的
我们认识到,替代且有效的解决方案在于装备2D基础模型(即,SAM)通过3D表示模型与3D感知进行对比。换句话说,不需要从头建立3D基础模型。但是,有一个前提:3D表示模型应能够呈现2D视图并将2D分割结果配准到3D场景。因此,我们使用神经辐射场(NeRF)[32,45,3]作为现成的解决方案。NeRF是一系列算法,将每个3D场景制定为深度神经网络,该网络在连接多个2D视图之前用作3D。

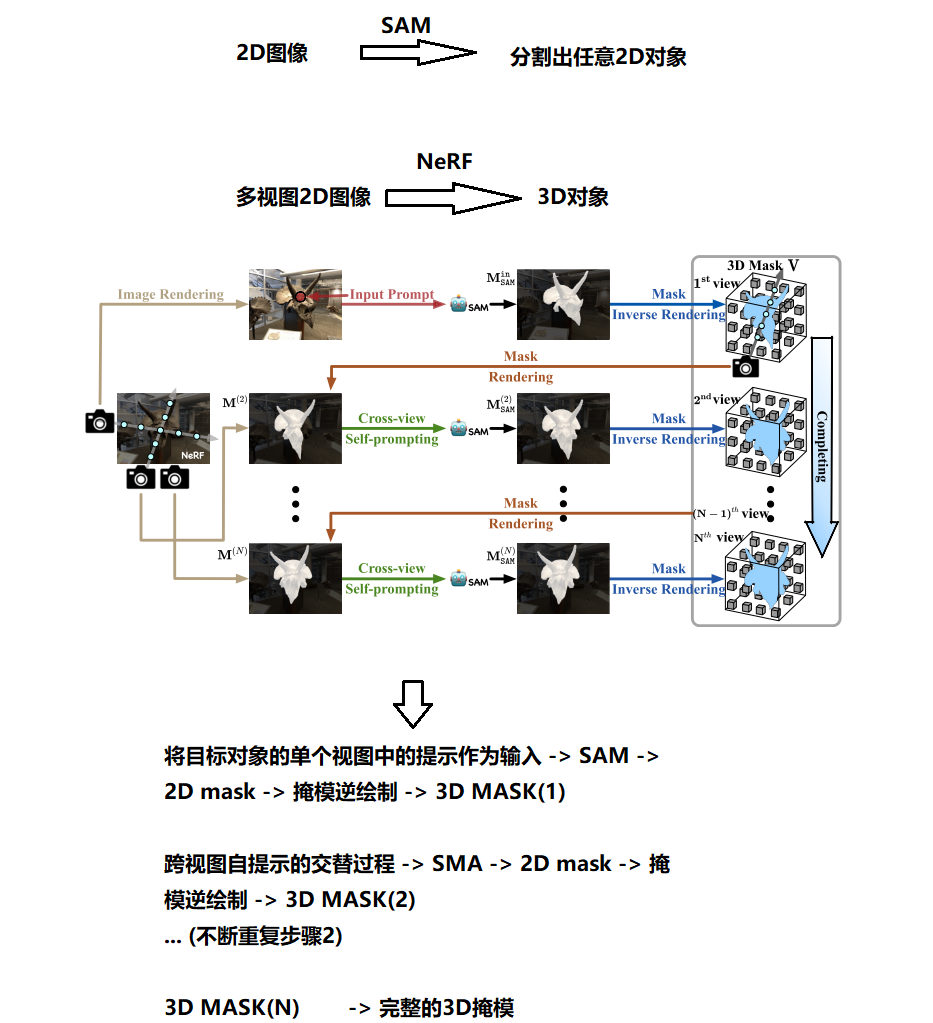
图1:给定任何预先训练的NeRF,SA3D将来自单个渲染视图的提示作为输入,并输出特定目标的3D分割结果。
如图1所示,我们的解决方案被命名为Segment Anything in 3D(SA3D)。给定在一组2D图像上训练的NeRF,SA3D采取提示(例如,单击对象上的点)作为输入,其用于在具有SAM的该视图中生成2D遮罩。接下来,SA3D在各个视图上交替地执行两个步骤,以迭代地完成用体素网格构造的对象的3D掩模。在每一轮中,第一步是掩模逆渲染,其中通过SAM获得的先前2D分割掩模经由NeRF提供的密度引导逆渲染投影到3D掩模上。第二步是交叉视图自提示,其中NeRF用于基于3D掩模和来自另一视图的图像来渲染2D分割掩模(其可能是不完整的),然后从渲染的掩模自动生成几个点提示并馈送到SAM中以产生更完整和准确的2D掩模。迭代地执行上述过程,直到所有必要的视图都已被采样。
- 给定在一组2D图像上训练的NeRF,SA3D采取提示(例如,单击对象上的点)作为输入,其用于在具有SAM的该视图中生成2D遮罩。
- SA3D在各个视图上交替地执行两个步骤,以迭代地完成用体素网格构造的对象的3D掩模。
我们进行各种(例如,对象、部分级)分段任务。无需重新训练/重新设计SAM或NeRF,SA3D就能轻松有效地适应不同场景。与现有方法相比,SA3D具有简化的流水线,通常在几分钟内完成3D分割。SA3D不仅提供了一个有效的工具,用于分割3D中的任何东西,而且还揭示了一种通用的方法,将2D基础模型提升到3D空间。唯一的先决条件是能够稳定地解决跨多个视图的提示分割,我们希望它在未来成为2D基础模型的一般属性。
- 相关工作
2D分割
自从FCN [30]提出以来,2D图像分割的研究经历了快速增长。许多研究已经深入探讨了分割的各个子领域[15,21,4,59]。随着变压器[49,8]进入分段领域,已经提出了许多新的分段架构[60,6,5,44,54],并且整个分段领域已经得到进一步发展。最近在这一领域的重大突破是细分任何模型(SAM)[22]。作为一种新兴的视觉基础模型,SAM被认为是一个潜在的游戏规则改变者,其目的是通过引入基于提示的分割范式来统一2D分割任务。SAM的一个类似模型是SEEM [63],它也表现出令人印象深刻的开放词汇分割能力[SEEM尝鲜地址]。
3D分割
许多方法已经探索了各种类型的3D表示来执行3D分割。这些场景表示包括RGB-D图像[51,53,55,7,17]、点云[37,38,58]和网格空间,诸如体素[19,47,29]、圆柱体[62]和鸟瞰视图空间[56,14]。虽然3D分割已经发展了一段时间,但与2D分割相比,标记数据的稀缺性和计算复杂度高,使得设计类似SAM的统一框架变得困难。在本文中,我们的目标是导航的方式,利用神经辐射场(NeRF)的能力,探索这一有前途的方向。
NeRF神经辐射场
(NeRF)的分割[32,45,3,1,34,16,11,52,26,10]是一系列3D隐式表示。受其在3D一致性新颖视图合成方面的成功启发,许多研究已经深入到NeRF内的3D分割领域。Zhi等人。[61]提出了Semantic-NeRF,这是一种将语义纳入外观和几何结构的方法。它们展示了NeRF在标签传播和细化方面的潜力。NVOS [39]引入了一种交互式方法,通过使用定制设计的3D特征训练轻量级多层感知(MLP),从NeRF中选择3D对象。其他方法,例如N3F [48]、DFF [24]、LERF [20]和ISRF [13]旨在通过训练额外的特征字段将2D视觉特征提升到3D。这些方法需要重新设计/训练NeRF模型,并且通常涉及额外的特征匹配过程。还有一些其他实例分割和语义分割方法[42,35,9,57,28,18,2,12,50,41]与NeRF相结合。
与我们的SA3D最密切相关的方法是MVSeg [33],这是SPIn-NeRF的一个组件[33],其专注于NeRF修复。MVSeg采用视频分割技术来跨不同视图传播2D掩模,并采用这些掩模作为用于训练语义-NeRF模型的标签。然而,视频分割模型缺乏明确的三维结构信息,难以处理复杂场景中的显著遮挡。我们的方法的目的是建立NeRF驱动的一致性,基于自我提示和提升2D掩模到强大的3D掩模。
- 方法
在本节中,我们首先简要回顾神经辐射场(NeRF)和分段任意模型(SAM)。然后介绍了SA3D的总体流水线。最后,我们详细演示了SA3D中每个组件的设计。
准备工作
神经辐射场(NeRF)
给定多视图2D图像的训练数据集I,NeRF [32]学习函数fθ:(x,d)→(c,σ),将点的空间坐标x ∈ R3和观察方向d ∈ S2映射为相应的颜色c ∈ R3和体密度σ ∈ R。θ表示函数f的可学习参数,其通常由多层感知器(MLP)表示。为了渲染图像Iθ,每个像素经历光线投射过程,其中光线r(t)= xo + td通过相机姿态被投影。这里,xo是相机原点,d是射线方向,并且t表示沿着射线的点距原点的距离。通过可微分体绘制算法获得由射线r确定的位置处的RGB颜色Iθ(r):
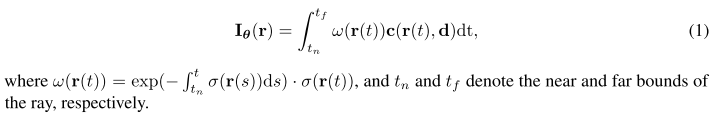
分割任何模型(SAM)
SAM [22]将图像I和一组提示P作为输入,并且以位图的形式输出对应的2D分割掩码MSAM,即,
![]()
提示p ∈ P可以是点、框、文本和掩码。
- 整体管道
我们假设我们已经有了在数据集I上训练的NeRF模型。在本文中,除非另有说明,否则我们选择使用TensoRF [3]作为NeRF模型,考虑到其上级的训练和渲染效率。如图2所示,首先用预训练的NeRF模型渲染来自特定视图的图像Iin。一组提示(例如,在本文中,我们经常使用一组点),Pin被引入并与渲染图像沿着馈送到SAM中。获得相应视图的2D分割maskMin SAM,然后将其投影到3D掩模V ∈ R3构造的体素网格上,使用所提出的掩模逆绘制技术(第3.3节)。然后,从3D掩模渲染来自新颖视图的2D分割掩模M(n)。渲染的蒙版通常不准确。我们提出了一种跨视图自提示方法(第3.4节),以从渲染的掩码中提取点提示P(n),并进一步将它们馈送到SAM中。因此,在该新颖视图中产生更精确的2D掩模M(n)SAM,并且还将其投影到体素网格上以完成3D掩模。以上过程迭代地执行,遍历更多视图。与此同时,3D掩模也变得越来越完整。整个过程有效地将2D分割结果与3D分割结果连接起来。注意,除了3D掩模之外,不需要优化神经网络。
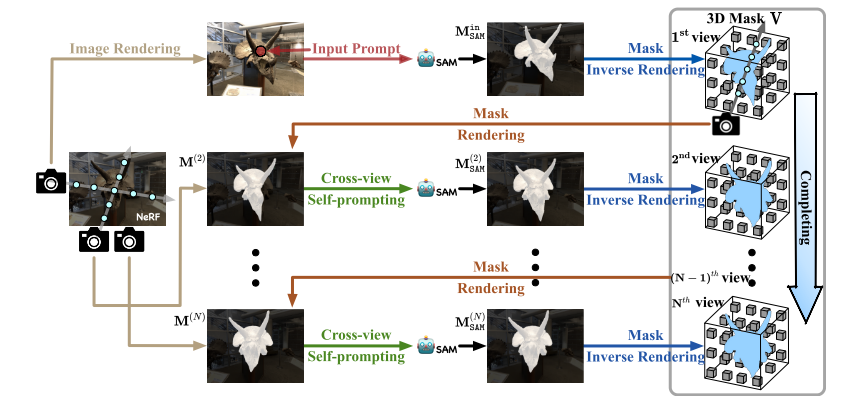
图2:SA3D的整体流水线。给定在一组多视图2D图像上训练的NeRF,SA3D首先将目标对象的单个视图中的提示作为输入,并使用SAM在具有这些提示的该视图中产生2D掩模。然后,SA3D执行掩模逆绘制和跨视图自提示的交替过程,以完成由体素网格构造的目标对象的3D掩模。根据嵌入NeRF中的学习密度分布,执行掩模逆渲染以将SAM获得的2D掩模投影到3D掩模上。交叉视图自提示进行提取可靠的提示自动输入到SAM从NeRF渲染的二维掩模给定一个新的视图。迭代地执行该交替过程,直到我们得到完整的3D掩模。
将目标对象的单个视图中的提示作为输入 -> SAM -> 2D mask -> 掩模逆绘制 -> 3D MASK
掩模逆绘制和跨视图自提示的交替过程 -> 3D MASK
-> 完整的3D掩模
产生该新颖视图中的2D掩模M(n)SAM,并且还将其投影到体素网格上以完成3D掩模。以上过程迭代地执行,遍历更多视图。与此同时,3D掩模也变得越来越完整。整个过程有效地将2D分割结果与3D分割结果连接起来。注意,除了3D掩模之外,不需要优化神经网络。
- 实验
在本节中,我们定量评估SA3D在各种数据集上的分割能力。然后,我们定性地证明了SA3D的通用性,它可以进行实例分割,部分分割,文本提示分割等。
数据集
对于定量实验,我们使用神经体积对象选择(NVOS)[39],SPInNeRF [33]和副本[43]数据集。NVOS [39]数据集基于LLFF数据集[31],其中包括几个前向场景。对于每个场景,NVOS提供具有涂鸦的参考视图和具有注释的2D分割掩模的目标视图。与NVOS类似,SPInNeRF [33]手动注释一些数据以评估交互式3D分割性能。这些注释基于一些广泛使用的NeRF数据集[31,32,25,23,11]。副本[43]数据集提供了各种室内场景的高质量重建地面实况,包括干净的密集几何结构、高分辨率和高动态范围纹理、玻璃和镜面信息、语义类、平面分割和实例分割掩模。对于定性分析,我们使用LLFF [31]数据集和360◦数据集[1]。SA3D进一步应用于LERF [20]数据集,其中包含更逼真和更具挑战性的场景。
- 讨论
在实验结果之上,我们希望从整合SAM和NeRF的初步研究中提供一些见解,即:2D基础模型和3D表示模型。
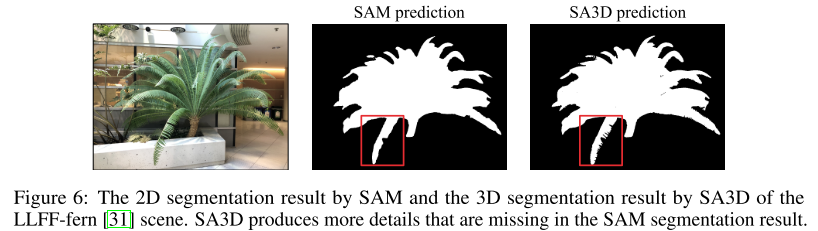
首先,NeRF提高了SAM的分割质量。在图6中,我们展示了SA3D可以消除SAM的分割错误,并有效地捕获诸如孔洞和边缘等细节。从感知上讲,SAM以及其他2D感知模型通常对视点敏感,NeRF提供了3D建模的能力,因此具有辅助识别的互补性。此外,SA3D启发我们,使用NeRF或其他3D结构先验是一种资源高效的方法,可以将视觉基础模型从2D提升到3D,只要基础模型具有自我提示的能力。这种方法可以保存许多资源,因为收集大量的3D数据语料库通常是昂贵的。我们期待着研究努力来增强2D基础模型的3D感知能力(例如,将3D感知损失注入到2D预训练中)。
SA3D可以消除SAM的分割错误,并有效地捕获诸如孔洞和边缘等细节
局限
我们证明了SA3D在全景3D分割中的局限性。首先,当前范例依赖于第一视图提示。如果某些对象没有出现在视图中进行提示,则在后续分割过程中将忽略这些对象。第二,场景中的相同部分可以被分割成不同视图中具有相似语义的不同实例。这种模糊性在目前的机制设计下不易消除,导致训练不稳定。我们把这些问题作为未来的工作。
- 结论
在本文中,我们提出了SA3D,一个新的框架,概括SAM分割3D对象的神经辐射场(NeRFs)作为结构先验。基于训练的NeRF和单个视图中的一组提示,SA3D执行迭代过程,该过程涉及渲染新的2D视图、用于2D分割的自提示SAM以及将分割投影回3D掩模网格。SA3D可以有效地应用于广泛的3D分割任务。我们的研究揭示了一种资源高效的方法,将视觉基础模型从2D提升到3D。