DCN v1即 Deformable Convolutional Networks。
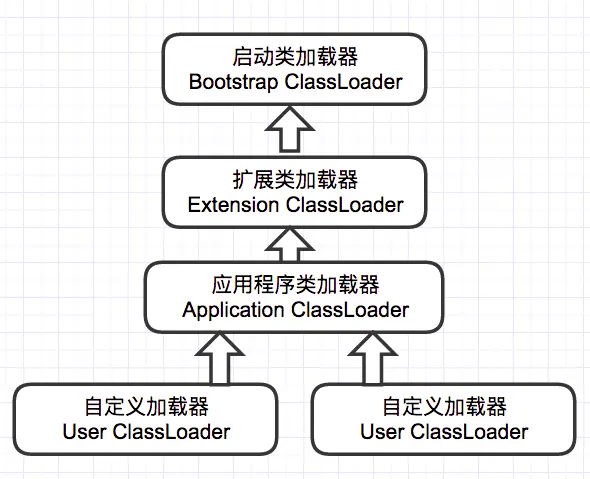
视觉识别(例如对象检测和语义分割)中的一个关键挑战是如何适应物体尺度、姿态、视角和零件变形中的几何变化或模型几何变换。卷积神经网络(CNN)构建模块中为固定几何结构:
- 卷积单元在固定位置对输入特征图进行采样;
- 池化层以固定比率降低空间分辨率;
- RoI(感兴趣区域)池化层将 RoI 分成固定的空间箱等。
缺乏处理几何变换的内部机制,固有地在建模几何变换方面受限:
- 同一个 CNN 层中所有激活单元的感受野大小是相同的。这对于在空间位置上编码语义的高层 CNN 层来说是不可取的。由于不同的位置可能对应不同尺度或形变的物体,自适应地确定尺度或感受野大小对于具有精细定位的视觉识别是所期望的,例如,使用全卷积网络的语义分割[FCN]。
- 目标检测方法[R-CNN, MultiBox, Fast R-CNN, Faster R-CNN, YOLO, SSD R-FCN]仍然依赖于基于原始边界框的特征提取。这显然是次优的,特别是对于非刚性物体。
以往通过扩充现有数据样本,构建具有足够所需变化的训练数据集来缓解。
Deformable ConvNet 引入了两个新模块来增强神经网络的变换建模能力:
- 可变形卷积:它在标准卷积中的规则网格采样位置上添加2D 偏移。它实现了采样网格的自由变形。如图 Figure 1 所示。通过额外的卷积层,从前面的特征图中学习偏移。因此,变形以局部、密集和自适应的方式以输入特征为条件。
- 可变形 RoI 池化:它在之前的 RoI 池化[Fast R-CNN, R-FCN]的常规 bin 分区中的每个 bin 位置添加一个偏移量。类似地,偏移量是从前面的特征图和 RoI 中学习的,从而可以对具有不同形状的物体进行自适应部件定位。

这两种方法的指导思想为在模块中增加额外偏移量的空间采样位置,并从目标任务中学习偏移量,而无需额外监督。新模块可以很容易地替换现有 CNN 中的普通模块,并且可以通过标准反向传播很容易地进行端到端训练,从而产生可变形卷积网络。
Deformable Convolution
CNN 中的特征图和卷积是 3D 的。可变形卷积和 RoI 池化模块都在 2D 空间域上操作。操作在整个通道维度上保持不变。在不失一般性的情况下,为了符号清晰起见,下面以 2D 形式描述模块。 扩展到 3D 非常简单。2D 卷积包括两个步骤:
- 在输入特征图 x \mathbf{x} x 上使用规则网格 R \mathcal{R} R 进行采样;
- 对 w \mathbf{w} w 加权的采样值求和。
网格
R
\mathcal{R}
R 定义感受野大小和膨胀。例如,
R
=
{
(
−
1
,
−
1
)
,
(
−
1
,
0
)
,
…
,
(
0
,
1
)
,
(
1
,
1
)
}
\mathcal{R}=\{(-1, -1), (-1, 0), \ldots, (0,1), (1, 1)\}
R={(−1,−1),(−1,0),…,(0,1),(1,1)}
定义了一个扩张为 1 1 1 的 3 × 3 3\times 3 3×3 内核。
对于输出特征图
y
\mathbf{y}
y 上的每个位置
p
0
\mathbf{p}_0
p0,我们有
y
(
p
0
)
=
∑
p
n
∈
R
w
(
p
n
)
⋅
x
(
p
0
+
p
n
)
,
\mathbf{y}(\mathbf{p}_0)=\sum_{\mathbf{p}_n\in\mathcal{R}}\mathbf{w}(\mathbf{p}_n)\cdot \mathbf{x}(\mathbf{p}_0+\mathbf{p}_n),
y(p0)=pn∈R∑w(pn)⋅x(p0+pn),
其中,
p
n
\mathbf{p}_n
pn 列举了
R
\mathcal{R}
R 中的位置。
在可变形卷积中,规则网格
R
\mathcal{R}
R 增加了偏移量
{
Δ
p
n
∣
n
=
1
,
.
.
.
,
N
}
\{\Delta \mathbf{p}_n|n=1,...,N\}
{Δpn∣n=1,...,N},其中
N
=
∣
R
∣
N=|\mathcal {R}|
N=∣R∣。标准卷积等式变为
y
(
p
0
)
=
∑
p
n
∈
R
w
(
p
n
)
⋅
x
(
p
0
+
p
n
+
Δ
p
n
)
.
\mathbf{y}(\mathbf{p}_0)=\sum_{\mathbf{p}_n\in\mathcal{R}}\mathbf{w}(\mathbf{p}_n)\cdot \mathbf{x}(\mathbf{p}_0+\mathbf{p}_n+\Delta \mathbf{p}_n).
y(p0)=pn∈R∑w(pn)⋅x(p0+pn+Δpn).
目前,在不规则的偏移位置
p
n
+
Δ
p
n
\mathbf{p}_n+\Delta \mathbf{p}_n
pn+Δpn 上采样。由于偏移
Δ
p
n
\Delta \mathbf{p}_n
Δpn 通常是小数,上式通过双线性插值实现为
x
(
p
)
=
∑
q
G
(
q
,
p
)
⋅
x
(
q
)
,
\mathbf{x}(\mathbf{p})=\sum_\mathbf{q} G(\mathbf{q},\mathbf{p})\cdot \mathbf{x}(\mathbf{q}),
x(p)=q∑G(q,p)⋅x(q),
其中 p \mathbf{p} p 表示任意(小数)位置(对于可变形卷积公式, p = p 0 + p n + Δ p n \mathbf{p}=\mathbf{p}_0+\mathbf{p}_n+\Delta \mathbf{p}_n p=p0+pn+Δpn), q \mathbf{q} q 枚举特征图 x \mathbf{x} x 中的所有积分空间位置, G ( ⋅ , ⋅ ) G(\cdot,\cdot) G(⋅,⋅) 是双线性插值核。 请注意 G G G 是二维的。它被分解为两个一维核
G
(
q
,
p
)
=
g
(
q
x
,
p
x
)
⋅
g
(
q
y
,
p
y
)
,
G(\mathbf{q},\mathbf{p})=g(q_x,p_x)\cdot g(q_y,p_y),
G(q,p)=g(qx,px)⋅g(qy,py),
其中
g
(
a
,
b
)
=
m
a
x
(
0
,
1
−
∣
a
−
b
∣
)
g(a,b)=max(0,1-|a-b|)
g(a,b)=max(0,1−∣a−b∣)。等式计算快速,因为
G
(
q
,
p
)
G(\mathbf{q},\mathbf{p})
G(q,p) 仅对少数
q
\mathbf{q}
q 为非零。
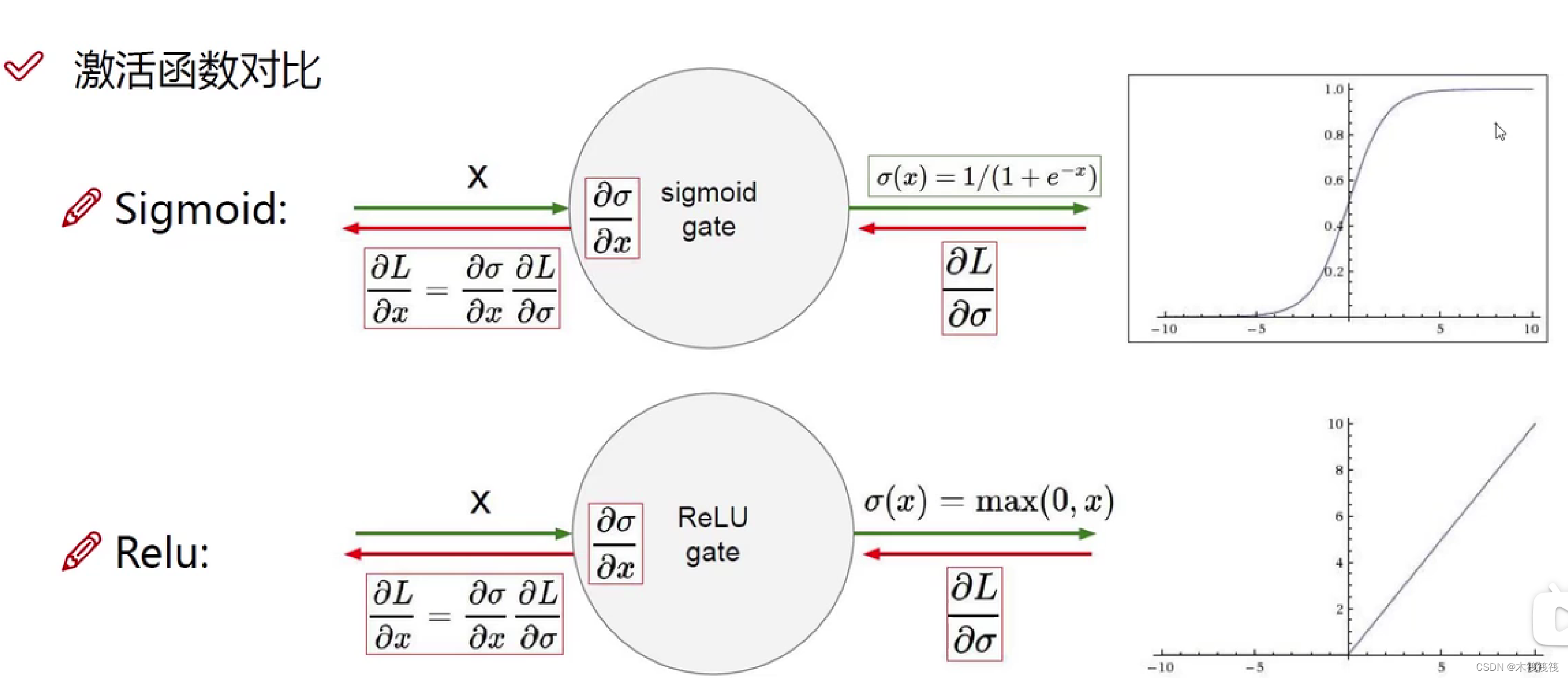
如图 Figure 2 所示,偏移量是通过在同一输入特征图上应用卷积层获得的。卷积核与当前卷积层具有相同的空间分辨率和扩张(例如,在图 Figure 2 中也是 3 × 3 3\times 3 3×3,扩张为 1)。输出偏移场具有与输入特征图相同的空间分辨率。通道维度 2 N 2N 2N 对应于 N N N 个2D 偏移量。在训练期间,同时学习用于生成输出特征和偏移的卷积核。

Deformable RoI Pooling
所有基于区域建议的目标检测方法[R-CNN, Fast R-CNN, Faster R-CNN, R-FCN]均使用 RoI 池化。它将任意大小的输入矩形区域转换为固定大小的特征。
RoI Pooling [Fast R-CNN] 给定输入特征图 x \mathbf{x} x 和大小为 w × h w\times h w×h、左上角 p 0 \mathbf{p}_0 p0 的 RoI,RoI 池化将 RoI 划分为 k × k k\times k k×k( k k k 是一个自由参数)个 bin 并输出 k × k k\times k k×k 的特征图 y \mathbf{y} y。对于第 ( i , j ) (i,j) (i,j) 个 bin ( 0 ≤ i , j < k 0\le i,j < k 0≤i,j<k),我们有
y ( i , j ) = ∑ p ∈ b i n ( i , j ) x ( p 0 + p ) / n i j , \mathbf{y}(i,j)=\sum_{\mathbf{p}\in bin(i,j)} \mathbf{x}(\mathbf{p}_0+\mathbf{p})/n_{ij}, y(i,j)=p∈bin(i,j)∑x(p0+p)/nij,
其中 n i j n_{ij} nij 是 bin 中的像素数。第 ( i , j ) (i,j) (i,j) 个 bin 范围是 ⌊ i w k ⌋ ≤ p x < ⌈ ( i + 1 ) w k ⌉ \lfloor i \frac{w}{k} \rfloor \le p_x < \lceil (i+1)\frac{w}{k}\rceil ⌊ikw⌋≤px<⌈(i+1)kw⌉ 和 ⌊ j h k ⌋ ≤ p y < ⌈ ( j + 1 ) h k ⌉ \lfloor j \frac{h}{k}\rfloor \le p_y < \lceil (j+1)\frac{h}{k} \rceil ⌊jkh⌋≤py<⌈(j+1)kh⌉。
与卷积类似,在可变形 RoI 池化中,在空间分箱位置上添加偏移
{
Δ
p
i
j
∣
0
≤
i
,
j
<
k
}
\{\Delta \mathbf{p}_{ij}|0\le i,j < k\}
{Δpij∣0≤i,j<k}。上式变为
y
(
i
,
j
)
=
∑
p
∈
b
i
n
(
i
,
j
)
x
(
p
0
+
p
+
Δ
p
i
j
)
/
n
i
j
.
\mathbf{y}(i,j)=\sum_{\mathbf{p}\in bin(i,j)} \mathbf{x}(\mathbf{p}_0+\mathbf{p}+\Delta \mathbf{p}_{ij})/n_{ij}.
y(i,j)=p∈bin(i,j)∑x(p0+p+Δpij)/nij.
通常, Δ p i j \Delta \mathbf{p}_{ij} Δpij 是小数。该式同样通过双线性插值实现。
图 Figure 3 说明了如何获得偏移量。

首先,RoI 池化 (式 eq.standard_roi_pooling) 生成池化特征图。从映射图中,一个 fc 层生成归一化偏移量
Δ
p
^
i
j
\Delta \widehat{\mathbf{p}}_{ij}
Δp
ij,然后与 RoI 的宽度和高度按元素乘积转换为式 Eq eq.deformable_roi_pooling 中的偏移量
Δ
p
i
j
\Delta \mathbf{p}_{ ij}
Δpij:
Δ
p
i
j
=
γ
⋅
Δ
p
^
i
j
∘
(
w
,
h
)
\Delta \mathbf{p}_{ij} = \gamma \cdot \Delta \widehat{\mathbf{p}}_{ij} \circ (w, h)
Δpij=γ⋅Δp
ij∘(w,h)
这里
γ
\gamma
γ 是一个预定义的标量,用于调制偏移量的大小。它根据经验设置为
γ
=
0.1
\gamma=0.1
γ=0.1。为使偏移学习不受 RoI 大小影响,偏移归一化是必要的。
Position-Sensitive (PS) RoI Pooling[R-FCN] 是全卷积,与 RoI 池化不同。通过一个 conv 层,首先将每个目标类(
C
C
C 类目标总计为
C
+
1
C+1
C+1 个类别)的所有输入特征图转换为
k
2
k^2
k2 个得分图,如图 Figure 4 中的底部分支所示。在不需要区分类的情况下,这样的分数映射表示为
{
x
i
,
j
}
\{\mathbf{x}_{i,j}\}
{xi,j},其中
(
i
,
j
)
(i,j)
(i,j) 枚举所有 bin。对这些得分图进行池化。第
(
i
,
j
)
(i,j)
(i,j) 个 bin 的输出值是通过从对应于该 bin 的一个分数映射
x
i
,
j
\mathbf{x}_{i,j}
xi,j 求和获得的。简而言之,与 RoI 池化公式的不同之处在于,将一个通用的特征图
x
\mathbf{x}
x 替换为特殊的正敏感得分图
x
i
,
j
\mathbf{x}_{i,j}
xi,j。

在可变形 PS RoI 池化中,公式唯一的变化是将 x \mathbf{x} x 也修改为 x i , j \mathbf{x}_{i,j} xi,j。 然而,偏移学习是不同的。它遵循 R-FCN 中的“全卷积”精神,如图 Figure 4 所示。在顶部分支中,一个 conv 层生成全空间分辨率偏移场。对于每个 RoI (对于每个类也是如此),PS RoI 池化应用于这些域上以获得归一化偏移量 Δ p ^ i j \Delta \widehat{\mathbf{p}}_{ij} Δp ij,然后以与上述可变形 RoI 池中相同的方式将其转换为实际偏移量 Δ p i j \Delta \mathbf{p}_{ij} Δpij。
Deformable ConvNets
可变形卷积和 RoI 池化模块都具有与其普通版本相同的输入和输出。在训练中,这些添加的用于偏移学习的 conv 和 fc 层用零权重初始化。它们的学习率设置为现有层学习率的 β \beta β 倍(默认情况下为 β = 1 \beta = 1 β=1,Faster R-CNN 中的 fc 层为 β = 0.01 \beta = 0.01 β=0.01)。
特征提取网络使用 Aligned-Inception-ResNet,结构见表 Table 6。当特征维度发生变化时,使用步幅为 2 的
1
×
1
1\times 1
1×1 卷积层。


Ablation Study
Deformable Convolution
表 Table 1 使用 ResNet-101 特征提取网络评估可变形卷积的效果。当使用更多可变形卷积层时,准确性稳步提高,特别是对于 DeepLab 和类感知 RPN。当 DeepLab 使用
3
3
3 个可变形层,其他网络使用
6
6
6 个时,改进达到饱和。在剩余的实验中,特征提取网络使用
3
3
3 个。

作者根据经验观察到,可变形卷积层中学习的偏移量对图像内容具有高度自适应性,如图 Figure 6 和图 Figure 7 所示。为了更好地理解可变形卷积的机制,作者为可变形卷积滤波器定义了一个称为有效膨胀的度量。它是滤波器中所有相邻采样位置对之间距离的平均值。这是对滤波器的感受野大小的粗略测量。

在 VOC 2007 测试图像上应用具有
3
3
3 个可变形层的 R-FCN 网络(如表 Table 1)。根据真实边界框标注和滤波器中心位置将可变形卷积滤波器分为小、中、大和背景四类。 表 Table 2 报告了有效扩张值的统计数据(平均值和标准差)。

它清楚地表明:
- 可变形滤波器的感受野大小与物体大小相关,表明变形是从图像内容中有效学习的;
- 背景区域上的滤波器尺寸介于中型和大型物体之间,表明识别背景区域需要相对较大的感受野;
这些观察结果在不同层中是一致的。
默认的 ResNet-101 模型对最后三个
3
×
3
3\times 3
3×3 卷积层使用带膨胀
2
2
2 的空洞卷积(参见第 2.3 节)。 我们进一步尝试了膨胀值
4
4
4、
6
6
6 和
8
8
8,并在表 Table 3 中报告了结果。

它表明:
- 当使用较大的扩张值时,所有任务的准确性都会增加,这表明默认网络的感受野太小;
- 最佳扩张值因不同任务而异,例如,DeepLab 为 6 6 6,而 Faster R-CNN 为 4 4 4;
- 可变形卷积具有最佳精度。
这些观察结果验证了滤波器变形自适应学习的有效性和必要性。
Deformable RoI Pooling
它适用于 Faster R-CNN 和 R-FCN。如表 Table 3 所示,单独使用它已经产生了明显的性能增益,尤其是在严格的 mAP@0.7 指标下。当同时使用可变形卷积和 RoI Pooling 时,可以获得显著的精度提升。
Model Complexity and Runtime
表 Table 4 报告了所提出的可变形 ConvNet 及其普通版本的模型复杂度和运行时间。可变形 ConvNet 仅对模型参数和计算量增加了少量开销。这表明显著的性能提升来自于建模几何变换的能力,而不是增加模型参数。

参考资料:
- deform_conv2d
- Deformable Convolutional Networks
- Deformable ConvNets v2: More Deformable, Better Results
- msracver/Deformable-ConvNets
- Question about num_deformable_group #268
- 【VALSE 前沿技术选介17-02期】可形变的神经网络
- DCN v2 (Arxiv, 2018)
- DCN_v2_paper_reading.pdf
- Deformable Convolutional Networks