Fast Segment Anything Model(FastSAM)
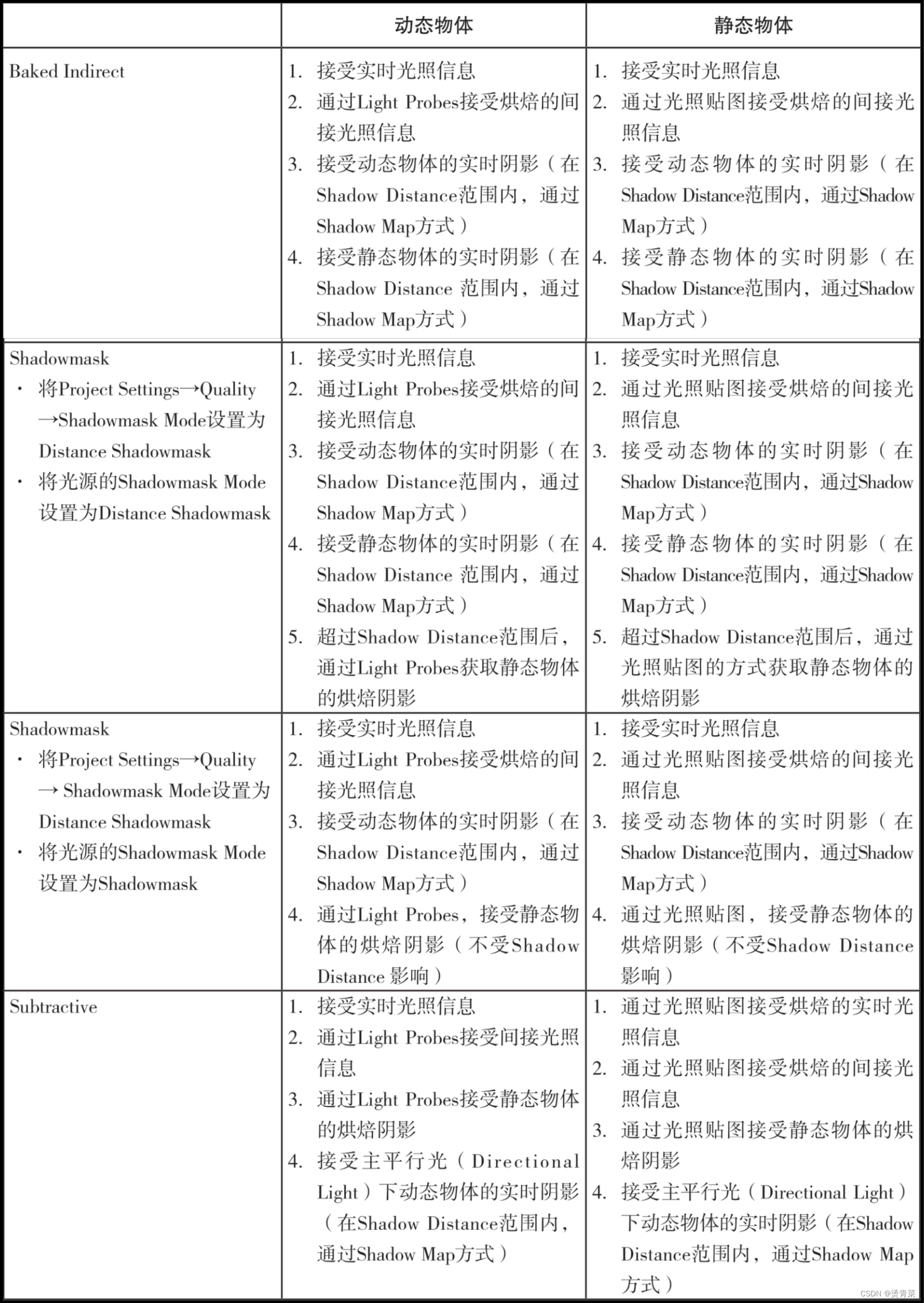
Fast Segment Anything Model(FastSAM)是一个仅使用SAM作者发布的SA-1B数据集的2%进行训练的CNN Segment Anything模型。FastSAM在50倍的运行速度下实现了与SAM方法相当的性能。
SAM代码:https://github.com/casia-iva-lab/fastsam
SAM论文:https://arxiv.org/pdf/2306.12156.pdf
1 概述
Segment Anything Model(SAM)在计算机视觉任务中很有用,但它的Transformer架构在高分辨率输入下计算成本很高,限制了它在工业场景中的应用。我们提出了一种速度更快的替代方法,性能与SAM相当。通过将任务重新定义为分段生成和提示,我们发现一个常规的CNN检测器加上实例分割分支可以完成任务。我们只使用SAM作者发布的SA-1B数据集的1/50来训练现有的实例分割方法。使用我们的方法,我们在50倍运行速度下实现了与SAM相当的性能。
2 FastSAM
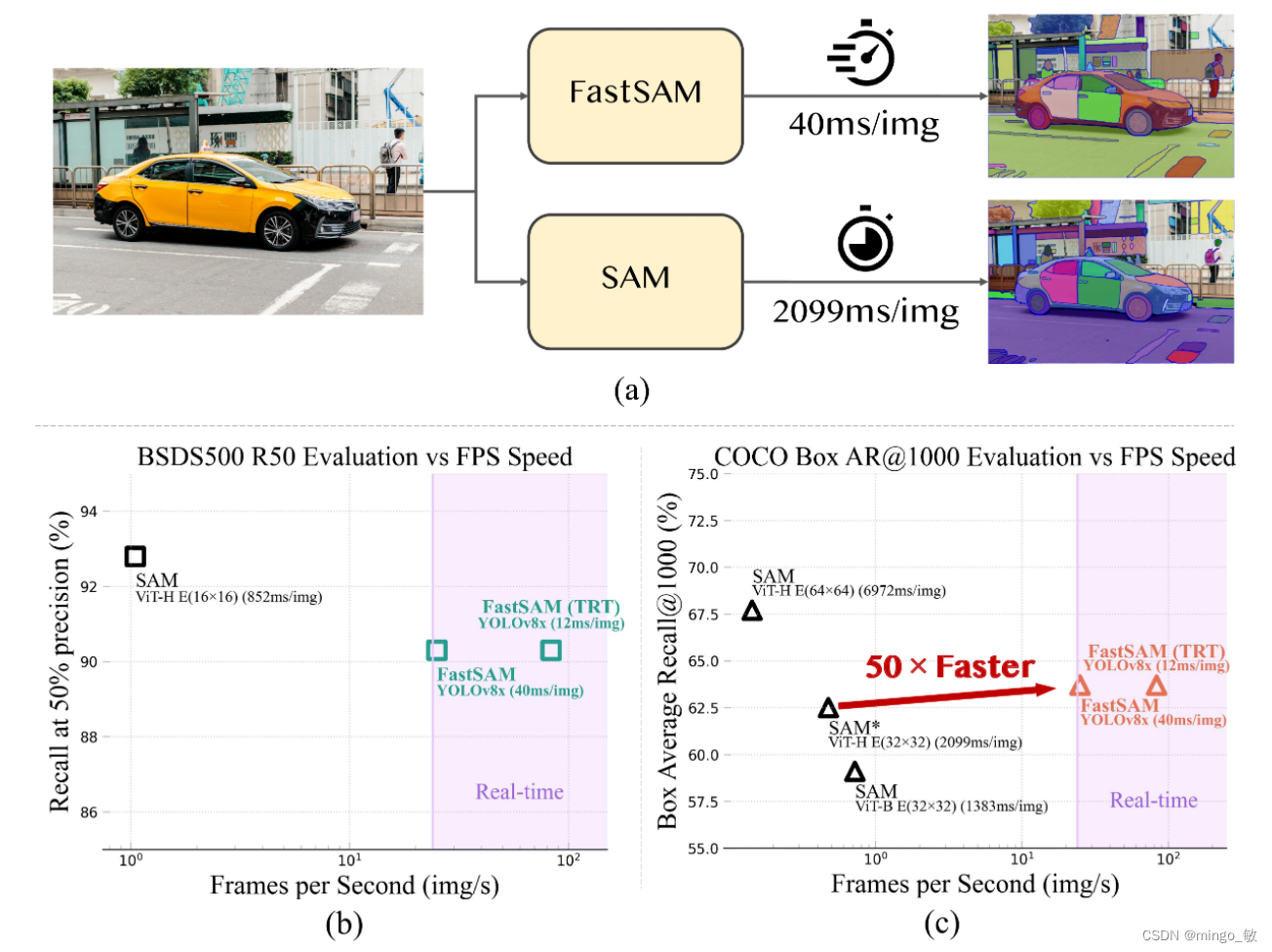
FastSAM将segment anything任务分解为两个连续的阶段,即全实例分割和提示引导选择。第一阶段依赖于基于卷积神经网络(CNN)的检测器的实现。它生成图像中所有实例的分割掩码。然后在第二阶段,它输出与提示相对应的感兴趣区域。通过利用CNN的计算效率,FastSAM可以在不太损失性能质量的情况下,可以实现实时的segment anything模型。
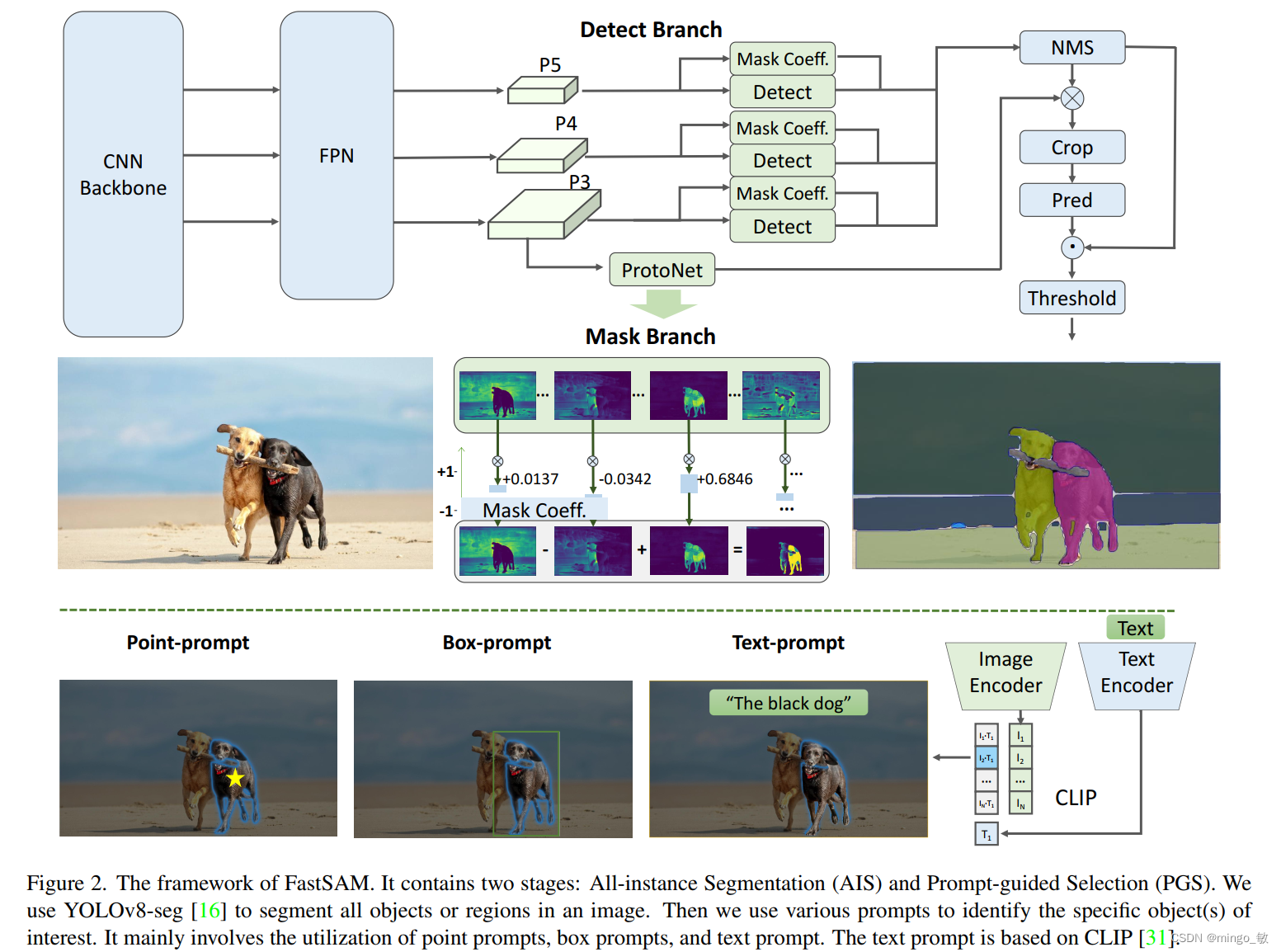
2-1 All-instance Segmentation
在FastSAM中,我们直接使用YOLOv8-Seg方法进行全实例分割阶段。YOLOv8-Seg检测分支负责输出物体类别和边界框信息,而分割分支则输出k个原型(在FastSAM中默认为32)以及对应的k个掩模系数。这两个任务是同时进行的。分割分支输入高分辨率特征图,保留了空间细节和语义信息。该特征图经过卷积层处理,上采样后再经过两个卷积层,最终输出掩模。与检测分支的分类分支类似,掩模系数的取值范围在-1到1之间。实例分割的结果是通过将掩模系数与原型相乘并相加得到的。
2-2 Prompt-guided Selection
在使用YOLOv8成功地对图像中的所有对象或区域进行分割之后,分割任何物体任务的第二阶段是使用各种提示来识别感兴趣的特定对象。这主要涉及使用点提示、框提示和文本提示。点提示。
点提示 包括将所选点与从第一阶段获得的各种掩模进行匹配。目标是确定点所在的掩模。与SAM类似,我们采用前景/背景点作为提示。在前景点位于多个掩模的情况下,可以利用背景点来过滤与当前任务无关的掩模。通过使用一组前景/背景点,我们能够在感兴趣的区域内选择多个掩模。这些掩模将合并为一个掩模,以完全标记感兴趣的对象。此外,我们利用形态学操作来提高掩模合并的性能。
框提示框提示涉及在所选框和从第一阶段对应于各个掩模的边界框之间执行交并比(IoU)匹配。目的是确定与所选框具有最高IoU分数的掩模,从而选择感兴趣的对象。
文本提示在文本提示的情况下,使用CLIP 模型提取文本的相应文本嵌入。然后确定相应的图像嵌入,并使用相似度度量将其与每个掩模的内在特征进行匹配。然后选择与文本提示的图像嵌入具有最高相似度分数的掩模。
通过精心实施这些提示引导的选择技术,FastSAM可以可靠地从分割图像中选择特定的感兴趣对象。
3 Experiments

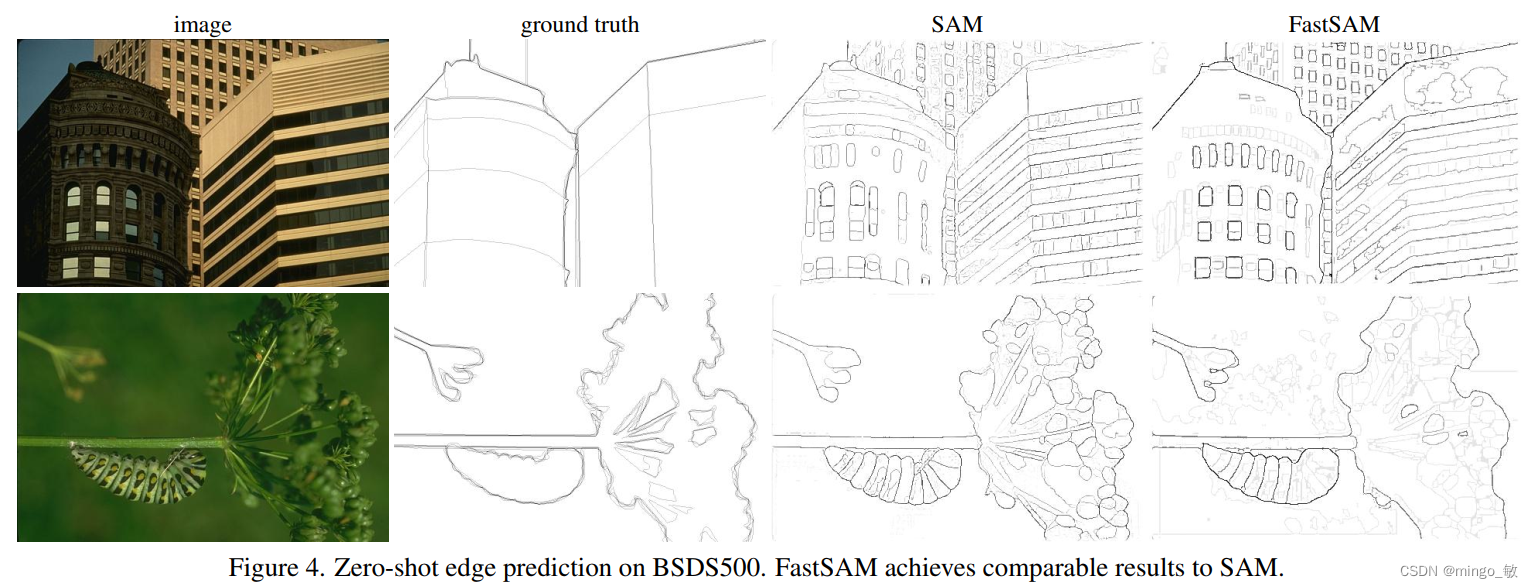
Zero-Shot Edge Detection
anomaly detection

salient object segmentation

4 Discussion
FastSAM的框生成具有显著优势,但我们的掩模生成性能低于SAM。可能有以下原因:
- 低质量的小尺寸分割掩模具有较大的置信度分数。我们认为这是因为置信度分数被定义为YOLOv8的bbox分数,与掩模质量没有强烈关联。改变网络以预测掩模IoU或其他质量指标是改善这一问题的一种方式。
- 一些微小尺寸对象的掩模倾向于近似正方形。此外,大型对象的掩模可能在边界框的边缘具有一些伪影。这是YOLACT方法的缺点。通过增强掩模原型的能力或重新构造掩模生成器,预计可以解决这个问题。