通用视觉&音频模型的思考
- 0. 视觉(Diff)怎么和多模态结合
- (0) 总结
- (1) 关键技术
- (1-1) LangChain
- (1-2) **Versatile Diffusion**
- (1-3) Tango
- (1-4) SUR-adapter
- 1. SUR-Adapter
- (0) 总结
- (1) 摘要
- (2) 相关工作
- (2-1) 文图生成 & LLM
- (2-2) 语义理解和推理数据集
- (2-2-1) 数据收集
- (2-2-2) 数据分析
- (3) 模型
- (3-1) 初步: Preliminary
- (3-2) SUR-adapter 微调思路
- (3-2-1) LLM知识蒸馏
- (3-2-2) 调校DM期间的性能维护
- (3-2-3) 调整复杂提示和简单提示的表示方式。
- (4) 实验
- 2. Tango
- (0) 总结
- (1) 摘要
- (2) 相关工作
- (3) 模型
- (3-1) 文本提示编码器
- (3-2) 文本引导生成的潜在扩散模型
- (3-3) 上升
- (3-4) 无分类器引导
- (3-5) 音频VAE和声码器
- (4) 实验和评价
NLP领域有LLM,这很nice,很强,但是声音和图像领域,大一统的模型还很难做到像NLP领域的chatGPT那样的强泛化性。当前,使用LLM模型引导视觉和声音领域,是一个通用模型构建的思路。以下将从目前新鲜出炉的两项技术:SUR-Adapter(中山大学林倞老师团队,很强)和Tango模型出发,给出一些思考与总结。
0. 视觉(Diff)怎么和多模态结合
参考: 当大语言模型遇上扩散模型
Diff + LLM
(0) 总结
Diff有一个亟待解决的问题,就是图片到图片的扩散,模型无法理解图片中的文字内容,可以基于这一点出发,用LLM模型更好地调教模型识别图片文字内容的能力。首先使用OCR技术识别图片中的文字内容,然后结合文字内容(LLM模型理解)和图片内容(CLIP模型理解)去理解这张图。将理解的特征信息和用户输入的promote信息结合起来,再去作用于一个Query Stable Diffusion,去生成一张图片(这里就是核心难点了,如何像blip2那样使用Query Transformer去调和LLM语言模型和CLIP视觉模型,我认为核心在于需要将结合的特征信息作为更有效的文本提示,图片还是用SD模型中使用的原始图片的潜在特征空间)。
0620总结的非常正确!SUR-Adapter (林倞团队) 就是按照这个思路来的!
(1) 关键技术
visual-chatgpt、Hugging Face(transformers、diffusers)、LangChain、Stable Diffusion、ChatGLM-6B、clip-interrogator、prompt-generator、stanford_alpaca、alpaca.cpp、alpaca-lora、llama.cpp、pyllama、chatglm-6b-int4 …
(1-1) LangChain
略(见下文的专题)
LangChain 是一个用于构建端到端语言模型应用的Python框架。随着ChatGPT等大型语言模型(LLM)的发布,应用开发者越来越倾向于将LLM集成到自己的应用中。然而,由于LLM生成结果的不确定性和不准确性,目前还无法仅依靠LLM提供智能化服务。因此,LangChain应运而生,其主要目标是将LLM与开发者现有的知识和系统相结合,以提供更智能化的服务。
(1-2) Versatile Diffusion
略(见下文的专题)
(1-3) Tango
TANGO是一种用于生成文本到音频 (TTA) 的潜在扩散模型 (LDM)。TANGO可以生成逼真的音频,包括人类声音、动物声音、自然和人造声音以及文本提示的声音效果。我们使用冻结指令调整的 LLM Flan-T5 作为文本编码器,并训练基于 UNet 的扩散模型来生成音频。尽管在小 63 倍的数据集上训练 LDM,但我们在客观和主观指标方面的表现与当前最先进的 TTA 模型相当。我们为研究社区发布我们的模型、训练、推理代码和预训练检查点。
https://github.com/declare-lab/tango
(1-4) SUR-adapter
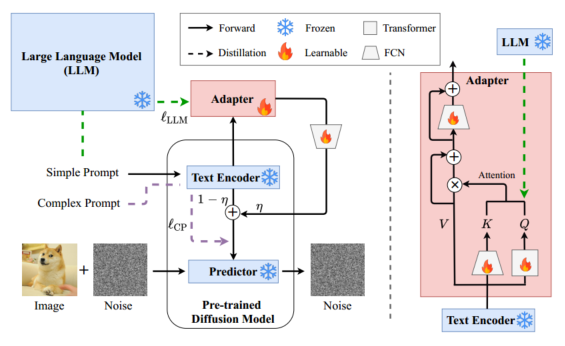
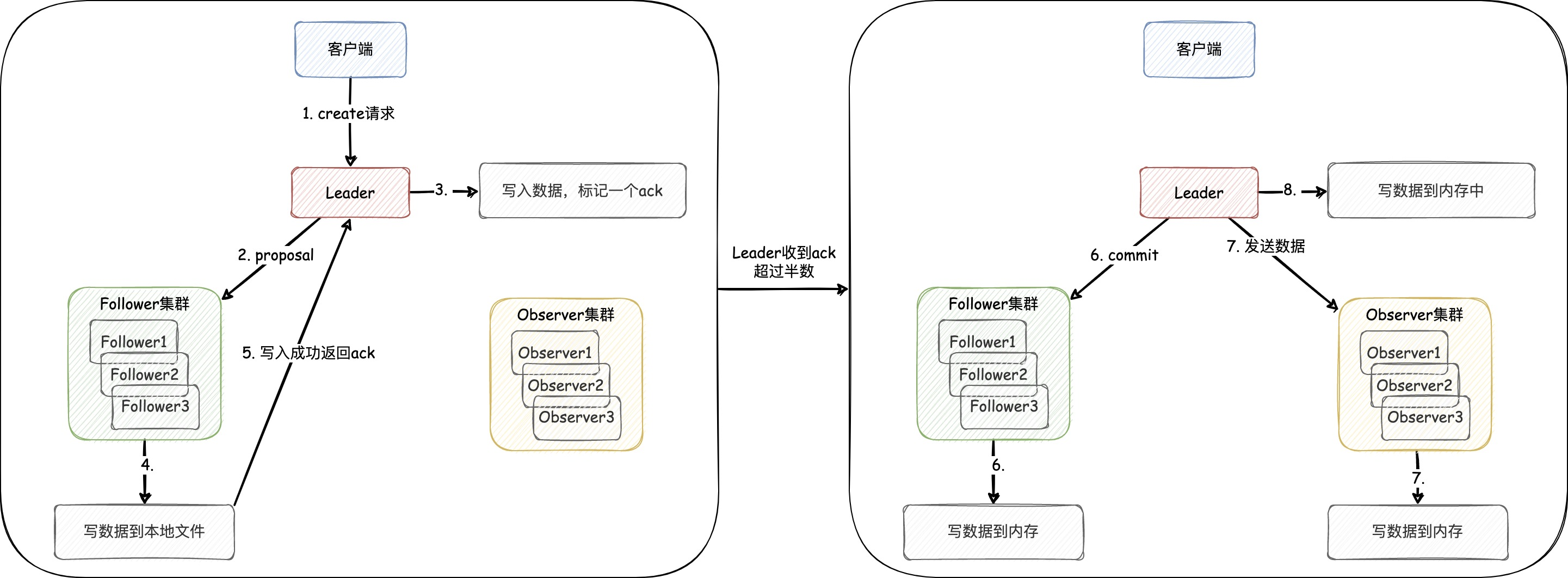
图5: Suradapter的图示。FCN是一种全连接网络。(左)预训练扩散模型的微调管道。给定一个预训练的扩散模型,适配器用于转移大型语言模型的语义理解和推理能力,并在复杂和简单提示之间对齐表示。权重系数(weight coefficient)用来调整适配器的效果。(右)适配器的网络结构。
近日,科研团队推出了一种名为 SUR-adapter 的新技术,可升级计算机程序中的扩散模型,将简单的描述转化为详细的图像。通过训练这些模型更好地理解故事,并使用超过 57,000 个样本的新数据集,研究人员使模型更擅长从简单描述中创建高质量图像,使其更易于使用且更有趣。
1. SUR-Adapter
(0) 总结
模型总体为三个损失函数,一个是大语言模型的损失,保持大语言模型的推理能力。一个是对齐复杂Prompts和简单Prompts的损失,使得Encoder可以汲取到LLM生成的复杂Prompts知识。还有一个就是基础的Diff的期望损失,输入的简单的Prompts会先送入Encoder,并加上LLM的推理信息。
Simple-简单的Prompts作为Q,Complex-复杂的Prompts(由simple经过encoder和LLM演化而来)作为K,V即复杂的Prompts。
注意,传统的StableDiff在融合文本条件扩散的时候,文本特征作为V,时序信息作为K,UNet中间层的输出作为Q。在SUR-Adapter融合文本时,文本特征的V会发生改变,采用的是一个基于LLM调整的V(具体来说就是设计了一个Transformer,复杂文本做为Q,简单文本作为K和V-保持简单文本语义不变)
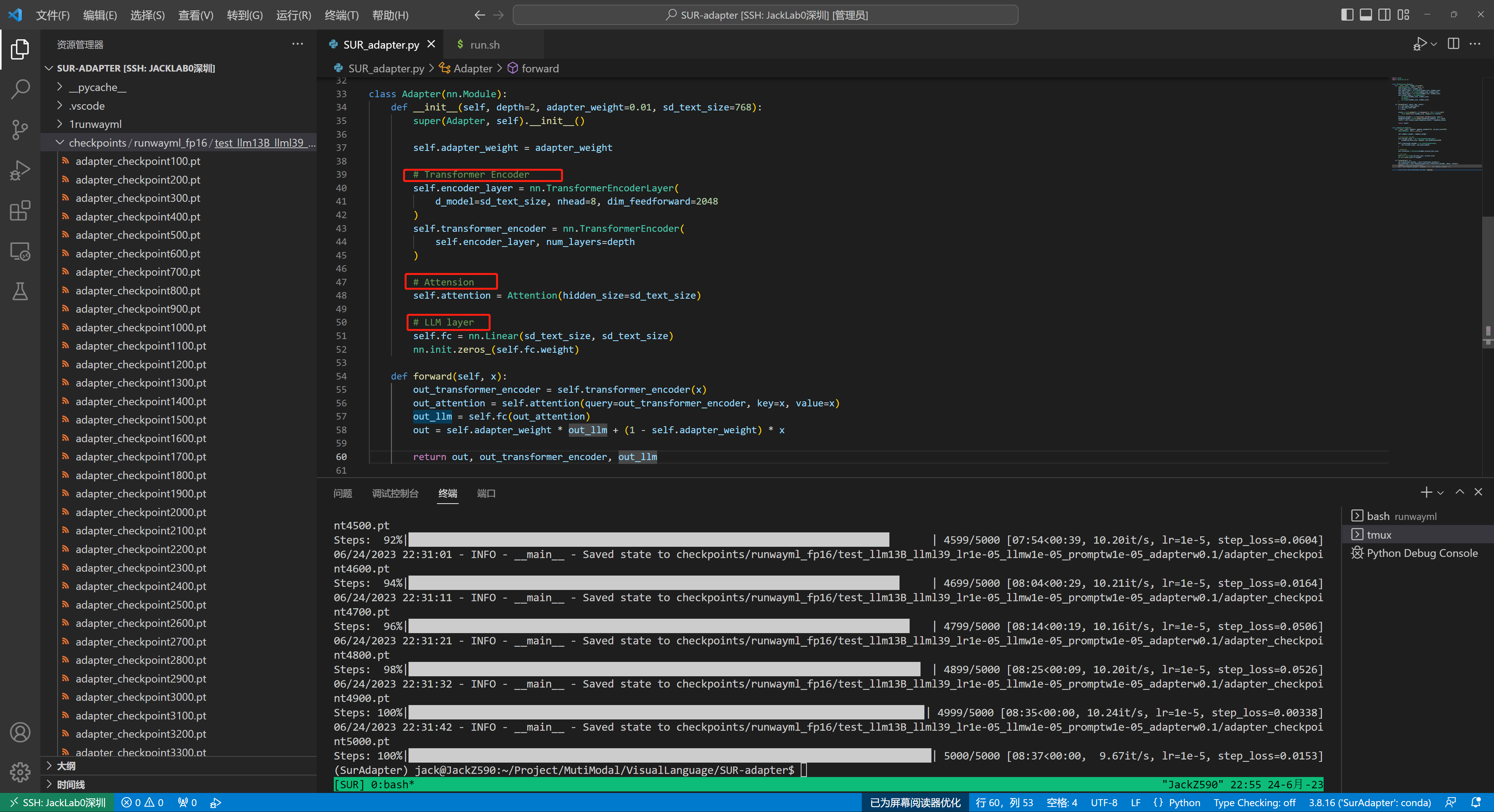
SUR模型训练细节
(1) 摘要
扩散模型可以在文本提示的引导下生成高质量、内容丰富的图像,已经成为流行的文本到图像生成模型。然而,当输入提示是简洁的叙述时,现有模型在语义理解和常识推理方面存在局限性,导致图像生成质量低。为了提高叙事提示的能力,我们提出了一种简单而有效的参数高效微调方法,称为语义理解和推理适配器(su -adapter),用于预训练的扩散模型。为了实现这一目标,我们首先收集并注释了一个新的数据集SURD,该数据集由超过57,000个语义校正的多模态样本组成。每个示例包含一个简单的叙述提示,一个复杂的基于关键字的提示和一个高质量的图像。然后,我们将叙述性提示的语义表示与复杂提示对齐,并将大型语言模型(llm)的知识通过知识蒸馏转移到我们的su -适配器,使其获得强大的语义理解和推理能力,从而构建用于文本到图像生成的高质量文本语义表示。我们通过整合多个llm和流行的预训练扩散模型来进行实验,以显示我们的方法在使扩散模型能够理解和推理简洁的自然语言而不会降低图像质量方面的有效性。我们的方法可以使文本-图像扩散模型更容易使用,并提供更好的用户体验,这表明我们的方法有潜力进一步推进用户友好的文本-图像生成模型的发展,通过弥合简单的叙事提示和复杂的基于关键字的提示之间的语义差距。该代码发布在https://github.com/Qrange-group/SUR-adapter
(2) 相关工作
近年来,基于扩散模型的多模态文本到图像生成技术取得了令人印象深刻的进步[50]。通过对这些模型[38,46]进行大量数据和模型参数的训练,人们可以通过文本提示和其他信息生成端到端的与文本相关且具有视觉吸引力的图像,而不需要复杂的绘画技能。然而, 在这些现有的扩散模型中,图像生成的质量严重依赖于基于关键字的文本提示或其他形式的文本提示的复杂而精细的设计。此外,如果文本提示是简明的叙述或日常表达的短语,则生成图像的保真度和文本相关性通常会受到严重损害。这种限制使得扩散模型难以通过具有优秀用户体验的简明叙述直观地控制。造成这一问题的最重要原因是,这些扩散模型的文本编码器通常是使用imagetext对比学习训练的预训练CLIP[34]的文本编码器,与文本到图像生成任务不一致,导致图像生成的语义理解和推理(SUR)较差。
具体来说,CLIP是一个使用对比学习对大约400M的图像-文本对进行训练的多模态神经模型,它的图像编码器和文本编码器由于能够成功地桥接图像和文本之间的关联,已被广泛应用于各种多模态任务或模型中,如扩散模型。虽然CLIP的学习目标是通过在特征空间中拉近匹配的图像和文本对来建立图像-文本对应关系,但是描述相应图像的文本很简短,并且可能只匹配图像中的部分语义,导致文本编码器生成的特征不完整。然而,文本到图像生成任务要求文本编码器不仅要理解简洁叙事的语义,还要推理和完成基于叙事的隐含常识或知识,以便模型能够生成与叙事高度一致的准确图像。因此,将CLIP的文本编码器嵌入到条件文本到图像生成的扩散模型中,由于文本编码器缺乏语义理解和常识推理能力,当输入文本为自然语言时,会导致图像生成质量低。
为了显示这些缺陷,我们首先使用多模态视觉问答[1,7,8,31]中三种常见的文本提示类型来评估扩散模型中文本编码器的语义理解能力:“计数”、“颜色”和“动作”。如表1所示,我们为每种类型设计了三种不同的提示符,对于每种文本提示符,我们使用文本到图像扩散模型[38]生成了130张图像,并手动评估生成的图像是否满足给定文本提示符的语义含义。通过对结果的统计分析,我们发现大多数文本提示的语义理解准确率不超过50%。令人惊讶的是,即使是“七个复古玻璃瓶”、“一对分别穿着蓝色和黄色纯色衣服的夫妇”这样看似简单的叙事提示也有0%的准确率,这说明扩散模型中的文本编码器完全没有理解这些简单文本在图像生成中的语义,导致了严重的信息偏差。图2(a)进一步说明了由于语义理解能力不足而导致语义错误的例子。

图2: 扩散模型中文本编码器的语义理解和常识推理能力。
接下来,我们考虑文本编码器的常识推理能力。如果我们希望稳定的扩散模型生成一只漂亮的猫,根据广泛验证的生成技术,我们需要一些复杂而精细的基于关键字的提示,以获得高质量的生成图像,例如以下提示:

我们可以观察到,使用复杂提示生成的图像,如图2 (b)所示,与使用简单提示(如“a beautiful cat”)生成的图像相比,具有更好的细节,更准确的轮廓,更精确的常识(例如猫的身体是自然的,没有扭曲的)。
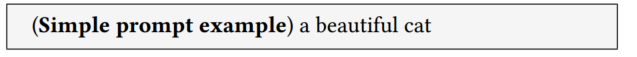
输入复杂的提示符,相当于直接将**“美”与“猫”之间的细节和理解注入到文字编码器中,让扩散模型生成令人愉悦的“美猫”。这表明扩散模型有可能生成语义上有意义的图像,但受到文本编码器常识推理能力的限制。简单的提示不能让文本编码器直接很好地理解“漂亮的猫”的含义,也不能从编码器自己的知识中演绎出“漂亮”的含义。面对这样的问题,ChatGPT和LLaMA[45]等大型语言模型(llm)的最新进展显示出惊人的会话能力**,提高了**(语义理解和推理)SUR**能力,在自然语言处理(NLP)领域创造了新的高度。因此,我们尝试用ChatGPT来描述“一只美丽的猫”,得到如下文本:

本文演示了LLM对“美丽”和“猫”的理解,以及对什么样的“猫”被认为是“美丽”的常识性推理。该文本生成的图像在质量上与使用复杂提示生成的图像相似,如图2 (b)右下角所示。
以上所有的案例研究都激励我们考虑是否可以将llm的SUR能力转移到预训练的扩散模型中,这样扩散模型即使使用简单的叙事提示也可以产生语义正确的高质量图像。
为了实现这一目标,在本文中,我们首先收集并注释了一个名为SURD的新数据集,该数据集由超过57,000个语义校正的图像-文本对组成。每个图像-文本对包含一个简单的叙述提示,一个复杂的基于关键字的提示和一个高质量的图像。利用SURD,我们提出了SUR适配器,将LLM的SUR能力转移到预训练的扩散模型中,并对齐简单和复杂提示的表示。大量的实验和统计测试证实,我们提出的sr -适配器显著增强了预训练扩散模型的文本编码器,并生成高质量的图像,减轻了简洁的叙事提示和生成图像之间的不匹配。总之,我们的贡献有三个方面:
-
我们收集并注释了一个数据集SURD,其中包括超过57,000个语义校正的图像-文本对。每个图像-文本对包含一个简单提示、一个复杂提示和一个高质量的相应图像。
-
基于SURD,我们提出了suradapter,将llm的语义理解和推理能力有效地转移到预训练的扩散模型上,缓解了语义不匹配和简单提示生成的低质量图像的问题。
-
我们使用拟议的sr -适配器对生成的图像进行了广泛的统计测试和讨论,以分析其有效性并进一步讨论其局限性。
(2-1) 文图生成 & LLM
扩散模型已广泛应用于文本到图像的生成[2,11,23,25,38,41,46]。文本到图像扩散利用文本输入作为扩散模型的调节信号,通过加噪和去噪过程生成与文本相关的图像[38]。文本到图像扩散的文本编码器通常通过利用预训练的语言模型(如CLIP[34])将文本输入编码为潜在向量来完成。文本到图像扩散广泛应用于各个领域,如图像超分辨率[27,42]、绘图[32]、操作[5,54]、语义分割[4,12]、视频生成[51,56]等。
最近,NLP领域见证了LLM的激增[17]。Jozefowicz等人[21]通过将lstm扩展到10亿个参数,在十亿字基准上取得了最先进的结果。随后,缩放变形导致了许多NLP任务的改进,值得注意的模型包括BERT[10]、GPT-2[35]、MegatronLM[43]和T5[37]。具有1750亿个参数的GPT-3模型[6]的引入标志着该领域的重大突破,并导致了众多llm的发展,如侏罗纪-1[29]、Megatron-Turing NLG[44]、Gopher[36]、Chinchilla[17]、PaLM[9]、OPT[57]、GLM[52]和LLAMA[45]。此外,一些研究[15,17,22,40,49]研究了缩放对LLM性能的影响,以提高其易用性。
(2-2) 语义理解和推理数据集
SURD是一个多模态数据集,由57,603个简单的叙事提示、复杂的基于关键字的提示和语义正确的图像组成,如图3所示。据我们所知,SURD是第一个记录简单和复杂提示的数据集,并专注于提供语义正确的图像-文本对,以帮助解决文本到图像扩散模型的SUR问题,这使得扩散模型能够仅基于简单提示生成语义一致的高质量图像。
(2-2-1) 数据收集
原始数据。为了构建内容丰富且语义可靠的数据集,我们广泛研究了各种具有可靠提示和高质量图像的开源图像生成网站。其中,我们选取了三个网站:Lexica 1、civitai 2和Stable Diffusion Online 3。在这些网站上,公开提供的图像通常语义正确,质量高,提示复杂。因此,我们收集来自网站的提示作为复杂提示。我们总共收集了114,148对**(11W)**图像-文本。
数据清洗。在第一步中,为了确保BLIP[13]生成的简单提示符的语义准确性,我们使用公开可用的预训练模型CLIP[34]进行语义清洗,因为大多数扩散模型中的文本编码器是CLIP模型的文本编码器,这将在4.1节中解释。如果CLIP模型判断一个简单提示的语义与对应图像的语义相匹配,扩散模型很可能能够根据简单提示生成相似的图像。对于每张图像,我们要求CLIP对其简单提示和复杂提示进行分类,以选择最符合图像语义的提示。一般来说,复杂的提示符通常包含其他语义上不相关的信息,例如图像质量描述,因此语义正确的简单提示符通常比复杂提示符具有更高的CLIP分数。因此,如果一个简单提示符的CLIP分数不低于对应的复杂提示符,我们保留样本。在基于CLIP分数的自动语义清洗之后,我们保留了66408个样本。在第二步中,我们进一步手动过滤第一步中保留的样本,以确保所有图像-文本对在语义上匹配。最后,SURD包含57,603个图像-文本对,其中每个图像-文本对包含一个图像、一个简单提示和一个复杂提示。
**LLM的知识。**由于我们希望从LLM中提取知识来提高文本编码器的语义理解和推理能力,我们也将LLM中简单提示的知识保存在向量中。具体来说,我们使用了最近开源的大型语言模型LLaMA[45],它有三种不同的参数大小:7B(32层,维度为4096)、13B(40层,维度为5120)和33B(60层,维度为6656)。对于每个简单提示,我们计算由LLM生成的每个令牌嵌入的平均值作为知识表示,以便我们可以统一处理不同长度的不同样本。
此外,我们将所有图像统一调整为512 × 512。关于BLIP、CLIP和LLM使用的更多细节可以在附录中找到。
(2-2-2) 数据分析
提示符的长度。图4显示了提示语的句子长度分布,(a)表示复杂提示语的分布,(b)表示简单提示语的分布。为了提高视觉清晰度,超过300字的提示被合并为300字。简单提示语的长度分布相对集中,句子长度集中在10句左右,与人类语言模式一致。相比之下,具有长尾分布的复杂提示不仅包含语义,还包含定义和图像质量信息,导致句子长度明显长于简单提示
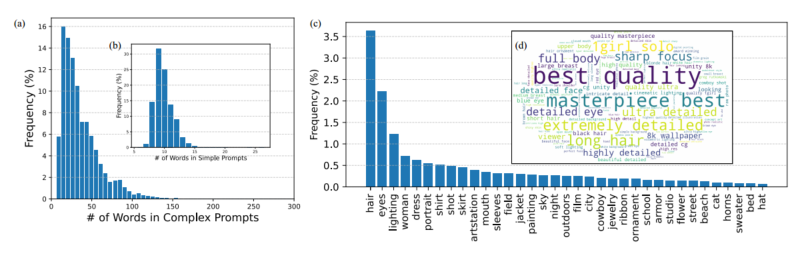
图4: (左)提示长度分布 和 (右)提示内容分布。
**提示内容。**文本到图像生成的提示符通常包含大量名词,由于图像由不同的对象组成,这些名词会极大地影响生成图像的质量和语义一致性。因此,我们对SURD中名词出现的频率分布进行统计分析,以展示文本和视觉内容的多样性。图4 ©显示了从SURD中选择的实体的频率比例分布。这些实体涵盖了各种各样的普通对象,如人、动物、植物和场景,表明了SURD内容的多样性。此外,这些实体的多样性可以使预训练的扩散模型在更复杂的场景中对文本和视觉内容具有较强的高层次理解能力。此外,我们还通过过滤掉停顿词,给出了如图4 (d)所示的文本词云,以说明SURD中文本词汇的整体分布情况。出现频率最高的短语,如“best quality”、“masterpiece best”和“extremely detail”,主要是对图像质量的约束,并且源于复杂的提示,这表明这些一致的文本约束对于高质量的图像生成很重要。因此,复杂提示符的语义表示将在通过微调增强su -adapter扩散模型中发挥至关重要的作用
(3) 模型
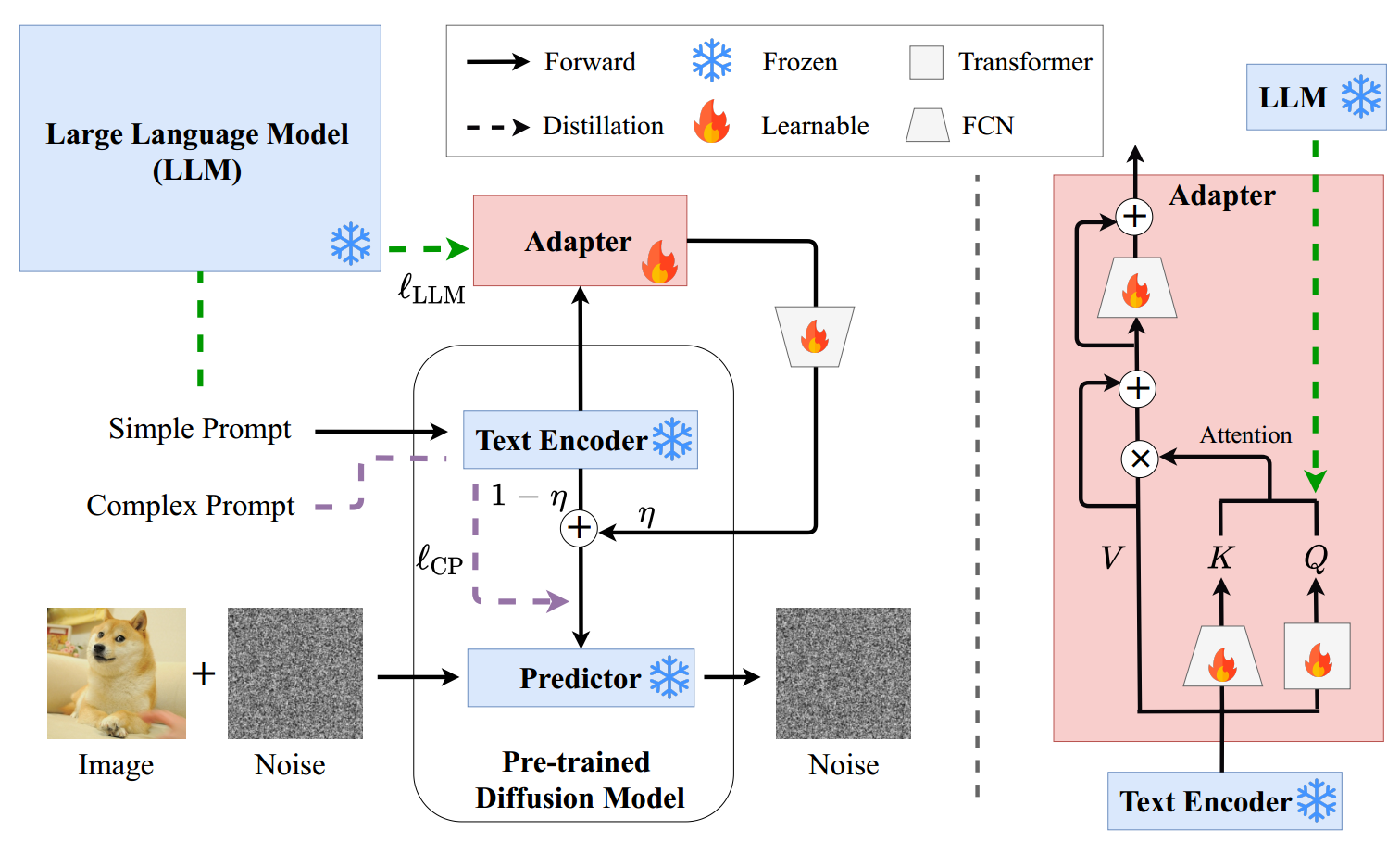
图5: suradapter的图示。FCN是一种全连接网络。(左)预训练扩散模型的微调管道。给定一个预训练的扩散模型,适配器用于转移大型语言模型的语义理解和推理能力,并在复杂和简单提示之间对齐表示。权重系数(weight coefficient)用来调整适配器的效果。(右)适配器的网络结构。
(3-1) 初步: Preliminary
扩散模型是一种很好的多模态图像生成方法,它通常包括两个阶段:(1)前向噪声处理。假设训练数据x0来自给定分布𝑝(x0),扩散模型首先得到序列x1, x2,…, x𝑇通过对x0添加𝑇轮噪声,如下所示:
q
(
x
t
∣
x
0
)
=
N
(
x
t
;
α
t
x
0
,
σ
t
2
I
)
q\left(\mathbf{x}_{t} \mid \mathbf{x}_{0}\right)=N\left(\mathbf{x}_{t} ; \alpha_{t} \mathbf{x}_{0}, \sigma_{t}^{2} \mathbf{I}\right)
q(xt∣x0)=N(xt;αtx0,σt2I)
略 (基本的Diff)

(3-2) SUR-adapter 微调思路
在本节中,我们将介绍用于可控文本到图像扩散模型的简单而有效的微调方法,称为语义理解和推理适配器(SUR-adapter)。让我们考虑图像文字对 ( p c i , p s i , I i ) i = 1 N \left(p_{c}^{i}, p_{s}^{i}, I^{i}\right)_{i=1}^{N} (pci,psi,Ii)i=1N 在清音的数据集,在 p c i p_{c}^{i} pci和 p s i p_{s}^{i} psi是复杂的和简单的提示,分别为𝑖-th高质量和语义正确的图像𝐼𝑖。如图5所示(左),我们首先冻结 f L L M f_{\mathrm{LLM}} fLLM大语言的所有可学的参数模型,文本编码器 f E n f_{\mathrm{En}} fEn,和使用预训练扩散模型的预测器 f p r e f_{\mathrm{pre}} fpre,然后我们添加两个可训练的神经网络,一个全连通网络(FCN)𝑔(·;𝜙1)和一个适配器𝑔Ada(·;𝜙2),可学的参数𝜙1和𝜙2。
(3-2-1) LLM知识蒸馏
LLM知识蒸馏。适配器𝑔Ada(·;𝜙2)的结构如图5(右)所示,它由三个可学习的变换组成,𝑗= 1,2,3的𝑗(·),它们使用全连接神经网络或Transformer实现[47]。为输出
f
E
n
(
p
s
i
)
f_{E n}\left(p_{s}^{i}\right)
fEn(psi)的文本编码,我们构建𝑄𝑖=ℎ3[
f
E
n
(
p
s
i
)
f_{E n}\left(p_{s}^{i}\right)
fEn(psi)]和𝐾𝑖=ℎ2[
f
E
n
(
p
s
i
)
f_{E n}\left(p_{s}^{i}\right)
fEn(psi)],并计算一个注意价值(10,47)
att
i
=
softmax
(
Q
i
K
i
T
d
)
\operatorname{att}_{i}=\operatorname{softmax}\left(\frac{Q_{i} K_{i}^{T}}{\sqrt{d}}\right)
atti=softmax(dQiKiT)
式中𝑑为𝑄妨妨性和𝐾妨妨性的特征维度。为了保证简单提示符的语义信息不被直接干扰,我们不做任何转换,直接设置了
V
i
=
f
E
n
(
p
s
i
)
V_{i}=f_{E n}\left(p_{s}^{i}\right)
Vi=fEn(psi) 。特别是,为了将LLM强大的语义理解和推理能力嵌入到文本中,我们通过以下损失函数从LLM中提取知识:
ℓ
L
L
M
(
ϕ
)
=
K
L
[
W
0
f
L
L
M
(
p
s
i
)
/
τ
,
Q
i
/
τ
]
,
\ell_{\mathrm{LLM}}(\phi)=\mathbf{K L}\left[\mathbf{W}_{0} f_{\mathrm{LLM}}\left(p_{s}^{i}\right) / \tau, Q_{i} / \tau\right],
ℓLLM(ϕ)=KL[W0fLLM(psi)/τ,Qi/τ],
这里,
τ
\tau
τ 为温度,一般设为1, KL为KL散度。W0是一个使用kaim初始化的随机初始化矩阵,是不可学习的,这保证了在对齐
f
L
L
M
(
p
s
i
)
f_{\mathrm{LLM}}\left(p_{s}^{i}\right)
fLLM(psi) 和𝑄之间的维数时,尽可能保留LLM的语义信息。此外,我们还得到了校准后的语义信息为:
V
i
′
=
V
i
V_{i}^{\prime}=V_{i}
Vi′=Vi 最后,通过可学习转换𝑔(·;𝜙1)对Adapter的输出进行转换,得到与之前工作一样具有LLM语义能力的输出𝑐LLM [14,20,58]:
g
{
g
A
d
a
(
f
E
n
(
p
s
i
)
;
ϕ
2
)
;
ϕ
1
}
=
g
{
V
i
′
+
V
i
+
h
1
[
V
i
′
+
V
i
]
;
ϕ
1
}
g\left\{g_{\mathrm{Ada}}\left(f_{E n}\left(p_{s}^{i}\right) ; \phi_{2}\right) ; \phi_{1}\right\}=g\left\{V_{i}^{\prime}+V_{i}+h_{1}\left[V_{i}^{\prime}+V_{i}\right] ; \phi_{1}\right\}
g{gAda(fEn(psi);ϕ2);ϕ1}=g{Vi′+Vi+h1[Vi′+Vi];ϕ1}
则输入到预测器的语义信息如下:
c
L
L
M
′
=
η
⋅
c
L
L
M
+
(
1
−
η
)
⋅
f
E
n
(
p
s
i
)
c_{\mathrm{LLM}}^{\prime}=\eta \cdot c_{\mathrm{LLM}}+(1-\eta) \cdot f_{E n}\left(p_{s}^{i}\right)
cLLM′=η⋅cLLM+(1−η)⋅fEn(psi)
其中𝜂是常数。
(3-2-2) 调校DM期间的性能维护
为了在微调过程中保持扩散模型的性能,我们通过Eq.(1)在图像
I
i
I_i
Ii中加入不同程度的噪声,并在简单提示
p
s
i
p_s^i
psi的指导下,将Eq.(7+4)得到的语义信息特征
c
LLM
′
c_{\text {LLM }}^{\prime}
cLLM ′提供给预测器。为了确保预训练的扩散模型在微调过程中对新图像
I
i
I_i
Ii保持足够的去噪能力,我们最小化了以下损失函数:
ℓ
simple
t
(
ϕ
)
=
E
∥
ϵ
−
ϵ
^
(
α
t
I
i
+
σ
t
ϵ
,
t
,
c
L
L
M
′
)
∥
2
2
,
\ell_{\text {simple }}^{t}(\phi)=\mathbb{E}\left\|\epsilon-\hat{\epsilon}\left(\alpha_{t} I_{i}+\sigma_{t} \epsilon, t, c_{\mathrm{LLM}}^{\prime}\right)\right\|_{2}^{2},
ℓsimple t(ϕ)=E∥ϵ−ϵ^(αtIi+σtϵ,t,cLLM′)∥22,
此外,为了确保增加的适配器在训练初期能够稳定地训练,并减少其对预训练扩散模型的不利影响,我们遵循先前作品[19,54]的设置,将参数𝜙1中矩阵的所有元素初始化为0。
(3-2-3) 调整复杂提示和简单提示的表示方式。
由第3节的描述可知,图像
I
i
I_i
Ii是由
p
c
i
p_c^i
pci生成的语义正确的高质量图像。为了生成足够的相似度和质量的图像
I
i
I_i
Ii,我们需要通过一个简单的提示。我们需要在
c
LLM
′
c_{\text {LLM }}^{\prime}
cLLM ′和
f
E
n
(
p
c
i
)
f_{E n}\left(p_{c}^{i}\right)
fEn(pci)之间对齐特征的语义表示。具体来说,我们考虑最小化以下损失函数:
ℓ
C
P
(
ϕ
)
=
KL
(
c
L
L
M
′
/
τ
,
f
E
n
(
p
c
i
)
/
τ
)
\ell_{\mathrm{CP}}(\phi)=\operatorname{KL}\left(c_{\mathrm{LLM}}^{\prime} / \tau, f_{E n}\left(p_{c}^{i}\right) / \tau\right)
ℓCP(ϕ)=KL(cLLM′/τ,fEn(pci)/τ)
其中,设置为式(5)中所示,KL为KL散度[26]。综上所述,sr -adapter训练的最终损失函数为:
ℓ
total
(
ϕ
)
=
λ
1
⋅
ℓ
LLM
(
ϕ
)
+
λ
2
⋅
ℓ
C
P
(
ϕ
)
+
λ
3
⋅
ℓ
simple
t
(
ϕ
)
,
\ell_{\text {total }}(\phi)=\lambda_{1} \cdot \ell_{\text {LLM }}(\phi)+\lambda_{2} \cdot \ell_{\mathrm{CP}}(\phi)+\lambda_{3} \cdot \ell_{\text {simple }}^{t}(\phi),
ℓtotal (ϕ)=λ1⋅ℓLLM (ϕ)+λ2⋅ℓCP(ϕ)+λ3⋅ℓsimple t(ϕ),
式中,
λ
i
≤
1
,
i
=
1
,
2
,
3
\lambda_{i} \leq 1, i=1,2,3
λi≤1,i=1,2,3 为损失系数;在算法1中给出了sur -adapter 的训练过程。经过训练,微调后的扩散模型可以使用与之前相同的采样方法生成图像。
(4) 实验
我们使用了两个预训练扩散模型(DMs)和三个具有不同参数的llm[45]。DM(1.5)[38]专门从事高分辨率图像合成和DM(卡通)2的现代训练动漫特色电影影像。LLM(𝑠)表示参数大小为𝑠的LLaMa模型。此外,我们用各种控制方法验证了sr -适配器的通用性。ControlNet[54]是一个引入附加条件的辅助网络。我们的实验包括2个典型的预训练控制网络,即使用控制网络进行边缘检测(canny)和使用控制网络进行语义分割(seg)。提示权重3是一种直接的技术,它为文本输入的特定部分分配更高的注意权重。MultiDiffusion[3]在预先训练的扩散模型之上定义了一个新的生成过程,该模型合并了多种扩散生成方法。在我们的实验中,我们对DM(1.5)和DM(卡通)使用了不同的调度器。自注意引导[18]提供了从不依赖高频细节的预测到完全条件图像的方向。从UNet自关注图中提取高频细节。
我们使用SURD数据集通过两种类型的度量来评估模型: 语义和质量。值得注意的是,所有的指标都是积极导向的。对于语义评价,我们设计了三种类型的提示[1,7,8,31],即Action, Color和Counting,每种类型有15个提示。这些提示用于评估基线和sr -适配器的语义功能。动作、颜色和计数都是百分比指标,表示满足不同类型语义的图像的比例。在测试期间,我们为每个提示生成10个图像。为了进一步评估语义质量,我们还使用了CLIP评分[34]。我们使用CLIP为基线和sr -适配器构建二元分类问题,并根据提示选择最合适的图像。使用Softmax后避免我们记录基线和SUR-adapter的分数,并使用测试集上的平均值作为扩散模型的最终CLIP分数。对于质量评价,我们使用了BRISQUE[33]、CLIP-IQA[48]、MUSIQ[24]和用户偏好研究。用户偏好研究由单选问题组成,用户从基线和sur -适配器生成的一对图像中选择质量最好的图像。我们从用户偏好研究中收集了89份有效问卷。在附录中,我们提供了详细的培训食谱。
表3: 第5.1节中描述的各种预训练模型和控制方法在各种质量指标方面的评估结果。我们计算了两个独立样本的得分均值的t检验,如果结果p值大于0.05,则表明基线和SURadapter的NR得分之间没有显著差异,表明它们的生成质量具有可比性。
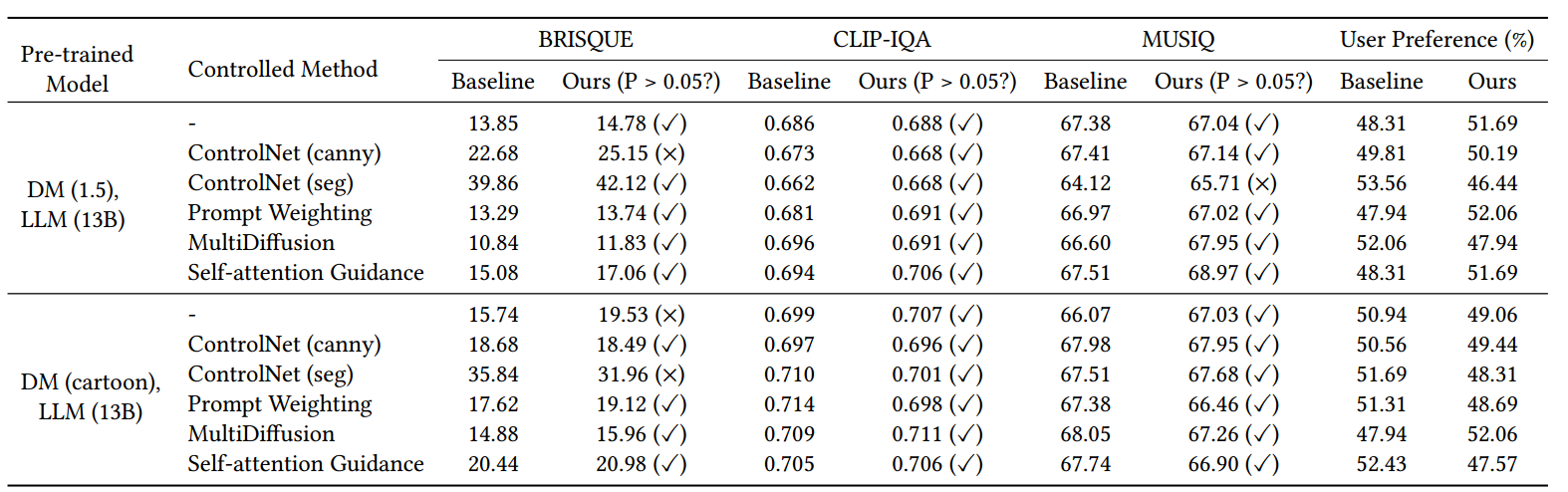
表4: 不同LLM设置下扩散模型的性能。粗体和下划线分别表示最优和次优性能。
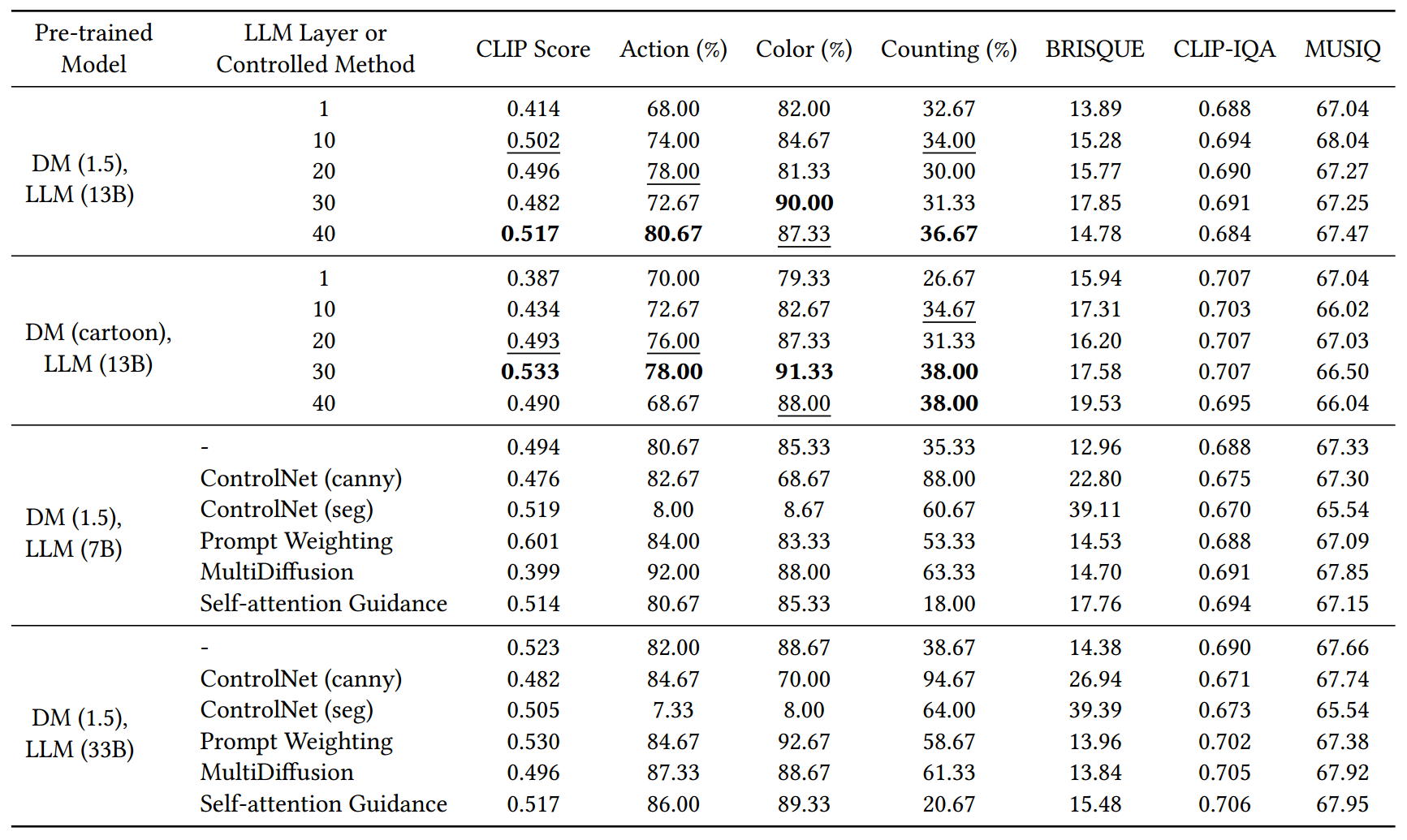
表2 显示了基线和sr -适配器的语义功能。值得注意的是,结果表明,在大多数情况下,SUR-adapter可以有效地提高基线的SUR性能。此外,我们可以得出以下结论:(a)使用Softmax在CLIP中获得相对分数会使CLIP分数不可靠,特别是当基线和sur -适配器产生同样差的结果时。例如,ControlNet (seg)获得了相对较高的分数,尽管它在动作和颜色上的生成效果低于标准。(b) ControlNet在计数分数方面表现良好,因为它利用了具有正确信息量的图像轮廓作为参考。©不准确的图像分割会导致使用ControlNet (seg)的扩散模型忽略语义信息,生成完全模糊的图像,从而导致Action和Color的生成效果不理想。然而,通过sr -adapter可以减轻ControlNet (seg)的负面影响。(d)预先训练的扩散模型的SUR能力可以通过使用提示加权和多重扩散来提高,并通过使用SUR适配器进一步提高。
表2: 5.1节中描述的各种预训练模型和控制方法在各种语义度量方面的评估结果。
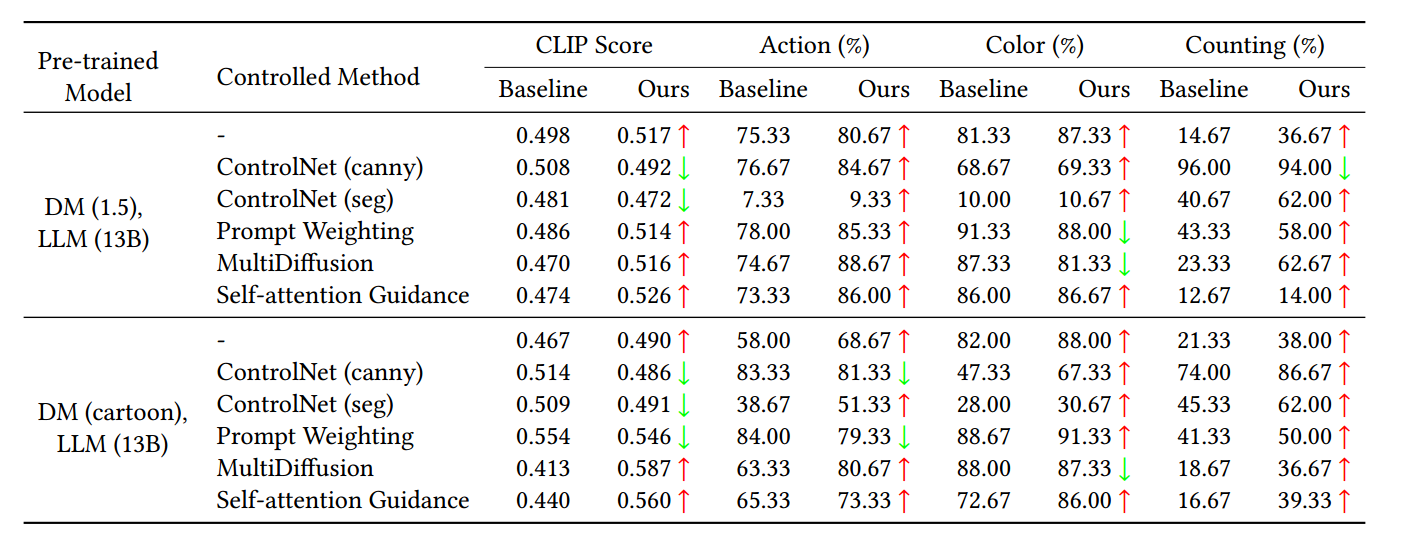
如表2所示,SUR-adapter改进扩散模型的能力有限,不能完全解决SUR问题。例如,改进后DM (1.5), LLM (13B)的计数只增加了36.67%。然而,解决SUR的不足可能需要大规模的多模态数据集来优化扩散模型的文本编码器,这是一项昂贵且具有挑战性的任务。此外,正如第6节所强调的,不同参数大小的llm在提取后的性能没有显著差异,这表明由于参数限制等因素,su -adapter只能从llm转移有限的语义知识。因此,SURadapter需要进一步的增强来更有效地从llm中提取语义信息。
总结:
在本文中,我们揭示了现有预训练扩散模型在理解语义和参与常识推理的能力方面的局限性,当以简单的叙事提示作为输入时,导致次优图像生成。为了缓解这个问题,我们引入了一个名为SURD的新数据集,它包含超过57,000个语义校正的图像文本对,以及可以从复杂的基于关键字的提示和大型语言模型中提取语义理解和推理知识的SURD适配器模块。在SURD上进行的大量实验和严格的评估表明,SURD适配器可以在不影响图像生成质量的情况下增强对扩散模型的语义理解。
2. Tango
(0) 总结
0625 和SUR-Adapter一样,会使用LLM将文本编码为一个更灵活的指令信息传递给Diff,不同的是Tango这里的Diff是需要重新调整学习的(StableDiff前半段的Encoder和Decoder是冻结的),也没有保留Simple的文本信息,并且Tango的输出还会经过HiFiGAN这样的预训练模型进行进一步解码。
文章中没有说损失函数的构成,这里我推测是由两部分构成,一部分是Diff本身的期望损失,另外一部分是LLM的损失,使得LLM模型的语义输出一直能够保持稳定。
(1) 摘要
最近的大型语言模型(LLM)的巨大规模允许许多有趣的属性,例如基于指令和思想链的微调,这在许多自然语言处理(NLP)任务中显著提高了零样本和小样本学习性能。受这些成功的启发,我们采用了这样一个指令调优的LLM FLAN-T5作为文本到音频(TTA)生成的文本编码器,该任务的目标是从文本描述生成音频。之前在TTA上的工作要么是预训练一个联合文本音频编码器,要么是使用一个非指令调谐模型,比如T5。因此,我们基于潜在扩散模型(LDM)的方法(TANGO)在大多数指标上优于最先进的AudioLDM,并且在AudioCaps测试集上保持可比性,尽管在小63倍的数据集上训练LDM并保持文本编码器冻结。这种改进也可能归因于采用基于音频压力级的声音混合来增强训练集,而之前的方法采用随机混合。
(2) 相关工作
在文本到图像(TTI)自动生成成功之后[31-33],许多研究人员采用与前者类似的技术,也成功地进行了文本到音频(TTA)生成[17,18,43]。这种模式可能在媒体制作中具有强大的潜在用例,因为创作者总是在寻找适合他们创作的新颖声音。这在制作原型或制作精确声音可能不可行的小型项目中尤其有用。除此之外,这些技术还为通用的多模态人工智能铺平了道路,可以同时识别和生成多种模态。
为此,现有作品使用大型文本编码器,如RoBERTa[19]和T5[30],对要生成的音频的文本描述进行编码。随后,大型变压器解码器或扩散模型生成音频先验,随后由预训练的VAE解码,然后是声码器。相反,我们假设用指令调优的大型语言模型(LLM)替换文本编码器将提高文本理解和整体音频生成,而无需任何微调,因为它最近发现了梯度下降模仿特性[4]。为了增加训练样本,现有的方法采用随机生成的音频对组合,以及它们的描述的串联。这样的混合没有考虑到源音频的整体压力水平,可能导致更大声的音频压倒更安静的音频。因此,我们采用Tokozume等人[39]提出的基于压力水平的混合方法。
我们的模型(TANGO) 1受到潜在扩散模型(latent diffusion model, LDM)[33]和AudioLDM[18]模型的启发。然而,我们没有使用基于clap的嵌入,而是使用了大型语言模型(LLM),因为它具有强大的表示能力和微调机制,可以帮助学习文本描述中的复杂概念。我们的实验结果表明,使用LLM大大提高了文本到音频的生成,并且优于最先进的模型,即使在使用小得多的数据集时也是如此。在图像生成的文献中,之前已经有撒哈拉等人研究了LLM的效果[35]。然而,他们认为T5是文本编码器,它没有在基于指令的数据集上进行预训练。FLAN-T5[3]使用T5检查点进行初始化,并在1.8K NLP任务数据集上进行指令和思维链推理方面的微调。通过利用基于指令的调优,FLAN-T5在几个NLP任务上实现了最先进的性能,与具有数十亿参数的llm的性能相匹配。
在第3节中,我们通过经验表明,尽管在小63倍的数据集上训练LDM,但在客观和主观评估下,TANGO在AudioCaps测试集的大多数指标上都优于AudioLDM和其他基线方法。我们认为,如果TANGO在更大的数据集(如AudioSet)上进行训练(如Liu等人[18]所做的那样),它将能够提供更好的结果,并提高其识别更广泛声音的能力。
本文的总体贡献有三个方面:
-
我们不使用任何联合文本-音频编码器(如clap)作为指导。Liu等[18]认为在训练过程中,基于clap的音频指导是提高训练成绩的必要条件。在训练和推理中,我们使用了一个冻结指令调优的预训练LLM FLAN-T5,它具有很强的文本表示能力,用于文本指导。
-
AudioLDM需要微调RoBERTa[19]文本编码器来预训练CLAP。然而,我们在LDM训练期间保持FLAN-T5文本编码器冻结。因此,我们发现LDM本身能够从一个比AudioLDM小63倍的训练集中学习文本到音频的概念映射和组合,给定一个指令调谐的LLM。
-
为了混合音频对以增强数据,受Tokozume等人[39]的启发,我们考虑音频对的压力水平,而不是像之前的AudioLDM工作那样随机组合。这确保了融合音频中两个源音频的良好表示。
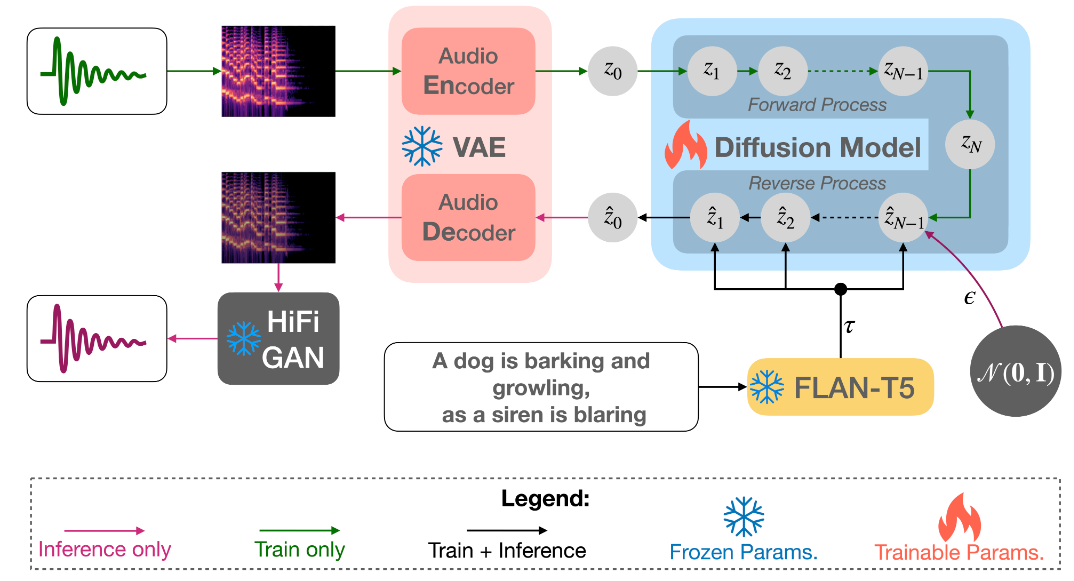
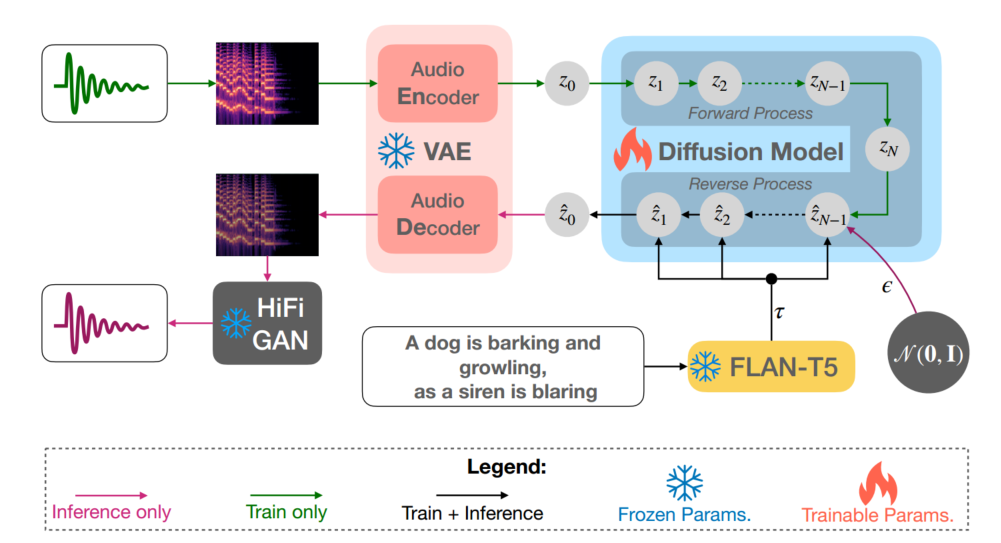
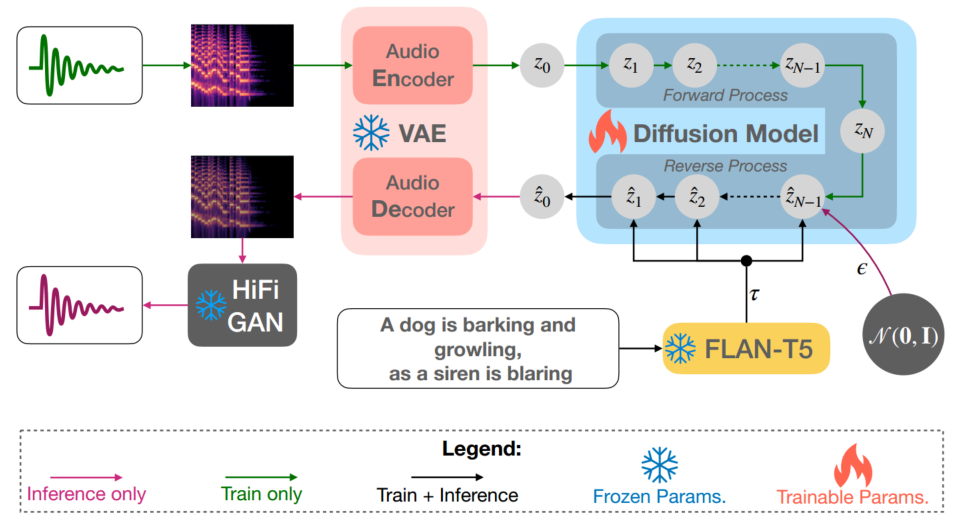
如图1所示,TANGO有三个主要组成部分:i)文本提示编码器,ii)潜在扩散模型(LDM),以及iii) mel- spectrum /audio VAE。文本提示编码器对音频的输入描述进行编码。随后,文本表示使用反向扩散从标准高斯噪声构建音频或音频先验的潜在表示。然后,mel- spectrum VAE解码器根据潜在音频表示构建mel- spectrum。该梅尔谱图被馈送到声码器以生成最终的音频。
(3) 模型
(3-1) 文本提示编码器
我们使用预训练的LLM FLAN-T5-LARGE (780M)[3]作为文本编码器(Etext),得到文本编码τ∈R L×dtext,其中L和dtext分别为令牌计数和令牌嵌入大小。由于FLAN-T5模型在大规模思维链(CoT)和基于指令的数据集上进行了预训练,Dai等人[4]假设他们能够通过注意力权重模拟梯度下降,从上下文信息中很好地学习新任务。这一特性在较老的大型模型中是缺失的,例如RoBERTa [19] (Liu等人[18]使用)和T5 [30] (Kreuk等人[17]使用)。考虑到每个输入样本都是一个不同的任务,我们可以合理地假设,梯度下降模拟特性可能是学习文本和声学概念之间映射的关键,而无需微调文本编码器。更丰富的预训练也可以让编码器更好地强调关键细节,更少的噪音和丰富的背景。这也可能导致将相关的文本概念更好地转化为声学对应。因此,我们保持文本编码器冻结,假设随后的反向扩散过程(见2.2节)能够在构建之前很好地学习音频的模态间映射。我们还怀疑微调Etext可能会降低其上下文学习能力,因为音频模态的梯度不在预训练数据集的分布范围内。这与Liu等人[18]形成对比,Liu等人将预训练的文本编码器作为文本-音频联合表示学习(CLAP)的一部分进行微调,以允许从文本中预先重建音频。在第3节中,我们通过经验表明,这种联合表示学习可能不是文本到音频转换所必需的。
(3-2) 文本引导生成的潜在扩散模型
潜在扩散模型(latent diffusion model, LDM)[33]改编自Liu等人[18],目的是在文本编码τ的指导下构建音频先验z0(见第2.5节)。这本质上简化为用参数化的pθ(z0|τ)逼近真实先验q(z0|τ)。
LDM可以通过正向和反向扩散过程来实现上述功能。正向扩散是一个预定噪声参数0 < β1 < β2 <···< βN < 1的高斯分布的马尔可夫链到z0的样本噪声版本:
q
(
z
n
∣
z
n
−
1
)
=
N
(
1
−
β
n
z
n
−
1
,
β
n
I
)
q
(
z
n
∣
z
0
)
=
N
(
α
ˉ
n
z
0
,
(
1
−
α
ˉ
n
)
I
)
,
\begin{array}{l} q\left(z_{n} \mid z_{n-1}\right)=\mathcal{N}\left(\sqrt{1-\beta_{n}} z_{n-1}, \beta_{n} \mathbf{I}\right) \\ q\left(z_{n} \mid z_{0}\right)=\mathcal{N}\left(\sqrt{\bar{\alpha}_{n}} z_{0},\left(1-\bar{\alpha}_{n}\right) \mathbf{I}\right), \\ \end{array}
q(zn∣zn−1)=N(1−βnzn−1,βnI)q(zn∣z0)=N(αˉnz0,(1−αˉn)I),
式中,N为正向扩散步数,αn =1−βn, αn = _1 αn。Song等[38]表明,通过重参数化技巧,可以通过非马尔可夫过程从z0直接采样任意zn,从而方便地从Eq.(1)推导出Eq. (2):
z
n
=
α
ˉ
n
z
0
+
(
1
−
α
ˉ
n
)
ϵ
z_{n}=\sqrt{\bar{\alpha}_{n}} z_{0}+\left(1-\bar{\alpha}_{n}\right) \epsilon
zn=αˉnz0+(1−αˉn)ϵ
其中噪声项为λ ~ N (0, I)。正向过程的最后一步产生zN ~ N (0, I)。反向过程通过使用损失的文本引导噪声估计(λ θ)对z0进行降噪和重构
L
D
M
=
∑
n
=
1
N
γ
n
E
ϵ
n
∼
N
(
0
,
I
)
,
z
0
∥
ϵ
n
−
ϵ
^
θ
(
n
)
(
z
n
,
τ
)
∥
2
2
\mathcal{L}_{D M}=\sum_{n=1}^{N} \gamma_{n} \mathbb{E}_{\epsilon_{n} \sim \mathcal{N}(\mathbf{0}, \mathbf{I}), z_{0}}\left\|\epsilon_{n}-\hat{\epsilon}_{\theta}^{(n)}\left(z_{n}, \tau\right)\right\|_{2}^{2}
LDM=n=1∑NγnEϵn∼N(0,I),z0
ϵn−ϵ^θ(n)(zn,τ)
22
其中,使用标准正态噪声ϵn从Eq.(3)中采样zn, τ为文本编码(参见2.1节)以作指导,γn为反步n的权值[6],以α1: n表示信噪比(SNR)。利用估计的噪声重构z0:
p
θ
(
z
0
:
N
∣
τ
)
=
p
(
z
N
)
∏
n
=
1
N
p
θ
(
z
n
−
1
∣
z
n
,
τ
)
p
θ
(
z
n
−
1
∣
z
n
,
τ
)
=
N
(
μ
θ
(
n
)
(
z
n
,
τ
)
,
β
~
(
n
)
)
μ
θ
(
n
)
(
z
n
,
τ
)
=
1
α
n
[
z
n
−
1
−
α
n
1
−
α
ˉ
n
ϵ
^
θ
(
n
)
(
z
n
,
τ
)
]
β
~
(
n
)
=
1
−
α
ˉ
n
−
1
1
−
α
ˉ
n
β
n
.
\begin{aligned} p_{\theta}\left(z_{0: N} \mid \tau\right) & =p\left(z_{N}\right) \prod_{n=1}^{N} p_{\theta}\left(z_{n-1} \mid z_{n}, \tau\right) \\ p_{\theta}\left(z_{n-1} \mid z_{n}, \tau\right) & =\mathcal{N}\left(\mu_{\theta}^{(n)}\left(z_{n}, \tau\right), \tilde{\beta}^{(n)}\right) \\ \mu_{\theta}^{(n)}\left(z_{n}, \tau\right) & =\frac{1}{\sqrt{\alpha_{n}}}\left[z_{n}-\frac{1-\alpha_{n}}{\sqrt{1-\bar{\alpha}_{n}}} \hat{\epsilon}_{\theta}^{(n)}\left(z_{n}, \tau\right)\right] \\ \tilde{\beta}^{(n)} & =\frac{1-\bar{\alpha}_{n-1}}{1-\bar{\alpha}_{n}} \beta_{n} . \end{aligned}
pθ(z0:N∣τ)pθ(zn−1∣zn,τ)μθ(n)(zn,τ)β~(n)=p(zN)n=1∏Npθ(zn−1∣zn,τ)=N(μθ(n)(zn,τ),β~(n))=αn1[zn−1−αˉn1−αnϵ^θ(n)(zn,τ)]=1−αˉn1−αˉn−1βn.
噪声估计
ϵ
^
θ
\hat{\epsilon}_{\theta}
ϵ^θ 用U-Net[34]参数化,其中包含交叉注意分量,以包含文本指导
τ
\tau
τ。而AudioLDM[18]则在训练过程中使用音频作为指导。在推理过程中,它们切换回文本指导,因为这是通过**预先训练的联合文本音频嵌入(CLAP)**来促进的。如2.1节所述,我们没有发现音频指导训练和预训练CLAP是必要的。
(3-3) 上升
许多文本到图像[28]和文本到音频[17]的研究表明,使用基于融合的增强样本进行训练,可以提高扩散网络的跨模态概念构成能力。因此,我们通过将现有音频对相互叠加并连接其字幕来合成额外的文本音频对。
与Liu等人[18]和Kreuk等人[17]不同的是,为了混合音频对,我们没有将它们随机组合。继Tokozume等人[39]之后,我们转而考虑人类听觉感知进行融合。具体来说,音频压力水平G被考虑在内,以确保高压水平的样品不会压倒低压水平的样品。音频样本的权重(x1)计算为相对压力水平(其分布见附录中的图2)
p
=
(
1
+
1
0
G
1
−
G
2
20
)
−
1
p=\left(1+10^{\frac{G_{1}-G_{2}}{20}}\right)^{-1}
p=(1+1020G1−G2)−1
式中G1和G2分别为两个音频样本x1和x2的压力级。这确保了音频样本和后期混音的良好表现。
此外,Tokozume等人[39]指出,声波的能量与其振幅的平方成正比。因此,我们将x1和x2混合为:
mix
(
x
1
,
x
2
)
=
p
x
1
+
(
1
−
p
)
x
2
p
2
+
(
1
−
p
)
2
\operatorname{mix}\left(x_{1}, x_{2}\right)=\frac{p x_{1}+(1-p) x_{2}}{\sqrt{p^{2}+(1-p)^{2}}}
mix(x1,x2)=p2+(1−p)2px1+(1−p)x2
(3-4) 无分类器引导
为了引导反向扩散过程重建音频先验z0,我们采用文本输入τ的无分类器制导[7]。在推理过程中,引导尺度w控制文本引导对噪声估计的贡献λ θ,相对于非引导估计,其中传递空文本:
ϵ
^
θ
(
n
)
(
z
n
,
τ
)
=
w
ϵ
θ
(
n
)
(
z
n
,
τ
)
+
(
1
−
w
)
ϵ
θ
(
n
)
(
z
n
)
\hat{\epsilon}_{\theta}^{(n)}\left(z_{n}, \tau\right)=w \epsilon_{\theta}^{(n)}\left(z_{n}, \tau\right)+(1-w) \epsilon_{\theta}^{(n)}\left(z_{n}\right)
ϵ^θ(n)(zn,τ)=wϵθ(n)(zn,τ)+(1−w)ϵθ(n)(zn)
我们还训练了一个模型,在训练过程中,10%的样本的文本指导被随机丢弃。我们发现这个模型的表现与一个总是对所有样本使用文本指导的模型相当。
(3-5) 音频VAE和声码器
音频变分自编码器(Audio variational auto-encoder, VAE)[13]将音频样本m∈R T ×F的梅尔谱压缩为音频先验z0∈R C×T /r×F/ R,其中C、T、F、R分别为信道数、时隙数、频隙数和压缩级别。LDM(见第2.2节)使用输入-文本指导τ重建音频先验z @ 0。编码器和解码器由ResUNet块[15]组成,并通过最大化证据下限(ELBO)[13]和最小化对抗损失[9]进行训练。我们采用Liu等人[18]提供的音频VAE检查点。因此,我们使用他们报告的最佳设置,其中C和r分别设置为8和4。
作为将音频- vae解码器生成的mel- spectrum转换为音频的声码器,我们也使用HiFi-GAN[14],如Liu等人[18]。
(4) 实验和评价
客观的评价。在这项工作中,我们使用了两个常用的客观指标:Frechet音频距离(FAD)和KL散度。FAD[11]是一种感知度量,适用于音频域的Fechet Inception Distance (FID)。与基于参考的指标不同,它在不使用任何参考音频样本的情况下测量生成音频分布与真实音频分布之间的距离。另一方面,KL散度[43,17]是一种依赖于参考的度量,它根据预训练的分类器生成的标签计算原始音频样本和生成音频样本分布之间的散度。虽然FAD更多地与人类感知有关,但KL散度根据原始音频信号和生成音频信号中存在的广泛概念捕获了它们之间的相似性。除FAD外,我们还使用Frechet Distance (FD)[18]作为客观指标。FD类似于FAD,但它用PANN代替了VGGish分类器。在FAD和FD中使用不同的分类器允许我们使用不同的特征表示来评估生成的音频的性能
主观评价。继Liu等人[18]和Kreuk等人[17]之后,我们要求六名人类评估者评估30个随机选择的基线和tango生成的音频样本的两个方面——整体音频质量(OVL)和与输入文本的相关性(REL),评分范围从1到100。评价者精通英语,并能很好地进行公平的评估。