机器学习涉及很多专业术语,为了避免混淆概念,我们在学习中,首先必须统一语言:即充分理解专业术语,并采用专业术语来描述机器学习相关的内容。本节将介绍几种基本的机器学习术语。
目录
1.标签
2.特征
3.示例
4.模型
5.回归与分类
6.损失
6.1 平方损失:一种流行的损失函数
6.2 损失低,也可能是一个糟糕的模型
7.数据分割
7.1 分割方式一
7.2 分割方式二
1.标签
标签是输出结果,即我们要预测的东西——如线性回归()中的
。标签可以是小麦的未来价格、图片中显示的动物种类、音频剪辑的含义,或者任何东西。
2.特征
特征是输入变量——如线性回归中的变量 。一个简单的机器学习项目可能只需使用单一特征,而更复杂的机器学习项目可能使用数百万个特征,指定为:
在垃圾邮件检测器示例中,特征可能包括以下内容:
- 电子邮件文本中的单词
- 寄件人地址
- 发送电子邮件的时间
- 电子邮件包含短语“一个奇怪的技巧”。
3.示例
一个示例是数据 的特定实例。(我们将
加粗以表明它是一个向量。)我们将示例分为两类:
- 标记示例
- 未标记的示例
带标签的示例——包括特征和标签,例如:
带标签的示例: {features, label}: (x, y)
使用带标签的示例来训练模型。在我们的垃圾邮件检测器示例中,标记的示例将是用户明确标记为“垃圾邮件”或“非垃圾邮件”的单个电子邮件。举个例子,下表显示了包含加利福尼亚州房价信息的数据集中的 5 个标记示例:
| 住房中位年龄(特征) | 客房总数(特征) | 卧室总数(特征) | 房屋价值中位数(标签) |
|---|---|---|---|
| 15 | 5612 | 1283 | 66900 |
| 19 | 7650 | 1901 | 80100 |
| 17 | 720 | 174 | 85700 |
| 14 | 1501 | 337 | 73400 |
| 20 | 1454 | 326 | 65500 |
未标记的示例——包含特征但不包含标签,例如:
未标记的示例: {features, ?}: (x, ?)
以下是来自同一住房数据集的 3 个未标记示例,其中不包括【房屋价值中位数】:
| 住房中位年龄(特征) | 客房总数(特征) | 卧室总数(特征) |
|---|---|---|
| 42 | 1686 | 361 |
| 34 | 1226 | 180 |
| 33 | 1077 | 271 |
一旦我们用带标签的示例训练了我们的模型,我们就使用该模型来预测未标记示例的标签。在垃圾邮件检测器中,未标记的示例是人类尚未标记的新电子邮件。
4.模型
模型定义了特征和标签之间的关系。例如,垃圾邮件检测模型可能会将某些特征与“垃圾邮件”密切相关。让我们重点介绍模型生命周期的两个阶段:
-
训练——即创建或学习模型。向模型输入带标签的示例,并使模型逐渐学习特征和标签之间的关系。
-
推理——即将训练好的模型应用于未标记的示例。使用经过训练的模型来做出有用的预测 。例如,在推理过程中,您可以预测未标记 “房屋价值中位数”
的示例。
5.回归与分类
回归模型预测连续值。例如,回归模型做出的预测可以回答如下问题:
-
加州的房子值多少钱?
-
用户点击此广告的概率是多少?
分类模型预测离散值。例如,分类模型做出的预测可以回答如下问题:
-
给定的电子邮件是垃圾邮件还是非垃圾邮件?
-
这是狗、猫还是仓鼠的图像?
6.损失
训练模型仅仅意味着学习(确定)所有权重的良好值以及来自标记示例的偏差。在监督学习中,机器学习算法通过检查许多示例并尝试找到最小化损失的模型来构建模型;这个过程称为经验风险最小化。
损失是对错误预测的惩罚。也就是说, 损失是一个数字,表明模型对单个示例的预测有多糟糕。如果模型的预测是完美的,则损失为零;否则,损失更大。训练模型的目标是找到一组在所有示例中平均损失较低的权重和偏差。例如,图 1 左侧显示高损失模型,右侧显示低损失模型。请注意该图的以下几点:
- 箭头代表损失
- 蓝线代表预测
- 圆圈代表实际值
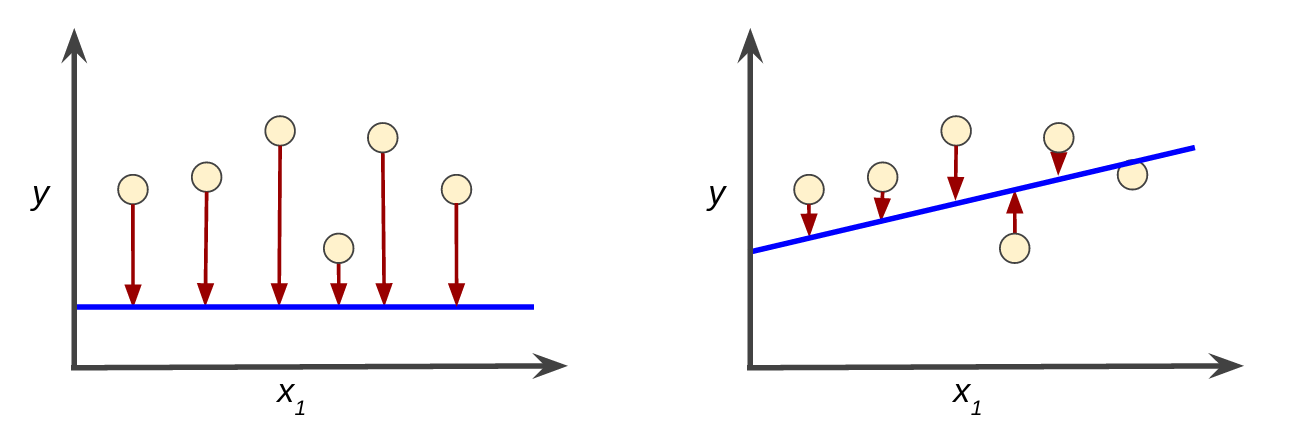
图 1 左侧模型中的高损失;正确模型的低损耗
请注意,左图中的箭头比右图中的箭头长得多。显然,右图中的线是比左图中的线更好的预测模型。您可能想知道是否可以创建一个数学函数(损失函数),以有意义的方式汇总各个损失。
6.1 平方损失:一种流行的损失函数
我们将在此处检查的线性回归模型使用称为平方损失(也称为 损失)的损失函数 。单个示例的平方损失如下:
= the square of the difference between the label and the prediction = (observation - prediction(x))2 = (y - y')2
均方误差( MSE ) 是整个数据集中每个示例的平均平方损失。要计算 MSE,请将各个示例的所有平方损失相加,然后除以示例数量:
在哪里:
是一个例子,其中
是模型用于进行预测的一组特征(例如,学历、年龄、性别)。
是示例的标签(例如温度、购物偏好)。
是权重和偏差与特征集相结合的函数。
是一个包含许多标记示例的数据集,这些示例是
-
是数据集
尽管 MSE 在机器学习中很常用,但它既不是唯一实用的损失函数,也不是适合所有情况的最佳损失函数。
6.2 损失低,也可能是一个糟糕的模型
如图 2 所示,假设这些图中的每个点代表一棵树在森林中的位置。两种颜色的含义如下:
- 蓝点代表生病的树。
- 橙色点代表健康的树木。

图 2 生病的(蓝色)树和健康的(橙色)树
您能想象一个好的模型来预测随后患病或健康的树木吗?花点时间在心里画一条弧线,将蓝色和橙色分开,或者在心里套住一批橙色或蓝色。然后,看图 3,它显示了某种机器学习模型如何将病树与健康树分开。请注意,该模型产生的损失非常低。

图 3 用于区分病树和健康树的复杂模型
乍一看,图 3 所示的模型似乎在区分健康树木和患病树木方面表现出色,或者做到了极地的损失。但是,它的泛华能力非常差。图 4 显示了我们向模型添加新数据时发生的情况。事实证明,该模型对新数据的适应能力非常差。请注意,该模型对许多新数据进行了错误分类。
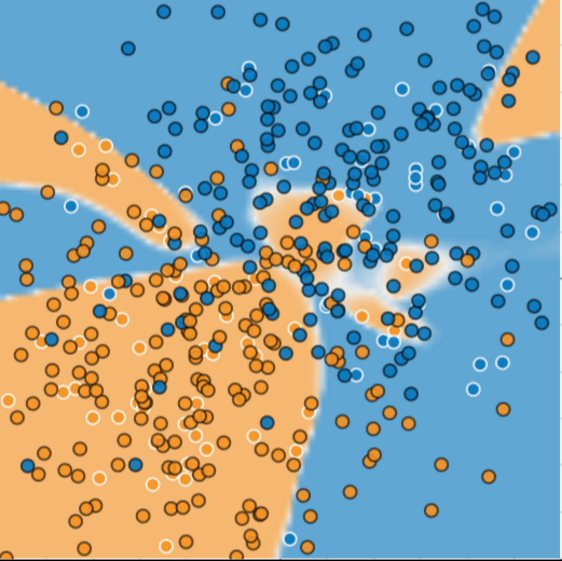
图 4 该模型在预测新数据方面表现不佳
图 3 中所示的模型过度拟合了其训练数据的特殊性。过度拟合模型在训练过程中损失较低,但在预测新数据方面表现不佳。如果一个模型能够很好地拟合当前样本,我们如何相信它能够对新数据做出良好的预测?过度拟合是由于模型变得过于复杂而导致的。机器学习的基本张力在于很好地拟合我们的数据,但又尽可能简单地拟合数据。
机器学习的目标是对从(隐藏的)真实概率分布中提取的新数据进行良好预测。不幸的是,模型无法看到全部真相;该模型只能从训练数据集中进行采样。如果一个模型很好地适合当前的示例,你如何相信该模型也能对从未见过的示例做出良好的预测?
7.数据分割
7.1 分割方式一
一种最朴素的思路,是将数据集分为两个子集——即训练集+测试集。
- 训练集——训练模型的子集。
- 测试集——测试训练模型的子集。
如图 5 所示,对单个数据集进行切片:

图 5 将单个数据集分割为训练集和测试集
确保您的测试集满足以下两个条件:
- 足够大以产生具有统计意义的结果。
- 代表整个数据集。换句话说,不要选择与训练集具有不同特征的测试集。
假设测试集满足上述的两个条件,目标是创建一个能够很好地推广到新数据的模型。我们的测试集充当新数据的代理。如图 6 所示,请注意,基于训练数据学习的模型非常简单,这个模型并不完美——一些预测是错误的。然而,该模型在测试数据上的表现与在训练数据上的表现一样好。换句话说,这个简单的模型不会过度拟合训练数据。

图 6 根据测试数据验证训练模型
切勿根据测试数据进行训练。 如果在评估指标上看到令人惊讶的良好结果,则可能表明我们不小心在测试集上进行了训练,或者测试数据已泄漏到训练集中(很好理解,相当于你提前拿到了考试卷和参考答案,考试当然可以取得好成绩,但这并非你真正掌握了知识,而是一种“作弊”行为)。
例如,一个使用主题行、电子邮件正文和发件人电子邮件地址作为特征来预测电子邮件是否为垃圾邮件的模型。我们将数据分割为训练集和测试集,比例为 80%,20%。训练后,模型在训练集和测试集上均达到 99% 的精度。我们预计测试集的精度较低,因此我们再次查看数据,发现测试集中的许多示例都是训练集中示例的重复项(我们忽略了删除相同垃圾邮件的重复条目)在分割数据之前来自我们输入数据库的电子邮件)。我们无意中对一些测试数据进行了训练,因此,我们不能准确地衡量我们的模型对新数据的泛化程度。
7.2 分割方式二
上面介绍了将数据集划分为训练集和测试集。这种分区使我们能够在一组示例上进行训练,然后针对另一组示例测试模型。对于两个分区,工作流程可能如图 7 所示:

图 7 可能的工作流程
在图 7 中,“调整模型” 意味着调整你可以想象的模型的任何内容——从改变学习率,到添加或删除特征,再到从头开始设计一个全新的模型。在此工作流程结束时,您选择在测试集上表现最好的模型。
将数据集分为两组是一个好主意,但不是万能的。通过将数据集划分为图 8 所示的三个子集,可以大大减少过度拟合的机会:

图 8. 将单个数据集分割成三个子集
使用验证集来评估训练集的结果。然后,在模型 “通过” 验证集后,使用测试集再次评估 。图 9 显示了这个新的工作流程:
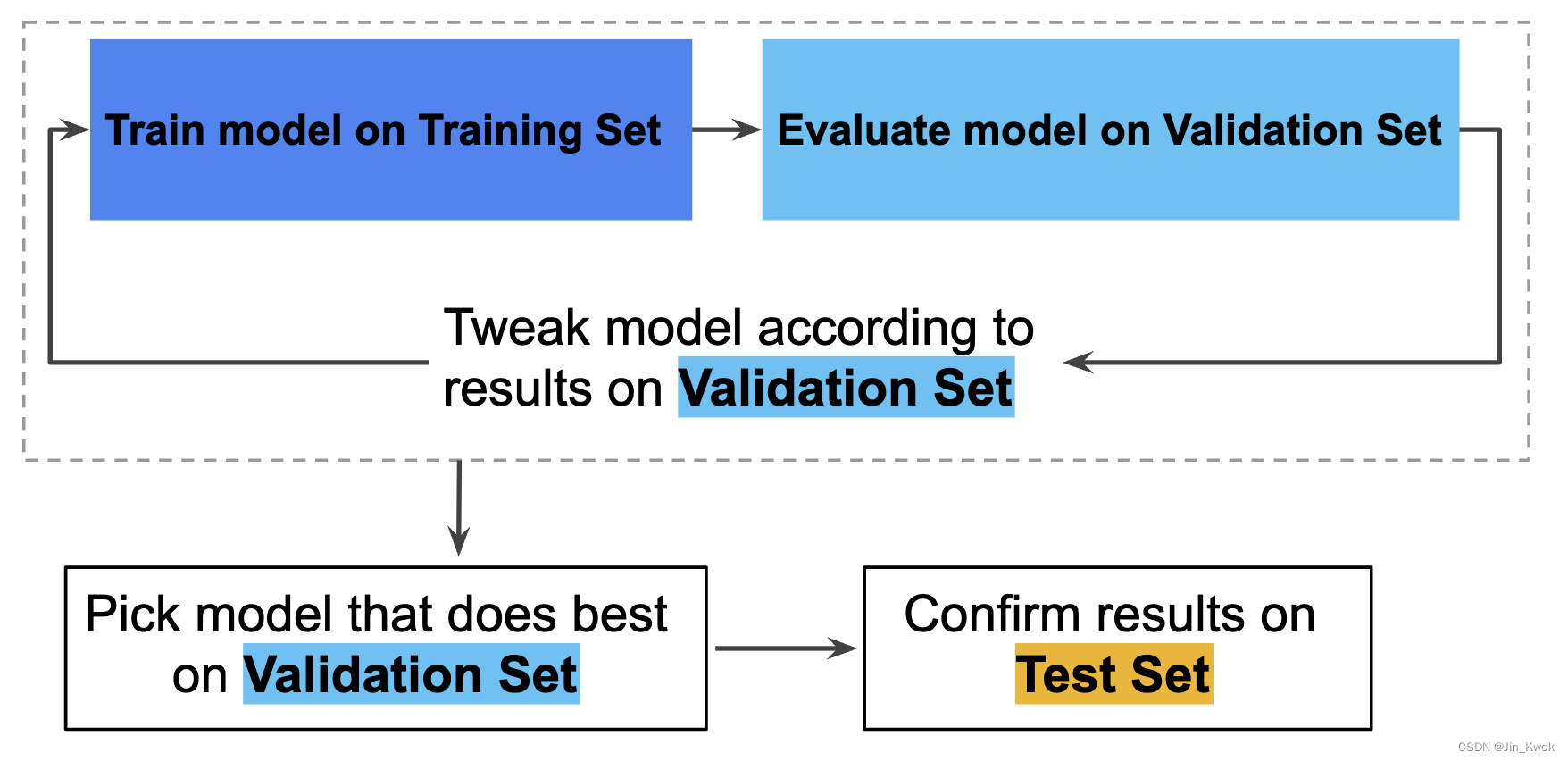
图 9 更好的工作流程
在这个改进的工作流程中:
- 选择在验证集上表现最好的模型。
- 根据测试集仔细检查该模型。
这是一个更好的工作流程,因为它减少了测试集的暴露。
8.参考文献
本文部分内容翻译自 英文资料(链接-https://developers.google.cn/machine-learning/crash-course/descending-into-ml/training-and-loss),感兴趣的读者可以查看原文。