1 JDBC回顾
Statement 语句执行者
Connection conn = null;
Statement st = null;
ResultSet rs = null;
try{
//1 通过工具类获得连接
conn = JdbcUtils.getConnection();
//2 获得语句执行者
st = conn.createStatement() --> 参数 结果集类型、并发参数 (滚动结果集)
//3 执行语句
int r = st.executeUpdate(sql); // DDL /DML(insert /update /delete)
rs = st.executeQuery(sql) ;
//DQL (select … from … where 查询条件 group by 分组字段 having 分组条件 order by排序字段)
//4 结果集处理
while(rs.next()) 查询所有
if(rs.next()) 查询一个
} catch(){
throw new …();
} finally{
JdbcUtils.closeResources(conn,st,rs);
}
PreparedStatement 预处理对象
try{
//1 获得连接
//2 必须准备sql语句
String sql = “select * from t_user where id = ?”; //update t_user set username = ? , password = ? where id = ?
//3 获得预处理对象
psmt = conn.prepareStatement(sql);
//4 设置实际参数
psmt.setString(1,100); //psmt.setString(1,“jack”) psmt.setString(2,“rose”) …
//5 执行
int r = psmt.executeUpdate();
rs = psmt.executeQuery(); //注意没有参数
}
工具类
//获得连接
// 1 注册驱动
Class.forName(“com.mysql.jdbc.Driver”);
// 2 获得
Connection conn = DriverManager.getConnection(“jdbc:mysql://localhost:3306/day16_db”,“root”,“1234”);
//释放资源
rs.close();
st.close();
conn.close();
预处理对象应用
1.防sql注入
2.大数据处理 IO
3.批处理
2 JDBC批处理
Statement 和 PreparedStatement 都提供批处理。
批处理:批量处理sql语句。
Statement的批处理,可以一次性执行不同的sql语句。应用场景:系统初始化(创建数据库,创建不同表)
PreparedStatement 的批处理,只能执行一条sql语句,实际参数可以批量。应用场景:数据的初始化
2.1 Statement
addBatch(sql) ,给批处理缓存中添加sql语句。
clearBatch(); 清空批处理缓存。
executeBatch() , 执行批处理缓存所有的sql语句。注意:执行完成之后缓存中的内容仍然存在。
2.2 PreparedStatement
addBatch() , 将实际参数批量设置缓存中。注意:获得预处理之前必须提供sql语句。
mysql 默认没开启批处理。
通过URL之后参数开启, ?rewriteBatchedStatements = true
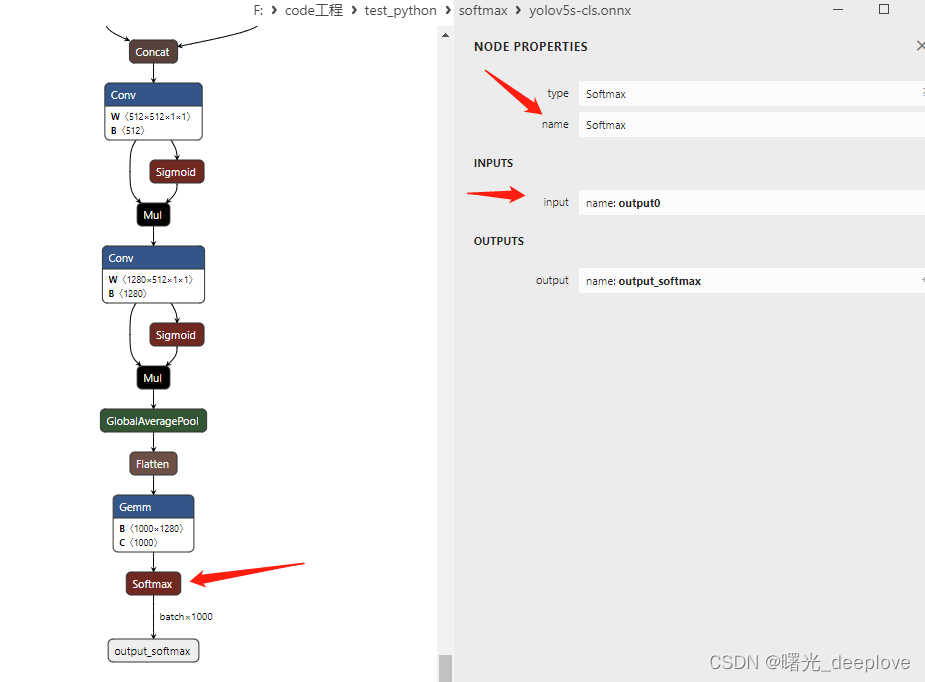
2.3 Oracle 使用
所有程序不需要修改
导入 oracle 驱动 jar包
注意:sql语句必须符合不同数据库。
mysql 和 oracle对比
mysql 使用database 管理 table
oracle 使用 user 管理table
启动
导入jar包
3 事务
思想:转账
汇款:update account set money = money - 100 where username = ‘jack’;
收款:update account set money = money + 100 where username = ‘rose’;
3.1 什么是事务
事务:一组业务逻辑操作,要么全部成功,要么全部不成功。
事务特性:ACID
原子性:一个事务是不可划分的一个整体。要么成功,要么不成功。
一致性:事务操作前后数据一致。(数据完整)。转账前后,两个人和一样的。
隔离性:多个事务对同一个内容并发操作。
持久性:事务提交,操作成功了。不能改变了。保存到数据库中了。
隔离问题
脏读:一个事务 读到 另一个 事务 没有提交的数据。
不可重复读:一个事务 读到 另一个事务 已经提交的数据。(update更新)
虚读(幻读):一个事务 读到 另一个事务 已经提交的数据。(insert插入) --理论时
事务隔离级别:用于解决隔离问题
1.读未提交:read uncommitted,一个事务读到另一个事务没有提交的数据。存放问题:3个
2.读已提交:read committed,一个事务读到另一个事务提交的数据。解决:脏读,存在2个问题
3.可重复读:repeatable read ,一个事务中读到数据重复的。及时另一个事务已经提交。解决:脏读、不可重复读,存放1个问题。
4.串行化,serializable,单事务,同时只能一个事务在操作。另一个事务挂起(暂停)。解决:3个问题。
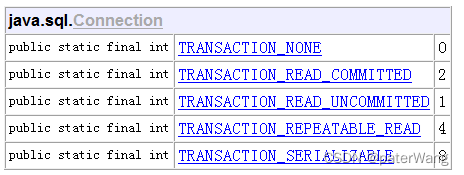
mysql默认隔离级别:repeatable read
oracle默认隔离级别:read committed
对比:
性能:read uncommitted > read committed > repeatable read > serializable
安全:read uncommitted < read committed < repeatable read < serializable
3.2 事务操作
mysql 命令操作
开启事务:mysql> start transaction; --开启相当于关闭自动提交
提交事务:mysql> commit; --全部成功
回滚事务:mysql> rollback; --保证全部不成功
jdbc java代码操作【掌握】-- JDBC中必须使用Connection连接进行事务操作。
开启事务:conn.setAutoCommit(false);
提交事务:conn.commit();
回滚事务:conn.rollback();
mysql 默认事务提交的,及每执行一条sql语句就是一个事务。
扩展:oracle事务默认不提交,需要手动提交。
分析
mysql> show variables like ‘%auto%’;
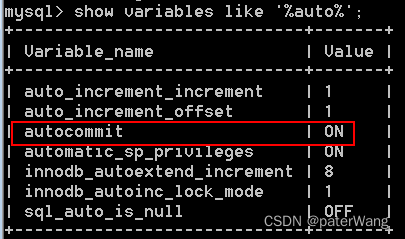
关闭自动提交,0等效off :mysql> set autocommit = 0;
ABCD整体
try{
//1开启事务
conn.setAutoCommit(false);
ABCD
//2 提交事务
conn.commit();
} catch(){
//3 回滚
conn.rollback();
}
3.3 隔离级别演示(了解)
mysql 命令 事务隔离级别的设置
读未提交:read uncommitted
A 隔离级别:读未提交
AB 同时开启事务
A 先查询 --正常数据
B 更新,但未提交
A 再查询 – 读到B没有提交的数据
B 回滚
A 再查询 – 读到回滚后的数据
读已提交: read committed
A 隔离级别:读已提交
AB 同时开启事务
A 先查询 --正常
B 更新,但未提交
A 再查询 – 之前数据,解决问题:脏读
B 提交
A 再查询 – 已经提交的数据。问题:不可重复读
可重复读: repeatable read – 保证当前事务中读到的是重复的数据
A 隔离级别:可重复读
AB 同时开启事务
A 先查询 --正常
B 更新,但未提交
A 再查询 – 之前数据,解决:脏读
B 提交
A 再查询 – 之前数据,解决:不可重复读
A 回滚|提交
A 再查询 – 更新后数据,新事务获得最新数据
串行化:serializable 单事务
A 隔离级别:串行化
AB 同时开启事务
A 先查询 --正常
B 更新 – 等待 (对方事务结束 ,超时)
3.4 保存点
Savepoint 保存点,用于记录程序执行位置,方便可以随意回滚指定的位置。spring 事务的传播行为
AB整体(必须),CD整体(可选)
Savepoint savepoint = null;
try{
// 1 开启事务
conn.setAutoCommit(false);
A
B
// 记录保存点
savepoint = conn.setSavepoint();
C
D
//2 提交ABCD
conn.commit();
} catch(){
if(savepoint != null){
//CD 有异常,回滚到CD之前
conn.rollback(savepoint);
// 提交AB
conn.commit();
} else {
//AB有异常 ,回滚到最开始处
conn.rollback();
}
}
3.5 丢失更新 lost update
A 查询数据,username = ‘jack’ ,password = ‘1234’
B 查询数据,username=“jack”, password=“1234”
A 更新用户名 username=“rose”,password=‘1234’ --> username=“rose”,password=“1234”
B 更新密码 password=“9999” ,username=“jack” --> username=“jack”,password=‘9999’
丢失更新:最后更新数据,将前面更新的数据覆盖了。
解决方案:采用锁机制。
乐观锁:丢失更新肯定不会发生。
给表中添加一个字段(标识),用于记录操作版本。
username=“jack”,password=“1234”,version=“1” ,比较版本号,如果一样,修改版本自动+1.。如果不一样,必须先查询,再更新。
悲观锁:丢失更新肯定会发生。采用数据库锁机制。
读锁:共享锁,大家可以一起读。
select … from … lock in share mode;
写锁:排他锁,只能一个进行写,不能有其他锁(写、读),所有更新update操作丢将自动获得写锁。
select … from … for update;
注意:数据库的锁,必须在事务中使用。
只要事务操作完成(commit|rollback|超时)自动释放锁
4 事务:案例
服务器端三层体系架构:web层、service、dao层。
dao层:操作数据库(insert/update/delete/select)
service 层:进行事务管理
ThreadLocal
JDK提供工具类,ThreadLocal,线程局部变量
作用:在一个线程中共享数据。
获得当前线程,Thread.currentThread();及就是ThreadLocal底层的key
api
* set(value)
* get()
* remove()
5 连接池
为什么使用连接池:连接Connection 创建与销毁 比较耗时的。为了提供性能,开发连接池。
什么是连接池:
javaee规范规定:连接池必须实现接口,javax.sql.DataSource (数据源)
为了获得连接 getConnection()
连接池给调用者提供连接,当调用者使用,此链接只能供调动者是使用,其他人不能使用。当调用者使用完成之后,必须归还给连接池。连接必须重复使用。
自定义连接池:
第三方连接池:
DBCP,apache
C3P0 ,hibernate 整合
tomcat 内置(JNDI)
5.1 DBCP
apache提供 commons 一个成员
导入jar包
核心类 BasicDataSource

手动编写
使用BasicDataSource,设置基本参数,设置优化参数
//1 创建核心类
BasicDataSource dataSource = new BasicDataSource();
//2 配置4个基本参数
dataSource.setDriverClassName(“com.mysql.jdbc.Driver”);
dataSource.setUrl(“jdbc:mysql:///day16_db”);
dataSource.setUsername(“root”);
dataSource.setPassword(“1234”);
//3 管理连接配置
dataSource.setMaxActive(30); //最大活动数
dataSource.setMaxIdle(20); //最大空闲数
dataSource.setMinIdle(10); //最小空闲数
dataSource.setInitialSize(15); //初始化个数
配置使用
DBCP采用properties文件,key=value ,key为 BasicDataSource属性(及setter获得)
//0 读取配置文件
InputStream is = TestDBCP.class.getClassLoader().getResourceAsStream(“dbcpconfig.properties”);
Properties properties = new Properties();
properties.load(is);
//1 加载配置文件,获得配置信息
DataSource dataSource = BasicDataSourceFactory.createDataSource(properties);
5.2 C3P0
第三方 非常优秀 连接池
导入jar包
核心类:ComboPooledDataSource
手动使用api:设置基本4项,及优化项
//1 核心类 (日志级别:debug info warn error)
ComboPooledDataSource dataSource = new ComboPooledDataSource();
//2 基本4项
dataSource.setDriverClass(“com.mysql.jdbc.Driver”);
dataSource.setJdbcUrl(“jdbc:mysql:///day16_db”);
dataSource.setUser(“root”);
dataSource.setPassword(“1234”);
//3 优化
dataSource.setMaxPoolSize(30); //最大连接池数
dataSource.setMinPoolSize(10); //最小连接池数
dataSource.setInitialPoolSize(15); //初始化连接池数
dataSource.setAcquireIncrement(5); //每一次增强个数
配置文件:
位置:WEB-INF/classes (classpath , src)
名称:c3p0-config.xml
//1 c3p0…jar 将自动加载配置文件。规定:WEB-INF/classes (src) c3p0-config.xml
//ComboPooledDataSource dataSource = new ComboPooledDataSource(); //自动从配置文件
ComboPooledDataSource dataSource = new ComboPooledDataSource(“itheima”); //手动指定配置文件
5.3 tomcat管理连接池
JNDI(Java Naming and Directory Interface,Java命名和目录接口)是SUN公司提供的一种标准的Java命名系统接口,用于存放java任意对象,给对象进行命名(使用目录结构)。例如:/a/b/c
作用:在多个项目之间共享数据,只需要传递名称,就可以获得对象。
理解:JNDI 就是一个容器,用于存放任意对象。
tomcat 将连接池存放 JNDI容器,可以获得使用。使用前提必须通知tomcat进行存放,默认情况下tomcat没有存放。
- 给tomcat配置数据源(连接池),使用
方式1:%tomcat%/conf/server.xml -->
方式2:%tomcat%/conf/Catalina/localhost/day16.xml —>
/META-INF/Context.xml 自动发布到“方法2”指定位置
<Context>
<!--
name 存放进去名称
auth 存放位置
type 确定存放内容,tomcat将通过指定接口创建实例,底层使用DBCP
其他都是DBCP属性设置
-->
<Resource name="jdbc/itheima" auth="Container" type="javax.sql.DataSource"
maxActive="100" maxIdle="30" maxWait="10000"
username="root" password="1234" driverClassName="com.mysql.jdbc.Driver"
url="jdbc:mysql://localhost:3306/day16_db"/>
</Context>
2 从JNDI容器获取,在当前项目web.xml配置
<!-- 给当前项目配置,从JNDI容器获得指定名称内容 -->
<resource-ref>
<res-ref-name>jdbc/itheima</res-ref-name>
<res-type>javax.sql.DataSource</res-type>
<res-auth>Container</res-auth>
</resource-ref>
- 使用
//0 包名:javax.naming
//1 初始化JNDI容器
Context context = new InitialContext();
//2 获得数据源 固定 “java:/comp/env”
DataSource dataSource = (DataSource)context.lookup(“java:/comp/env/jdbc/itheima”);
JavaEE 13核心
servlet/jsp/xml/jndi —> ejb (spring取代)
JDBC事务操作
事务:概念、特性、隔离问题、隔离级别(读)
C3P0连接池使用,使用xml配置 c3p0-config.xml
2.DBCP 优先配置
3.保存点、丢失更新、JNDI,JDBC批处理