论文题目:
Self-supervised Learning Representation based Accent Recognition with Persistent Accent Memory
作者列表:
李睿,谢志伟,徐海华,彭亦周,刘和鑫,黄浩,Chng Eng Siong
研究背景
口音识别 (AR) 是一项重要且具有挑战性的任务。因为口音不仅包含说话人的语音特征,还包括区域信息,这对于说话人识别[1]和语音识别[2]可能至关重要。然而, 大规模的口音标记数据很难获得,因此它是一项低资源任务。因此,要获得理想的 AR 系统,需要同时充分利用数据和模型建模效率。
本文方案
本文旨在从两个角度提高 AR 性能。首先,为了缓解数据不足的问题,我们使用从预训练模型WavLM[3]中提取的自我监督学习表示 (SSLR) 来构建 AR 模型。在 SSLRs 的帮助下,与传统的声学特征相比,它获得了显著的性能提升。其次,我们提出了一种持久性口音记忆 (PAM) 作为上下文知识来偏置 AR 模型。AR 模型的编码器从所有训练数据中提取的口音嵌入被聚类以形成口音码本,即 PAM。此外,我们提出了多种注意机制来研究 PAM 的最佳使用。我们观察到,通过选择最相关的口音嵌入可以获得最佳性能。
1.为了缓解数据不足的问题,我们使用从预训练模型中提取的自我监督学习表示 (SSLRs) 来构建 AR 模型。

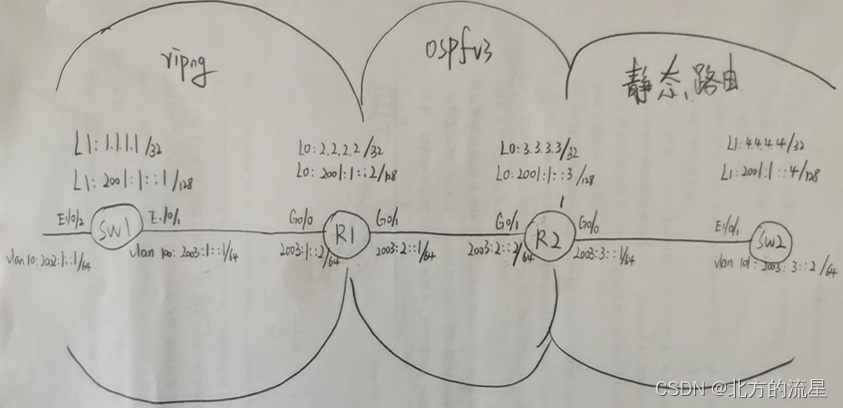
图 1 多任务主干模型
表1 使用 WavLM 提取的 SSLRs 在测试集的准确率

首先,我们使用 WavLM 提取的 SSLRs代替传统的声学特征Fbank训练模型。从表 1 的系统1-5可以看出,与使用传统声学特征的 Fbank 从头开始训练的系统相比,使用 WavLM 提取的 SSLRs 可以显著提高 AR 的性能。其次,在中间偏上的编码器中提取的 SSLRs 训练模型的效果要比低层编码器的 SSLRS效果好,在第 20 层达到最好的结果。最后,根据表 1 在不同口音上的准确率,我们会发现不同层编码器提取的 SSLRs 对不同口音提供的有效信息是不一样的。那么我们会产生一个问题,如何将不同层的 SSLRs对于不同口音提供的有效信息结合起来,从而提高所有口音的准确率?
2.我们提出了一种持久性口音记忆 (PAM) 作为上下文知识来偏置 AR 模型。
具体来说,PAM是一个包含 256 个 embedding 的码本,它是从使用 WavLM SSLRs 训练的 AR模型的编码器由训练集数据输出聚类而来。训练集包含 8 个口音,我们将每个口音对应音频的embedding使用 k-means 聚成 32个 embedding,最终得到256 个 embedding,称之为 PAM。其中,“持久性”表示这 256 个 embedding 在训练期间不会更新。
3.为了利用口音上下文信息,我们尝试了多种注意力机制。
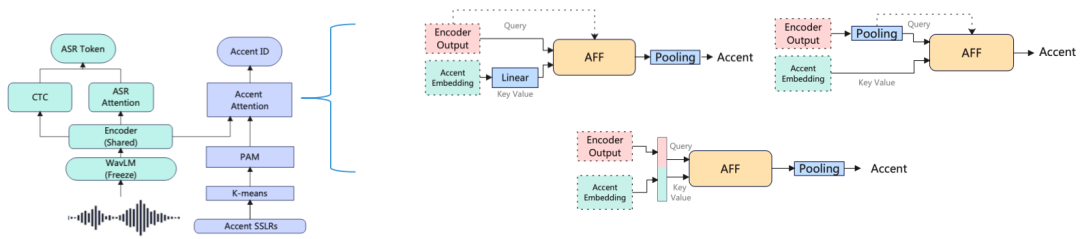
图 2 不同的注意力机制
(1) 帧级交叉注意力融合: 将编码器的输出作为 query,PAM 作为 key 和 value,注意力机制作用在帧级别上。
(2) 话语级交叉注意力融合:通过池化将编码器的输出在话语级别上,由于 PAM 也是话语级别的。这实现了所有注意力组件,如 query,key 和 value 都在同等话语级别,使注意力具有明确的语意。
(3) 拼接 PAM 自注意力融合:将编码器的输出与PAM 在时间维度进行拼接,并在整个序列做自注意力操作。动机是通过让编码器通过口音上下文来偏置编码器输出,进而提高 AR 性能。
4.为了更好地利用口音上下文信息,我们提出了 N-best 持久口音记忆选择方法。
当我们使用不同的注意力机制时,它的局限性在于 PAM 中的 embedding全部被考虑,这会导致过于冗余,因为我们认为模型在训练过程中,只需要考虑跟当前口音相同或相似的 embedding 的信息。所以我们提出了N-best 持久口音记忆选择方法。N 表示根据 PAM 中的 embedding与编码器输出之间的相似性得分从 PAM 中选择的 embedding 的数量。方法架构如图 3 所示。
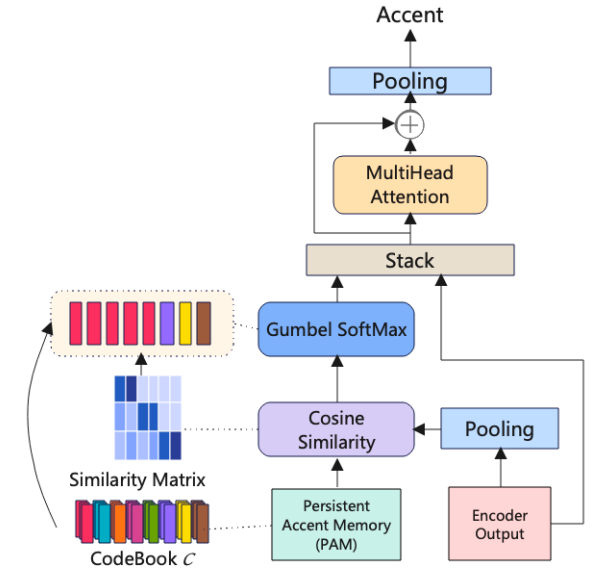
图 3 N-best持久口音记忆选择方法
实验结果
表 2 展示了所有基于注意力方法的实验结果,为了验证我们提出的方法的有效性和通用性,“Oracle”代表 PAM 是由每个口音对应的最好表现的口音识别模型提取的 embedding 构建的,另外两个是基于最后一层输出和整体加权和输出,分别表示为“layer-24”和“layers:1-24”。我们发现所有方法相较于基线都有提升,而且 N-best 选择方法达到最佳性能。
表2 使用 PAM 在测试集上的准确率
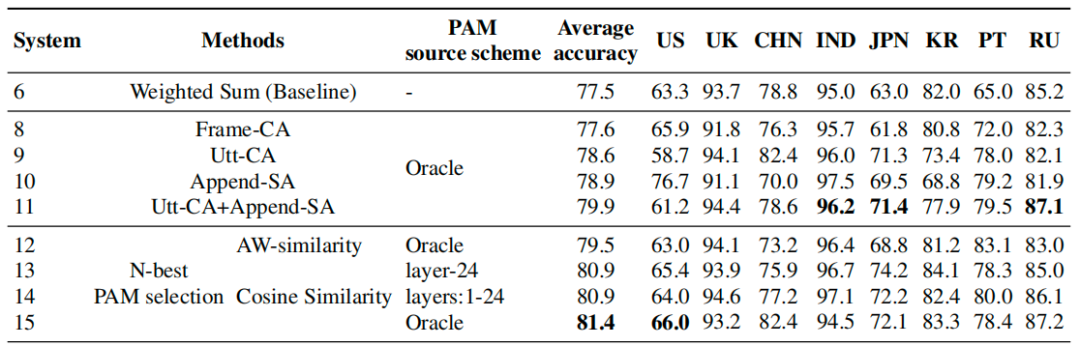
表3 N在N-best PAM选择方法中的作用

此外,我们研究了不同的 N 对 N-best 选择方法的影响,如表 3 所示。N等于 64 时,模型显示出了最高的准确性。然而,更大的 N 并不一定会产生更高的性能,同时会导致更高的计算复杂度。
结论
在这项工作中,我们将自我监督学习表示 (SSLRs) 纳入我们提出的持久性口音记忆 (PAM) 方法中以改进 AR。我们使用从预训练的 WavLM 模型中提取的 SSLRs 来解决口音识别任务中的数据不足问题。与传统声学特征相比,SSLRs 的使用显示出显著的性能提升,这表明 SSLRs 在口音识别中的有效性。此外,我们提出了一种具有不同注意力机制的 PAM 方法来提高口音识别。我们证明了我们提出的方法在公共口音基准数据集上的有效性,并且从持久性口音记忆中选择 N 个最佳相关嵌入的最佳性能系统在口音识别方面取得了进一步的改进。
参考文献
[1] S. Shon, H. Tang, and J. Glass, “Frame-level speaker embeddings for text-independent speaker recognition and analysis of end-toend model,” in Proc. SLT 2018. IEEE, 2018, pp. 1007–1013.
[2] X. Gong, Y. Lu, Z. Zhou, and Y. Qian, “Layer-Wise Fast Adaptation for End-to-End Multi-Accent Speech Recognition,” in Proc. INTERSPEECH 2021, 2021, pp. 1274–1278.
[3] S. Chen, C. Wang, Z. Chen, Y. Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao et al., “Wavlm: Large-scale selfsupervised pre-training for full stack speech processing,” IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022.