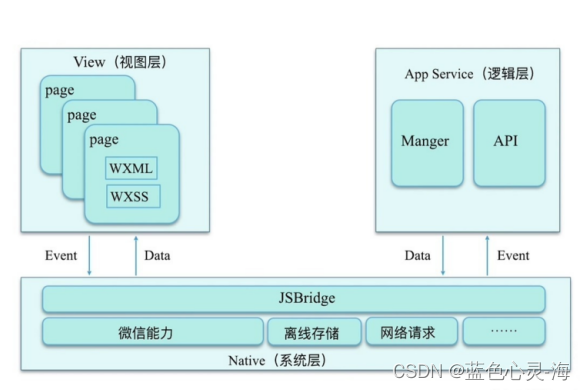
15.1 OCR流水线及七工作原理
Photo OCR:照片 光学字符识别(photo optical character recognition)
Photo OCR注重的问题:如何让计算机都出图片中的文字信息,它有以下步骤:
- 首先给定某张图片,它将图像扫描一遍,然后找出照片中的文字信息。
- 成功找出这些文字以后,它将重点关注这些文字区域,并对区域中的文字进行识别。当正确读出这些文字以后,它会将这些文字内容显示并记录下来。
如何实现OCR?
- 首先我们要扫描图像,并找出有文字的图像区域(文字检测)
- 对有文字的图像区域进行文字分离(字符分割)
- 分割这些文字得到独立的字符后,使用一个分类器,它会对这些可见字符进行识别,最后就可以得到文字信息(字符分类)

这样的步骤就成为了机器学习流水线。



15.2 滑动窗口分类器

15.3 人工数据合成
- 从零开始创造新数据
- 从已有的小的标签训练集,以某种方式扩充训练集
获取数据:
下载字体,然后将它们放到一个随机北京图片上

对图像进行人工扭曲

对语音文本加入不同的背景干扰

首先确保算法已经有很低的偏差,整体的模型ok,然后在考虑加数据,否则只是徒劳。
然后考虑加数据的人工和时间成本。

15.4 上限分析
对多个模块进行分析,让其中一个模块达到100%的准确率,然后判断它能提高整个系统多少准确率。