文章目录
- 前言
- 传输的开启和关闭
- 设备调度以准备传输
- 队列规则接口
- qdisc_restart函数
- dev_queue_xmit函数
- 有队列设备
- 无队列设备
- 处理NET_TX_SOFTIRQ: net_tx_action
- 看门狗定时器
前言
“传输”这一术语用于离开系统的帧,也许是因为被系统传送出去,或者是因为被转发出去。本章我们讨论帧传输的数据通路中所涉及的主要任务:
-
为设备开启和关闭帧的传输
-
为设备调度以准备传输
-
为下一帧调度以准备传输。也就是在设备出口队列中等待的那些帧。
-
传输本身(我们将检查主要函数)
传输过程和第十章所谈的接收过程大部分是对称的:NET_TX_SOFTIRQ传输软IRQ,与NET_RX_SOFTIRQ软IRQ配对,而net_tx_action与net_rx_action配对,诸如此类。因此,如果你已读过前一章,应该会发现这一章很容易理解。下图比较了调度设备以准备接收,以及调度设备以准备传输两者之间背后的逻辑。
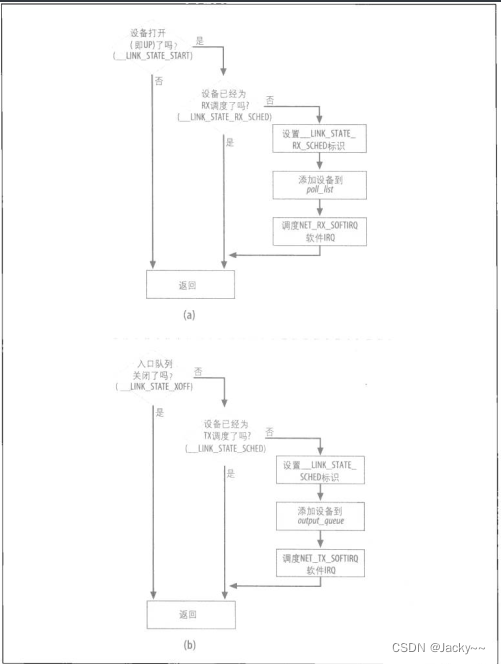
以下是一些相似性:
-
poll_list是设备列表,因为其接收队列不为空,其中的设备会被轮询。output_queue是设备列表,其中的设备有信息要传输。poll_list和out_queue是前面介绍的softnet_data结构的两个字段。 -
只有开启的设备(
__LINK_STATE_START标识设置的那些设备)才能接受调度以准备接收。只有开启传输功能的设备(__LINK_STATE_XOFF标识清除的那些设备)才可以接收调度以准备传输。 -
当设备接受调度准备接收时,其
__LINK_STATE_RX_SCHED标识会设置。当设备接受调度准备传输时,其__LIINK_STATE_SCHED标识会设置。
dev_queue_xmit对出口路径的角色就如同netif_rx对入口路径一样,都是在驱动程序的缓冲区和内核的队列之间传输帧。当设备等待传输某些数据以及对那些不再需要的缓冲区做些清扫工作时,net_tx_action函数就会被调用。就像入口流量有队列可用一样,出口流量也有队列可用。出口队列(由流量控制处理,QoS层),实际上比入口队列复杂许多:入口队列只是平常的FIFO队列,但出口队列是层次化的树形队列。虽然流量控制也回转此入口队列操作功能,但是,使用流量控制主要是为了监督和管理的原因,而不是为了实际做队列的操作:流量控制对入口流量并没有使用真正的队列,而是只对动作进行分类,然后予以施行而已。
传输的开启和关闭
在上篇博客的“拥塞管理”一节中我们已经知道,某些情况下帧的接收必须关闭,也许是单一设备,也许是全部的设备。对帧的传输而言,也有类似的情况。
出口队列的状态是由net_device->state中的标识__LINK_STATE_XOFF表示。其值可以通过定义在include/linux/netdeivce.h中的下列函数操作和检查:
-
netif_start_queue- 开启设备的传输。当设备启动时通常就会调用此函数,此外,如果必须重启已停止的设备时,也可以再次调用。
-
netif_stop_queue- 关闭传输的设备。任何企图在设备上传输信息的尝试都会被拒绝。本节稍后有一个此函数应用的常见实例。
-
netif_queue_stopped- 返回出口队列的状态:开启或关闭。此函数很简单:
static inline int netif_queue_stopped(const struct net_device *dev)
{
return test_bit(__LINK_STATE_XOFF, &dev->state);
}
只有设备驱动程序可以开启或关闭设备的传输。
设备运行时,为什么要停止和启动队列?原因之一是设备可能暂时用其内存,使得传输尝试失败。以前,传输函数需要把帧再放回队列以解决这个问题。现在,由于__LINK_STATE_XOFF标识,这个额外的处理工作可以避开了。当设备驱动程序了解到没有足够空间以存储一个最大尺寸(MTU)的帧时,就会以netif_stop_queue停止出口队列。如此一来,就有可能避免后续的传输(内核已知会失败)而浪费资源。下面的窒息范例取自vortex_start_xmit(drivers/net/3c59x.c驱动程序所用的hard_start_xmit方法):
outsl(ioaddr + TX_FIFO, skb->data, (skb->len + 3)>>2);
dev_kfree_skb(skb);
if(inw(ioaddr + TxFree) > 1536){
netif_start_queue (dev); /*AKPM: 多余的?*/
}else{
/*当FIFO有空间容纳最大尺寸的封包时,就打断我们。*/
netif_stop_queue(dev);
outw(SetTxThreshold + (1536>>2), ioaddr + EL3_CMD);
}
outsl传输之后,程序马上就会检查是否有空间容纳一个最大尺寸(1536)的帧,然后如果没有足够空间,就使用netif_stop_queue以停止设备的出口队列。这是相当粗糙的技术,用于避免因为内存不足造成的传输失败。当然,只要有300个字节以上的空间存在,就可传输一个300个字节的帧,因此,检查是否有1536个字节可能就会造成不必要的传输关闭。程序也可以使用较低的值,如500,以作为折中,但是到头来并没有获得很大的利益,而且当传输开启却碰到较大帧来到时,反而会造成失败。
为了包含所有可能性,当设备上有足够内存时,程序会调用netif_start_queue。代码注释中的“多余的?”指的是两种中断事件而重启队列的事。当设备指出其已完成传输时,以及当设备指出其内存有足够空间可容纳一个帧时,驱动程序就会发出队列重启请求。如果驱动程序只因这些中断事件之一而发出重启请求时,队列可能会立刻重启,但是,并无法保证。所以,重启该队列的请求都是在这两种情况下都会发出。
代码也会传送SetTxThreshould命令给设备,指示该设备在特定内存量(此例就是MTU的量)可用时产生一个中断事件。
你可能会想,在前述情景中队列何时以及如何重启。就Vortex驱动程序而言,当特定量的内存可用时(就此而言的就是MTU的量),就会要求设备产生一个中断事件。下面就是处理这种中断事件的代码:
static void vortex_interrupt(int irq, void *dev_id, struct pt)
{
.. ... ...
if(status & TxAvailable) {
if(vortex_debug > 5)
printk(KERN_DEBUG, " Tx room bit was handled.\n");
/*FTFO中有空间可容纳一个全尺寸的封包*/
outw(AckIntr | TxAvailable, ioaddr + EL3_CMD);
netif_wake_queue(dev);
}
... ... ...
}
status变量的那些位代表的是适配卡产生中断事件的原因。TxAvailable位指出空间足够,因此,唤醒设备是安全的(也就是唤醒队列,而且是由netif_wake_queue来做)。如EL3_CMD之类的值只是从ioaddr起算的偏移量,设备驱动程序借此在正确的位置读写网卡寄存器。
注意,出口队列是用netif_wake_queue而不是用netif_start_queue重启。那个新函数不仅开启出口队列,也会要要求内核去检查该队列中是否有任何信息等待传输。原因在于,当队列被关闭时可能已有传输的尝试。就此而言,都会失败,而那些无法被传送的帧都会被放回出口队列。
设备调度以准备传输
说明入口路径时,我们知道当设备接收一个帧时,其驱动程序会启用一个内核函数(至于启用哪一个则依赖于驱动程序是否使用NAPI),把设备添加到轮询列表中,然后调度NET_RX_SOFTIRQ以准备执行。
出口路径上所发生的事也很类似。要传输帧时,内核会提供dev_queue_xmit函数。此函数会会从设备的出口队列中退出一个帧,然后将该帧传递给设备的hard_start_xmit方法。然而,dev_queue_xmit可能因各种原因而无法传输,例如,因为该设备的出口队列已关闭,或者该设备队列的锁已被取走。为了处理后一种情况,内核提供了一个函数,名为__netif_schedule,可为设备调度以准备传输(有点类似netif_rx_schedule对接收路径所做之事)。此函数绝不会被直接调用,而是会通过两个包括函数(本节稍后会谈及)。
以下是此函数的定义(来自于include/linux/netdevice.h):
static inline void __netif_schedule(struct net_device *dev)
{
if(!test_and_set_bit(__LINK_STATE_SCHED, &dev->state)){
unsigned long flags;
struct softnet_data *sd;
local_irq_save(flags);
sd = &__get_cpu_var(softnet_data);
dev->next_sched = sd->output_queue;
sd->output_queue = dev;
raise_softirq_irqoff(cpu, NET_TX_SOFTIRQ);
local_irq_restore(flags);
}
}
__netif_schedule完成两项主要任务:
-
把设备添加到
output_queue列表的头部。此列表是接收时所用的与poll_list配对的列表。每个CPU都有一个output_queue,就如同每个CPU都有一个poll_list。然而,output_queue会由NAPI及非NAPI设备所用,而poll_list只用于处理非NAPI设备。output_queue中的设备是以net_device->next_sched指针链接在一起的。在“处理NET_TX_SOFTIRQ:next_tx_action”一节将会知道这个列表如何使用。前面我们讲述过softnet_data结构,output_queue代表的是一个设备列表,其中的设备有数据要传送(因为先前的尝试失败了)或者其出口队列在被关闭一段时间之后又重新开启。因为__netif_schedule可在中断环境内外被调用,把输入设备添加到output_queue列表时,就会关闭中断功能。 -
为
NET_TX_SOFTIRQ软IRQ调度以准备执行。__LINK_STATE_SCHED用来标记位于output_queue列表中的设备,因为那些设备有数据要传输(__LINK_STATE_SCHED是接收路径的__LINK_STATE_RX_SCHED配对标识)。注意,如果该设备已进入调度准备传输,__netif_schedule不做任何事。
如果设备的传输功能已关闭,为设备调度以准备传输就没意义,因此,内核另外提供了两个函数以供使用,而这两个函数都是__netif_schedule的包裹函数:
-
netif_schedule- 确保为设备调度进行传输之前该设备的传输功能已开启:
static inline void netif_schedule(struct net_device *dev)
{
if(!test_bit(__LINK_STATE_XOFF, &dev->state))
__netif_schedule(dev);
}
-
netif_wake_queue-
开启设备的传输,而且如果先前传输已经关闭,就为设备调度以准备传输。这种调度是必需的,因为该设备队列被关闭时可能已有传输的尝试。前一节已看到此函数的使用范例。
-
test_and_clear_bit会清掉__LINK_STATE_XOFF标识(如果有设置),然后返回旧值。
-
static inline void netif_wake_queue(struct net_device *dev)
{
...
if(test_and_clear_bit(__LINK_STATE_XOFF, &dev->state))
__netif_schedule(dev);
}
注意,调用netif_wake_queue就相当于调用netif_start_queue和netif_schedule。在前面一节说过,驱动程序的责任(不是较高层的函数)是关闭和开启设备的传输功能。通常来讲,高层函数会为设备的传输进行调度,而设备驱动程序则在必要时关闭和重启队列,如为了应付内核不足的情况。因此,netif_wake_queue是由设备驱动程序使用,而netif_schedule则是用在其他地方——例如,由net_tx_action和流量控制使用——应该就不会令人差异了。
驱动程序会在下列情况使用netif_wake_queue:
-
到了“看门狗定时器”一节就会知道,设备驱动程序会使用一个看门狗定时器,令挂起的传输得以恢复。在这种情况下,虚拟函数
net_device->tx_timeout通常会重设适配卡。在设备不可用的那段黑洞期间内,可能有其他传输尝试,所以驱动程序必须先开启设备队列,然后为设备调度以准备传输。对那些通知错误情况的中断事件也是如此。 -
当设备通知驱动程序(驱动程序之前的请求)已有足够内存可处理一个特定尺寸的帧传输时,该设备就可唤醒。我们已在前一节谈到
TxAvailable中断事件时看过这种范例。使用此函数的原因依然是在驱动程序关闭该队列的期间可能已有一些传输尝试。类似的考虑也用在一种中断事件类型上(当驱动程序对适配卡的DMA传输已完成时,就通知驱动程序)。
队列规则接口
几乎所有设备都会使用队列调度出口流量,而内核可以使用名为队列规则的算法安排帧,使其以最有效率的次序传输。本节对设备驱动程序以及传输层之间的接口做一些简介。
每种流量控制队列规则都是提供各种函数指针,可由较高层调用,以完成各种任务。其中最重要的函数如下:
-
enqueue- 把一个元素添加到队列中。
-
dequeue- 从队列中提取一个元素
-
requeue- 把一个原先已经提取的元素放回队列上(例如,因为传输失败)。
每当设备进入调度以准备传输时,qdisc_run函数就会选出下一个要传输的帧,而该函数会间接调用相关联的队列规则的dequeue虚拟函数。
同样,真实的工作是由另一个函数qdisc_restart.qdisc_run函数(定义在include/linux/pkt_sched.h)只是一个包裹函数,为那些输出队列已关闭的设备过滤请求而已:
static inline void qdisc_run(struct net_device *dev)
{
while(!netif_queue_stopped(dev) && qdisc_restart(dev) < 0 )
/*nothing*/
}
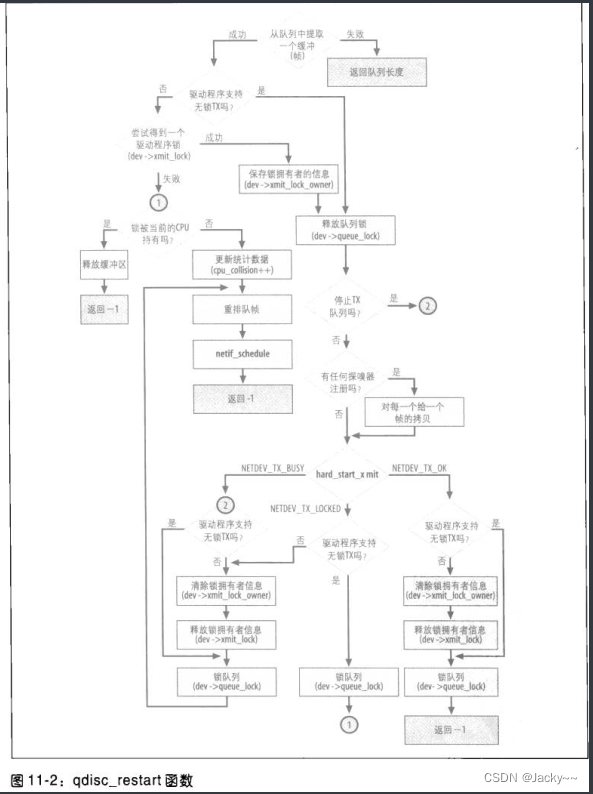
qdisc_restart函数
前面已知设备进入调度以准备传输的常见情况。有时是因为出口队列中有数据等待传输,但是其他时候,设备会被调度是因为其队列已被关闭了一段时间,因此有可能因先前失败的传输尝试使得队列中有数据在等待。驱动程序不知道是否真的已有任何数据抵达,但必须对设备进行调度,以免有数据在等待中。如果事实上并没有数据在等待,则后续对dequeue方法的调用就会失败。即使有数据在等待,调用也可能失败,因为复杂的队列规则可能决定不传输任何数据。因此,qdisc_restart(定义在net/sched/sch_generic.c)会根据dequeue方法的返回值而采取各种不同的行动:
int qdisc_restart(struct net_device *dev)
{
struct Qdisc *q = dev->qdisc;
struct sk_buff *skb;
if((skb = q->dequeue(q)) != NULL ){
... ... ...
}
}
一开始dequeue函数就会被调用。我们假设调用成功。传输一个帧需要取得两个锁:
-
保护队列锁(
dev->queue_lock)。这是由qdisc_restart的调用者(dev_queue_xmit)取得的。 -
驱动程序传输函数
hard_start_xmit的锁(dev->xmit_lock)。此锁是由此函数管理。当设备驱动程序已实现其自己的上锁机制时,就会设置dev->features中的NETIF_F_LLTX标识(无锁传输功能)指出这一点,以通知那些上层没必要取得dev->xmit_lock锁。所用NETIF_F_LLTX可让内核在不需要取得dev->xmit_lock锁时就不用取得,借此让传输数据路径得以最优化。当然,如果队列是空,也就没必要取得该锁。
注意,从队列中退出一个缓冲区之后,qdisc_rstart并没有立刻释放queue_lock,因为如果无法取得该驱动程序锁时,就得立刻将该缓冲区重新排入队列。当该函数取得驱动程序锁之后,就会释放queue_lock,然后再返回到前面,会再次重新取得queueu_lock。最后,dev_queue_xmit会负责予以释放。
当驱动程序不支持NETIF_F_LLTX,而且驱动程序的锁已经被取走时(也就是spin_trylock返回0),传输就会失败。如果qdisc_restart无法获取驱动程序锁,就表示另一个cpu正通过同一个设备进行传输。此时,因为qdisc_restart不想等待,所以唯一能做的事就是把帧放回队列,再为设备和从新调度以作准备传输。如果此函数运行的CPU和持有该锁的CPU是同一个,这表示侦测了一个循环(也就是代码中有bug),那么帧就会被丢弃,否则就只是冲突而已
if(!spin_trylock(&dev->xmit_lock)){
collsion:
...
goto requeue;
}
...
requeue:
q->ops->requeue(skb, q);
netif_schedule(dev);
一旦成功取得驱动程序锁后,就会放开队列锁,使得其他CPU可访问队列。有时,没必要取得驱动程序锁,因为NETIF_F_LLTX有设置。无论那种情况,qdisc_restart都可着手进行其真实的工作:
if(!netif_queue_stopped(dev)){
int ret;
if(netdev_nit)
dev_queue_xmit_nit(skb, dev);
ret = dev->hard_start_xmit(skb, dev);
if(ret == NETDEV_TX_OK){
if(!nolock){
dev->xmit_lock_owner = -1
spin_unlock(&dev->xmit_lock);
}
spin_lock(&dev->queue_lock);
return -1;
}
if(ret == NETDEV_TX_LOCKED && nolock){
spin_lock(&dev->queue_lock);
goto collision;
}
}
由前节已知,qdisc_run早已利用netif_queue_stopped检查出口队列的状态,但是,这里qdisc_restart又检查了一次。第二次检查并非多余的。考虑这种情景:当qdisc_run调用netif_queue_stopped时,驱动程序的锁尚未被取走。到了该锁被取走时,另一个CPU可能传送了某种数据,而该适配卡可能已经没有缓冲区空间可用了。因此,netif_queue_stopped先前返回FLASE,但现在则会返回TRUE。
netdev_nit代表的是已注册的协议探嗅器数目。如果任何协议探嗅器已注册,就会用dev_queue_xmi_nit把帧的副本递送给每个协议探嗅器。
最后,我们得启用设备驱动程序的虚拟函数以进行帧的传输。设备驱动程序提供的函数是dev->hard_start_xmit(每个设备在初始化设置期间都会定义)。hard_start_xmit函数返回的NETDEV_TX_XXX值列在include/linux/netdeice.h。以下是qdisc_restart处理的结果:
-
NETDEV_TX_OK- 传输成功。缓冲区尚未被释放(还没发出
kfree_skb)。到后面就会知道,驱动程序不会自行释放缓冲区,而是通过NET_TX_SOFTIRQ软IRQ要求内核做此事。比起每个驱动程序都自己来释放,这样的内存处理会比较有效率。
- 传输成功。缓冲区尚未被释放(还没发出
-
NETDEV_TX_BUSY- 驱动程序发现NIC的传输缓冲池内没有足够的空间。侦测到这种情况时,驱动程序通常会调用
netif_stop_queue。
- 驱动程序发现NIC的传输缓冲池内没有足够的空间。侦测到这种情况时,驱动程序通常会调用
-
NETDEV_TX_LOCKED- 驱动程序被锁住了。此返回值只由支持
NETIF_F_LLTX的驱动程序使用。
- 驱动程序被锁住了。此返回值只由支持
总之,当下列条件之一为真时,传输失败,而帧就必须被放回队列:
-
队列已关闭(
netif_queue_stopped(dev)为真)。 -
另一个CPU持有驱动程序锁。
-
驱动程序失败(
hard_start_xmit没有传回NETDEV_TX_OK)。
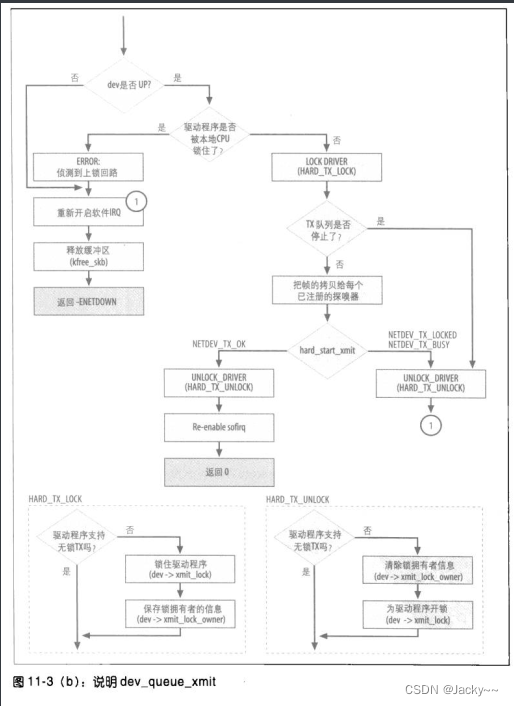
dev_queue_xmit函数
此函数是设备驱动程序执行传输时的接口。dev_queue_xmit会导致驱动程序传输函数hard_start_xmit通过以下两种路径之一执行:
-
衔接至流量控制(
QoS层)- 这是通过上一节已说明过的
qdisc_run函数实现的
- 这是通过上一节已说明过的
-
直接启用hard_start_xmit- 这是为那些不使用流量控制基础架构的设备(也就是虚拟设备)所做的。
我们很快就会看到这些案例,但先从这两者都常见的检查和任务着手。
当dev_queue_xmit被调用时,传输帧所需的所有信息都已准备就绪,如外出设备,下一个跳点,以及其链接层地址。
dev_queue_xmit只接收一个sk_buff结构作为输入值。此结构包含此函数所需的一切信息。例如,skb->dev是外出设备,而skb->data是指向有效载荷的开头,而其长度为skb->len
int dev_queue_xmit(struct sk_buff *skb)
dev_queue_xmit的主要任务是:
-
检查帧是否由一些片段(fragment)组成,以及设备是否能通过散播/聚集DMA的方式处理这些片段。如果设备无法这么做,就把这些片段结合起来。
-
计算以确认L4检验和(也就是TCP/UDP),除非设备在硬件内计算此校验和。
-
选择要传输那个帧(由input sk_buff所指的帧不一定就是要传输的帧,因为有一个队列要重传)。
下列程序中,当skb_shinfo(skb)->frag_list不为NULL时,数据有效载荷就是一个片段列表;否则,有效载荷就是一个区块。如果有一些片段,则程序会检查设备是否支持散播/聚集DMA功能,如果不支持,就把那些片段给结合成单一缓冲区。如果片段之中有任何片段存储所在的内存区域其地址过大,使得设备无法寻址(即illegal_highdma(dev, skb)为真),此函数也得把那些片段结合起来。
if(skb_shinfo(skb)->frag_list &&
!dev->features&NETIF_F__FRAGLIST) &&
__skb_linearize(skb, GFP_ATOMIC)){
goto out_kfree_skb;
}
if(skb_shinfo(skb)->nr_frags && !(dev->features & NETIF_F_SG)
|| illegal_highdma(dev, skb)) && __skb_linearize(skb, GFP_ATOMIC)){
goto out_kfree_skb;
}
片段的重组是由__skb_linearize所做,但是,会因为下列原因之一而失败:
-
用于存储那些联结后的片段的新缓冲区无法得到分配。
-
sk_buff缓冲区和其他子系统共享(也就是引用计数大于1)。就此而言,此函数并非实质失败,但是会调用BUG()以产生一条警示信息。
L4校验和可在软件和硬件中计算。并非所有网络卡都可在硬件内计算校验和。那些可以如此做的网络卡会在设备初始化期间设置net_device->features中相关的位标识。这样会通知较高层的网络层,它们不需要担心检验和计算的问题。但是,如果下列情况之一,校验和就必须在软件内计算:
-
硬件不支持校验和计算
-
适配卡只能针对底层是IP的TCP/UDP封包使用硬件校验和计算,但是,正在传输的封包不使用IP,或者使用其他底层是IP的L4协议。
软件校验和是由skb_checksum_help计算的:
if(skb->ip_summed == CHECKSUM_HW &&
(!(dev->features & (NETIF_F_HW_CSUM) | NETIF_F_NO_CSUM)) &&
(!dev->features & NETIF_F_IP_CSUM) ||
skb->protocol != htons(ETH_P_IP))))
if(skb_checksum_help(skb, 0))
goto out_kfree_skb;
一旦校验和被处理后,所有报头也都准备就绪,下一步就是决定该传送那个帧了。
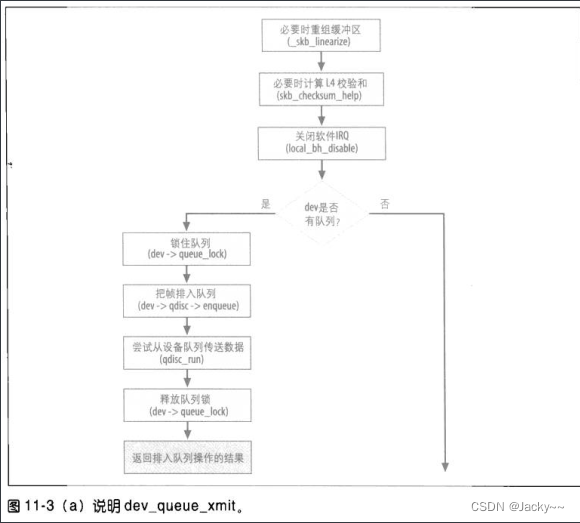
此时,其行为依赖于设备是否使用流量控制基础架构,以及是否获派队列规则。是的,这有点令人惊讶。此函数只处理一个缓冲区(必要时,予以重组以计算校验和),但是依赖于是否使用队列规则,使用那种队列规则以及外出队列的状态,此缓冲区可能不是下一个实际传送的缓冲区。
有队列设备
当设备的队列规则存在时,就可通过dev->qdisc予以访问。输入帧会通过enqueue虚拟函数而排入队列,接着,一个帧会通过qdisc_run而退出队列并传输,其细节在“队列规则接口”一节已经描述。
local_bh_disable();
q = rcu_dereference(dev->qdisc);
...
if(q->enqueue){
spin_lock(&dev->queue_lock);
rc = q->enqueue(skb, q);
qdisc_run(dev);
spin_unlock_bh(&dev->queue_lock);
rc = rc - NETIF_XMIT_BYPASS ? NET_XMIT_SUCCESS;
goto out;
}
注意,排入队列以及退出队列都会由队列锁queue_lock保护。软IRQ也会用local_bh_disable关闭,作为RCU的需要local_bh_disable也会把先占功能关闭。
无队列设备
有些设备没有队列,如回环设备:每当一个帧传输时,就会立刻被传递出去(但是,因为没有队列可以让帧重新排入,如果有地方出错,帧就会被丢弃,没有第二次机会)。如果看一下drivers/net/lookback.c中的loopback_xmit,会发现在程序末尾直接调用netif_rx,跳过所有队列事务。netif_rx是由非NAPI设备驱动程序所调用的API,可将送进来的帧放入输入队列,然后通知较高层有关此事件。由于回环设备没有输入队列,传输函数要完成两个任务:一端传输,而另一端接收。如下图所示:
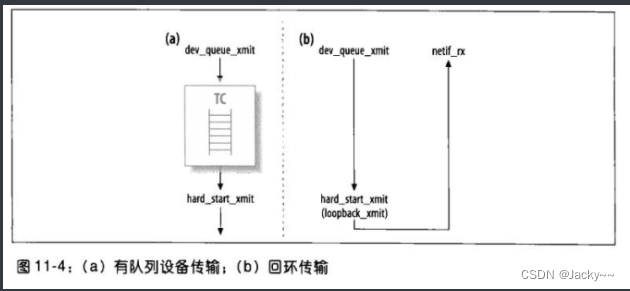
dev_queue_xmit的最后一部分用于处理没有队列规则的设备(因此也没有出口队列)。这部分相当类似“队列规则接口”一节提到的qdisc_run的行为。然而,不使用队列时有两点差异在:
-
当传输失败时,驱动程序无法把缓冲区放回任何队列中,因为根本没有队列,所以
dev_queue_xmit会丢弃该缓冲区。如果较高层使用的是可靠的协议,如TCP,则数据终究会被重新传输,否则,数据就会遗失。 -
“qdisc_restart函数”一节介绍的
NETIF_F_LLTX是由HARD_TX_LOCK和HARD_TX_UNLOCK这两个宏负责。HARD_TX_LOCK使用spin_lock而不是spin_trylock,当驱动程序锁被取走时,dev_queue_xmit就处于旋转状态,等待该锁被释放。
处理NET_TX_SOFTIRQ: net_tx_action
net_rx_action函数是与NET_RX_SOFIRQ软件中断相关联的处理函数。此函数由设备驱动程序触发(某些特定情况下会自行触发),负责设备驱动程序延期至“中断事件处理阶段之后”才进行的那一部分的输入帧的处理。如此一来,驱动程序在中断环境内所执行的程序就只会做绝对必要之事(把数据拷贝到内存,然后产一个软件中断事件通知内核此事),因而不会强制系统其余部分等待太久,稍后,此软件中断会负责处理那部分可以等待的帧的处理。
net_tx_action的工作方式类似,此函数可由设备在两种情景下以raise_softirq_irqoff(NET_TX_SOFTIRQ)予以触发,以完成两项主要任务:
-
当设备的传输功能通过
netif_wake_queue开启时,在这种情况下,此函数要确保当所有必需条件都吻合时(例如,当设备有足够内存时),等待被传送的帧实际上都被传送出去。 -
当传输已完成而且设备驱动程序通过
dev_kfree_skb_irq通知相关联的缓冲区可释放时,在这种情况下,此函数要收回(deallocate)那些已成功传输的缓冲区的skb_buff结构。
第二项任务的原因如下。我们知道当来自设备驱动程序的程序在中断环境下运行时,就必须尽快执行。释放一个缓冲区会耗很多时间,所以会受到拖延,而要求net_tx_action软IRQ予以负责。设备驱动程序使用dev_kfree_skb,而是使用dev_kfree_skb_irq。dev_kfree_skb收回sk_buff(实际上就是缓冲区,回到每CPU缓存内),但是,dev_kfree_skb_irq只会把要是被释放的缓冲区的指针添加到与CPU相关联的softnet_data结构的completion_queue列表中,然后让net_tx_action稍后去做实际的工作。
让我们来看net_tx_action如何完成其两项任务。
首先,收回所有因设备驱动程序调用dev_kfree_skb_irq而被添加到completion_queue列表的缓冲区。因为net_tx_action是在中断环境外运行的,设备驱动程序可以在任何时刻添加元素,所以,net_tx_action在访问softnet_data结构时必须关闭中断功能。为了尽可能让中断功能关闭时间短一点,net_tx_action会把completion_queue设成NULL以清楚该列表,然后把指向该列表的指针存储在一个局部变量clist(没人可以访问,此外每个CPU都有自己的列表)。如此一来,net_tx_action就能遍历此列表,用__kfree_skb释放每个元素,同时驱动程序又能持续把新元素添加到completion_queue。
if(sd->completion_queue){
struct sk_buff *clist;
local_irq_disable();
clist = sd->completion_queue;
sd->completion_queue = NULL;
local_irq_enable();
while(clist != NULL ){
struct sk_buff *skb = clist;
clist = clist->next;
BUG_TRAP(!atomic_read(&skb_users));
__kfree_skb(skb);
}
}
函数的另一半是传输帧,其工作方式也很相似:使用一个局部变量,不让硬件中断受影响。注意,对每个设备而言,传输任何数据之前此函数都必须获取输出设备的队列锁(dev->queue_lock)。如果函数无法获取该锁(因为另一个CPU持有该锁),就只好以netif_schedule为设备重新调度以准备传输。
if(sd->output_queue){
struct net_device *head;
local_irq_disable();
head = sd->output_queue;
sd->output_queue = NULL;
local_irq_enable();
while(head){
struct net_device *dev = head;
head = head->next_sched;
smp_mb__before_clear_bit();
clear_bit(__LINK_STATE_SCHED, &dev->state);
if(spin_trylock(&dev->queue_lock)){
qdisc_run(dev);
spin_unlock(&dev->queue_lock);
}else{
netif_schedule(dev);
}
}
}
在“队列规则接口”一节已知qdisc_run如何工作。设备是用循环从列表的头开始依次接收处理。因为netif_schedule函数(内部调用__netif_schedule)会把元素添加到列表的头,设备接收服务的次序就是FIFO,在某些情况下这可能不公平。
以上就是net_tx_action函数的说明。我们来看一些启用此函数以释放缓冲区的情况。有些想释放缓冲区的函数可以在各种不同的情况下启用(在中断环境内外)。有一个包裹函数可以用优雅的方式处理这些情况:
static inline void dev_kfree_skb_any(struct sk_buff *skb)
{
if( in_irq || irqs_disabled())
dev_kfree_skb_irq(skb);
else
dev_kfree_skb(skb);
}
当调用函数处于中断环境下时,dev_kfree_slb_irq函数执行,如下所示:
static inline void dev_kfree_skb_irq(struct sk_buff *skb
{
if( atomic_dec_and_test(&skb->users)){
struct softnet_data *sd;
unsigned long flags;
local_irq_save(flags);
sd = &__get_cpu_var(softnet_data);
skb->next = sd->completion_queue;
sd->completion_queue = skb;
raise_softirq_irqoff(NET_TX_SOFTIRQ);
local_irq_restore(flags);
}
}
只有当没有任何引用时,缓冲区才可被释放(也就是skb->user为0)。
我们看一个实例:设备驱动程序间接调用cpu_raise_softirq(cpu, NET_TX_SOFTIRQ)而触发net_tx_action的执行过程(另一个实例可在“传输的开启和关闭”一节找到)。
前面介绍过的vortex_interrupt函数所处理的中断类型中,有一种中断事件是由设备启用以通知驱动程序,CPU对设备的DMA传输已完成。由于缓冲区已传输给设备,sk_buff结构现在可以释放了。因为中断处理函数是在中断环境内工作的,驱动程序会调用dev_kfree_skb_irq。
if(status & DMADone){
if(inw(ioaddr + Wn7_MastweStatus) & 0x1000){
outw(0x1000, addr + Wn7_MasterStatus); //通知收到此事件
pci_unmap_single(VORTEX_PCI(vp), vp->tx_skb_dma,
(vp->tx_skb->len +3) & ~3, PCI_DMA_TODEVICE);
dev_kfree_skb_irq(vp->tx_skb); //释放已传输的缓冲区
if(inw(ioaddr + TxFre) > 1536) {
netif_wake_queue(dev);
}else{ //当FIFO有空间容纳大尺寸封包时就打断
outw(SetTxThreshold + (1536>>2), ioaddr+EL3_CMD);
netof_stop_queue(dev);
}
}
}
看门狗定时器
当某些条件吻合时,设备驱动程序可以关闭传输。关闭传输是暂时的,所以当传输没有在合理时间内重启,内核就假定该设备遇到了一些问题而应该重新启动。
这是由各个设备定时器(当设备以dev_active启动时,由dev_watchdog_up启动)所完成的。此定时器会定期到期,以确保该设备一切没问题,然后自行重新启动。当侦测到问题(因为设备的传输队列已关闭;netif_queue_stopped返回TRUE)以及上次帧传输后已经过太多时间时,定时器的处理函数就会启用设备驱动所注册的函数,以复位NIC。
以下是用于实现此机制的net_device字段:
-
trans_start- 这是由设备驱动程序设置的时间戳,记录上次帧传输启动的时间。
-
watchdog_timer- 这是由流量控制启动的定时器。当定时器到期时,所执行的处理函数是
dev_watchdong(定义在net/sched/sch_gerneric.c)
- 这是由流量控制启动的定时器。当定时器到期时,所执行的处理函数是
-
watchdog_timeo- 这是要等待的时间量。此值由设备驱动程序初始化。当其设为0时,
watchdog_timer就不会启动。
- 这是要等待的时间量。此值由设备驱动程序初始化。当其设为0时,
-
tx_timer- 这是设备驱动程序提供的函数,
dev_watchdog将被启动以复位设备。
- 这是设备驱动程序提供的函数,
定时器到期时,内核处理函数dev_watchdog会调用tx_timeout所指的函数而采取行动。tx_timeout会复位网络卡,然后以netif_wake_queue重启接口调度器。
watchdog_timeo的适当值依赖于接口而定。如果驱动程序没有设置,其默认值为5秒。定义此值时需要考虑的参数如下:
-
传输冲突可能性- 对点对点链接而言为零,但是对插入Hub的共享并超载的Ethernet链接而言,就可能很高。
-
接口速率- 接口愈慢,时限就应该愈大。
watchdog_timeo的值通常定义为变量HZ(代表1秒)的倍数。HZ是全局变量,其值依赖于平台而定(定义在体系结构依赖的文件include/asm-XXX/param.h)。如下表所示,每种相同类型的设备也可能采用不同的值作为时限。此表只列出一些范例,并不是完整的列表。
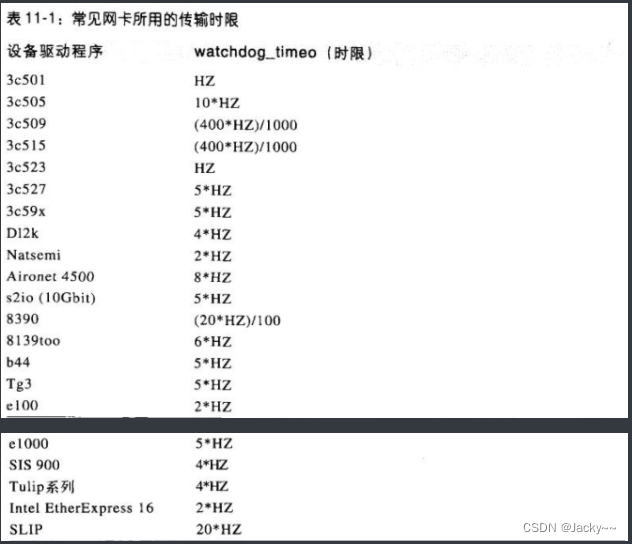
看门狗定时器机制是由流量控制程序所提供的。然而,高层设备驱动程序也可以实现自己的看门狗定时器。参见drivers/net/e1000_main.c中的范例。








![[附源码]Python计算机毕业设计Django学生宿舍维修管理系统](https://img-blog.csdnimg.cn/aaf0e93f60464383a62f7221f7fced84.png)

![[安装] Doris集群搭建环境](https://img-blog.csdnimg.cn/img_convert/bfef8c5f6930dc0d573e1bc97dc3c3ed.png)