原文首发于博客文章OpenAI 文档解读
LangChain 主体分为 6 个模块,分别是对(大语言)模型输入输出的管理、外部数据接入、链的概念、(上下文记忆)存储管理、智能代理以及回调系统,通过文档的组织结构,你可以清晰了解到 LangChain的侧重点,以及在大语言模型开发生态中对自己的定位。从本节langchian源码阅读系列第二篇,下面进入Data Connection模块👇
Data Connection
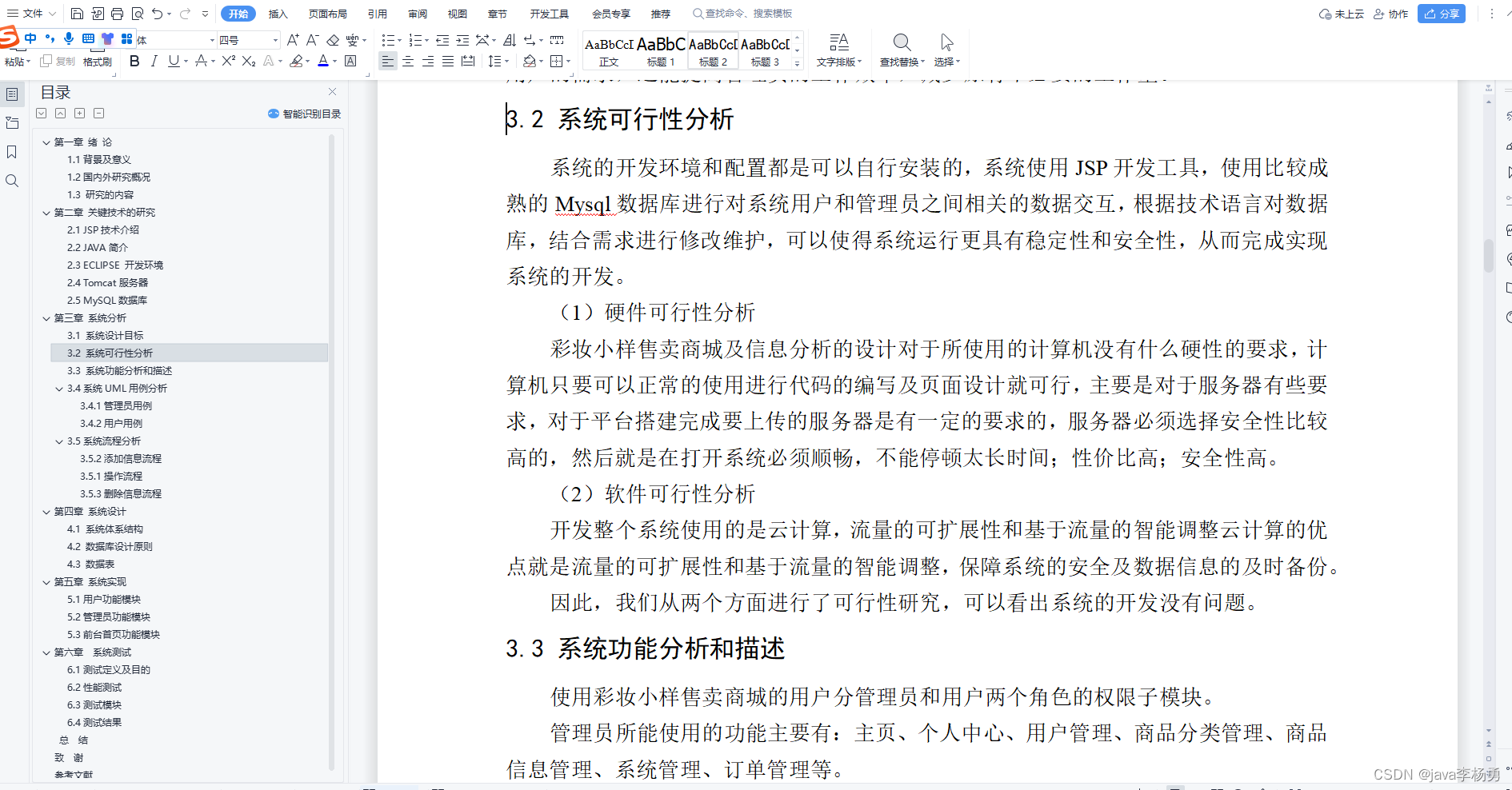
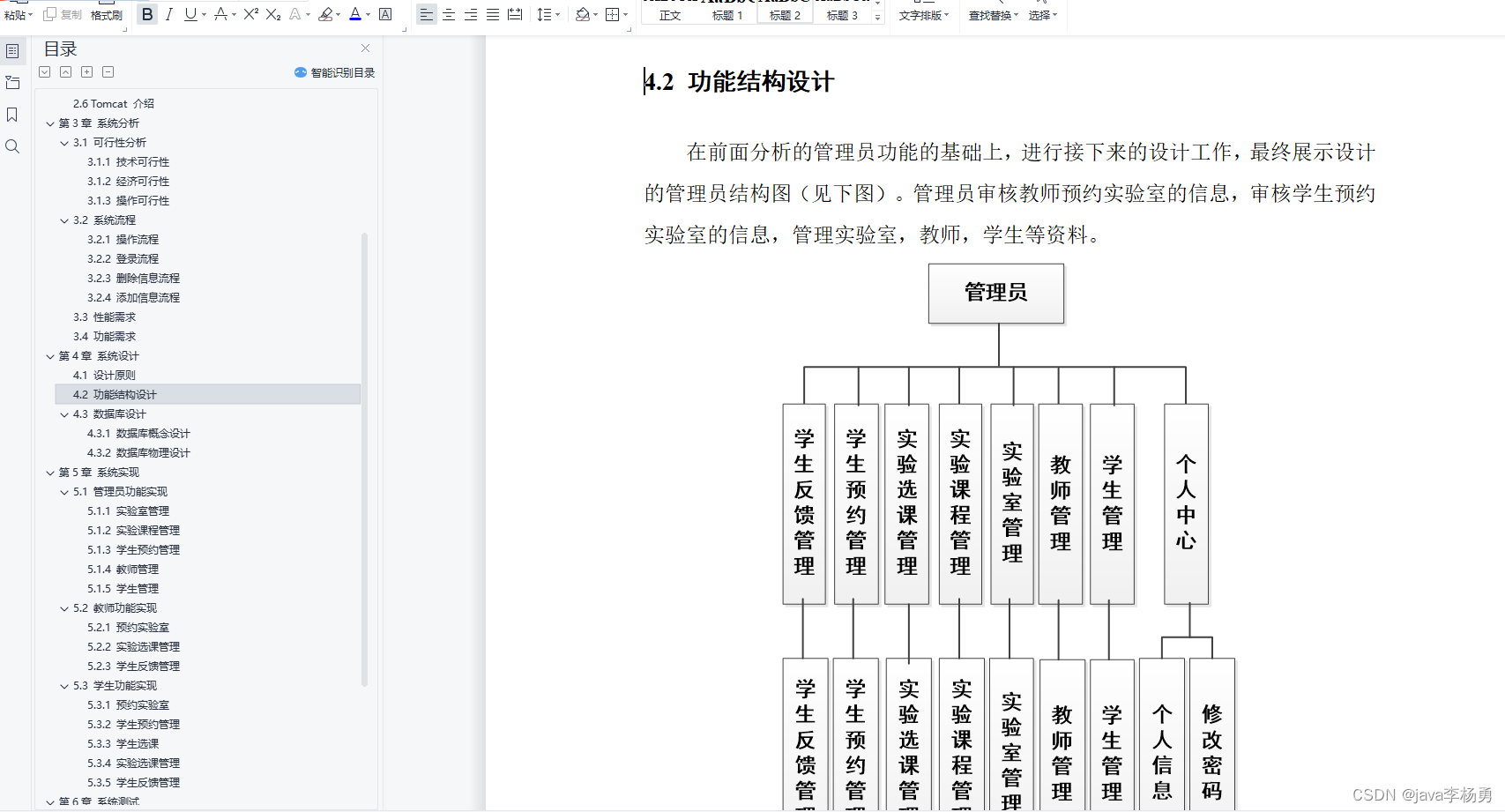
打通外部数据的管道,包含文档加载,文档转换,文本嵌入,向量存储几个环节。
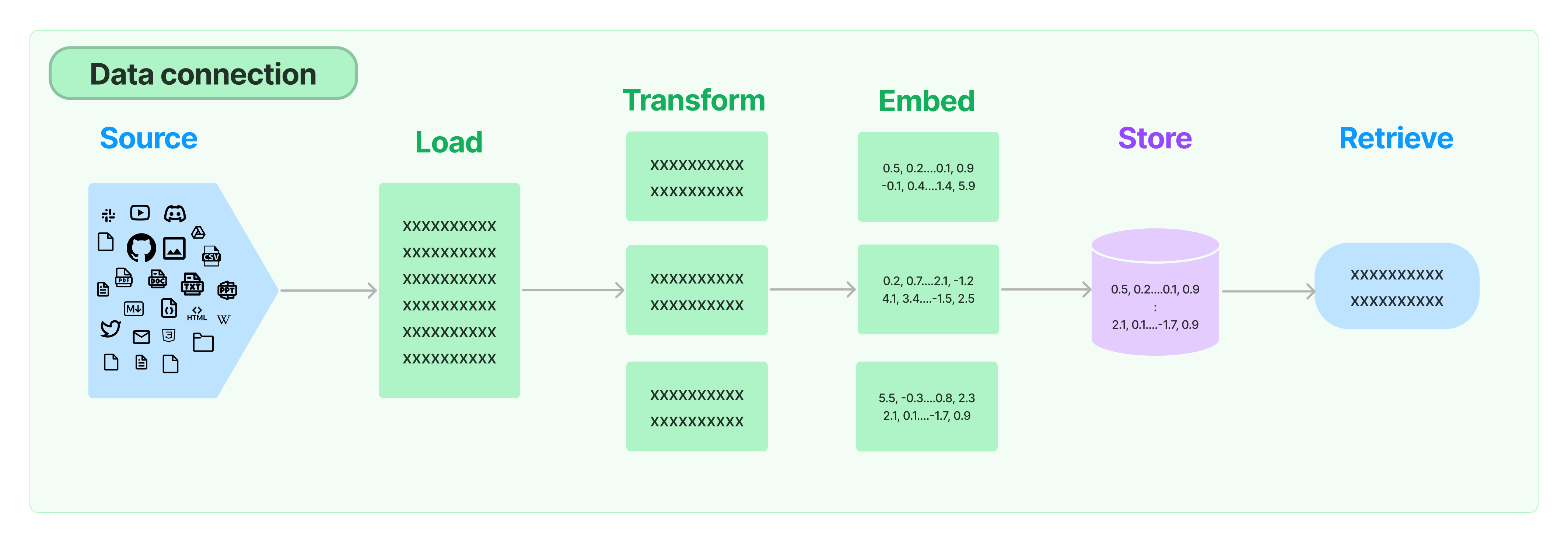
文档加载
重点包括了csv(CSVLoader),html(UnstructuredHTMLLoader),json(JSONLoader),markdown(UnstructuredMarkdownLoader)以及pdf(因为pdf的格式比较复杂,提供了PyPDFLoader、MathpixPDFLoader、UnstructuredPDFLoader,PyMuPDF等多种形式的加载引擎)几种常用格式的内容解析,但是在实际的项目中,数据来源一般比较多样,格式也比较复杂,重点推荐按需去查看与各种数据源
集成的章节说明,Discord、Notion、Joplin,Word等数据源。
文档拆分
重点关注按照字符递归拆分的方式 RecursiveCharacterTextSplitter ,这种方式会将语义最相关的文本片段放在一起。
文本嵌入
嵌入包含两个方法,一个用于嵌入文档,接受多个文本作为输入;一个用于嵌入查询,接受单个文本。文档中示例使用了OpenAI的嵌入模型text-embedding-ada-002,但提供了很多第三方嵌入模型集成可以按需查看。
from langchain.embeddings import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings()
# 嵌入文本
embeddings = embedding_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
len(embeddings), len(embeddings[0])
# 嵌入查询
embedded_query = embedding_model.embed_query("What was the name mentioned in the conversation?")
embedded_query[:5]
向量存储
这个就是对常用矢量数据库(FAISS,Milvus,Pinecone,PGVector等)封装接口的说明,详细的可以前往嵌入专题查看。大概流程都一样:初始化数据库连接信息——>建立索引——>存储矢量——>相似性查询,下面以 Pinecone为例:
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
import pinecone
loader = TextLoader("../../../state_of_the_union.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_ENV,
)
index_name = "langchain-demo"
docsearch = Pinecone.from_documents(docs, embeddings, index_name=index_name)
query = "What did the president say about Ketanji Brown Jackson"
docs = docsearch.similarity_search(query)
数据查询
这节重点关注数据压缩,目的是获得相关性最高的文本带入prompt上下文,这样既可以减少token消耗,也可以保证LLM的输出质量。
from langchain.llms import OpenAI
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
from langchain.document_loaders import TextLoader
from langchain.vectorstores import FAISS
documents = TextLoader('../../../state_of_the_union.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
retriever = FAISS.from_documents(texts, OpenAIEmbeddings()).as_retriever()
docs = retriever.get_relevant_documents("What did the president say about Ketanji Brown Jackson")
# 基础检索会返回一个或两个相关的文档和一些不相关的文档,即使是相关的文档也有很多不相关的信息
pretty_print_docs(docs)
llm = OpenAI(temperature=0)
compressor = LLMChainExtractor.from_llm(llm)
# 迭代处理最初返回的文档,并从每个文档中只提取与查询相关的内容
compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever)
compressed_docs = compression_retriever.get_relevant_documents("What did the president say about Ketanji Jackson Brown")
pretty_print_docs(compressed_docs)
针对基础检索得到的文档再做一次向量相似性搜索进行过滤,也可以取得不错的效果。
from langchain.retrievers.document_compressors import EmbeddingsFilter
embeddings = OpenAIEmbeddings()
embeddings_filter = EmbeddingsFilter(embeddings=embeddings, similarity_threshold=0.76)
compression_retriever = ContextualCompressionRetriever(base_compressor=embeddings_filter, base_retriever=retriever)
最后一点就是自查询(SelfQueryRetriever)的概念,其实就是结构化查询元数据,因为对文档的元信息查询和文档内容的概要描述部分查询效率肯定是高于全部文档的。
资源推荐
- LangGPT:一种面向大模型的 prompt 编程语言