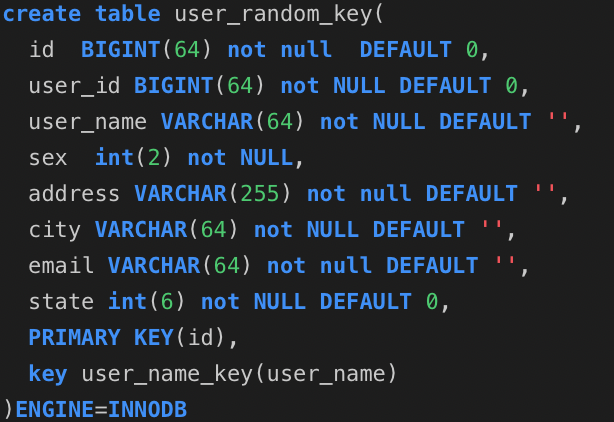
Python爬虫需要数据解析的原因是,爬取到的网页内容通常是包含大量标签和结构的HTML或XML文档。这些文档中包含所需数据的信息,但是需要通过解析才能提取出来,以便后续的处理和分析。

以下是一些使用数据解析的原因:
数据提取:网页内容通常包含大量的无关信息和嵌套结构,数据解析可以帮助我们从中提取出所需的信息,如标题、正文、链接、图片等。
数据清洗:爬取到的数据可能包含多余的空格、换行符、HTML标签等噪音数据,通过数据解析,我们可以清洗掉这些不需要的内容,使得数据更加整洁和可用。
数据转换:网页的数据往往以HTML或XML格式呈现,而我们可能需要将其转换成其他形式,如JSON、CSV、数据库等。数据解析可以帮助我们将提取到的数据按照需求进行格式转换。
数据结构化:提取出的数据通常以非结构化的形式存在,数据解析可以帮助我们将其转换为结构化的数据,方便后续的处理、存储和分析。
数据分析:通过数据解析,我们可以获得网页中的各种关键数据指标,以便进行进一步的数据分析和挖掘,帮助我们洞察信息和获取有价值的见解。
数据解析是爬虫过程中重要的一环,它能够将爬取到的原始网页内容转化为可用的、结构化的数据,从而更加方便地进行后续的处理和分析。
在Python爬虫中,有多种数据解析技术可供选择,常用的包括以下几种:
1、Beautiful Soup:Beautiful Soup是一个流行的Python库,用于解析HTML和XML文档,提供了简洁的API来提取所需的数据。它支持标签选择、CSS选择器和正则表达式等多种方式。
2、XPath:XPath是一种用于选取XML文档中节点的语言,也可以应用于HTML解析。在Python中,可以通过lxml库使用XPath进行网页解析。XPath使用路径表达式来定位和提取节点,具有强大的灵活性。
3、正则表达式:正则表达式是一种强大的模式匹配工具,在Python中通过re模块实现。正则表达式可以用于处理文本数据,并从中提取所的信息。对于简单的数据提取,正则表达式是快速而有效的选择。
这些技术各有特点,对于不同的解析任务,可以根据实际情况选择合适的技术。以下是一个简单示例,展示如何使用Beautiful Soup进行HTML解析:
import requests
from bs4 import BeautifulSoup
# 发起网络请求获取网页内容
url = 'https://www.example.com'
response = requests.get(url)
html_content = response.text
# 使用Beautiful Soup解析网页内容
soup = BeautifulSoup(html_content, 'html.parser')
# 使用CSS选择器获取特定的元素
title = soup.select_one('h1').text
links = [a['href'] for a in soup.select('a')]
# 打印提取的数据
print('Title:', title)
print('Links:', links)
需要根据实际网页结构和需求来选择合适的解析技术,并结合Python编程能力,灵活地处理和提取所需的数据。