前言
最近有遇到很多私信让我讲一讲多进程的爬虫,我发现大家对爬虫的框架写法和进程的理解有很多的问题和疑问,这次就带来一个小实战让大家理解多进程爬虫以及框架的写法
由于进程爬虫会对任何服务器都有一定的影响,本文仅供学习交流使用,切勿拿去做什么不好的事情,要做一个合法的爬虫写手。
📝个人主页→数据挖掘博主ZTLJQ的主页
个人推荐python学习系列:
☄️爬虫JS逆向系列专栏 - 爬虫逆向教学
☄️python系列专栏 - 从零开始学python
首先是网址摩托车品牌大全|摩托车报价 那么这个网址就是我们要进行爬取的目标
那其实有一定爬虫基础的同学呢就可以看出URL后缀pinpai.asp?ppt=&slx=0&skey=&page=1其实很好构造,一般看到这样的网站不会去想有什么动态的处理,不放心的话点击下一页然后打开F12抓包看看有没有变化,或者看一下点击下一页以后网站是不是不需要刷新就可以下一页就能判断是不是有什么动态处理了。
那么我们通过分析就知道这个网站是一个简单的静态页面,那么翻页的问题直接就搞定了,只需要把URL中的 ppt=&slx=0&skey=&page=1 page更换页码就可以了,但是我们既然是使用多进程,那就不要像之前一样写个简单的for循环 让爬虫程序一页一页的去翻。
那么我们的逻辑就很清晰,我们既然不想一页一页的翻就直接获取到尾页,如图:

点击尾页直接就能知道一共有多少页数据,为了防止每次都更新,所有直接在页面获取到尾页的数据即可,各位小伙伴可能进去以后就会疑惑,不点击尾页不会显示出有多少页那么怎么抓到有多少页数据呢?
这里就要和大家说一下,有时候写爬虫不要光想,打开F12看一下尾页哪里,a标签的href就直接有数据了,所以是可以直接抓的如下图:
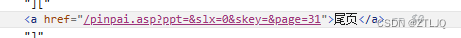
那么这个思路清楚以后就可以开始先写代码了,代码如下:
res = requests.get('https://www.2smoto.com/pinpai/')
text = xl(parse_xpath(res,"//a[contains(text(),'尾页')]/@href"))
# 这上面是开启多进程 然后获取这个网址总共有多少页 然后设置 每一个进程处理一页的数据
# 接下来取得尾页数据
count = text.split('=')[-1]
# 多进程
# 获取cpu 核心数量
cpu_count = multiprocessing.cpu_count() # 12个进程
pool = multiprocessing.Pool(processes=cpu_count)
for i in range(1,int(count)+1):
url = 'https://www.2smoto.com/pinpai.asp?ppt=&slx=0&skey=&page={}'.format(i)
pool.apply_async(request,(url,))
pool.close() # 关闭进程池 关闭之后 不能再向进程池中添加进程
pool.join() # 当进程池中所有进程执行完后,主进程才可以继续执行
print('程序用时{}'.format(time.time() - s))代码中先构造requests请求,然后通过上面我所说的获取到尾页的数据,text = xl(parse_xpath(res,"//a[contains(text(),'尾页')]/@href")),接下来就是每一个进程处理一页的数据,这个和线程不同,进程和线程的区别你可以理解为,进程相当于是按页分,线程是页中每一条数据来分。
我这里是直接获取CPU的核心数量就用了12个进程你们自己可以单独设置自己想要的数值。
接下来就是简单的for循环。最后要记得关闭进程池。
总体的逻辑分析清晰以后就是每一条数据的获取方式了,这个就非常简单了,使用XPATH或者正则表达式都可以,看你喜欢,我这里提供代码给大家参考,由于只是为了讲解就只爬取品牌和价格其他的东西你们喜欢可以自己加,代码如下:
goods_list = parse_xpath(res,'//ul[@class="goods_list"]/li')
for goods_lists in goods_list:
title = xl(goods_lists.xpath('./p[@class="name"]/a/@title'))
price = xl(goods_lists.xpath('./p[@class="price_wrap"]/span/text()'))
print({'品牌':title,'价格':price})
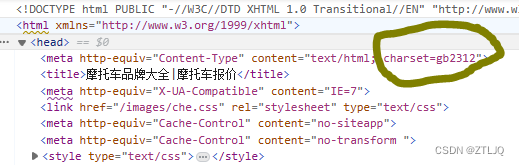
print('='*50)最后就是设置一个请求头即可,当然不要忘记查看一下这个网站的编码方式,我这里直接告诉大家如下图可以找到:
到这里其实基本上一整个代码都已经结束了,但是这次还要给大家提供一种框架的写法,也就是通用的爬虫框架,我下面会给大家一一介绍:
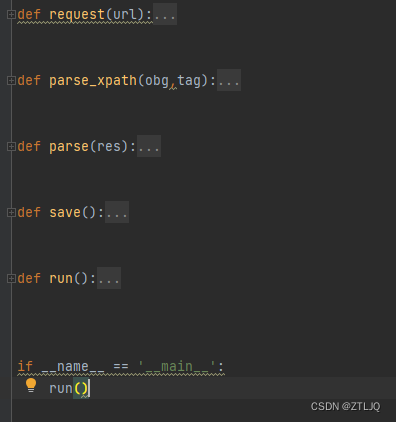
如图是一个非常简单的爬虫框架,我直接给大家代码,大家复制就可以使用了,代码如下:
def request(url):
"""
请求模块 负责网络请求
:return:
"""
def parse_xpath(obg,tag):
"""
负责 数据解析工作
:return:
"""
def parse(res):
"""
负责总体业务
:return:
"""
def save():
"""
负责存储数据
:return:
"""
def run():
"""
入口函数 开启任务
:return:
"""
那么这个框架其实就一目了然了,请求区域,解析区域,总体业务,存储,入口函数都有,大家不要觉得框架是无用的,其实等同学们出来工作后,每天都是在用框架进行工作和学习,所以提早接触是好事
那么就把刚刚进程的爬虫放入到这个框架中去,就会是这个情况,代码如下:
def request(url):
"""
请求模块 负责网络请求
:return:
"""
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36',
}
res = requests.get(url,headers=header)
res.encoding = 'gb2312'
if res.status_code == 200:
parse(res)
def parse_xpath(obg,tag):
"""
负责 数据解析工作
:return:
"""
html = etree.HTML(obg.text)
res = html.xpath(tag)
return res
def parse(res):
"""
负责总体业务
:return:
"""
goods_list = parse_xpath(res,'//ul[@class="goods_list"]/li')
for goods_lists in goods_list:
title = xl(goods_lists.xpath('./p[@class="name"]/a/@title'))
price = xl(goods_lists.xpath('./p[@class="price_wrap"]/span/text()'))
print({'品牌':title,'价格':price})
print('='*50)
def save():
"""
负责存储数据
:return:
"""
pass
def run():
"""
入口函数 开启任务
:return:
"""
res = requests.get('https://www.2smoto.com/pinpai/')
text = xl(parse_xpath(res,"//a[contains(text(),'尾页')]/@href"))
# 这上面是开启多进程 然后获取这个网址总共有多少页 然后设置 每一个进程处理一页的数据
# 接下来取得尾页数据
count = text.split('=')[-1]
# 多进程
# 获取cpu 核心数量
cpu_count = multiprocessing.cpu_count() # 12个进程
pool = multiprocessing.Pool(processes=cpu_count)
for i in range(1,int(count)+1):
url = 'https://www.2smoto.com/pinpai.asp?ppt=&slx=0&skey=&page={}'.format(i)
pool.apply_async(request,(url,))
pool.close() # 关闭进程池 关闭之后 不能再向进程池中添加进程
pool.join() # 当进程池中所有进程执行完后,主进程才可以继续执行
print('程序用时{}'.format(time.time() - s))
这样是不是就很方便了呢?这个框架到下一个网站,只需要改改URL这些就可以继续使用,所以框架的方便真的无法想象