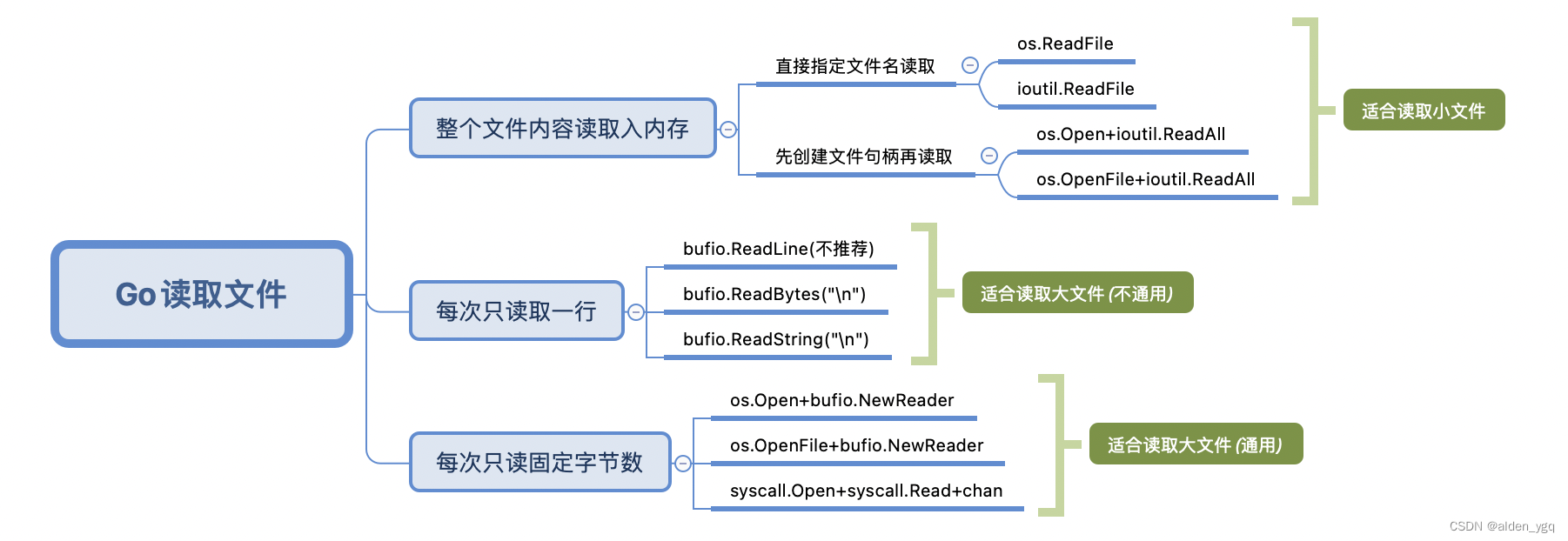
将数据保存到数据库
mysql数据库
下载链接数据库的依赖
Conda/pip install pymysql
在piplines.py 文件中
重写open_spider方法
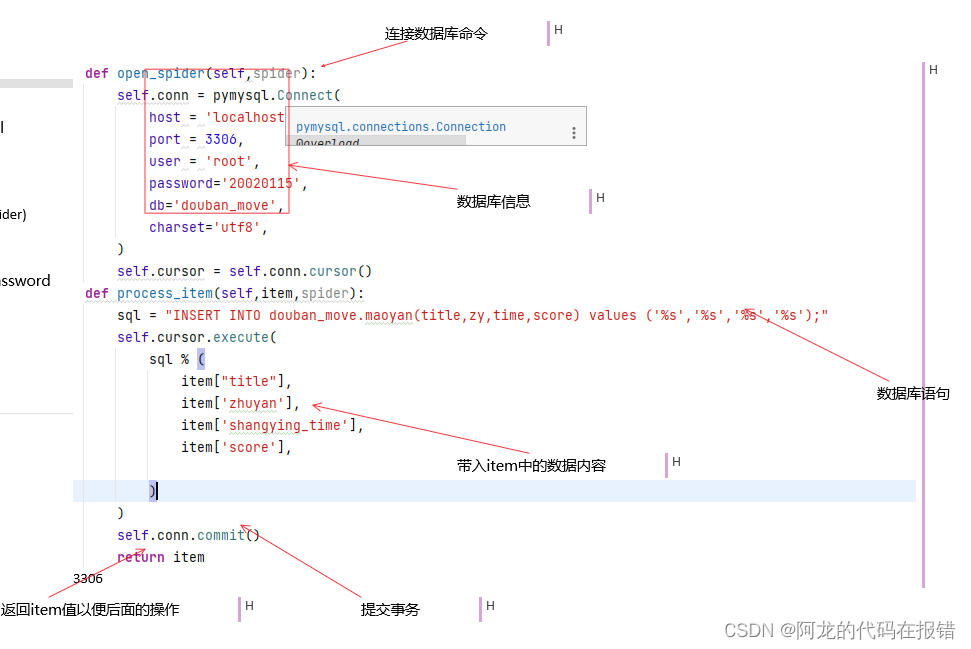
连接到mysql数据库
def open_spider(self, spider):
self.conn = pymysql.Connect(
host='localhost',
port=3306,
user='root',
password='20020115',
db='scrapy',
)
self.cursor = self.conn.cursor()
重写process_item方法
将数据保存到数据库中
def process_item(self, item, spider):
sql = "INSERT INTO scrapy.srr1(movie_name,movie_dates,movie_times,movie_scores,movie_adds,movie_pq) values ('%s','%s','%s','%s','%s','%s')"
self.cursor.execute(
sql % (
item['movie_name'],
item['movie_dates'],
item['movie_times'],
item['movie_scores'],
item['movie_adds'],
item['movie_pd'],
)
)
self.conn.commit()
return item
重写close_spider()
关闭爬虫时关闭数据库连接
def close_spider(self, spider):
self.conn.close()
self.cursor.close()
代码解析
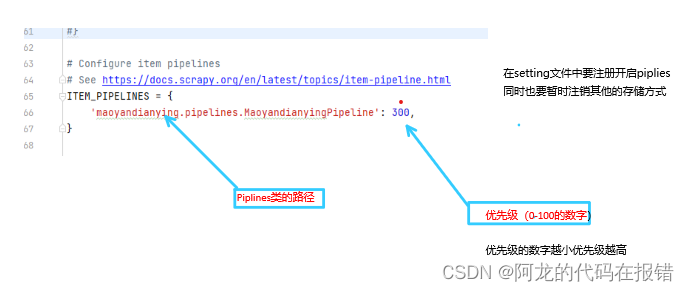
最后找到setting.py文件中的以下内容并且取消注释并且将指定优先级(优先级是一个 )
ITEM_PIPELINES = {
"ss1_miove.pipelines.Ss1MiovePipeline": 300,
}
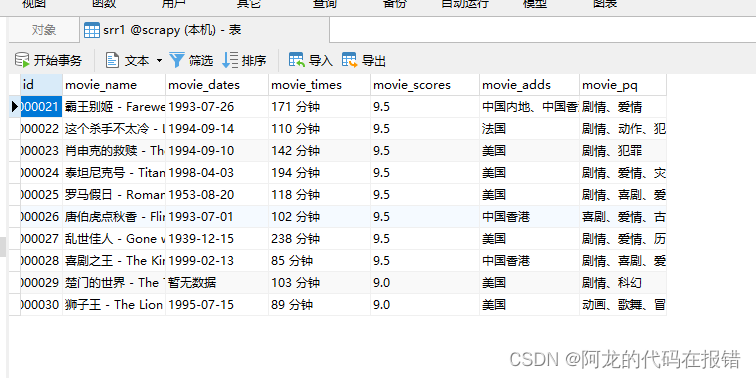
在native中查看数据验证程序是否成功运行
mongoDB数据库
数据库的安装参考:MongoDB数据库安装_阿龙的代码在报错的博客-CSDN博客
在Python环境中下载pymongo的库用来连接数据库并且写入数据
pip install pymongo
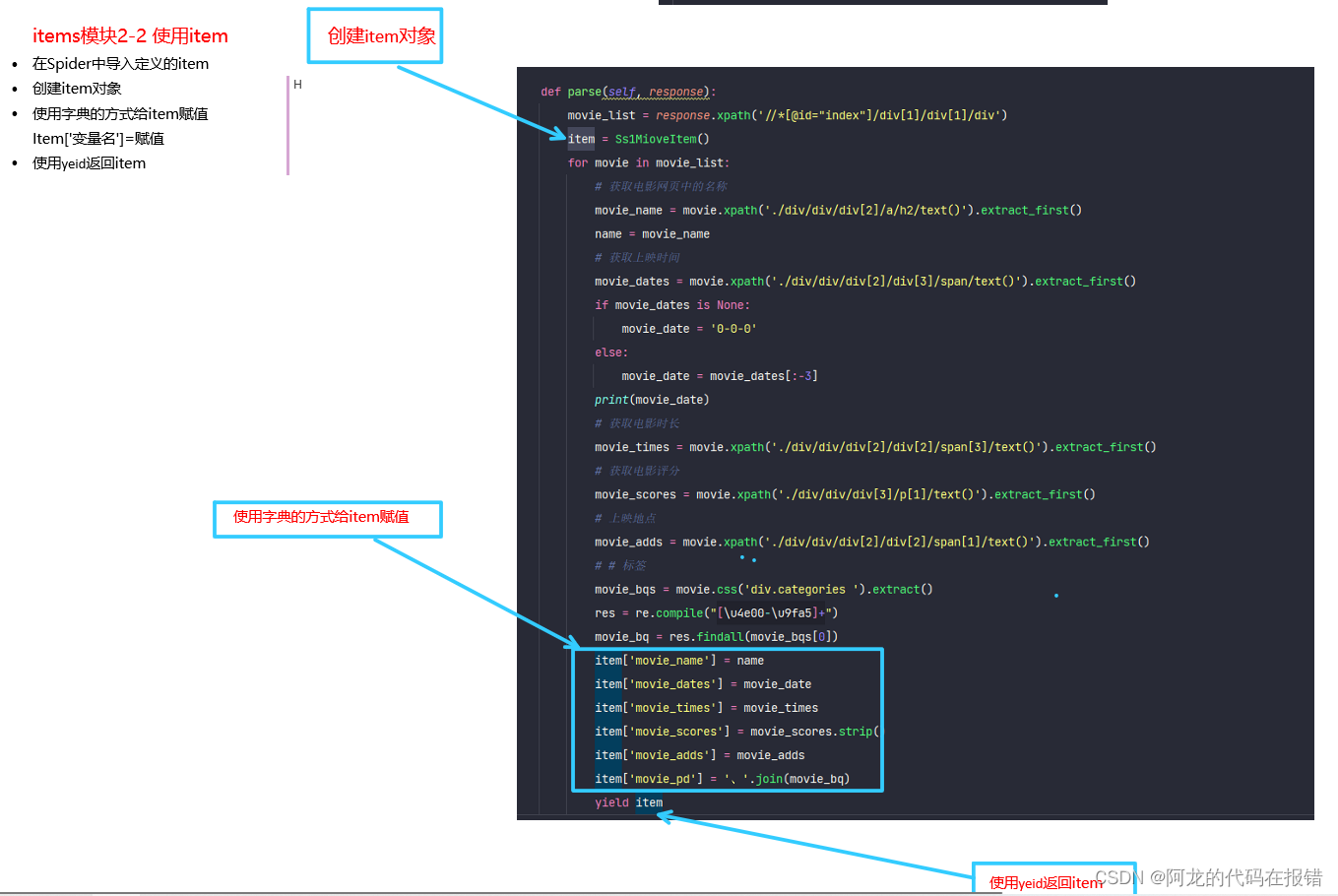
在其他内容不变的前提下载piplines.py文件中创建一个新的类并且重写open_spider、process_item、close_spider这三个方法
# 将数据写入MongoDB数据库
class Scrapyssr1Miovemongopipline(object):
def open_spider(self, spider):
self.conn = pymongo.MongoClient('localhost', 27017)
self.db = self.conn.ssr1_movie
self.mioves = self.db.mioves
def process_item(self, item, spider):
self.mioves.insert_one(
{
"name": item['movie_name'],
"date": item['movie_dates'],
"time": item['movie_times'],
"score": item['movie_scores'],
"location": item['movie_adds'],
"pq": item['movie_pd'],
}
)
def close_spider(self, spider):
self.conn.close()
代码解析
需要注意的是:pymongo 4.0.2 不再使用 insert () 而使用 insert_one () 或 insert_many ()
最后一步就是去setting.py文件中注册并且设置优先级
这里需要将其他的持久化存储方式注释掉
ITEM_PIPELINES = {
# "ss1_miove.pipelines.Ss1MiovePipeline": 300,
'ss1_miove.pipelines.Scrapyssr1Miovemongopipline': 300,
}
在MongoDB图形化程序中查看数据验证程序是否成功运行
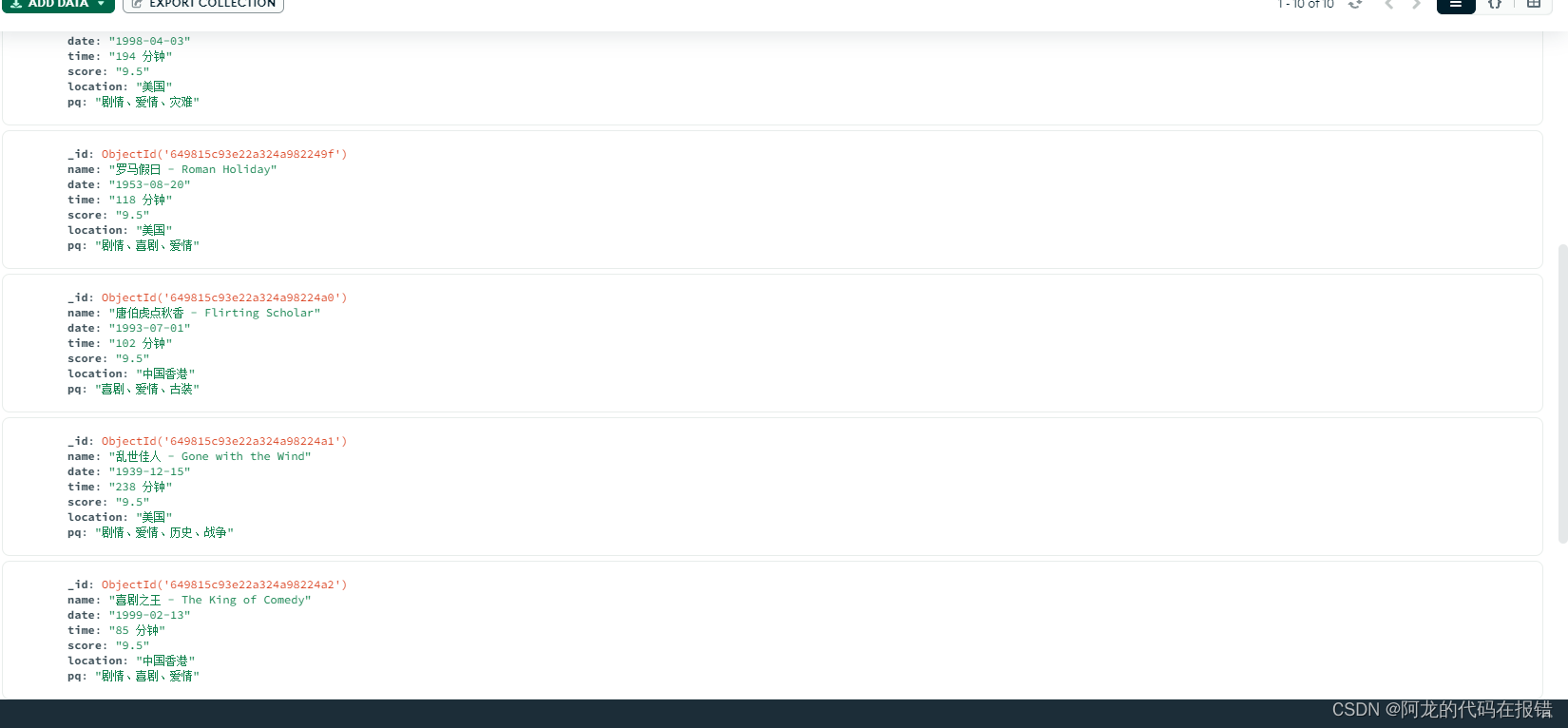
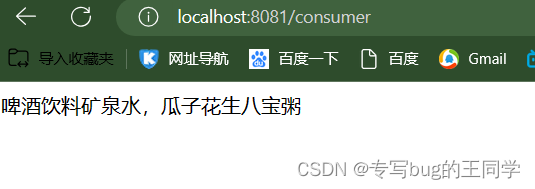
数据库中有数据并且数据正确,证明数据采集成功,并且完成数据的持久化存储
上一篇文章:创建完整的scrapy
个人笔记仅供参考,部分电脑可能因为环境不用代码无法运行,见谅。