概述
官网
https://www.python.org/
Python 是一种脚本语言(scripting language)。
与编译型语言(如 C 和 C++)不同,Python 的程序代码不需要进行显式的编译,在执行时会动态地解释执行代码。
Python 的脚本执行器可以直接解析并执行 Python 代码,无需将代码编译成可执行文件。
Python 脚本语言的特点之一是易于学习和使用。
Python 的语法简单、清晰,具有高度的可读性和可维护性,使得编写 Python 脚本非常方便。
同时,Python 也是一种功能强大、灵活性高的语言,支持多种编程范式,包括面向过程、面向对象和函数式编程等。
Python 脚本语言的另一个优势是跨平台性。
由于 Python 的程序代码不需要进行编译,因此可以在多个操作系统平台上运行,包括 Windows、Linux、macOS 等。
这使得 Python 成为一种广泛应用于软件开发、数据科学、人工智能和网络编程等领域的语言。
Python入门篇

基本语法
代码缩进
缩进4空格=1tab:

代码注释
# 单行注释
"""
多行注释
多行注释
"""
'''
多行注释
多行注释
'''
python关键字
⚠️ 在命名py文件时,不要与python自有包名一样,否则可能会报错
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OKRLDSkB-1687659109635)(./Python.assets/image-20230324160520881.png)]](https://img-blog.csdnimg.cn/44c41ec4cf0343fbbb9218b2d378b019.png)
import keyword
print(keyword.kwlist)
输出的关键字:
['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
引号
在python中可以使用单号号和双引号
print('hello')
print("world")
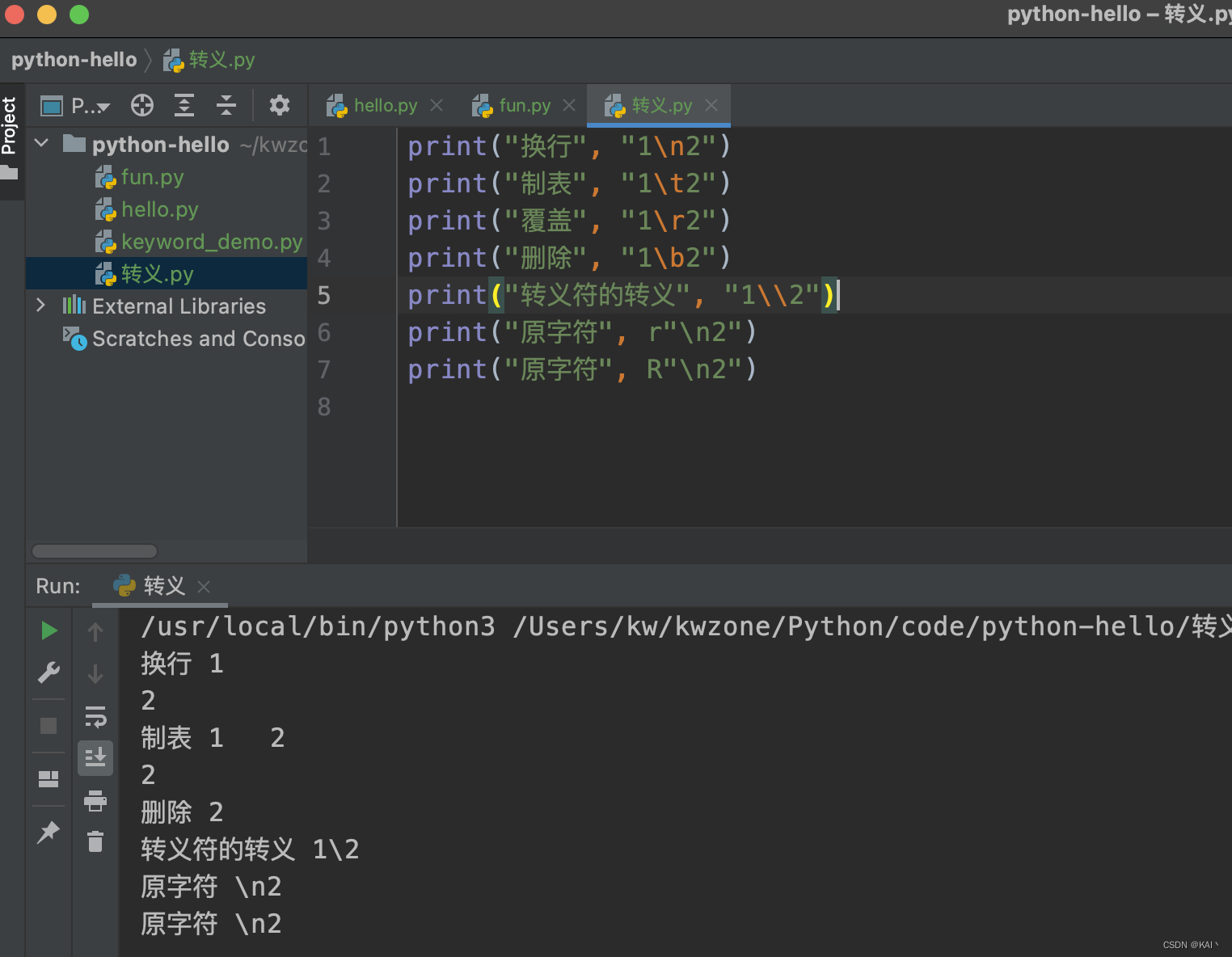
转义符
print("换行", "1\n2")
print("制表", "1\t2")
print("覆盖", "1\r2")
print("删除", "1\b2")
print("转义符的转义", "1\\2")
print("原字符", r"\n2")
print("原字符", R"\n2")
变量
Python 的变量是用于存储数据值的标识符(identifier)。
Python 的变量声明非常简单,只需要给变量名赋值即可,无需显式声明变量类型。
Python 的变量名可以是任意长度的字母、数字或下划线的组合,但不能以数字开头。
Python 的变量名区分大小写。
在 Python 中,可以使用
type()函数查看变量的类型。需要注意的是,Python 的变量赋值实际上是在内存中创建了一个对象,并将该对象的引用赋值给变量。
因此,在对变量进行操作时,需要注意变量所引用的对象的类型和属性。
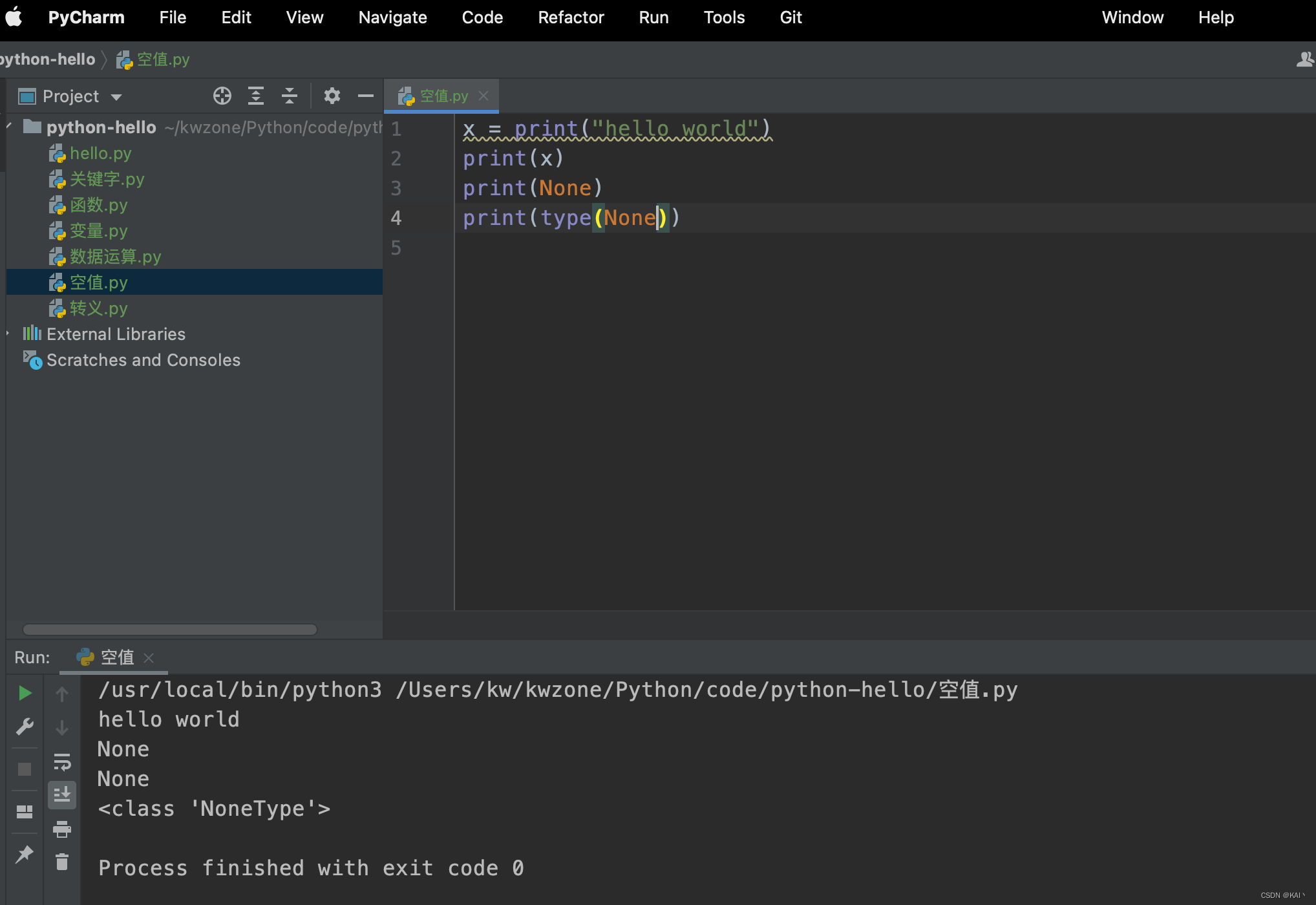
空值
算一种数据类型
内置函数是有返回值的,返回值为None
数据类型
Python 的数据类型非常灵活,支持动态类型和自动类型转换,使得编写 Python 程序变得非常方便。在编写 Python 程序时,需要根据需要选择合适的数据类型,以便更好地表达数据和实现相应的功能。
Python 有多种数据类型,包括但不限于以下几种:
- 数字(Numbers):整数、浮点数、复数等。
- 字符串(Strings):表示文本数据。
- 列表(Lists):有序集合,可以包含不同类型的元素。
- 元组(Tuples):有序集合,类似于列表,但元素不能修改。
- 集合(Sets):无序集合,不允许重复元素。
- 字典(Dictionaries):键-值对的无序集合,用于表示映射关系。
- 布尔值(Booleans):表示真或假两种状态。
除了上述数据类型外,Python 还有一些其他的内置数据类型,例如字节串(Bytes)和字节数组(Bytearrays),以及一些常用的数据结构,例如栈(Stacks)、队列(Queues)、堆(Heaps)等。此外,还可以使用第三方库来引入其他的数据类型,例如 Pandas 中的数据框(DataFrames)和 Numpy 中的数组(Arrays)。
整型(int)
表示整数,如 1、2、3 等。
浮点型(float)
表示浮点数,即带有小数部分的数字,如 1.0、2.5、3.1416 等。
字符串(str)
表示文本数据,用单引号或双引号括起来,如 ‘hello’、“world” 等。
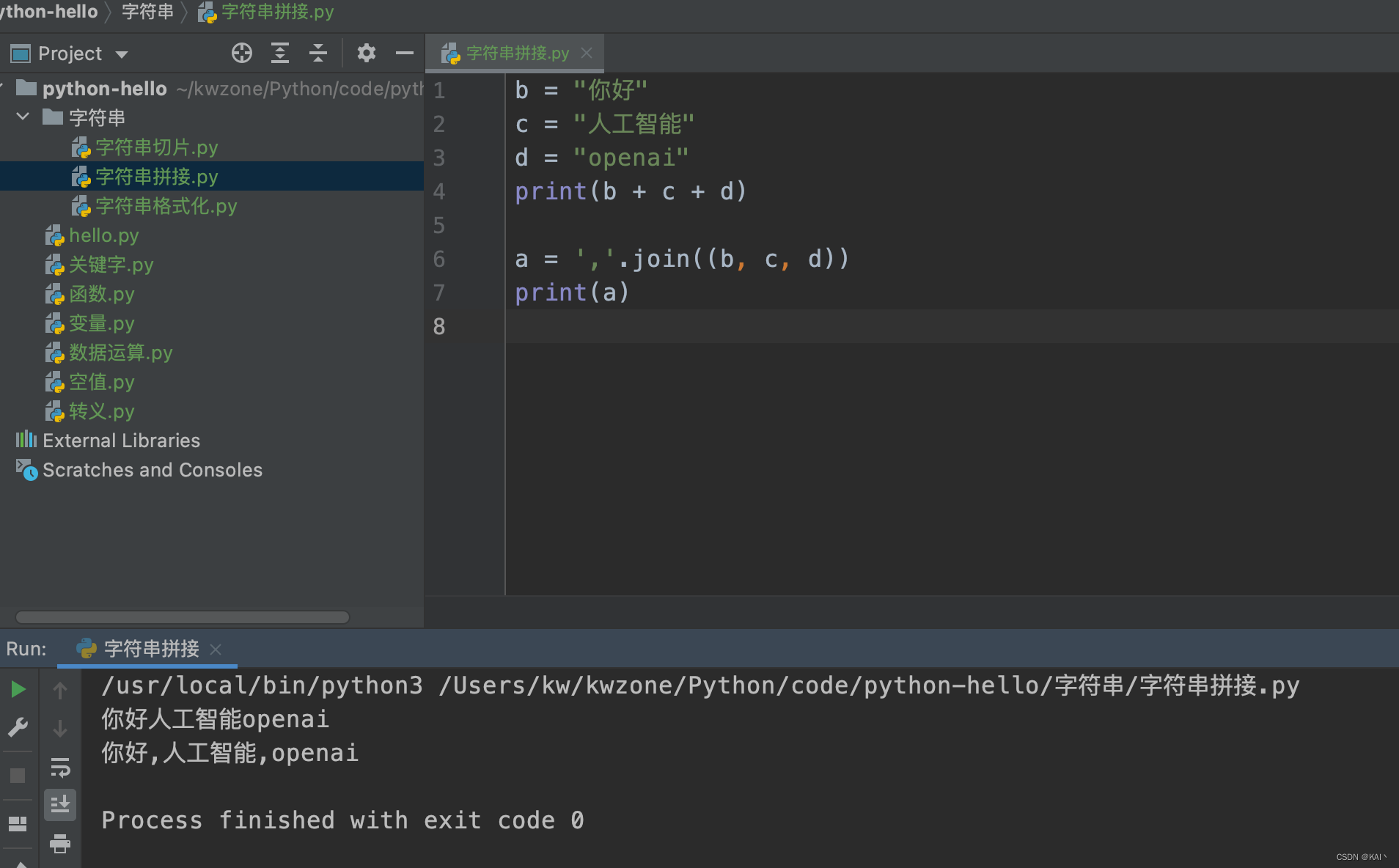
字符串拼接
b = "你好"
c = "人工智能"
d = "openai"
print(b + c + d)
a = ','.join((b, c, d))
print(a)
格式化,即占位符
百分号%
%s 为字符占位,任意类型都可以
%d 为正数占位,输入小数,会取整数位
%f 为浮点数占位,输入整数,会显示小数位,精度为6
format函数
占位符与传入的数据数量要一致,否则会报错
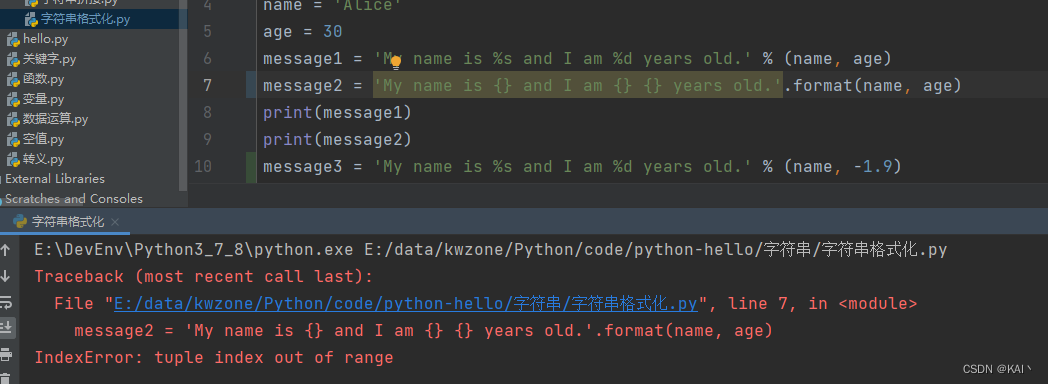
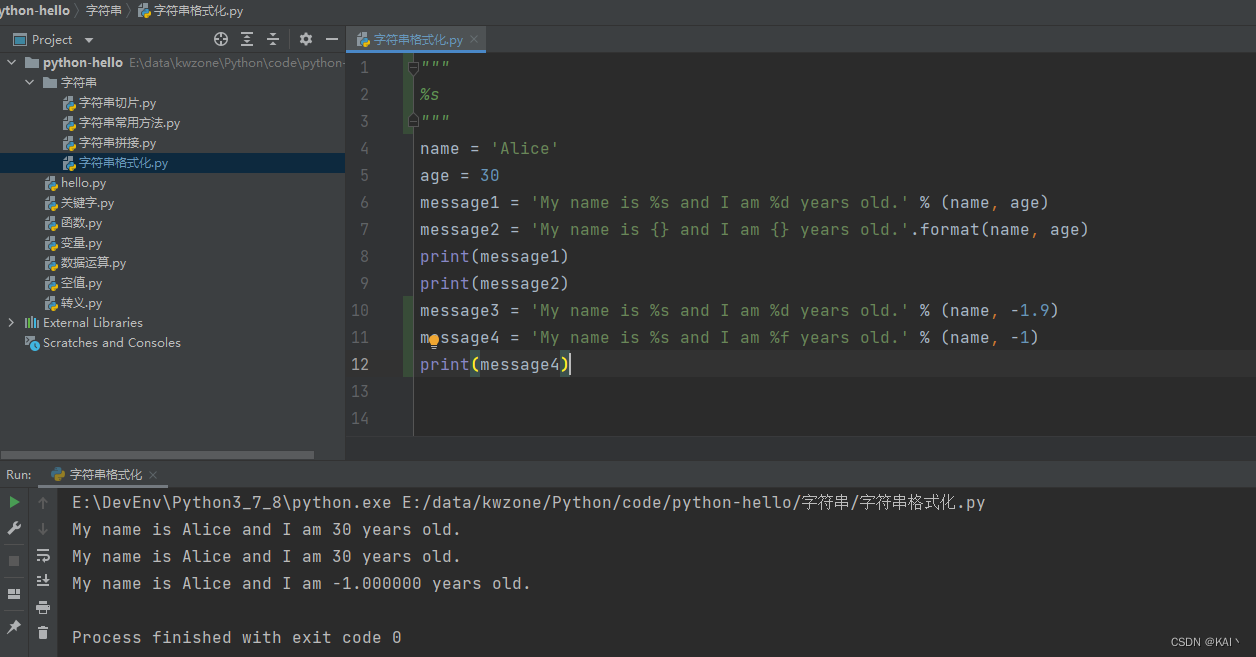
name = 'Alice'
age = 30
message = 'My name is %s and I am %d years old.' % (name, age)
message = 'My name is {} and I am {} years old.'.format(name, age)
F表达式
Python3.6以上支持
大小写F都可以
name = 'Alice'
age = 30
message5 = F'My name is {"李白"} and I am {18} years old.'
message6 = f'My name is {name} and I am {age} years old.'
print(message5)
print(message6)
format进阶用法
元组索引占位
message = 'My name is {1} and I am {0} years old.'.format(name, age)
print(message) # My name is 30 and I am Alice years old.
保留小数位
num1 = 3.1415926
message7 = '圆周率:{:.2f}'.format(num1)
print(message7) # 圆周率:3.14
格式化百分数
num2 = 0.12
message8 = '百分数:{:.2%}'.format(num2)
print(message8) # 百分数:12.00%
字符串常用方法
s = 'hello, world'
print("s:", s)
print("转换为大写字母:", s.upper())
print("转换为小写字母:", s.lower())
print("将第一个字符转换为大写:", s.capitalize())
print("将每个单词的首字母转换为大写:", s.title())
print("是否以'hello'开头:", s.startswith('hello'))
print("是否以'world'结尾:", s.endswith('world'))
print("将所有的'l'替换为'L':", s.replace('l', 'L'))
print("使用','分割字符串为列表:", s.split(","))
print("获取字符串长度:", len(s))
print("查找元素:", s.find("h")) # 0
print("在指定索引区间查找元素:", s.find("h", 1, 5)) # -1
print("统计元素数量:", s.count("l")) # 3
print("去除字符串首尾的空格", "111 ".strip())
print("字符串的乘法","李白"*3) #字符串的乘法 李白李白李白
字符串切片
[开始:结尾:步长]
在Python中,可以使用切片操作(slicing)从一个字符串中提取出一个子字符串。
切片操作使用中括号和冒号表示,语法为
[start:stop:step],其中
start表示起始索引,stop表示终止索引,step表示步长。注意,起始索引包含在结果中,但终止索引不包含在结果中。即[ ) 取左不取右
如果省略
start,则默认为 0;如果省略
stop,则默认为字符串的长度;如果省略
step,则默认为 1。
s = 'Hello, world!'
s[0:5] # 'Hello'
s[7:12] # 'world'
s[0:12:2] # 'Hlo ol'
s[:5] # 'Hello'
s[7:] # 'world!'
s[::-1] # '!dlrow ,olleH',反转字符串
上面的示例中,s[0:5] 提取了字符串 s 中的前 5 个字符,
而 s[7:12] 提取了字符串 s 中的第 7 个字符到第 12 个字符(不包含第 12 个字符)之间的子字符串。
而 s[::-1] 则使用了步长为 -1,实现了字符串的反转操作。
需要注意的是,切片操作不会修改原始的字符串,而是返回一个新的字符串。
字符串的比较
old()函数
chr()函数
id()函数
max min函数
比较大小时,字符类型会被转为 ascii码
字符串的编码转换
encode函数
decode函数
字符串的驻留机制
大概类似java Integer缓存?
布尔型(bool)
表示逻辑值,只有两个取值,True 和 False。
布尔值可以转换为数字的,True1 False0
列表(list)
表示一组有序的数据,可以包含任意类型的数据,用中括号括起来,如 [1, 2, 3]、[‘hello’, ‘world’] 等。
定义列表
# 定义list
list1 = [1, 2, 3, 4, 5, "李白", ["香蕉", "苹果", "葡萄"]]
print("输出列表信息:", list1) # [1, 2, 3, 4, 5, '李白', ['香蕉', '苹果', '葡萄']]
print("列表长度:", len(list1))
访问列表元素
# 通过索引访问list元素
print("索引访问元素:", list1[0], list1[6][2]) # 1 葡萄
列表切片
# 列表切片
print("列表切片:", list1[0:2]) # [1, 2]
print("列表切片:", list1[:2]) # [1, 2]
print("列表切片:", list1[1:]) # [2, 3, 4, 5, '李白', ['香蕉', '苹果', '葡萄']]
print("列表切片:", list1[-2]) # 李白
修改列表元素
list1[5] = '杜甫'
print("修改列表元素", list1) # [1, 2, 3, 4, 5, '杜甫', ['香蕉', '苹果', '葡萄']]
添加列表元素
list1.append("白居易")
print("添加一个元素", list1) # [1, 2, 3, 4, 5, '杜甫', ['香蕉', '苹果', '葡萄'], '白居易']
删除元素
remove函数
只会删除匹配到的第一个元素
list1 = [2, 3, 2, 3]
list1.remove(2)
print("remove", list1) # [3, 2, 3]
list2 = [2, 3, 2, 3]
list2.remove(list2[2])
print("remove", list2) # [3, 2, 3]
pop函数
删除指定下标元素
list3 = [2, 3, 2, 3]
list3.pop(2)
print("pop", list3) # [2, 3, 3]
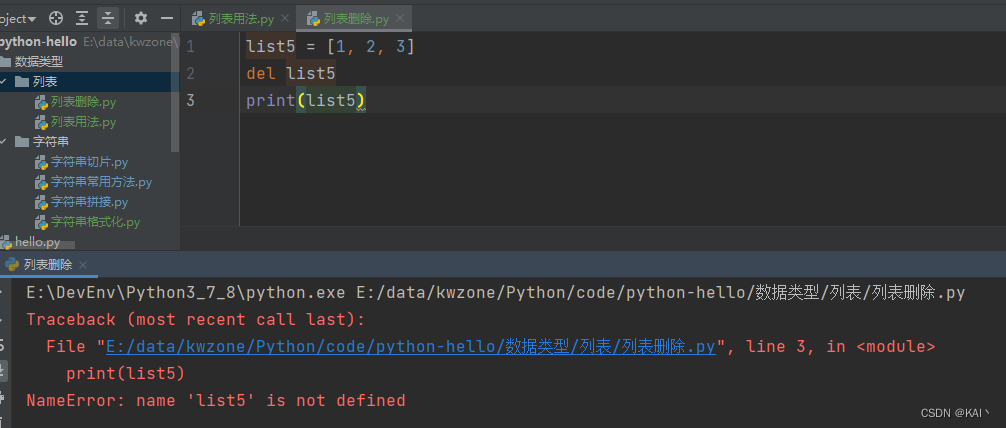
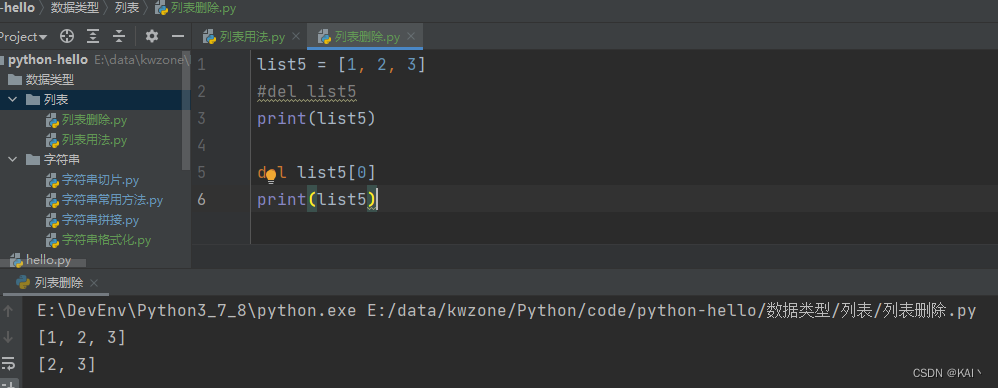
del关键字
使用del关键字删除整个列表
删除指定元素
列表排序
list2 = [3, 5, 2]
list2.sort()
print("列表排序", list2) # [2, 3, 5]
插入列表元素
list2.insert(1, 1)
print("在第二个位置插入值1:", list2)
列表的乘法
list3 = [1, 2, 3]
print("列表的乘法", list3 * 2) # [1, 2, 3, 1, 2, 3]
多个列表融合
注意:
使用加号运算符或 extend() 方法融合列表时,不会创建新的列表对象,而是将元素添加到原有的列表中。
list4 = [3, 4, 5]
print("列表融合方式一", list3 + list4) # [1, 2, 3, 3, 4, 5]
#list4的末尾添加list3
list4.extend(list3)
print("列表融合方式二", list4) # [3, 4, 5, 1, 2, 3]
推荐使用extend,节约内存空间
清空列表
list4.clear()
print("清空列表:", list4) # []
index函数
listA = ["李白", "杜甫", "白居易"]
print("查找元素所在索引", listA.index("李白")) # 0
print("在索引区间,查找元素所在索引", listA.index("李白", 1, 2)) # 报错了
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tXSYe4VT-1687659109635)(Python.assets/image-20230326204243476.png)]
reverse函数
反转
listA = ["李白", "杜甫", "白居易"]
listA.reverse()
print(listA) # ['白居易', '杜甫', '李白']
copy函数
list拷贝函数
listA = ["李白", "杜甫", "白居易"]
listB = listA.copy()
print("列表复制", listB) # ["李白", "杜甫", "白居易"]
listB = listA
#这么赋值,等于listA listB仍然指向同一个对象
count
用于统计某个元素在列表中的数量
元组(tuple)
与列表类似,但是元组是不可变的,用小括号括起来,如 (1, 2, 3)、(‘hello’, ‘world’) 等。
元组的元素是不是被修改的,
但元组中的元素对象中的值是可以修改的,比如元组中的List对象,可以修改List元素中的值
元组定义
tupleA = (1, 2, 3)
print(type(tupleA)) # <class 'tuple'>
#也可以不加括号
tupleC = 1, 2, 3
print(type(tupleC)) # <class 'tuple'>
#但是只有一个元素时,需要加逗号,否则就不是元组类型了
tupleE = (1)
print(type(tupleE)) # <class 'int'>
#应该这么写
tupleE = (1,)
print(type(tupleE))
元组的拼接
与list用法一样
tupleA = (1, 2, 3)
print(type(tupleA))
tupleB = (1, 2, 3)
print(tupleB+tupleA) # (1, 2, 3, 1, 2, 3)
集合(set)
集合(Set)是 Python 中的一种无序、可变的容器,其中每个元素都是唯一的(即不重复)。
集合可以用来进行数学上的集合运算,比如交集、并集、差集等。
表示一组互不相同的数据,用大括号括起来,如 {1, 2, 3}、{‘hello’, ‘world’} 等。
集合定义
setA = {1, 2, 2, 3}
print(type(setA)) # <class 'set'>
print(setA) # {1, 2, 3}
# 使用set函数创建集合
setB = set("12312")
print(setB) # {'3', '1', '2'}
#空集合
sNone = set()
print(sNone) # set()
print(type(sNone)) # <class 'set'>
添加元素
setB.add("4")
print(setB) # {'2', '1', '4', '3'}
setB.add("李白")
print(setB) # {'2', '李白', '3', '1', '4'}
合并集合
setC = {1, 2, 3}
setD = {"a", "b", "c"}
#C集合合并D集合,D集合不会变化
setC.update(setD)
print(setC) # {'b', 1, 2, 3, 'a', 'c'}
print(setD) # {'b', 'a', 'c'}
集合元素删除
remove
pop
discard
# 元素删除
setE = {"李白", "杜甫", "白居易", "王羲之"}
print(setE) # {'李白', '白居易', '杜甫'}
# 删除的元素不存在会报错
setE.remove("李白")
print(setE) # {'白居易', '杜甫'}
# 随机删除
# setE.pop()
# 删除的元素不存在,不会报错
setE.discard("李白2")
print(setE)
集合的交易和并集
s1 = {1, 2, 3}
s2 = {3, 4, 5}
print("集合的交集", s1 & s2) # {3}
print("集合的并集", s1 | s2) # {1, 2, 3, 4, 5}
字典(dict)
字典(Dictionary)是一种映射类型的数据结构,其中每个元素由一个键(key)和一个值(value)组成。
字典中的键必须是唯一的且不可变的,值可以是任意类型的对象。
表示一组键值对的数据,用大括号括起来,如 {‘name’: ‘John’, ‘age’: 30} 等。
字典定义
dictA = {
"name": "李白",
"age": 18,
"name": "杜甫",
}
print(type(dictA)) # <class 'dict'>
# 重复元素,后者会覆盖前者
print(dictA) # {'name': '杜甫', 'age': 18}
# 直接写大括号,表达的是字典,不是集合
dictB = {}
print(type(dictB)) # <class 'dict'>
# dict函数创建字典
dictC = dict([('name1', '杜甫'), ('name2', '李白')])
print(dictC) # {'name1': '杜甫', 'name2': '李白'}
添加或修改
# dict函数创建字典
dictC = dict([('name1', '杜甫'), ('name2', '李白')])
print(dictC) # {'name1': '杜甫', 'name2': '李白'}
# 添加或修改元素
dictC['name4'] = '王羲之'
dictC['name2'] = '王维'
print(dictC) # {'name1': '杜甫', 'name2': '王维', 'name4': '王羲之'}
删除元素
# 删除元素
del dictC['name1']
print(dictC) # {'name2': '王维', 'name4': '王羲之'}
获取元素
# get获取不存在的key不会报错,会返回None
print("获取字典中的值", dictC.get("name1"))
# 若Key不存在,会报错
print("获取字典中的值", dictC['name1'])
获取字典的key
keys = dictC.keys()
print(keys) # dict_keys(['name2', 'name4'])
字典遍历
print(dictC.items()) # dict_items([('name2', '王维'), ('name4', '王羲之')])
print(dictC.values()) # dict_values(['王维', '王羲之'])
clear函数
清空字典
dictD.clear()
print(dictD) # {}
copy函数
拷贝副本
dictD = dictC.copy()
print("dictD", dictD) # {'name2': '王维', 'name4': '王羲之'}
fromkeys函数
fromkeys() 是字典类方法之一,用于创建一个新字典,其中包含指定的键和相应的默认值
dictE = {}
dictE = dictE.fromkeys(("name1", "name2"))
print("dictE", dictE) # {'name1': None, 'name2': None}
dictE = dictE.fromkeys(("name1", "name2"), ("李白", "杜甫"))
# 会把元组的值都赋值给key,不是一一对应赋值
print("dictE", dictE) # {'name1': ('李白', '杜甫'), 'name2': ('李白', '杜甫')}
pop函数
删除指定的Key,并会返回指定的值
dictE.pop("name1")
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LrG61von-1687659109636)(Python.assets/image-20230326223846937.png)]
popitem函数
删除最后一个元素
dictF = {
'name1': "李白", "name2": "杜甫"
}
print("dictF", dictF)
popitem = dictF.popitem()
print("popitem:", popitem) # ('name2', '杜甫')
print(dictF) # {'name1': '李白'}
setdefault函数
setdefault()是字典类方法之一,用于获取字典中指定键的值,如果键不存在,则设置指定的默认值,并返回该默认值。
fruits = {'apple': 1, 'banana': 2, 'orange': 3}
# 获取字典中已有键的值
apple_value = fruits.setdefault('apple')
print(apple_value) # 输出:1
# 获取字典中不存在的键的值,并设置默认值
mango_value = fruits.setdefault('mango', 4)
print(mango_value) # 输出:4
print(fruits) # 输出:{'apple': 1, 'banana': 2, 'orange': 3, 'mango': 4}
# 获取字典中不存在的键的值,不设置默认值
pear_value = fruits.setdefault('pear')
print(pear_value) # 输出:None
print(fruits) # 输出:{'apple': 1, 'banana': 2, 'orange': 3, 'mango': 4, 'pear': None}
update函数
update()是字典类方法之一,用于将一个字典的键值对添加到另一个字典中,或用一个字典的键值对更新另一个字典中相同键的值。
fruits1 = {'apple': 1, 'banana': 2}
fruits2 = {'orange': 3, 'mango': 4}
# 将 fruits2 的键值对添加到 fruits1 中
fruits1.update(fruits2)
print(fruits1) # 输出:{'apple': 1, 'banana': 2, 'orange': 3, 'mango': 4}
# 将 fruits1 中已有键的值更新为 fruits2 中的值
fruits2 = {'orange': 5, 'mango': 6}
fruits1.update(fruits2)
print(fruits1) # 输出:{'apple': 1, 'banana': 2, 'orange': 5, 'mango': 6}
数据运算
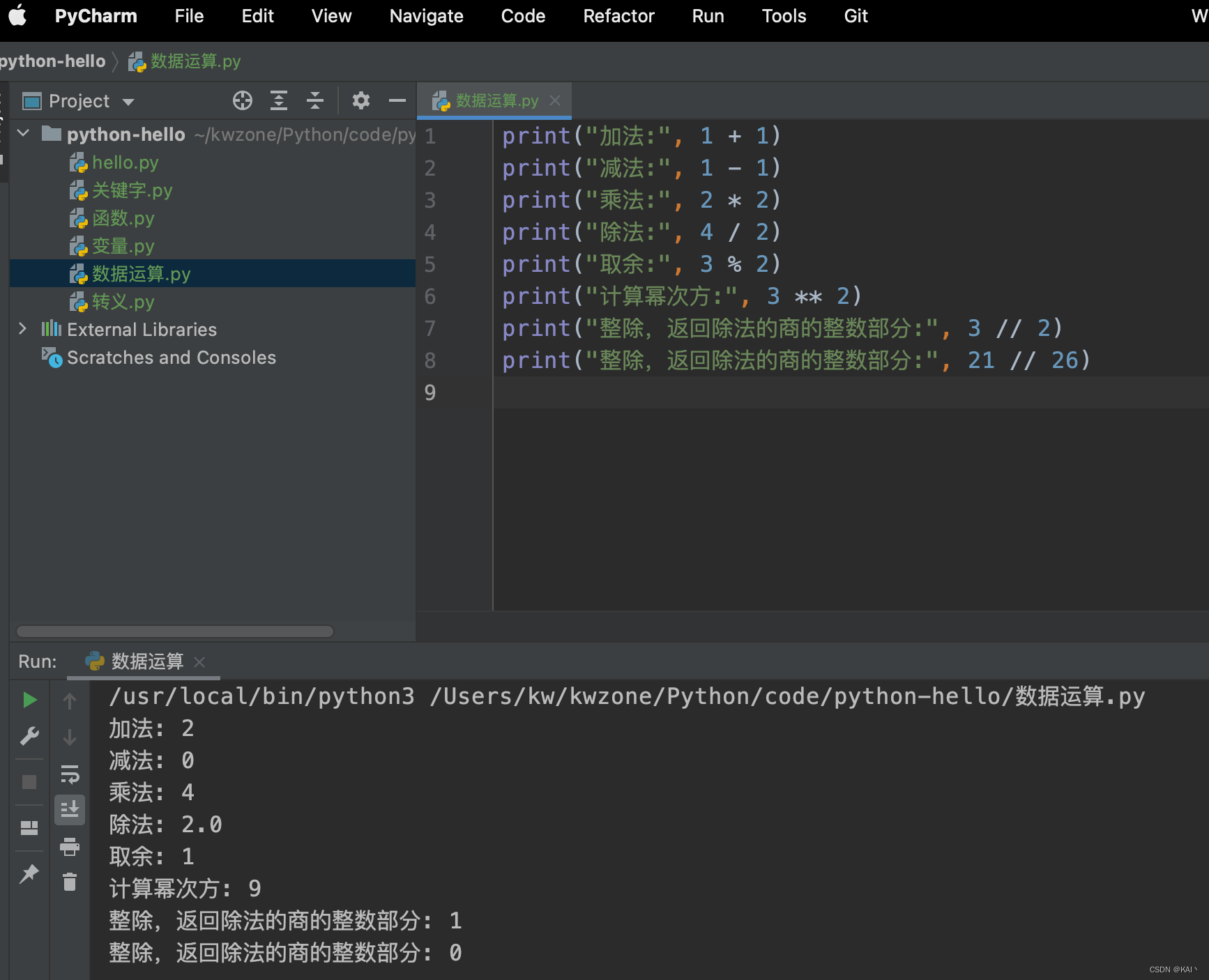
1. 算术运算符:
+加号:加法运算-减号:减法运算*乘号:乘法运算/除号:除法运算%取模运算符:返回除法的余数**幂运算符:计算幂次方//整除运算符:返回除法的商的整数部分
print("加法:", 1 + 1)
print("减法:", 1 - 1)
print("乘法:", 2 * 2)
print("除法:", 4 / 2)
print("取余:", 3 % 2)
print("计算幂次方:", 3 ** 2)
print("整除,返回除法的商的整数部分:", 3 // 2)
print("整除,返回除法的商的整数部分:", 21 // 26)
2. 比较运算符:
==等于!=不等于<小于>大于<=小于等于>=大于等于
3. 逻辑运算符:
and逻辑与or逻辑或not逻辑非
4. 位运算符:
&按位与|按位或^按位异或~按位取反<<左移位>>右移位
5. 赋值运算符:
=简单赋值运算符+=加法赋值运算符-=减法赋值运算符*=乘法赋值运算符/=除法赋值运算符%=取模赋值运算符**=幂赋值运算符//=整除赋值运算符
6. 成员运算符:
in如果在指定的序列中找到值返回 True,否则返回 False。not in如果在指定的序列中没有找到值返回 True,否则返回 False。
print("1" in "1234")
print(1 in [1, 2, 3, 4])
print(1 in (1, 2, 3))
print(1 in {1, 2, 3})
print(5 not in {1, 2, 3})
print("name" in {"name": "李白"})
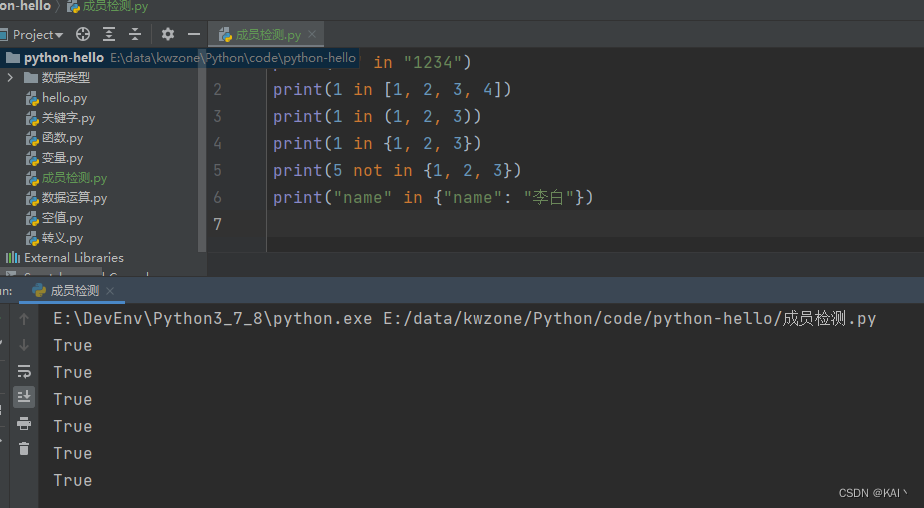
7. 身份运算符:
is判断两个标识符是不是引用同一个对象is not判断两个标识符是不是引用不同的对象
# 字符串对象相等判断,和java大概一致
a = "李白"
b = "杜甫"
c = a
d = "李白"
print(a is b) # False
print(a is c) # True
print(a == c) # True
print(a is not c) # False
print(a is d) # True
以上是Python中的常用运算符,可以用于计算、比较、逻辑操作、位操作、赋值等。
输入输出函数
print("hello")
input("请输入:")
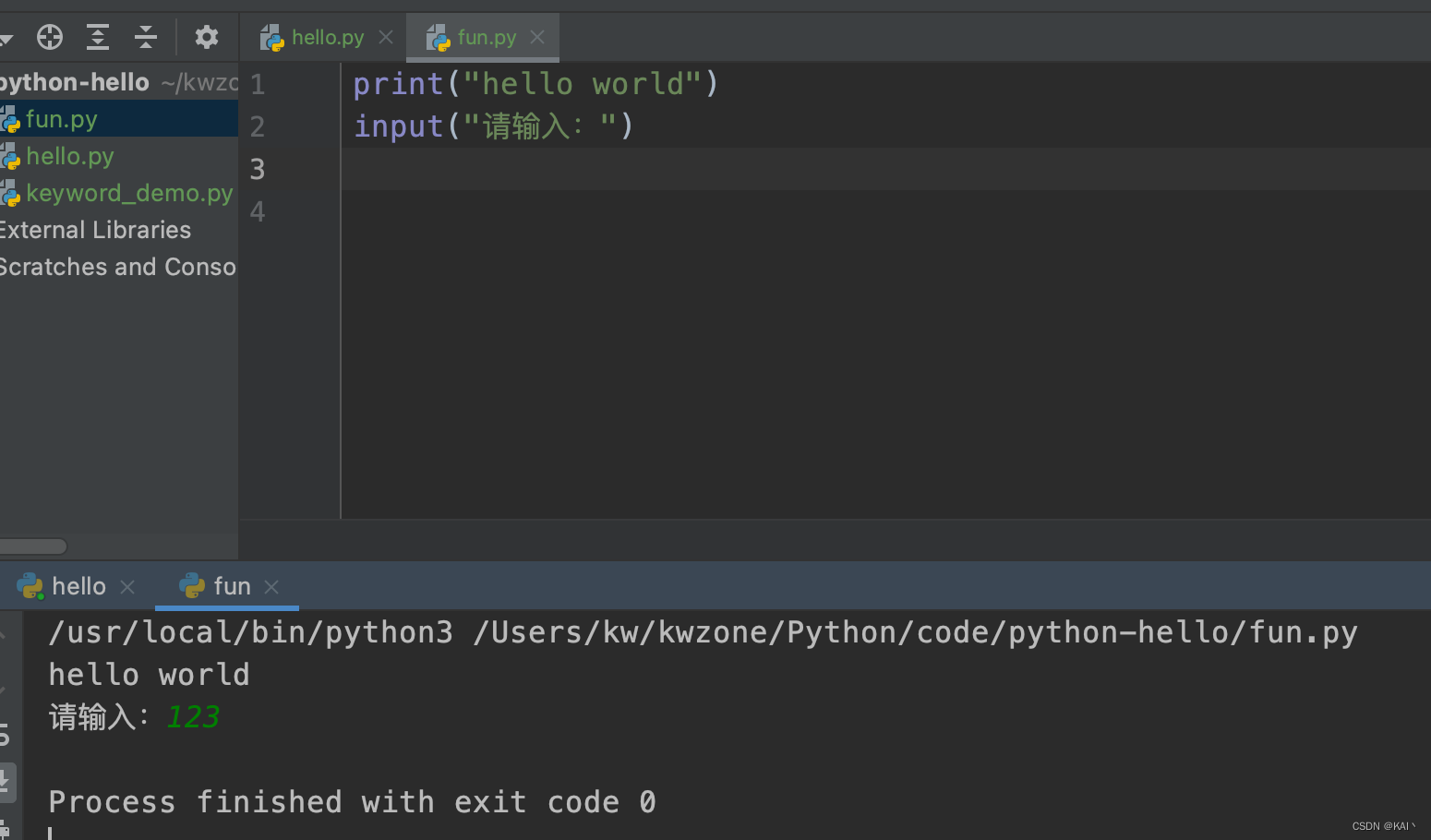
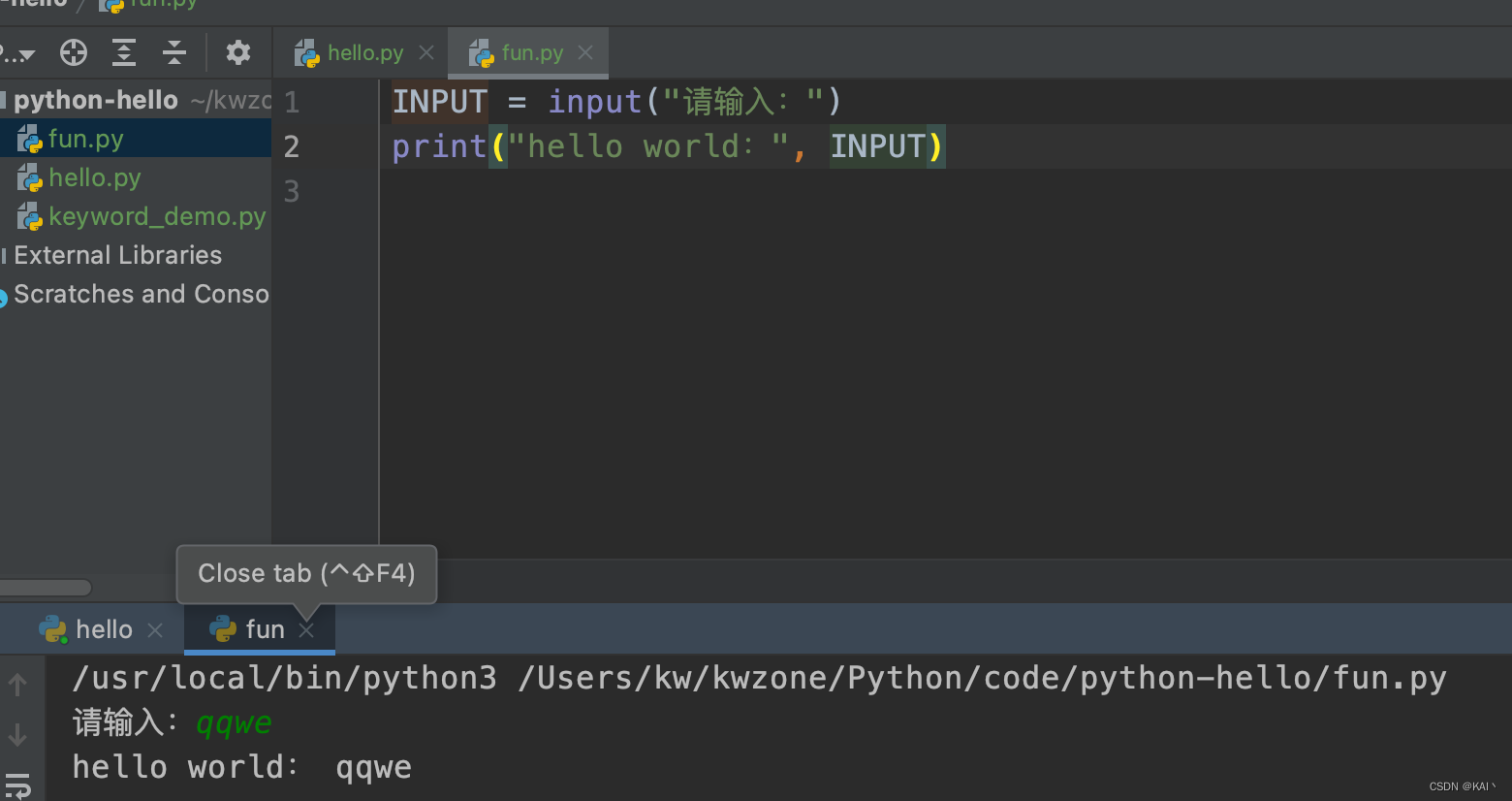
INPUT = input("请输入:")
print("hello world:", INPUT)
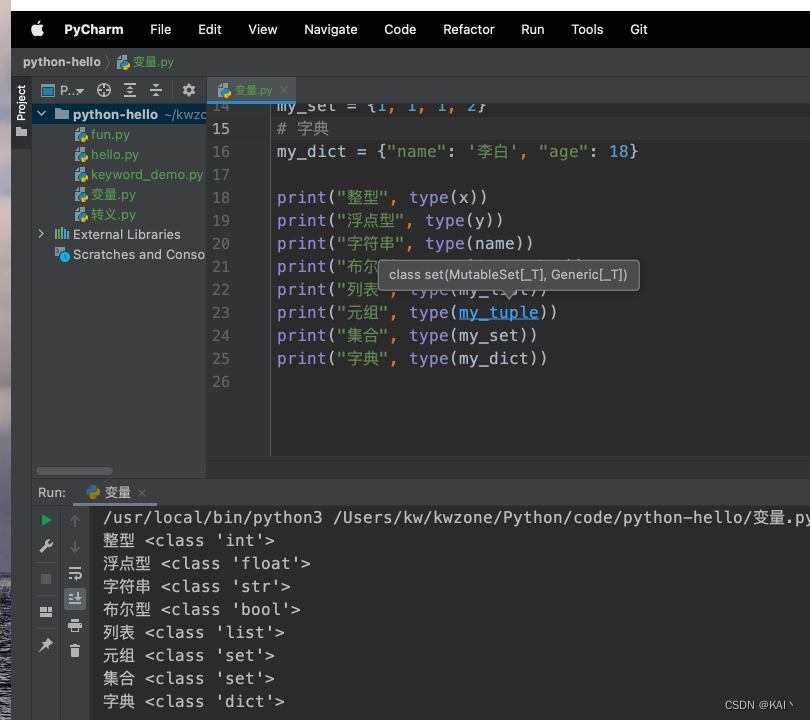
数据类型转换
查看变量的类型-type函数
# 整型
x = 5
# 浮点型
y = 99.99
# 字符串
name = "李白"
# 布尔型
is_active = True
# 列表
my_list = [1, 2, 3]
# 元组
my_tuple = {1, 2, 3}
# 集合
my_set = {1, 1, 1, 2}
# 字典
my_dict = {"name": '李白', "age": 18}
print("整型", type(x))
print("浮点型", type(y))
print("字符串", type(name))
print("布尔型", type(is_active))
print("列表", type(my_list))
print("元组", type(my_tuple))
print("集合", type(my_set))
print("字典", type(my_dict))
数据类型转换的方法
int()
将一个数值或字符串转换为整数。如果给定的参数无法转换为整数,则会抛出 ValueError 异常。
num_str = "123"
num_int = int(num_str)
print(num_int) # 输出:123
float()
将一个数值或字符串转换为浮点数。如果给定的参数无法转换为浮点数,则会抛出 ValueError 异常
num_str = "3.14"
num_float = float(num_str)
print(num_float) # 输出:3.14
str()
将一个对象转换为字符串。如果给定的参数无法转换为字符串,则会抛出 TypeError 异常。
num = 123
num_str = str(num)
print(num_str) # 输出:"123"
bool()
将一个对象转换为布尔值。
可以将数字、字符串、列表、元组、集合、字典等对象转换为布尔值。
如果对象为 0、空字符串、空列表、空元组、空集合、空字典等,则布尔值为 False;否则为 True。
num = 123
num_bool = bool(num)
print(num_bool) # 输出:True
empty_list = []
empty_bool = bool(empty_list)
print(empty_bool) # 输出:False
list()
将一个可迭代对象转换为列表。
可迭代对象包括列表、元组、集合、字符串、字典等。
num_tuple = (1, 2, 3)
num_list = list(num_tuple)
print(num_list) # 输出:[1, 2, 3]
str_dict = {'a': 'apple', 'b': 'banana'}
str_list = list(str_dict)
print(str_list) # 输出:['a', 'b']
tuple()
将一个可迭代对象转换为元组。
可迭代对象包括列表、元组、集合、字符串、字典等。
str_set = {'apple', 'banana', 'orange'}
str_tuple = tuple(str_set)
print(str_tuple) # 输出:('orange', 'banana', 'apple')
set()
将一个可迭代对象转换为集合。
可迭代对象包括列表、元组、集合、字符串、字典等
num_list = [1, 2, 3]
num_set = set(num_list)
print(num_set) # 输出:{1, 2, 3}
str_tuple = ('apple', 'banana', 'orange')
str_set = set(str_tuple)
print(str_set) # 输出:{'orange', 'banana', 'apple'}
dict()
将一个包含键值对的可迭代对象转换为字典。
可迭代对象包括列表、元组、集合、字典等。
如果可迭代对象中的元素不是一个包含两个元素的子序列,则会抛出 ValueError 异常。
num_list = [(1, 'one'), (2, 'two'), (3, 'three')]
num_dict = dict(num_list)
print(num_dict) # 输出:{1: 'one', 2: 'two', 3: 'three'}
str_tuple = [('a', 'apple'), ('b', 'banana'), ('o', 'orange')]
str_dict = dict(str_tuple)
print(str_dict) # 输出:{'a': 'apple', 'b': 'banana', 'o': 'orange'}
eval()
将一个字符串解析为 Python 表达式,并返回解析后的结果。
如果字符串不能被解析为 Python 表达式,则会抛出 SyntaxError 异常
num_str = "123"
num_int = eval(num_str)
print(num_int) # 输出:123
expr_str = "1 + 2 * 3"
expr_result = eval(expr_str)
print(expr_result) # 输出:7
isinstance函数
isinstance() 是 Python 内置的函数之一,用于判断一个对象是否属于某个指定的类或类型。其语法格式为
isinstance(object, classinfo)
#其中,object 表示要判断的对象,classinfo 表示要判断的类或类型。
#如果 object 是 classinfo 的实例,则返回 True,否则返回 False。
# 判断一个对象是否是整数类型
num = 123
if isinstance(num, int):
print("num is an integer")
else:
print("num is not an integer")
# 判断一个对象是否是字符串类型
strA = "hello"
if isinstance(strA, str):
print("str is a string")
else:
print("str is not a string")
# 判断一个对象是否是列表类型
lst = [1, 2, 3]
if isinstance(lst, list):
print("lst is a list")
else:
print("lst is not a list")
print(isinstance("李白", (int, str, float))) # True
流程控制语句
在 Python 中,流程控制语句主要包括三种:条件语句、循环语句和跳转语句。
条件语句if
print("---------------------单if语句---------------------")
if 1 > 0:
print("1>0")
print("---------------------if else语句---------------------")
b1 = 1 < 0
if b1:
print("1>0")
else:
print("1小于0")
print("---------------------if elif语句---------------------")
score = int(input("请输入你的成绩:"))
if score > 90:
print("你是一个优秀的学生")
elif score > 60:
print("你的成绩合格")
else:
print("你不及格")
循环语句
循环语句是通过多次执行相同或类似的代码来实现重复操作的结构。Python 中的循环语句主要有 for 和 while 两种。
- for 循环:用于遍历序列、列表、字典等可迭代对象中的元素。
- while 循环:用于重复执行一段代码,直到条件不成立。
在python中for while循环可以和else一起使用
for循环
listA = ["李白", "杜甫", "白居易"]
for item in listA:
print("for循环遍历:", item)
for index, item in enumerate(listA):
print("for循环遍历 listA[{}]".format(index), item)
else:
print("for循环遍历 listA结束")
while循环
n = 0
while n < 10:
n = n + 1
print("while循环:", n)
y = 0
while y < 10:
y = y + 1
print("while循环:", y)
else:
print("while循环结束")
跳转语句
跳转语句是用于改变程序执行顺序的语句,主要包括 break、continue 和 return 三种。
- break:用于跳出当前循环,不再执行循环中剩余的语句。
- continue:用于跳过当前循环中的某些语句,继续执行下一次循环。
- return:用于退出函数,并返回一个值。
listA = ["李白", "杜甫", "白居易"]
for item in listA:
if item == '李白':
print("for循环遍历:", item)
break
for index, item in enumerate(listA):
if item == '李白':
print("for循环遍历 listA[{}]".format(index), item)
continue
else:
print("for循环遍历 listA结束")
空语句pass
表示此行为空,不运行任何操作。
加了可以提高代码阅读性吧,python语言的代码可读性真的不习惯,容易看串行。。。
if 1 > 0:
pass
Python的函数
定义函数
定义函数的方式为使用关键字“def”加上函数名和参数列表,函数体代码必须缩进。
要调用函数,只需使用函数名和参数列表即可。
⚠️ 非编译型语言,要注意代码顺序,和java这种编译型语言不同。
def say():
print("say hello")
say()
def say(param):
print("函数的定义与调用", param)
say("hello world")
函数名的命名规范
在Python中,函数名的命名规范与变量名的命名规范相同,需要遵循以下规则:
- 函数名只能包含字母、数字和下划线,不能包含空格或其他特殊字符;
- 函数名不能以数字开头,只能以字母或下划线开头;
- 函数名应该简洁明了,能够准确描述函数的功能;
- 函数名一般使用小写字母,可以使用下划线分隔多个单词,如“calculate_salary”。
除了以上规则,还有一些约定俗成的规范,如:
- 以单个下划线开头的函数名被视为私有函数,不应该被直接调用;
- 函数名应该是动词或动词短语,例如“calculate_salary”、“print_report”等;
- 如果函数名包含多个单词,使用下划线分隔,而不是驼峰式命名,例如“calculate_salary”而不是“calculateSalary”。
遵循这些命名规范可以使代码更易于理解、维护和共享。
函数参数
函数可以有多个参数,包括必需参数、默认参数和可变参数。
必须参数
必需参数是必须传递给函数的参数,如果不传递,则会引发错误。
def say(param):
print("函数的定义与调用", param)
say("hello world")

默认参数
默认参数是在定义函数时就已经指定的参数,如果在调用函数时没有传递该参数,则函数将使用默认值。
def say_hello(param="hello"):
print("默认参数:", param)
say_hello()
参数为列表的情况
def update_list(param, listA=[]):
listA.append(param)
print(listA)
update_list(100) # [100]
update_list(200) # [100, 200]
# 上面输出的内容,不是我们想要的结果
def update_list(param, listA=None):
if listA is None:
listA = []
listA.append(param)
print(listA)
update_list(100) # [100]
update_list(200) # [200]
函数调用时的关键字参数
关键字参数,函数调用时,指定参数名称(⚠️ 别和函数定义中的默认参数混淆)
函数的普通参数即必须参数,必须在默认参数的前面。否则会报错
def sum_num(x, a=100, b=200):
print("a=", a, "b=", b)
print("计算", a + b)
sum_num(100, b=11, a=22)
例:

限定关键字传参
* 代表占位,* 之后的参数,在函数调用时,必须使用关键字传参,否则执行报错
def sum_num3(a, *, b, c):
print(a)
print(b)
print(c)
sum_num3(100, b=200, c=300) # b c必须使用关键字传参
可变参数
在Python中,函数的可变参数指的是函数定义时不确定需要传入多少个参数,
这些参数被封装为一个元组或列表作为函数的一个参数。
Python中的可变参数有两种方式:*args和**kwargs。
*args
在函数定义时,使用*args表示可变参数,这个参数接收一个元组,其中包含所有传入的参数。
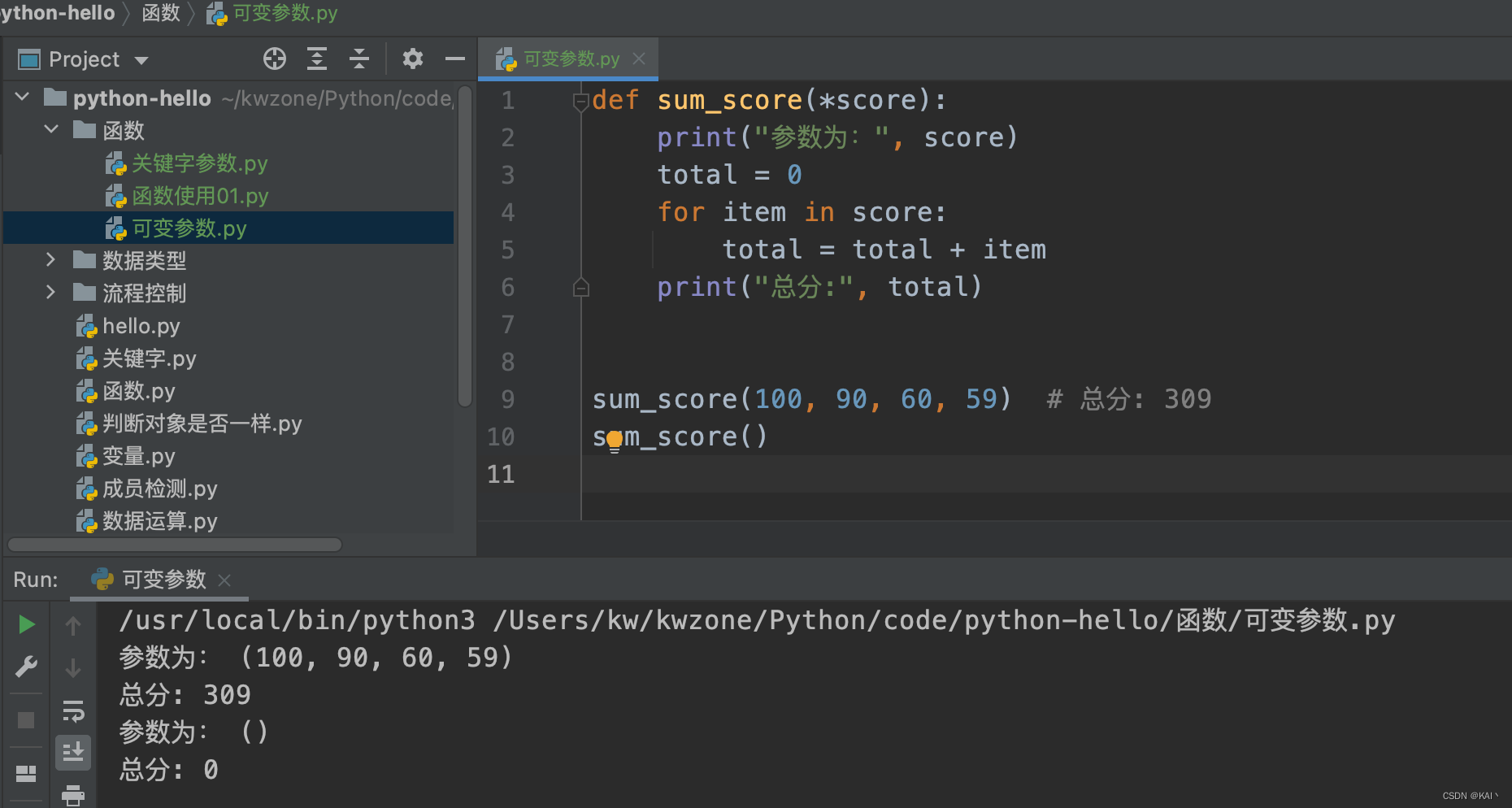
def sum_score(*score):
print("参数为:", score)
total = 0
for item in score:
total = total + item
print("总分:", total)
sum_score(100, 90, 60, 59) # 总分: 309
sum_score()
**kwargs
在函数定义时,使用**kwargs表示可变关键字参数,这个参数接收一个字典,其中包含所有传入的关键字参数。
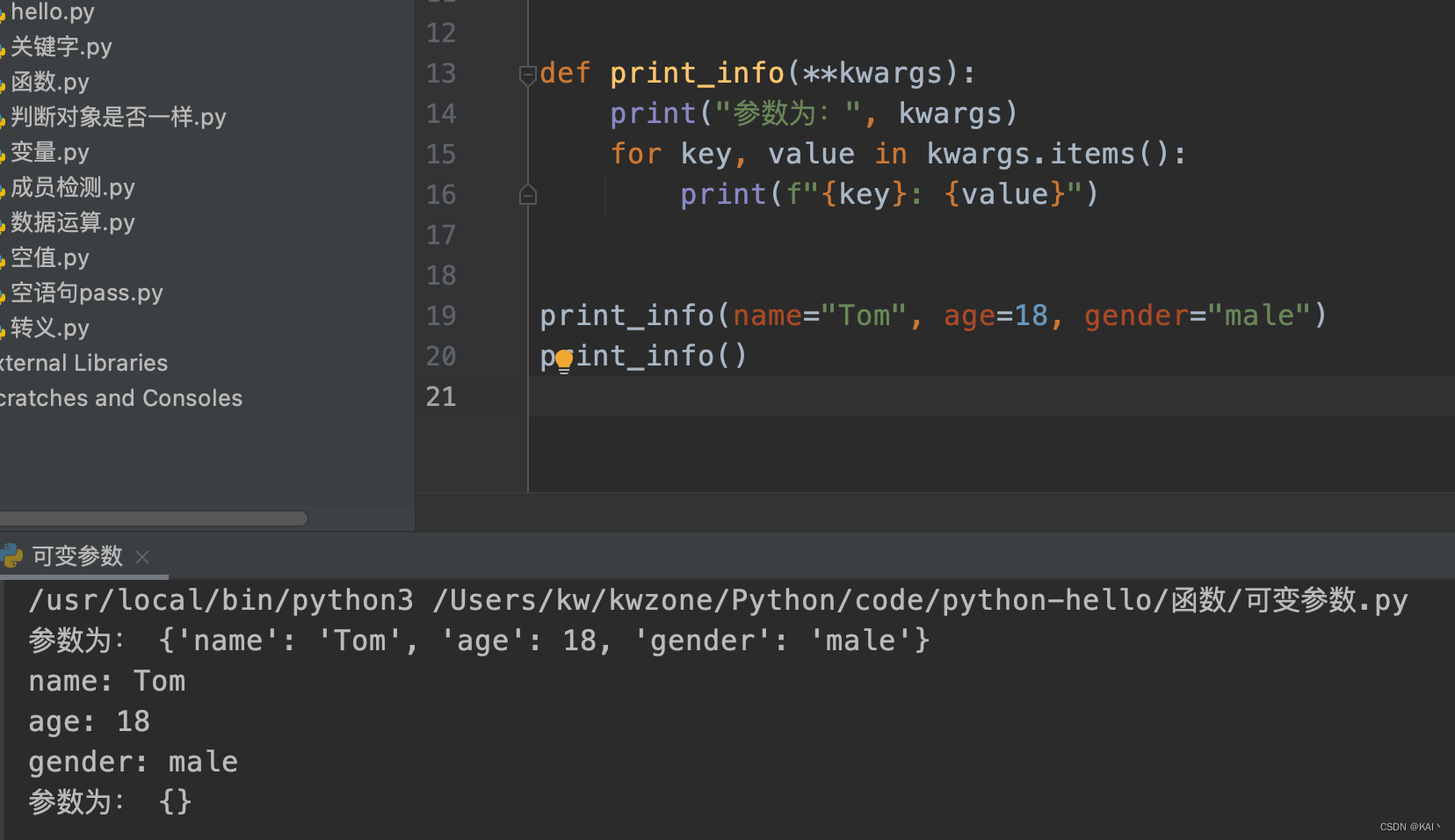
def print_info(**kwargs):
print("参数为:", kwargs)
for key, value in kwargs.items():
print(f"{key}: {value}")
print_info(name="Tom", age=18, gender="male")
print_info()
参数解包
Python中,我们可以使用*和**操作符来对参数进行解包。
这样可以将列表、元组、字典等数据结构中的元素分别传入函数中作为单独的参数,
或者将多个参数打包成一个列表、元组或字典。
⚠️ 解包后的参数数量要和函数定义的参数数量一致,否则运行报错
*操作符的参数解包
当我们使用*操作符对一个列表、元组或集合进行解包时,它会将其中的每个元素作为单独的参数传递给函数。
def print_info(name, age, city):
print(f"Name: {name}")
print(f"Age: {age}")
print(f"City: {city}")
info_list = ["Tom", 18, "Beijing"]
print_info(*info_list)
print_info(*"123")
**操作符的参数解包
当我们使用**操作符对一个字典进行解包时,它会将其中的每个键值对作为关键字参数传递给函数。
def print_info2(name, age, city):
print(f"Name: {name}")
print(f"Age: {age}")
print(f"City: {city}")
info_dict = {"name": "Tom", "age": 18, "city": "Beijing"}
print_info2(**info_dict)
参数解包与可变参数
def abc(*args):
print("参数:", args)
pass
abc(*["a", "李白"]) # ('a', '李白')
参数定义的顺序
def sort_param(a, b=100, *args, **kwargs):
print("a=", a)
print("b=", b)
print("args=", args)
print("kwargs=", kwargs)
pass
sort_param(11, 1, 2, 3, name="李白", age=18)
函数返回值
函数可以返回一个值,使用关键字“return”即可。
def sum_score(*args):
total = 0
for item in args:
total = total + item
return total
SCORE = sum_score(100, 90, 60)
print("计算总分:", SCORE)
def abc(*args):
total = 0
for item in args:
total = total + item
print("计算总分:", total)
print("函数的返回值:", abc(100, 90, 60))
函数返回函数
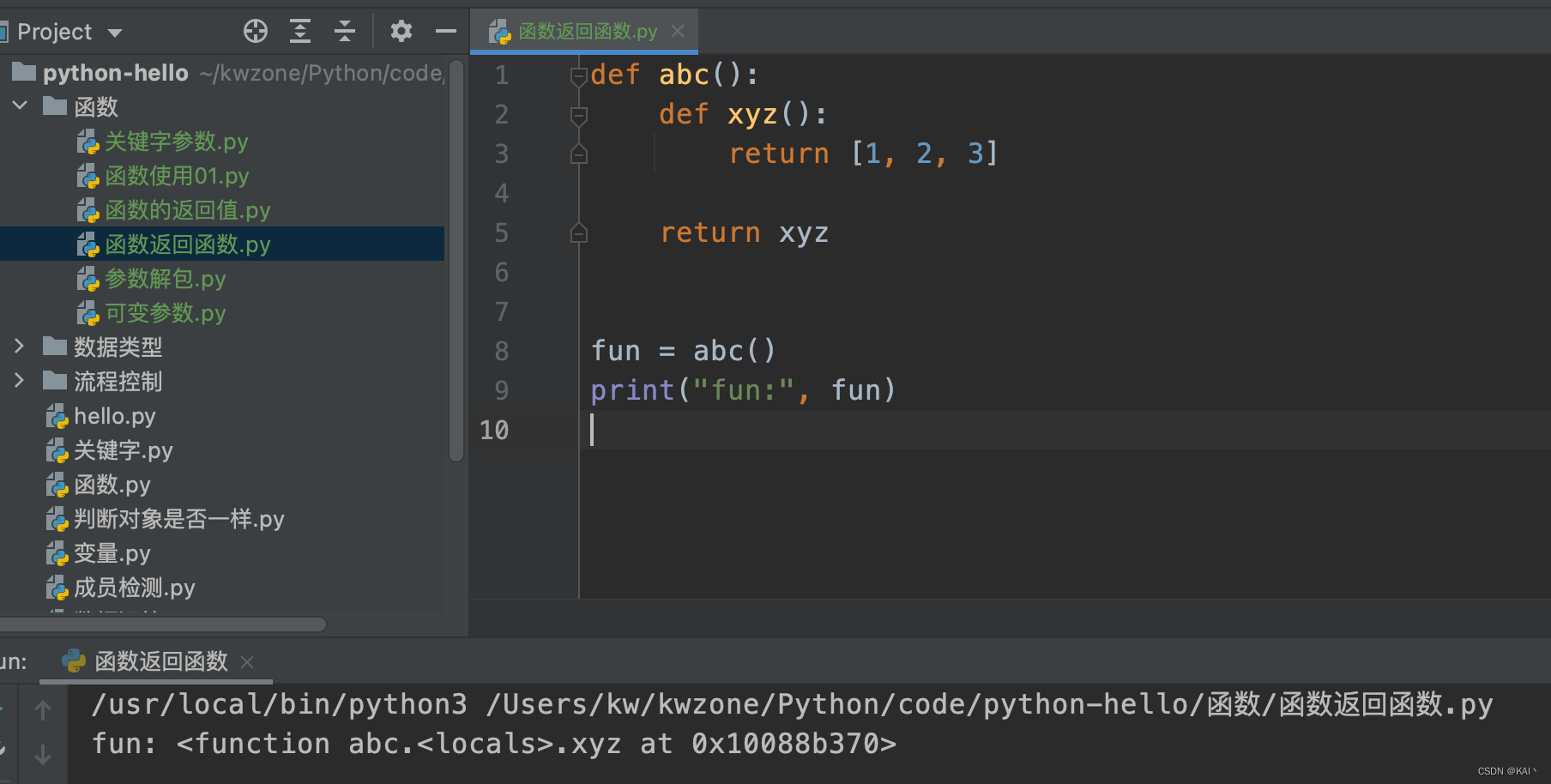
def abc():
def xyz():
return [1, 2, 3]
return xyz
fun = abc()
print("fun:", fun)
print("函数中的函数:", fun()) # [1, 2, 3]
lambda函数
lambda函数是一种匿名函数,可以用于快速定义简单的函数。
全局变量与局部变量
在函数中定义的变量都是局部变量,它们只在函数内部有效。
如果需要在函数外部使用变量,则需要在函数外部定义该变量,并使用关键字“global”指定该变量为全局变量。
# abc均为局部变量
def fun(a, b):
c = a + b
print(c)
pass
fun(1, 2)
name = '李白'
print(name)
def fun2():
print(name)
pass
fun2()
def fun3():
global age
age = 18
print(age)
fun3()
print(age)
递归函数
# 计算阶乘
def fac(n):
if n == 1:
return 1
else:
return n * fac(n - 1)
pass
print(fac(3))
# 斐波那契数列
# 1 1 2 3 5 8 11 19
def fib(n):
if n == 1:
return 1
elif n == 2:
return 1
else:
return fib(n - 1) + fib(n - 2)
print(fib(6))
异常处理
基本使用
和java try catch类似
try except…except…except…
try:
a = 1 / 0
print(a)
except ZeroDivisionError:
print("计算公式错误")
except BaseException:
print("异常处理")
try except…else
try:
a = 1 / 1
print(a)
except BaseException as e:
print("异常处理", e)
else:
print("计算结果为", a)
try except else finally
try:
a = 1 / 1
print(a)
except BaseException as e:
print("异常处理", e)
else:
print("计算结果为", a)
finally:
print("总会执行的代码")
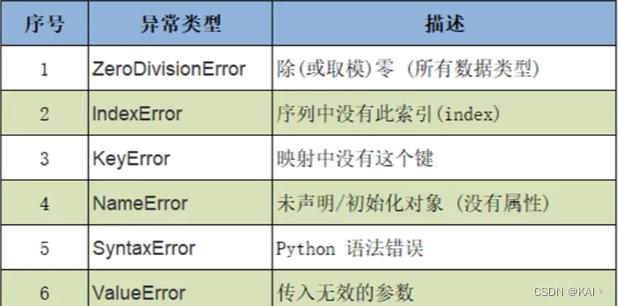
常见的异常类型
traceback
import traceback
try:
a = 1 / 0
print(a)
except:
traceback.print_exc()