学习基于如下书籍,仅供自己学习,用来记录回顾,非教程。
<PyTorch深度学习和图神经网络(卷 1)——基础知识>一书配套代码:
https://github.com/aianaconda/pytorch-GNN-1st
百度网盘链接:https://pan.baidu.com/s/1WjggntFWod0CQh6_y77l4w
提取码:jqtq
压缩包密码:dszn
该章为实例,不做具体分析,只叙述大致流程。
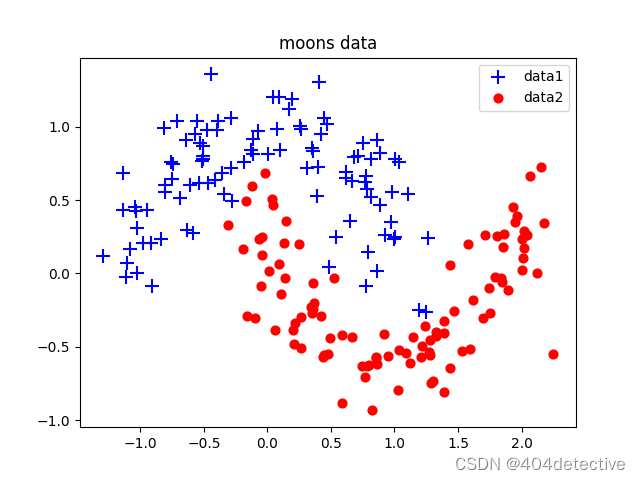
先利用sklearn生成如下数据集。我将随机种子设置为404
然后开始搭建网络,该网络模型共三层,输入、隐藏、输出。第一层为两个输入,即为点的横纵坐标,第二层为任意设置的神经元个数用来拟合,第三层为2个输出,即为两种类别。
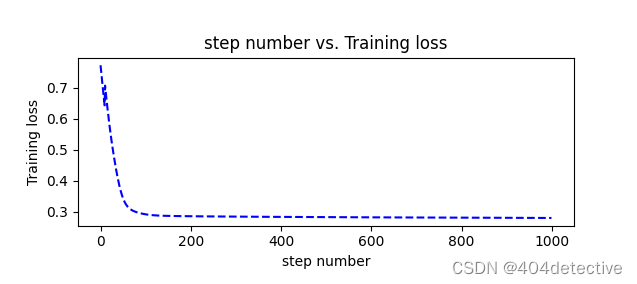
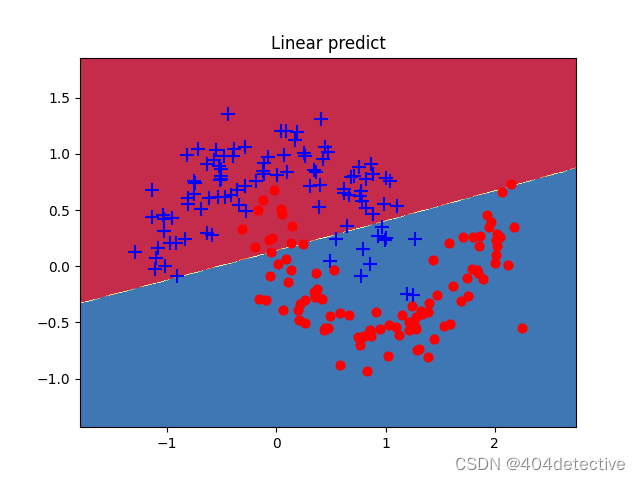
第一次训练便出现了欠拟合的问题,进入了局部最优解,由于隐藏层只有3个神经元,将其改为5便得到了很好的拟合。
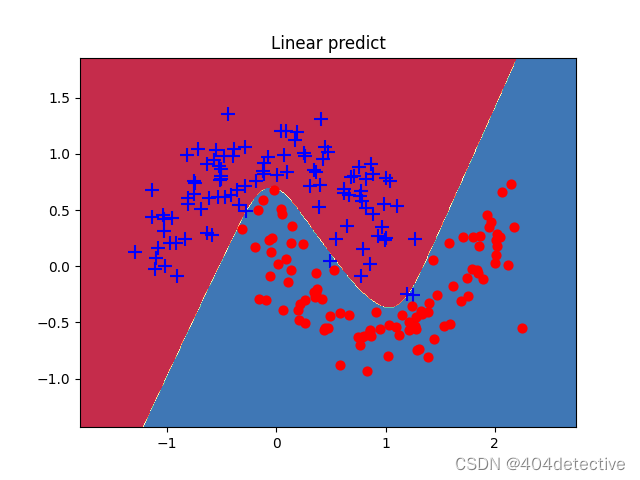
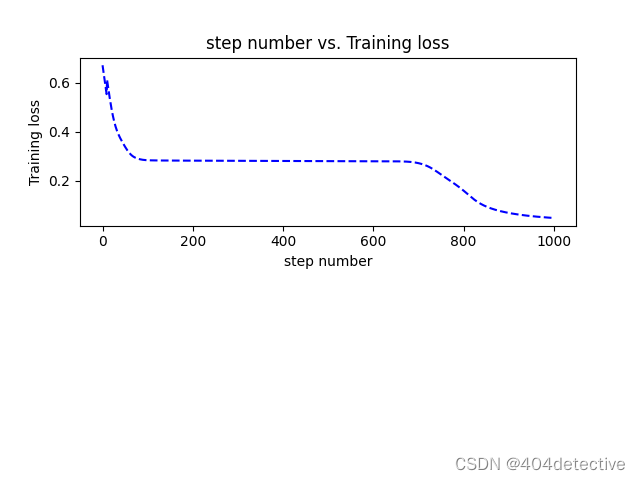
但是其第200到600轮损失很高,明显陷入局部最优,让我们看看200轮是什么效果。
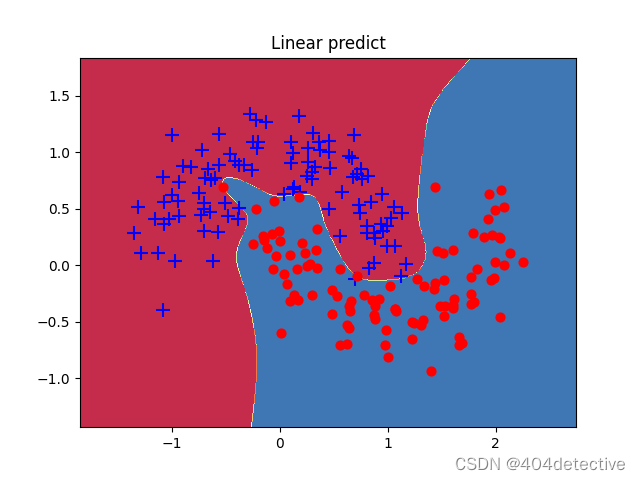
果然模型欠拟合,增加更多的隐藏层的神经元试试。下图为10个的loss图像,在200轮后,新增加的神经元发挥了作用,能够继续拟合。得到了不错的效果。
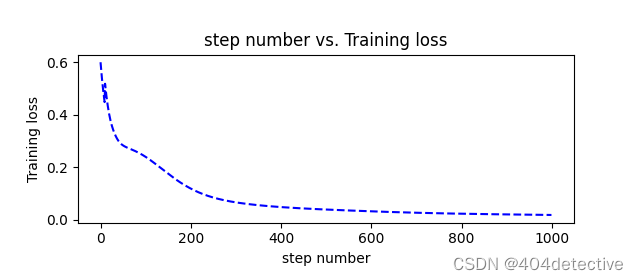
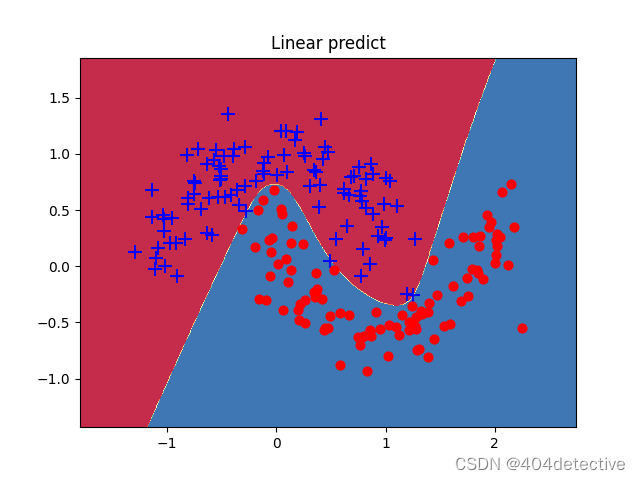
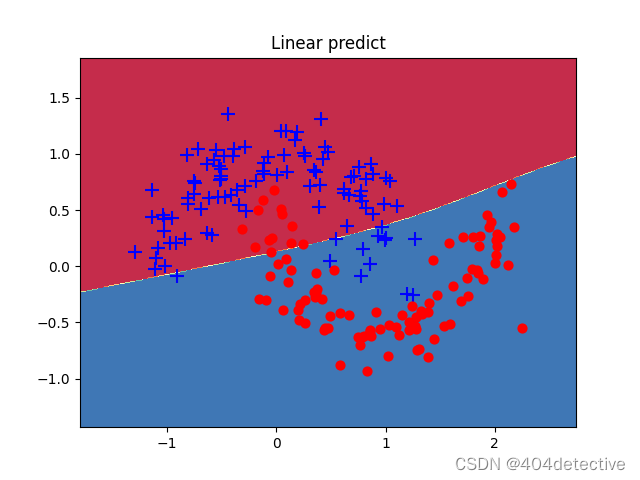
此图为随机种子为0时,隐藏层神经元个数为100时的有些过拟合的效果图。
具体代码分析
利用sklearn.datasets中的make_moons函数生成两组半月数据,并加入0.2的噪声。
X为有两个元素的列表,表示横纵坐标。
Y为该坐标对应的标签类别。
np.random.seed(404) #设置随机数种子
X, Y = sklearn.datasets.make_moons(200,noise=0.4) #生成2组半圆形数据
然后分别获取类别0和1对应的索引,这样X[arg,0],X[arg,1]则为Y对应索引的X的横纵坐标。
arg = np.squeeze(np.argwhere(Y==0),axis = 1) #获取第1组数据索引
arg2 = np.squeeze(np.argwhere(Y==1),axis = 1) #获取第2组数据索引
用matplotlib.pyplot绘制出来
plt.title("moons data")
plt.scatter(X[arg,0], X[arg,1], s=100,c='b',marker='+',label='data1')
plt.scatter(X[arg2,0], X[arg2,1],s=40, c='r',marker='o',label='data2')
plt.legend() #显示类别的label
plt.show()
定义网络模型。共三层,输入、隐藏、输出层。都为线性层。forward完后输出x作为预测值,输入进predict和getloss
class LogicNet(nn.Module):
def __init__(self,inputdim,hiddendim,outputdim):#初始化网络结构
super(LogicNet,self).__init__()
self.Linear1 = nn.Linear(inputdim,hiddendim) #定义全连接层
self.Linear2 = nn.Linear(hiddendim,outputdim)#定义全连接层
self.criterion = nn.CrossEntropyLoss() #定义交叉熵函数
def forward(self,x): #搭建用两层全连接组成的网络模型
x = self.Linear1(x)#将输入数据传入第1层
x = torch.tanh(x)#对第一层的结果进行非线性变换
x = self.Linear2(x)#再将数据传入第2层
# print("LogicNet")
return x
def predict(self,x):#实现LogicNet类的预测接口
#调用自身网络模型,并对结果进行softmax处理,分别得出预测数据属于每一类的概率
pred = torch.softmax(self.forward(x),dim=1)
return torch.argmax(pred,dim=1) #返回每组预测概率中最大的索引
def getloss(self,x,y): #实现LogicNet类的损失值计算接口
y_pred = self.forward(x)
loss = self.criterion(y_pred,y)#计算损失值得交叉熵
return loss
定义网络模型
model = LogicNet(inputdim=2,hiddendim=10,outputdim=2)#初始化模型
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)#定义优化器
模型训练
xt = torch.from_numpy(X).type(torch.FloatTensor)#将Numpy数据转化为张量
yt = torch.from_numpy(Y).type(torch.LongTensor)
epochs = 1000 #定义迭代次数
losses = [] #定义列表,用于接收每一步的损失值
for i in range(epochs):
loss = model.getloss(xt,yt)
losses.append(loss.item())
optimizer.zero_grad()#清空之前的梯度
loss.backward()#反向传播损失值
optimizer.step()#更新参数
plot_losses(losses)
可视化训练结果,定义如下函数
def moving_average(a, w=10):#定义函数计算移动平均损失值
if len(a) < w:
return a[:]
return [val if idx < w else sum(a[(idx-w):idx])/w for idx, val in enumerate(a)]
def plot_losses(losses):
avgloss= moving_average(losses) #获得损失值的移动平均值
plt.figure(1)
plt.subplot(211)
plt.plot(range(len(avgloss)), avgloss, 'b--')
plt.xlabel('step number')
plt.ylabel('Training loss')
plt.title('step number vs. Training loss')
plt.show()
使用及评估模型
计算准确率accuracy
from sklearn.metrics import accuracy_score
print(accuracy_score(model.predict(xt),yt))
可视化模型
数据为二维数组,可以在直角坐标系中进行可视化。
定义函数plot_decision_boundary()
def predict(model,x): #封装支持Numpy的预测接口
x = torch.from_numpy(x).type(torch.FloatTensor)
ans = model.predict(x)
return ans.numpy()
def plot_decision_boundary(pred_func,X,Y):#在直角坐标系中可视化模型能力
#计算取值范围
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
h = 0.01
#在坐标系中采用数据,生成网格矩阵,用于输入模型
xx,yy=np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
#将数据输入并进行预测
Z = pred_func(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
#将预测的结果可视化
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
plt.title("Linear predict")
arg = np.squeeze(np.argwhere(Y==0),axis = 1)
arg2 = np.squeeze(np.argwhere(Y==1),axis = 1)
plt.scatter(X[arg,0], X[arg,1], s=100,c='b',marker='+')
plt.scatter(X[arg2,0], X[arg2,1],s=40, c='r',marker='o')
plt.show()
plot_decision_boundary(lambda x : predict(model,x) ,xt.numpy(), yt.numpy())