梯度下降算法和最小二乘法都是用于求解线性回归问题中参数的优化方法。我们可以通过一个简单的例子来说明它们之间的区别。
假设我们有以下数据点:(1, 2),(2, 3),(3, 4),(4, 5),我们希望找到一条最佳拟合线 y = wx + b,使得预测值与真实值之间的误差最小。
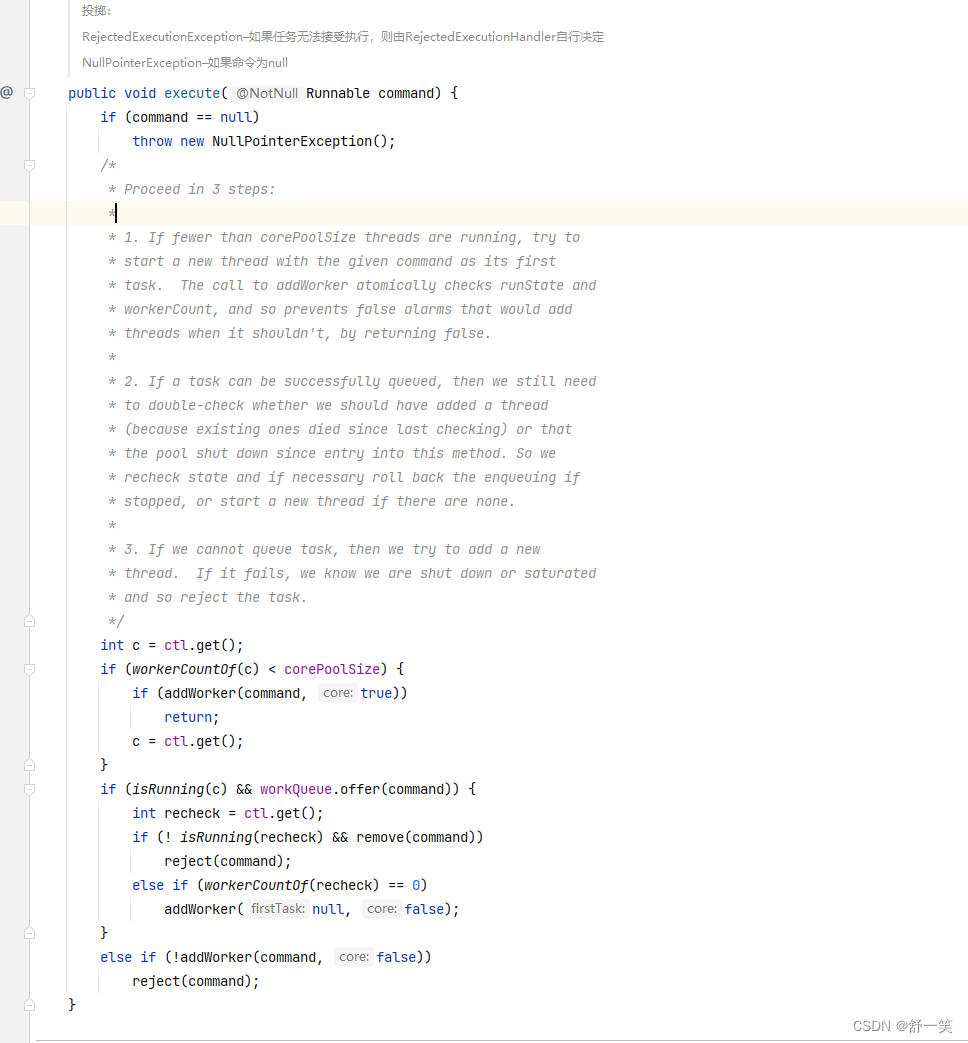
首先定义一个损失函数(均方误差):
L(w, b) = 1/n * Σ(yi - (wxi + b))^2
我们的目标是找到 w 和 b 的值,使得损失函数 L(w, b) 最小。
使用最小二乘法进行求解
最小二乘法通过求解损失函数的导数等于0的条件,直接得到最优解。对 w 和 b 分别求导,得到以下方程组:
∂L/∂w = 0
∂L/∂b = 0
通过求解这个方程组,可以得到 w 和 b 的最优解。在这个例子中,最小二乘法会给出 w = 1,b = 1 的解。
使用梯度下降算法进行求解
梯度下降算法是一种迭代方法,通过不断地更新 w 和 b 的值,使损失函数逐步减小。在每一步迭代中,我们分别计算损失函数关于 w 和 b 的梯度,并按照一定的学习率更新 w 和 b 的值。
初始时,我们可以随机设置 w 和 b 的值,例如 w = 0,b = 0。然后进行以下迭代过程:
计算损失函数关于 w 和 b 的梯度
按照学习率更新 w 和 b 的值
在每一步迭代中,我们都按照以下公式更新 w 和 b:
w = w - α * ∂L/∂w
b = b - α * ∂L/∂b
其中,α 是学习率,控制每次更新的幅度。通过多次迭代,梯度下降算法会逐步接近最优解。
总结:
最小二乘法通过解析方法直接求解最优解,计算简单,但对于大规模数据或者非线性问题,求解过程可能会非常复杂。
梯度下降算法通过迭代方法逐步接近最优解,适用于大规模数据和非线性问题,但需要调整学习率和设置合适的迭代次数,收敛速度可能较慢。