常见的进制
- 10 进制:除表示正负的符号外,以
1~9开头,由0~9组成。如128,+234,-278。 - 2 进制:以
0b开头,0b11 - 8 进制:以
0或0o开头,由0~7组成的数。如0126,050000,0o666. - 16 进制:以
0X或0x开头,由0~9,A~F或a~f组成。如0x12A,0x5a000。
进制的互相转换:js 中提供了相互转换的方法。
编码过程中都是以字节为单位,一个字节是由 8 个 bit 位(二进制)构成,常见的一个字节组成一个字符,双字节组成汉字(gbk),三个字节组成一个汉字(utf8)
转换规则:
- 把任意进制转换成 10 进制,需要用当前所在的值
*当前进制的^第几位
let sum = 0;
for(let i = 0; i < 8; i++) {
sum += Math.pow(2, i)
}
console.log(sum); // 255
- 把 10 进制转换成任意进制可以采用取余的方法
将任意进制转换成 10 进制
parseInt(string, radix)解析一个字符串并返回指定基数的十进制整数,radix 是 2-36 之间的整数,表示被解析字符串的基数。
console.log(parseInt('11', 2)); // 3
将任意进制转成任意进制
Number.prototype.toString()
Number对象覆盖了Object对象上的toString()方法,它不是继承的Object.prototype.toString()。对于Number对象,toString()方法以指定的基数返回该对象的字符串表示。进行数字到字符串的转换时,建议用小括号将要转换的目标括起来,防止出错。
console.log((0x16).toString(2)); // 10110
node 中编码
在 node 中需要进行文件读取,node 中操作的内容默认会存在内存中,内存中的表现形式肯定是二进制的,二进制转换成 16 进制来展现
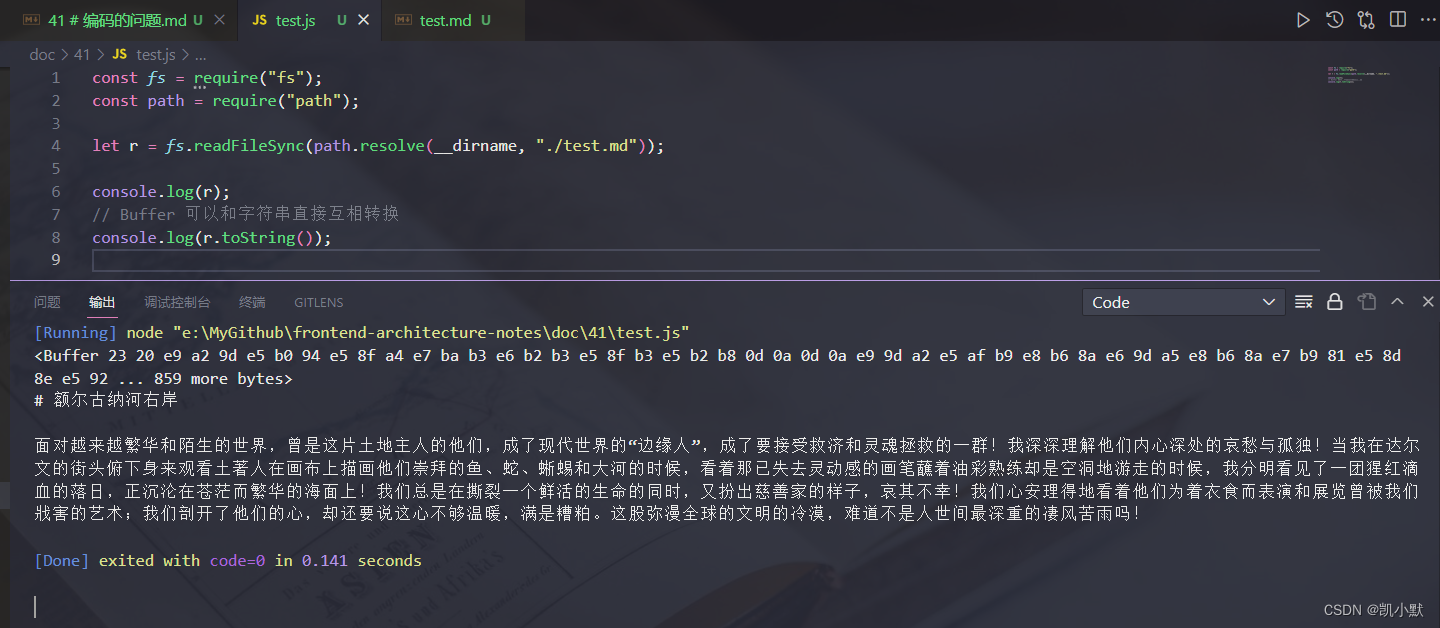
const fs = require("fs");
const path = require("path");
let r = fs.readFileSync(path.resolve(__dirname, "./test.md"));
console.log(r);
// Buffer 可以和字符串直接互相转换
console.log(r.toString());
编码的发展史
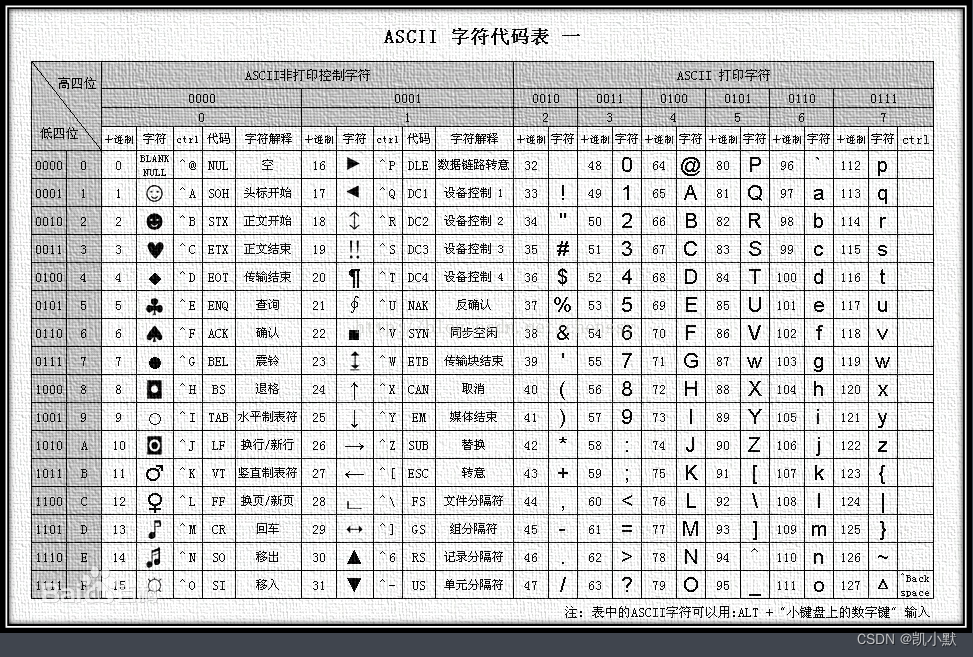
- ASCII 编码:一共定义了128个字符的编码规则,一些常用的符号和字母,进行了一个排号,最大编码就是 127(第一位为空),只会占用一个字节大小。
- GB2312:1980 年,中国发布了第一个汉字编码标准,收录了 6763 个常用的汉字和字符,汉字用两个字节,(255 * 255)
- GBK:1995 年发布,由于有些汉字是在 GB2312 标准发布之后才简化的,还有一些人名、繁体字、日语和朝鲜语中的汉字也没有包括在内,所以,在 GB2312 的基础上添加了这部分字符,就形成了 GBK ,全称 《汉字内码扩展规范》,共收录了两万多个汉字和字符,它完全兼容 GB2312
- GB18030:全称《信息技术中文编码字符集》收录七万多个汉字和字符, 它在 GBK 的基础上增加了中日韩语中的汉字 和 少数名族的文字及字符,完全兼容 GB2312,基本兼容 GBK
- Unicode:国际标准字符集,它将世界各种语言的每个字符定义一个唯一的编码,以满足跨语言、跨平台的文本信息转换,可以容纳一百多万个字符
- UTF8:(在 utf8 中,一个字符占用一个字节,一个汉字占用三个字节)
编码转换
gbk、utf8 是可以相互转化的,可以使用 iconv-lite
var iconv = require('iconv-lite');
// Convert from an encoded buffer to a js string.
str = iconv.decode(Buffer.from([0x68, 0x65, 0x6c, 0x6c, 0x6f]), 'win1251');
// Convert from a js string to an encoded buffer.
buf = iconv.encode("Sample input string", 'win1251');
// Check if encoding is supported
iconv.encodingExists("us-ascii")
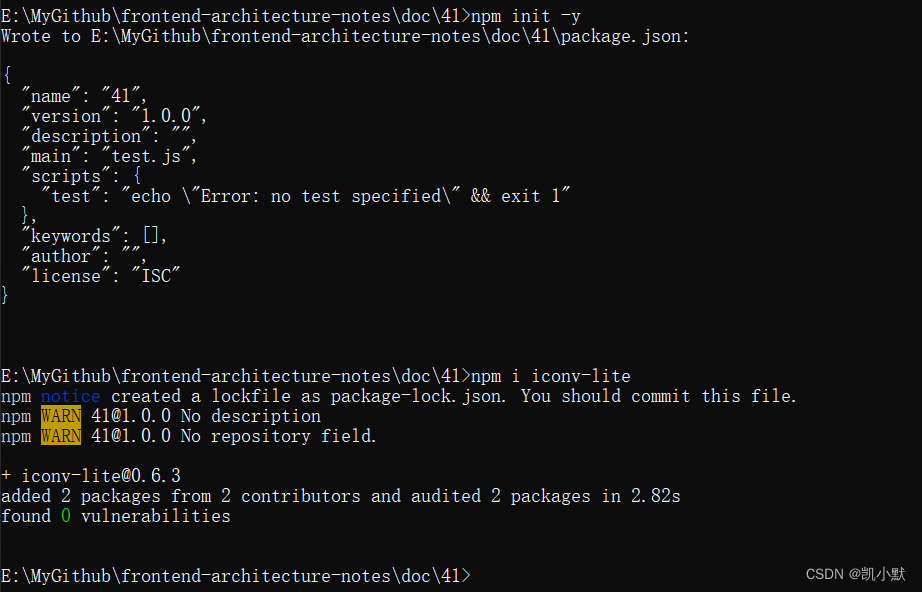
先安装依赖:
npm init -y
npm i iconv-lite
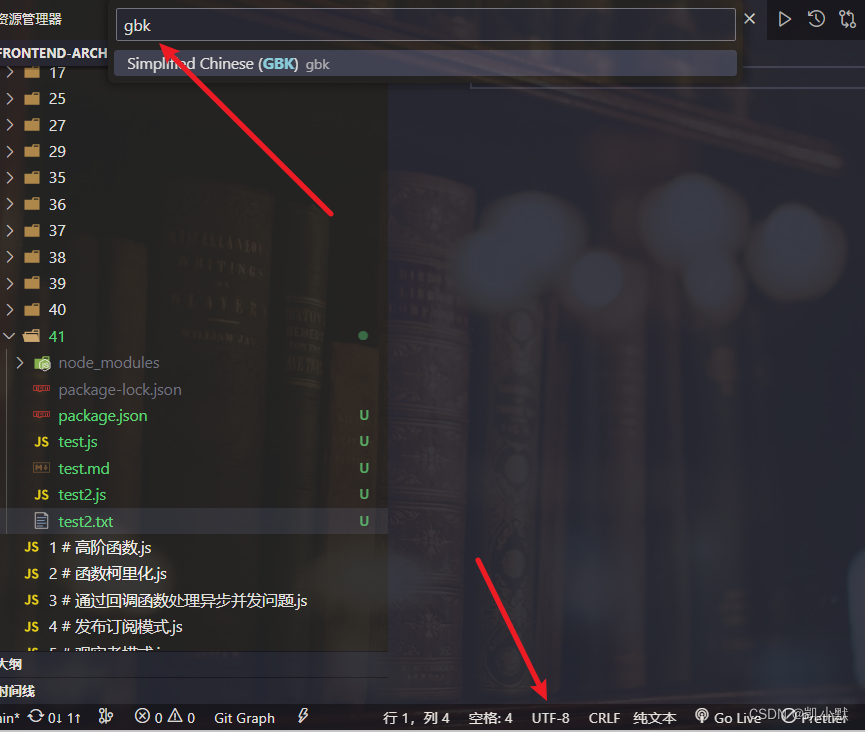
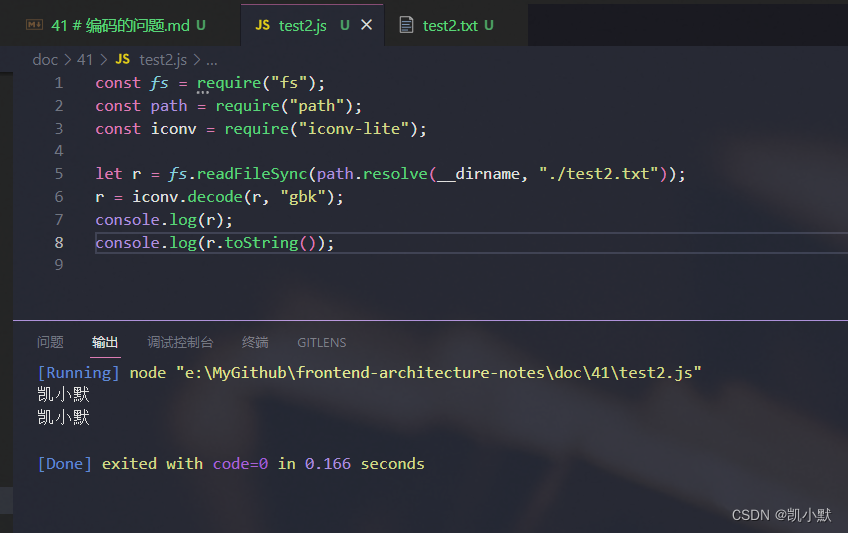
然后新建文件 test2.txt,里面添加文本 凯小默,然后使用 gbk 编码形式保存。
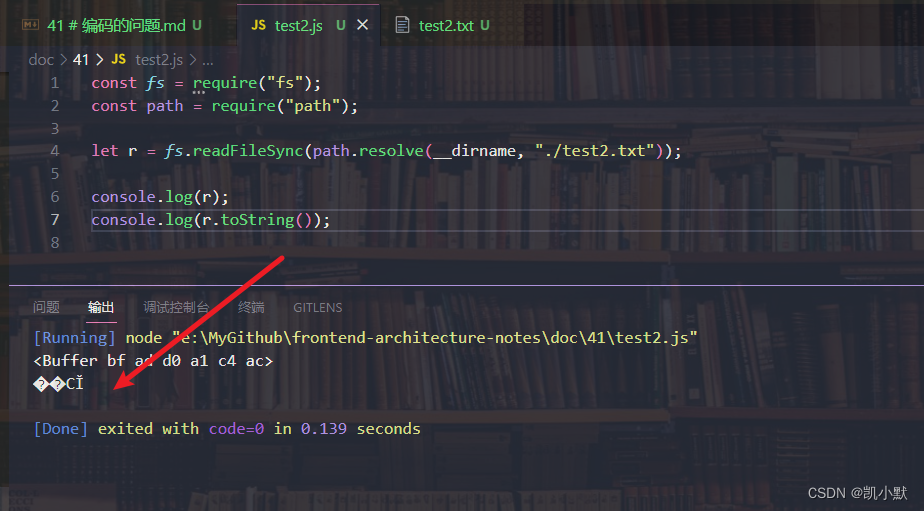
再添加 test2.js,添加读取文本代码,可以看到是乱码的
const fs = require("fs");
const path = require("path");
let r = fs.readFileSync(path.resolve(__dirname, "./test2.txt"));
console.log(r);
console.log(r.toString());
下面添加编码转换:
const fs = require("fs");
const path = require("path");
const iconv = require("iconv-lite");
let r = fs.readFileSync(path.resolve(__dirname, "./test2.txt"));
r = iconv.decode(r, "gbk");
console.log(r);
console.log(r.toString());
base64
base64 没有加密功能(只是编码转换)
好处:
- 可以传输数据,不乱码,减少 http 请求(不是所有的图片都转成 base64,体积会变大1/3)
其实就是将 3 * 8 的规则改成了 4 * 6 的方式
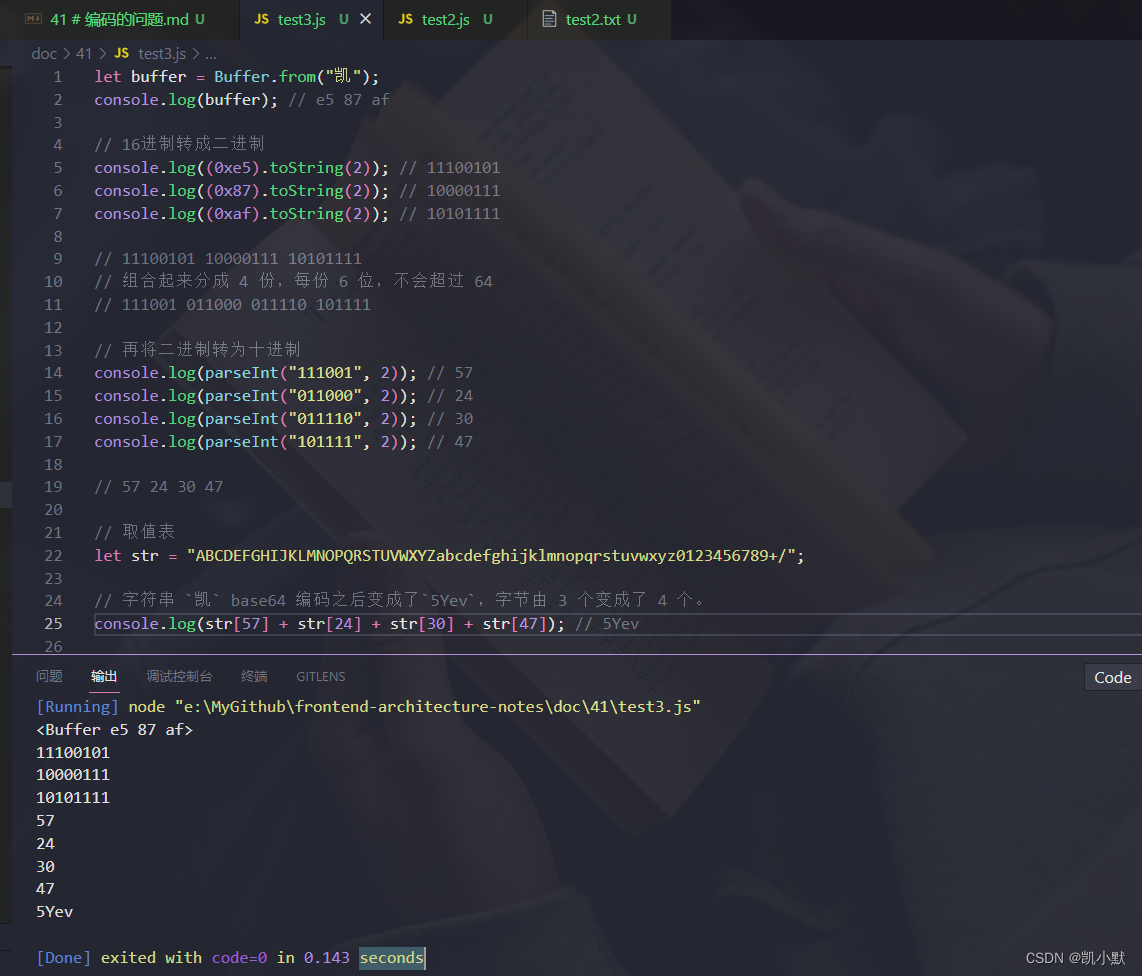
let buffer = Buffer.from("凯");
console.log(buffer); // e5 87 af
// 16进制转成二进制
console.log((0xe5).toString(2)); // 11100101
console.log((0x87).toString(2)); // 10000111
console.log((0xaf).toString(2)); // 10101111
// 11100101 10000111 10101111
// 组合起来分成 4 份,每份 6 位,不会超过 64
// 111001 011000 011110 101111
// 再将二进制转为十进制
console.log(parseInt("111001", 2)); // 57
console.log(parseInt("011000", 2)); // 24
console.log(parseInt("011110", 2)); // 30
console.log(parseInt("101111", 2)); // 47
// 57 24 30 47
// 取值表
let str = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/";
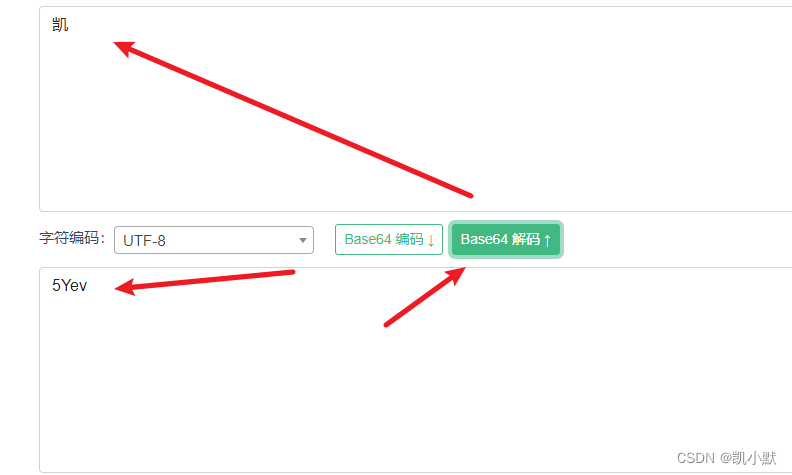
// 字符串 `凯` base64 编码之后变成了`5Yev`,字节由 3 个变成了 4 个。
console.log(str[57] + str[24] + str[30] + str[47]); // 5Yev
我们可以使用在线工具去对上面的结果进行 base64 解码,https://www.toolhelper.cn/EncodeDecode/Base64EncodeDecode