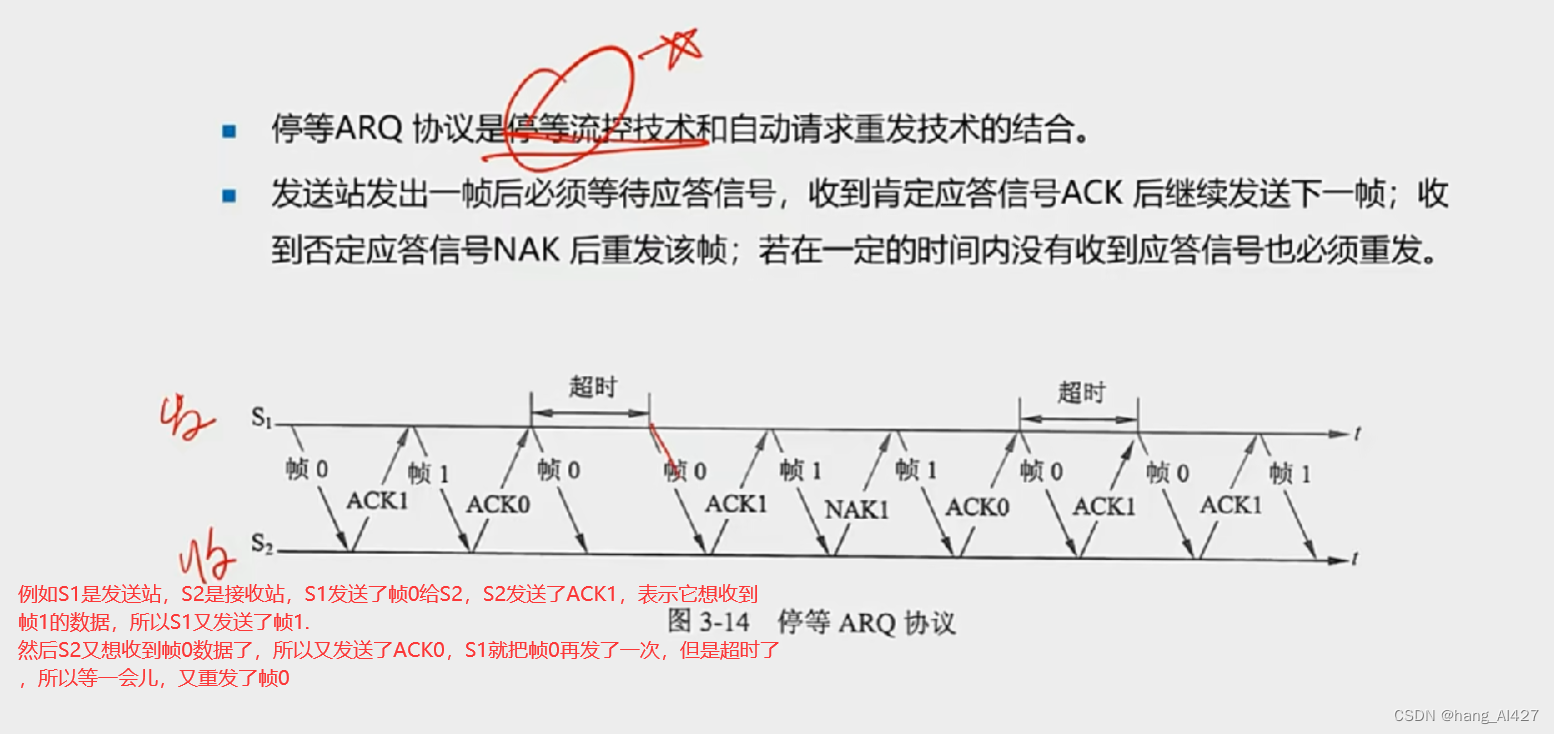
UDP和TCP有什么区别
- TCP协议在传送数据段的时候要给段标号;UDP协议不
- TCP协议可靠;UDP协议不可靠
- TCP协议是面向连接;UDP协议采用无连接
- TCP协议负载较高,采用虚电路;UDP采用无连接
- TCP协议的发送方要确认接收方是否收到数据段(3次握手协议)
- TCP协议采用窗口技术和流控制

对浏览器的缓存机制的理解
浏览器缓存的全过程:
-
浏览器第一次加载资源,服务器返回 200,浏览器从服务器下载资源文件,并缓存资源文件与 response header,以供下次加载时对比使用;
-
下一次加载资源时,由于强制缓存优先级较高,先比较当前时间与上一次返回 200 时的时间差,如果没有超过 cache-control 设置的 max-age,则没有过期,并命中强缓存,直接从本地读取资源。如果浏览器不支持HTTP1.1,则使用 expires 头判断是否过期;
-
如果资源已过期,则表明强制缓存没有被命中,则开始协商缓存,向服务器发送带有 If-None-Match 和 If-Modified-Since 的请求;
-
服务器收到请求后,优先根据 Etag 的值判断被请求的文件有没有做修改,Etag 值一致则没有修改,命中协商缓存,返回 304;如果不一致则有改动,直接返回新的资源文件带上新的 Etag 值并返回 200;
-
如果服务器收到的请求没有 Etag 值,则将 If-Modified-Since 和被请求文件的最后修改时间做比对,一致则命中协商缓存,返回 304;不一致则返回新的 last-modified 和文件并返回 200;
很多网站的资源后面都加了版本号,这样做的目的是:每次升级了 JS 或 CSS 文件后,为了防止浏览器进行缓存,强制改变版本号,客户端浏览器就会重新下载新的 JS 或 CSS 文件 ,以保证用户能够及时获得网站的最新更新。
介绍下 promise 的特性、优缺点,内部是如何实现的,动手实现 Promise
1)Promise基本特性
- 1、Promise有三种状态:pending(进行中)、fulfilled(已成功)、rejected(已失败)
- 2、Promise对象接受一个回调函数作为参数, 该回调函数接受两个参数,分别是成功时的回调resolve和失败时的回调reject;另外resolve的参数除了正常值以外, 还可能是一个Promise对象的实例;reject的参数通常是一个Error对象的实例。
- 3、then方法返回一个新的Promise实例,并接收两个参数onResolved(fulfilled状态的回调);onRejected(rejected状态的回调,该参数可选)
- 4、catch方法返回一个新的Promise实例
- 5、finally方法不管Promise状态如何都会执行,该方法的回调函数不接受任何参数
- 6、Promise.all()方法将多个多个Promise实例,包装成一个新的Promise实例,该方法接受一个由Promise对象组成的数组作为参数(Promise.all()方法的参数可以不是数组,但必须具有Iterator接口,且返回的每个成员都是Promise实例),注意参数中只要有一个实例触发catch方法,都会触发Promise.all()方法返回的新的实例的catch方法,如果参数中的某个实例本身调用了catch方法,将不会触发Promise.all()方法返回的新实例的catch方法
- 7、Promise.race()方法的参数与Promise.all方法一样,参数中的实例只要有一个率先改变状态就会将该实例的状态传给Promise.race()方法,并将返回值作为Promise.race()方法产生的Promise实例的返回值
- 8、Promise.resolve()将现有对象转为Promise对象,如果该方法的参数为一个Promise对象,Promise.resolve()将不做任何处理;如果参数thenable对象(即具有then方法),Promise.resolve()将该对象转为Promise对象并立即执行then方法;如果参数是一个原始值,或者是一个不具有then方法的对象,则Promise.resolve方法返回一个新的Promise对象,状态为fulfilled,其参数将会作为then方法中onResolved回调函数的参数,如果Promise.resolve方法不带参数,会直接返回一个fulfilled状态的 Promise 对象。需要注意的是,立即resolve()的 Promise 对象,是在本轮“事件循环”(event loop)的结束时执行,而不是在下一轮“事件循环”的开始时。
- 9、Promise.reject()同样返回一个新的Promise对象,状态为rejected,无论传入任何参数都将作为reject()的参数
2)Promise优点
- ①统一异步 API
- Promise 的一个重要优点是它将逐渐被用作浏览器的异步 API ,统一现在各种各样的 API ,以及不兼容的模式和手法。
- ②Promise 与事件对比
- 和事件相比较, Promise 更适合处理一次性的结果。在结果计算出来之前或之后注册回调函数都是可以的,都可以拿到正确的值。 Promise 的这个优点很自然。但是,不能使用 Promise 处理多次触发的事件。链式处理是 Promise 的又一优点,但是事件却不能这样链式处理。
- ③Promise 与回调对比
- 解决了回调地狱的问题,将异步操作以同步操作的流程表达出来。
- ④Promise 带来的额外好处是包含了更好的错误处理方式(包含了异常处理),并且写起来很轻松(因为可以重用一些同步的工具,比如 Array.prototype.map() )。
3)Promise缺点
- 1、无法取消Promise,一旦新建它就会立即执行,无法中途取消。
- 2、如果不设置回调函数,Promise内部抛出的错误,不会反应到外部。
- 3、当处于Pending状态时,无法得知目前进展到哪一个阶段(刚刚开始还是即将完成)。
- 4、Promise 真正执行回调的时候,定义 Promise 那部分实际上已经走完了,所以 Promise 的报错堆栈上下文不太友好。
4)简单代码实现
最简单的Promise实现有7个主要属性, state(状态), value(成功返回值), reason(错误信息), resolve方法, reject方法, then方法
class Promise{
constructor(executor) {
this.state = 'pending';
this.value = undefined;
this.reason = undefined;
let resolve = value => {
if (this.state === 'pending') {
this.state = 'fulfilled';
this.value = value;
}
};
let reject = reason => {
if (this.state === 'pending') {
this.state = 'rejected';
this.reason = reason;
}
};
try {
// 立即执行函数
executor(resolve, reject);
} catch (err) {
reject(err);
}
}
then(onFulfilled, onRejected) {
if (this.state === 'fulfilled') {
let x = onFulfilled(this.value);
};
if (this.state === 'rejected') {
let x = onRejected(this.reason);
};
}
}
5)面试够用版
function myPromise(constructor){ let self=this;
self.status="pending" //定义状态改变前的初始状态
self.value=undefined;//定义状态为resolved的时候的状态
self.reason=undefined;//定义状态为rejected的时候的状态
function resolve(value){
//两个==="pending",保证了了状态的改变是不不可逆的
if(self.status==="pending"){
self.value=value;
self.status="resolved";
}
}
function reject(reason){
//两个==="pending",保证了了状态的改变是不不可逆的
if(self.status==="pending"){
self.reason=reason;
self.status="rejected";
}
}
//捕获构造异常
try{
constructor(resolve,reject);
}catch(e){
reject(e);
}
}
myPromise.prototype.then=function(onFullfilled,onRejected){
let self=this;
switch(self.status){
case "resolved": onFullfilled(self.value); break;
case "rejected": onRejected(self.reason); break;
default:
}
}
// 测试
var p=new myPromise(function(resolve,reject){resolve(1)});
p.then(function(x){console.log(x)})
//输出1
6)大厂专供版
const PENDING = "pending";
const FULFILLED = "fulfilled";
const REJECTED = "rejected";
const resolvePromise = (promise, x, resolve, reject) => {
if (x === promise) {
// If promise and x refer to the same object, reject promise with a TypeError as the reason.
reject(new TypeError('循环引用'))
}
// if x is an object or function,
if (x !== null && typeof x === 'object' || typeof x === 'function') {
// If both resolvePromise and rejectPromise are called, or multiple calls to the same argument are made, the first call takes precedence, and any further calls are ignored.
let called
try { // If retrieving the property x.then results in a thrown exception e, reject promise with e as the reason.
let then = x.then // Let then be x.then
// If then is a function, call it with x as this
if (typeof then === 'function') {
// If/when resolvePromise is called with a value y, run [[Resolve]](promise, y)
// If/when rejectPromise is called with a reason r, reject promise with r.
then.call(x, y => {
if (called) return
called = true
resolvePromise(promise, y, resolve, reject)
}, r => {
if (called) return
called = true
reject(r)
})
} else {
// If then is not a function, fulfill promise with x.
resolve(x)
}
} catch (e) {
if (called) return
called = true
reject(e)
}
} else {
// If x is not an object or function, fulfill promise with x
resolve(x)
}
}
function Promise(excutor) {
let that = this; // 缓存当前promise实例例对象
that.status = PENDING; // 初始状态
that.value = undefined; // fulfilled状态时 返回的信息
that.reason = undefined; // rejected状态时 拒绝的原因
that.onFulfilledCallbacks = []; // 存储fulfilled状态对应的onFulfilled函数
that.onRejectedCallbacks = []; // 存储rejected状态对应的onRejected函数
function resolve(value) { // value成功态时接收的终值
if(value instanceof Promise) {
return value.then(resolve, reject);
}
// 实践中要确保 onFulfilled 和 onRejected ⽅方法异步执⾏行行,且应该在 then ⽅方法被调⽤用的那⼀一轮事件循环之后的新执⾏行行栈中执⾏行行。
setTimeout(() => {
// 调⽤用resolve 回调对应onFulfilled函数
if (that.status === PENDING) {
// 只能由pending状态 => fulfilled状态 (避免调⽤用多次resolve reject)
that.status = FULFILLED;
that.value = value;
that.onFulfilledCallbacks.forEach(cb => cb(that.value));
}
});
}
function reject(reason) { // reason失败态时接收的拒因
setTimeout(() => {
// 调⽤用reject 回调对应onRejected函数
if (that.status === PENDING) {
// 只能由pending状态 => rejected状态 (避免调⽤用多次resolve reject)
that.status = REJECTED;
that.reason = reason;
that.onRejectedCallbacks.forEach(cb => cb(that.reason));
}
});
}
// 捕获在excutor执⾏行行器器中抛出的异常
// new Promise((resolve, reject) => {
// throw new Error('error in excutor')
// })
try {
excutor(resolve, reject);
} catch (e) {
reject(e);
}
}
Promise.prototype.then = function(onFulfilled, onRejected) {
const that = this;
let newPromise;
// 处理理参数默认值 保证参数后续能够继续执⾏行行
onFulfilled = typeof onFulfilled === "function" ? onFulfilled : value => value;
onRejected = typeof onRejected === "function" ? onRejected : reason => {
throw reason;
};
if (that.status === FULFILLED) { // 成功态
return newPromise = new Promise((resolve, reject) => {
setTimeout(() => {
try{
let x = onFulfilled(that.value);
resolvePromise(newPromise, x, resolve, reject); //新的promise resolve 上⼀一个onFulfilled的返回值
} catch(e) {
reject(e); // 捕获前⾯面onFulfilled中抛出的异常then(onFulfilled, onRejected);
}
});
})
}
if (that.status === REJECTED) { // 失败态
return newPromise = new Promise((resolve, reject) => {
setTimeout(() => {
try {
let x = onRejected(that.reason);
resolvePromise(newPromise, x, resolve, reject);
} catch(e) {
reject(e);
}
});
});
}
if (that.status === PENDING) { // 等待态
// 当异步调⽤用resolve/rejected时 将onFulfilled/onRejected收集暂存到集合中
return newPromise = new Promise((resolve, reject) => {
that.onFulfilledCallbacks.push((value) => {
try {
let x = onFulfilled(value);
resolvePromise(newPromise, x, resolve, reject);
} catch(e) {
reject(e);
}
});
that.onRejectedCallbacks.push((reason) => {
try {
let x = onRejected(reason);
resolvePromise(newPromise, x, resolve, reject);
} catch(e) {
reject(e);
}
});
});
}
};
代码输出结果
var obj = {
say: function() {
var f1 = () => {
console.log("1111", this);
}
f1();
},
pro: {
getPro:() => {
console.log(this);
}
}
}
var o = obj.say;
o();
obj.say();
obj.pro.getPro();
输出结果:
1111 window对象
1111 obj对象
window对象
解析:
- o(),o是在全局执行的,而f1是箭头函数,它是没有绑定this的,它的this指向其父级的this,其父级say方法的this指向的是全局作用域,所以会打印出window;
- obj.say(),谁调用say,say 的this就指向谁,所以此时this指向的是obj对象;
- obj.pro.getPro(),我们知道,箭头函数时不绑定this的,getPro处于pro中,而对象不构成单独的作用域,所以箭头的函数的this就指向了全局作用域window。
DNS完整的查询过程
DNS服务器解析域名的过程:
- 首先会在浏览器的缓存中查找对应的IP地址,如果查找到直接返回,若找不到继续下一步
- 将请求发送给本地DNS服务器,在本地域名服务器缓存中查询,如果查找到,就直接将查找结果返回,若找不到继续下一步
- 本地DNS服务器向根域名服务器发送请求,根域名服务器会返回一个所查询域的顶级域名服务器地址
- 本地DNS服务器向顶级域名服务器发送请求,接受请求的服务器查询自己的缓存,如果有记录,就返回查询结果,如果没有就返回相关的下一级的权威域名服务器的地址
- 本地DNS服务器向权威域名服务器发送请求,域名服务器返回对应的结果
- 本地DNS服务器将返回结果保存在缓存中,便于下次使用
- 本地DNS服务器将返回结果返回给浏览器
比如要查询 IP 地址,首先会在浏览器的缓存中查找是否有该域名的缓存,如果不存在就将请求发送到本地的 DNS 服务器中,本地DNS服务器会判断是否存在该域名的缓存,如果不存在,则向根域名服务器发送一个请求,根域名服务器返回负责 .com 的顶级域名服务器的 IP 地址的列表。然后本地 DNS 服务器再向其中一个负责 .com 的顶级域名服务器发送一个请求,负责 .com 的顶级域名服务器返回负责 .baidu 的权威域名服务器的 IP 地址列表。然后本地 DNS 服务器再向其中一个权威域名服务器发送一个请求,最后权威域名服务器返回一个对应的主机名的 IP 地址列表。
Vue的父子组件生命周期钩子函数执行顺序?
<!-- 加载渲染过程 -->
<!-- 父beforeCreate -> 父created -> 父beforeMount -> 子beforeCreate -> 子created ->
子beforeMount -> 子mounted -> 父mounted -->
<!-- 子组件更新过程 -->
<!-- 父beforeUpdate -> 子beforeUpdate -> 子updaed -> 父updated -->
<!-- 父组件跟新过程 -->
<!-- 父beforeUpdate -> 父updated -->
<!-- 销毁过程 -->
<!-- 父beforeDestroy -> 子beforeDestroy -> 子destroyed ->父destroyed -->
参考 前端进阶面试题详细解答
闭包
闭包其实就是一个可以访问其他函数内部变量的函数。创建闭包的最常见的方式就是在一个函数内创建另一个函数,创建的函数可以 访问到当前函数的局部变量。

因为通常情况下,函数内部变量是无法在外部访问的(即全局变量和局部变量的区别),因此使用闭包的作用,就具备实现了能在外部访问某个函数内部变量的功能,让这些内部变量的值始终可以保存在内存中。下面我们通过代码先来看一个简单的例子
function fun1() {
var a = 1;
return function(){
console.log(a);
};
}
fun1();
var result = fun1();
result(); // 1
// 结合闭包的概念,我们把这段代码放到控制台执行一下,就可以发现最后输出的结果是 1(即 a 变量的值)。那么可以很清楚地发现,a 变量作为一个 fun1 函数的内部变量,正常情况下作为函数内的局部变量,是无法被外部访问到的。但是通过闭包,我们最后还是可以拿到 a 变量的值
闭包有两个常用的用途
- 闭包的第一个用途是使我们在函数外部能够访问到函数内部的变量。通过使用闭包,我们可以通过在外部调用闭包函数,从而在外部访问到函数内部的变量,可以使用这种方法来创建私有变量。
- 函数的另一个用途是使已经运行结束的函数上下文中的变量对象继续留在内存中,因为闭包函数保留了这个变量对象的引用,所以这个变量对象不会被回收。
其实闭包的本质就是作用域链的一个特殊的应用,只要了解了作用域链的创建过程,就能够理解闭包的实现原理。
let a = 1
// fn 是闭包
function fn() {
console.log(a);
}
function fn1() {
let a = 1
// 这里也是闭包
return () => {
console.log(a);
}
}
const fn2 = fn1()
fn2()
- 大家都知道闭包其中一个作用是访问私有变量,就比如上述代码中的 fn2 访问到了 fn1 函数中的变量 a。但是此时 fn1 早已销毁,我们是如何访问到变量 a 的呢?不是都说原始类型是存放在栈上的么,为什么此时却没有被销毁掉?
- 接下来笔者会根据浏览器的表现来重新理解关于原始类型存放位置的说法。
- 先来说下数据存放的正确规则是:局部、占用空间确定的数据,一般会存放在栈中,否则就在堆中(也有例外)。 那么接下来我们可以通过 Chrome 来帮助我们验证这个说法说法。
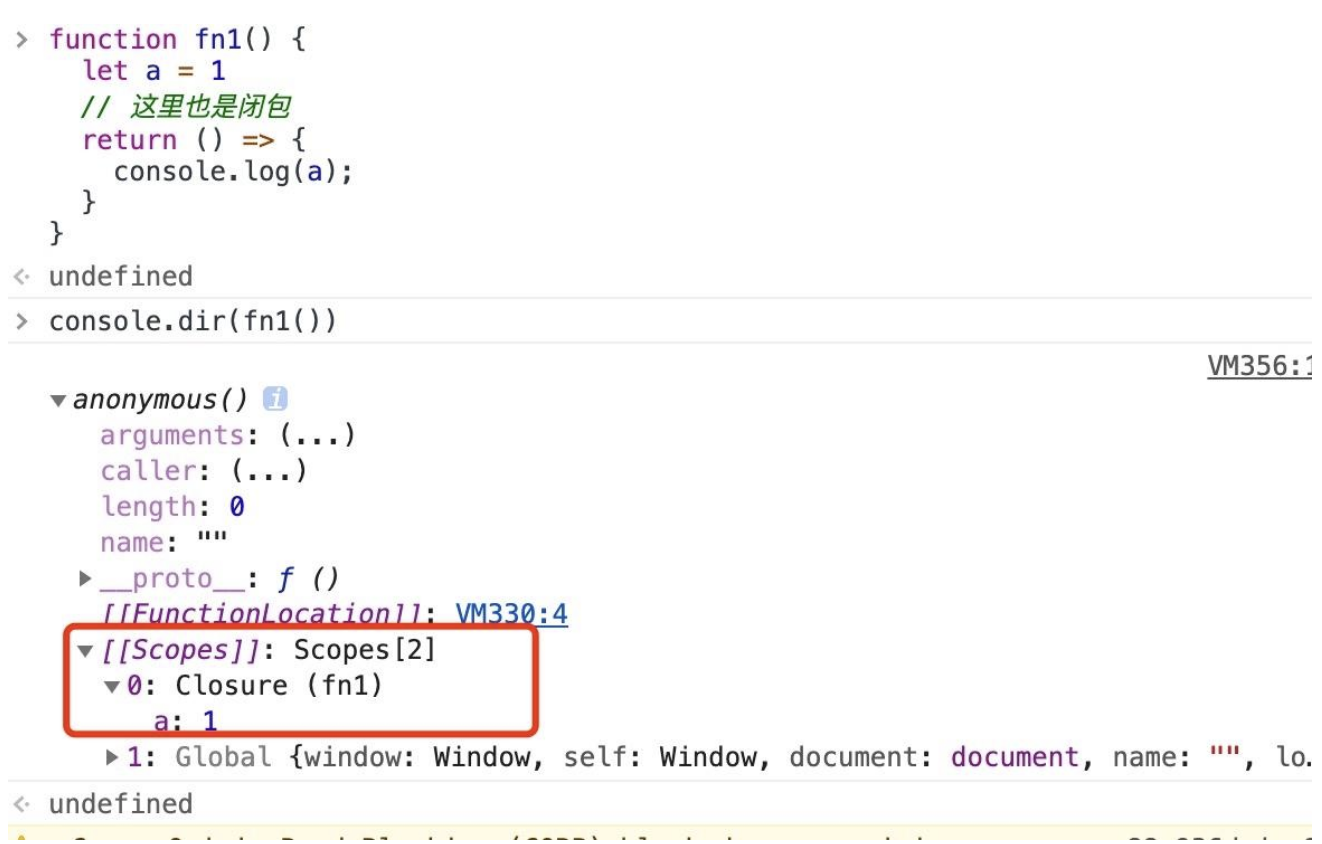
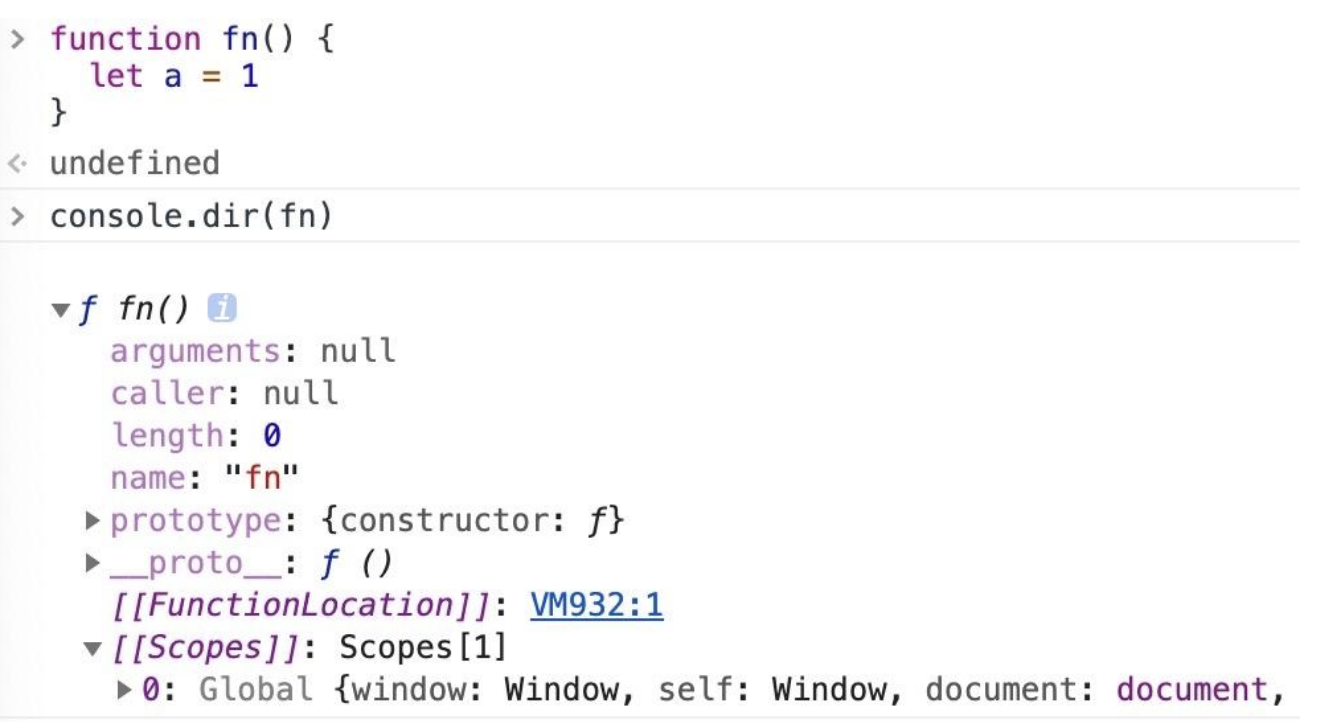
上图中画红框的位置我们能看到一个内部的对象
[[Scopes]],其中存放着变量 a,该对象是被存放在堆上的,其中包含了闭包、全局对象等等内容,因此我们能通过闭包访问到本该销毁的变量。
另外最开始我们对于闭包的定位是:假如一个函数能访问外部的变量,那么这个函数它就是一个闭包,因此接下来我们看看在全局下的表现是怎么样的。
let a = 1
var b = 2
// fn 是闭包
function fn() {
console.log(a, b);
}
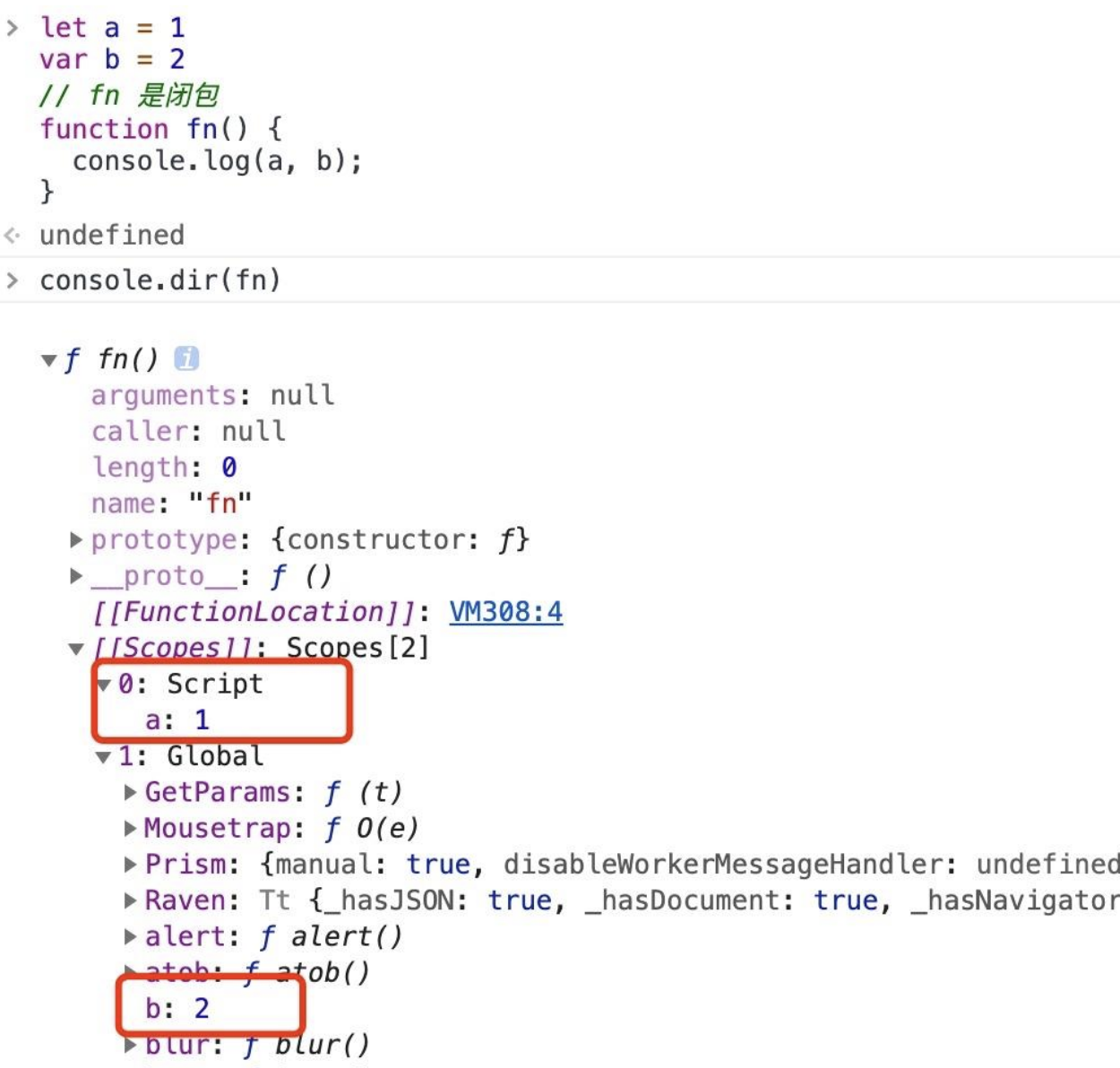
从上图我们能发现全局下声明的变量,如果是 var 的话就直接被挂到 globe 上,如果是其他关键字声明的话就被挂到 Script 上。虽然这些内容同样还是存在 [[Scopes]],但是全局变量应该是存放在静态区域的,因为全局变量无需进行垃圾回收,等需要回收的时候整个应用都没了。
只有在下图的场景中,原始类型才可能是被存储在栈上。
这里为什么要说可能,是因为 JS 是门动态类型语言,一个变量声明时可以是原始类型,马上又可以赋值为对象类型,然后又回到原始类型。这样频繁的在堆栈上切换存储位置,内部引擎是不是也会有什么优化手段,或者干脆全部都丢堆上?只有 const 声明的原始类型才一定存在栈上?当然这只是笔者的一个推测,暂时没有深究,读者可以忽略这段瞎想
因此笔者对于原始类型存储位置的理解为:局部变量才是被存储在栈上,全局变量存在静态区域上,其它都存储在堆上。
当然这个理解是建立的 Chrome 的表现之上的,在不同的浏览器上因为引擎的不同,可能存储的方式还是有所变化的。
闭包产生的原因
我们在前面介绍了作用域的概念,那么你还需要明白作用域链的基本概念。其实很简单,当访问一个变量时,代码解释器会首先在当前的作用域查找,如果没找到,就去父级作用域去查找,直到找到该变量或者不存在父级作用域中,这样的链路就是作用域链
需要注意的是,每一个子函数都会拷贝上级的作用域,形成一个作用域的链条。那么我们还是通过下面的代码来详细说明一下作用域链
var a = 1;
function fun1() {
var a = 2
function fun2() {
var a = 3;
console.log(a);//3
}
}
- 从中可以看出,fun1 函数的作用域指向全局作用域(window)和它自己本身;fun2 函数的作用域指向全局作用域 (window)、fun1 和它本身;而作用域是从最底层向上找,直到找到全局作用域 window 为止,如果全局还没有的话就会报错。
- 那么这就很形象地说明了什么是作用域链,即当前函数一般都会存在上层函数的作用域的引用,那么他们就形成了一条作用域链。
- 由此可见,
闭包产生的本质就是:当前环境中存在指向父级作用域的引用。那么还是拿上的代码举例。
function fun1() {
var a = 2
function fun2() {
console.log(a); //2
}
return fun2;
}
var result = fun1();
result();
- 从上面这段代码可以看出,这里 result 会拿到父级作用域中的变量,输出 2。因为在当前环境中,含有对 fun2 函数的引用,fun2 函数恰恰引用了 window、fun1 和 fun2 的作用域。因此 fun2 函数是可以访问到 fun1 函数的作用域的变量。
- 那是不是只有返回函数才算是产生了闭包呢?其实也不是,回到闭包的本质,我们只需要让父级作用域的引用存在即可,因此还可以这么改代码,如下所示
var fun3;
function fun1() {
var a = 2
fun3 = function() {
console.log(a);
}
}
fun1();
fun3();
可以看出,其中实现的结果和前一段代码的效果其实是一样的,就是在给 fun3 函数赋值后,fun3 函数就拥有了 window、fun1 和 fun3 本身这几个作用域的访问权限;然后还是从下往上查找,直到找到 fun1 的作用域中存在 a 这个变量;因此输出的结果还是 2,最后产生了闭包,形式变了,本质没有改变。
因此最后返回的不管是不是函数,也都不能说明没有产生闭包
闭包的表现形式
- 返回一个函数
在定时器、事件监听、Ajax 请求、Web Workers 或者任何异步中,只要使用了回调函数,实际上就是在使用闭包。请看下面这段代码,这些都是平常开发中用到的形式
// 定时器
setTimeout(function handler(){
console.log('1');
},1000);
// 事件监听
$('#app').click(function(){
console.log('Event Listener');
});
- 作为函数参数传递的形式,比如下面的例子。
var a = 1;
function foo(){
var a = 2;
function baz(){
console.log(a);
}
bar(baz);
}
function bar(fn){
// 这就是闭包
fn();
}
foo(); // 输出2,而不是1
IIFE(立即执行函数),创建了闭包,保存了全局作用域(window)和当前函数的作用域,因此可以输出全局的变量,如下所示
var a = 2;
(function IIFE(){
console.log(a); // 输出2
})();
IIFE 这个函数会稍微有些特殊,算是一种自执行匿名函数,这个匿名函数拥有独立的作用域。这不仅可以避免了外界访问此 IIFE 中的变量,而且又不会污染全局作用域,我们经常能在高级的 JavaScript 编程中看见此类函数。
如何解决循环输出问题?
在互联网大厂的面试中,解决循环输出问题是比较高频的面试题,一般都会给一段这样的代码让你来解释
for(var i = 1; i <= 5; i ++){
setTimeout(function() {
console.log(i)
}, 0)
}
上面这段代码执行之后,从控制台执行的结果可以看出来,结果输出的是 5 个 6,那么一般面试官都会先问为什么都是 6?我想让你实现输出 1、2、3、4、5 的话怎么办呢?
因此结合本讲所学的知识我们来思考一下,应该怎么给面试官一个满意的解释。你可以围绕这两点来回答。
setTimeout为宏任务,由于 JS 中单线程eventLoop 机制,在主线程同步任务执行完后才去执行宏任务,因此循环结束后 setTimeout 中的回调才依次执行- 因为
setTimeout函数也是一种闭包,往上找它的父级作用域链就是 window,变量 i 为 window 上的全局变量,开始执行 setTimeout 之前变量 i 已经就是 6 了,因此最后输出的连续就都是 6。
那么我们再来看看如何按顺序依次输出 1、2、3、4、5 呢?
- 利用 IIFE
可以利用 IIFE(立即执行函数),当每次 for 循环时,把此时的变量 i 传递到定时器中,然后执行,改造之后的代码如下。
for(var i = 1;i <= 5;i++){
(function(j){
setTimeout(function timer(){
console.log(j)
}, 0)
})(i)
}
- 使用 ES6 中的 let
ES6 中新增的 let 定义变量的方式,使得 ES6 之后 JS 发生革命性的变化,让 JS 有了块级作用域,代码的作用域以块级为单位进行执行。通过改造后的代码,可以实现上面想要的结果。
for(let i = 1; i <= 5; i++){
setTimeout(function() {
console.log(i);
},0)
}
- 定时器传入第三个参数
setTimeout 作为经常使用的定时器,它是存在第三个参数的,日常工作中我们经常使用的一般是前两个,一个是回调函数,另外一个是时间,而第三个参数用得比较少。那么结合第三个参数,调整完之后的代码如下。
for(var i=1;i<=5;i++){
setTimeout(function(j) {
console.log(j)
}, 0, i)
}
从中可以看到,第三个参数的传递,可以改变 setTimeout 的执行逻辑,从而实现我们想要的结果,这也是一种解决循环输出问题的途径
常见考点
- 闭包能考的很多,概念和笔试题都会考。
- 概念题就是考考闭包是什么了。
- 笔试题的话基本都会结合上异步,比如最常见的:
for (var i = 0; i < 6; i++) {
setTimeout(() => {
console.log(i)
})
}
这道题会问输出什么,有哪几种方式可以得到想要的答案?
变量提升
当执行
JS代码时,会生成执行环境,只要代码不是写在函数中的,就是在全局执行环境中,函数中的代码会产生函数执行环境,只此两种执行环境。
b() // call b
console.log(a) // undefined
var a = 'Hello world'
function b() {
console.log('call b')
}
想必以上的输出大家肯定都已经明白了,这是因为函数和变量提升的原因。通常提升的解释是说将声明的代码移动到了顶部,这其实没有什么错误,便于大家理解。但是更准确的解释应该是:在生成执行环境时,会有两个阶段。第一个阶段是创建的阶段,
JS解释器会找出需要提升的变量和函数,并且给他们提前在内存中开辟好空间,函数的话会将整个函数存入内存中,变量只声明并且赋值为undefined,所以在第二个阶段,也就是代码执行阶段,我们可以直接提前使用
- 在提升的过程中,相同的函数会覆盖上一个函数,并且函数优先于变量提升
b() // call b second
function b() {
console.log('call b fist')
}
function b() {
console.log('call b second')
}
var b = 'Hello world'
var会产生很多错误,所以在 ES6中引入了let。let不能在声明前使用,但是这并不是常说的let不会提升,let提升了,在第一阶段内存也已经为他开辟好了空间,但是因为这个声明的特性导致了并不能在声明前使用
对 WebSocket 的理解
WebSocket是HTML5提供的一种浏览器与服务器进行全双工通讯的网络技术,属于应用层协议。它基于TCP传输协议,并复用HTTP的握手通道。浏览器和服务器只需要完成一次握手,两者之间就直接可以创建持久性的连接, 并进行双向数据传输。
WebSocket 的出现就解决了半双工通信的弊端。它最大的特点是:服务器可以向客户端主动推动消息,客户端也可以主动向服务器推送消息。
WebSocket原理:客户端向 WebSocket 服务器通知(notify)一个带有所有接收者ID(recipients IDs)的事件(event),服务器接收后立即通知所有活跃的(active)客户端,只有ID在接收者ID序列中的客户端才会处理这个事件。
WebSocket 特点的如下:
- 支持双向通信,实时性更强
- 可以发送文本,也可以发送二进制数据‘’
- 建立在TCP协议之上,服务端的实现比较容易
- 数据格式比较轻量,性能开销小,通信高效
- 没有同源限制,客户端可以与任意服务器通信
- 协议标识符是ws(如果加密,则为wss),服务器网址就是 URL
- 与 HTTP 协议有着良好的兼容性。默认端口也是80和443,并且握手阶段采用 HTTP 协议,因此握手时不容易屏蔽,能通过各种 HTTP 代理服务器。
Websocket的使用方法如下:
在客户端中:
// 在index.html中直接写WebSocket,设置服务端的端口号为 9999
let ws = new WebSocket('ws://localhost:9999');
// 在客户端与服务端建立连接后触发
ws.onopen = function() {
console.log("Connection open.");
ws.send('hello');
};
// 在服务端给客户端发来消息的时候触发
ws.onmessage = function(res) {
console.log(res); // 打印的是MessageEvent对象
console.log(res.data); // 打印的是收到的消息
};
// 在客户端与服务端建立关闭后触发
ws.onclose = function(evt) {
console.log("Connection closed.");
};
为什么有时候⽤translate来改变位置⽽不是定位?
translate 是 transform 属性的⼀个值。改变transform或opacity不会触发浏览器重新布局(reflow)或重绘(repaint),只会触发复合(compositions)。⽽改变绝对定位会触发重新布局,进⽽触发重绘和复合。transform使浏览器为元素创建⼀个 GPU 图层,但改变绝对定位会使⽤到 CPU。 因此translate()更⾼效,可以缩短平滑动画的绘制时间。 ⽽translate改变位置时,元素依然会占据其原始空间,绝对定位就不会发⽣这种情况。
函数节流
触发高频事件,且 N 秒内只执行一次。
简单版:使用时间戳来实现,立即执行一次,然后每 N 秒执行一次。
function throttle(func, wait) {
var context, args;
var previous = 0;
return function() {
var now = +new Date();
context = this;
args = arguments;
if (now - previous > wait) {
func.apply(context, args);
previous = now;
}
}
}
最终版:支持取消节流;另外通过传入第三个参数,options.leading 来表示是否可以立即执行一次,opitons.trailing 表示结束调用的时候是否还要执行一次,默认都是 true。
注意设置的时候不能同时将 leading 或 trailing 设置为 false。
function throttle(func, wait, options) {
var timeout, context, args, result;
var previous = 0;
if (!options) options = {};
var later = function() {
previous = options.leading === false ? 0 : new Date().getTime();
timeout = null;
func.apply(context, args);
if (!timeout) context = args = null;
};
var throttled = function() {
var now = new Date().getTime();
if (!previous && options.leading === false) previous = now;
var remaining = wait - (now - previous);
context = this;
args = arguments;
if (remaining <= 0 || remaining > wait) {
if (timeout) {
clearTimeout(timeout);
timeout = null;
}
previous = now;
func.apply(context, args);
if (!timeout) context = args = null;
} else if (!timeout && options.trailing !== false) {
timeout = setTimeout(later, remaining);
}
};
throttled.cancel = function() {
clearTimeout(timeout);
previous = 0;
timeout = null;
}
return throttled;
}
节流的使用就不拿代码举例了,参考防抖的写就行。
实现数组原型方法
forEach
语法:
arr.forEach(callback(currentValue [, index [, array]])[, thisArg])参数:
callback:为数组中每个元素执行的函数,该函数接受1-3个参数currentValue: 数组中正在处理的当前元素index(可选): 数组中正在处理的当前元素的索引array(可选):forEach()方法正在操作的数组thisArg(可选): 当执行回调函数callback时,用作this的值。返回值:
undefined
Array.prototype.forEach1 = function(callback, thisArg) {
if(this == null) {
throw new TypeError('this is null or not defined');
}
if(typeof callback !== "function") {
throw new TypeError(callback + 'is not a function');
}
// 创建一个新的 Object 对象。该对象将会包裹(wrapper)传入的参数 this(当前数组)。
const O = Object(this);
// O.length >>> 0 无符号右移 0 位
// 意义:为了保证转换后的值为正整数。
// 其实底层做了 2 层转换,第一是非 number 转成 number 类型,第二是将 number 转成 Uint32 类型
const len = O.length >>> 0;
let k = 0;
while(k < len) {
if(k in O) {
callback.call(thisArg, O[k], k, O);
}
k++;
}
}
map
语法:
arr.map(callback(currentValue [, index [, array]])[, thisArg])参数:与
forEach()方法一样返回值:一个由原数组每个元素执行回调函数的结果组成的新数组。
Array.prototype.map1 = function(callback, thisArg) {
if(this == null) {
throw new TypeError('this is null or not defined');
}
if(typeof callback !== "function") {
throw new TypeError(callback + 'is not a function');
}
const O = Object(this);
const len = O.length >>> 0;
let newArr = []; // 返回的新数组
let k = 0;
while(k < len) {
if(k in O) {
newArr[k] = callback.call(thisArg, O[k], k, O);
}
k++;
}
return newArr;
}
filter
语法:
arr.filter(callback(element [, index [, array]])[, thisArg])参数:
callback: 用来测试数组的每个元素的函数。返回true表示该元素通过测试,保留该元素,false则不保留。它接受以下三个参数:element、index、array,参数的意义与forEach一样。
thisArg(可选): 执行callback时,用于this的值。返回值:一个新的、由通过测试的元素组成的数组,如果没有任何数组元素通过测试,则返回空数组。
Array.prototype.filter1 = function(callback, thisArg) {
if(this == null) {
throw new TypeError('this is null or not defined');
}
if(typeof callback !== "function") {
throw new TypeError(callback + 'is not a function');
}
const O = Object(this);
const len = O.length >>> 0;
let newArr = []; // 返回的新数组
let k = 0;
while(k < len) {
if(k in O) {
if(callback.call(thisArg, O[k], k, O)) {
newArr.push(O[k]);
}
}
k++;
}
return newArr;
}
some
语法:
arr.some(callback(element [, index [, array]])[, thisArg])参数:
callback: 用来测试数组的每个元素的函数。接受以下三个参数:element、index、array,参数的意义与 forEach 一样。
thisArg(可选): 执行callback时,用于this的值。
返回值:数组中有至少一个元素通过回调函数的测试就会返回 true;所有元素都没有通过回调函数的测试返回值才会为 false。
Array.prototype.some1 = function(callback, thisArg) {
if(this == null) {
throw new TypeError('this is null or not defined');
}
if(typeof callback !== "function") {
throw new TypeError(callback + 'is not a function');
}
const O = Object(this);
const len = O.length >>> 0;
let k = 0;
while(k < len) {
if(k in O) {
if(callback.call(thisArg, O[k], k, O)) {
return true
}
}
k++;
}
return false;
}
reduce
语法:
arr.reduce(callback(preVal, curVal[, curIndex [, array]])[, initialValue])参数:
callback: 一个 “reducer” 函数,包含四个参数:
preVal:上一次调用callback时的返回值。在第一次调用时,若指定了初始值initialValue,其值则为initialValue,否则为数组索引为 0 的元素array[0]。
curVal:数组中正在处理的元素。在第一次调用时,若指定了初始值initialValue,其值则为数组索引为 0 的元素array[0],否则为array[1]。
curIndex(可选):数组中正在处理的元素的索引。若指定了初始值initialValue,则起始索引号为 0,否则从索引 1 起始。
array(可选):用于遍历的数组。
initialValue(可选): 作为第一次调用callback函数时参数preVal的值。若指定了初始值initialValue,则curVal则将使用数组第一个元素;否则preVal将使用数组第一个元素,而curVal将使用数组第二个元素。
返回值:使用 “reducer” 回调函数遍历整个数组后的结果。
Array.prototype.reduce1 = function(callback, initialValue) {
if(this == null) {
throw new TypeError('this is null or not defined');
}
if(typeof callback !== "function") {
throw new TypeError(callback + 'is not a function');
}
const O = Object(this);
const len = O.length >>> 0;
let k = 0;
let accumulator = initialValue;
// 如果第二个参数为undefined的情况下,则数组的第一个有效值(非empty)作为累加器的初始值
if(accumulator === undefined) {
while(k < len && !(k in O)) {
k++;
}
// 如果超出数组界限还没有找到累加器的初始值,则TypeError
if(k >= len) {
throw new TypeError('Reduce of empty array with no initial value');
}
accumulator = O[k++];
}
while(k < len) {
if(k in O) {
accumulator = callback(accumulator, O[k], k, O);
}
k++;
}
return accumulator;
}
代码输出结果
var a, b
(function () {
console.log(a);
console.log(b);
var a = (b = 3);
console.log(a);
console.log(b);
})()
console.log(a);
console.log(b);
输出结果:
undefined
undefined
3
3
undefined
3
这个题目和上面题目考察的知识点类似,b赋值为3,b此时是一个全局变量,而将3赋值给a,a是一个局部变量,所以最后打印的时候,a仍旧是undefined。
ES6 之前使用 prototype 实现继承
Object.create() 会创建一个 “新” 对象,然后将此对象内部的 [[Prototype]] 关联到你指定的对象(Foo.prototype)。Object.create(null) 创建一个空 [[Prototype]] 链接的对象,这个对象无法进行委托。
function Foo(name) {
this.name = name;
}
Foo.prototype.myName = function () {
return this.name;
}
// 继承属性,通过借用构造函数调用
function Bar(name, label) {
Foo.call(this, name);
this.label = label;
}
// 继承方法,创建备份
Bar.prototype = Object.create(Foo.prototype);
// 必须设置回正确的构造函数,要不然在会发生判断类型出错
Bar.prototype.constructor = Bar;
// 必须在上一步之后
Bar.prototype.myLabel = function () {
return this.label;
}
var a = new Bar("a", "obj a");
a.myName(); // "a"
a.myLabel(); // "obj a"
动态规划求解硬币找零问题
题目描述:给定不同面额的硬币 coins 和一个总金额 amount。编写一个函数来计算可以凑成总金额所需的最少的硬币个数。如果没有任何一种硬币组合能组成总金额,返回 -1
示例1:
输入: coins = [1, 2, 5], amount = 11
输出: 3
解释: 11 = 5 + 5 + 1
示例2:
输入: coins = [2], amount = 3
输出: -1
实现代码如下:
const coinChange = function (coins, amount) {
// 用于保存每个目标总额对应的最小硬币个数
const f = [];
// 提前定义已知情况
f[0] = 0;
// 遍历 [1, amount] 这个区间的硬币总额
for (let i = 1; i <= amount; i++) {
// 求的是最小值,因此我们预设为无穷大,确保它一定会被更小的数更新
f[i] = Infinity;
// 循环遍历每个可用硬币的面额
for (let j = 0; j < coins.length; j++) {
// 若硬币面额小于目标总额,则问题成立
if (i - coins[j] >= 0) {
// 状态转移方程
f[i] = Math.min(f[i], f[i - coins[j]] + 1);
}
}
}
// 若目标总额对应的解为无穷大,则意味着没有一个符合条件的硬币总数来更新它,本题无解,返回-1
if (f[amount] === Infinity) {
return -1;
}
// 若有解,直接返回解的内容
return f[amount];
};
懒加载的特点
- 减少无用资源的加载:使用懒加载明显减少了服务器的压力和流量,同时也减小了浏览器的负担。
- 提升用户体验: 如果同时加载较多图片,可能需要等待的时间较长,这样影响了用户体验,而使用懒加载就能大大的提高用户体验。
- 防止加载过多图片而影响其他资源文件的加载 :会影响网站应用的正常使用。
发布订阅模式(事件总线)
描述:实现一个发布订阅模式,拥有 on, emit, once, off 方法
class EventEmitter {
constructor() {
// 包含所有监听器函数的容器对象
// 内部结构: {msg1: [listener1, listener2], msg2: [listener3]}
this.cache = {};
}
// 实现订阅
on(name, callback) {
if(this.cache[name]) {
this.cache[name].push(callback);
}
else {
this.cache[name] = [callback];
}
}
// 删除订阅
off(name, callback) {
if(this.cache[name]) {
this.cache[name] = this.cache[name].filter(item => item !== callback);
}
if(this.cache[name].length === 0) delete this.cache[name];
}
// 只执行一次订阅事件
once(name, callback) {
callback();
this.off(name, callback);
}
// 触发事件
emit(name, ...data) {
if(this.cache[name]) {
// 创建副本,如果回调函数内继续注册相同事件,会造成死循环
let tasks = this.cache[name].slice();
for(let fn of tasks) {
fn(...data);
}
}
}
}
发布订阅模式
题目描述:实现一个发布订阅模式拥有 on emit once off 方法
实现代码如下:
class EventEmitter {
constructor() {
this.events = {};
}
// 实现订阅
on(type, callBack) {
if (!this.events[type]) {
this.events[type] = [callBack];
} else {
this.events[type].push(callBack);
}
}
// 删除订阅
off(type, callBack) {
if (!this.events[type]) return;
this.events[type] = this.events[type].filter((item) => {
return item !== callBack;
});
}
// 只执行一次订阅事件
once(type, callBack) {
function fn() {
callBack();
this.off(type, fn);
}
this.on(type, fn);
}
// 触发事件
emit(type, ...rest) {
this.events[type] &&
this.events[type].forEach((fn) => fn.apply(this, rest));
}
}
// 使用如下
// const event = new EventEmitter();
// const handle = (...rest) => {
// console.log(rest);
// };
// event.on("click", handle);
// event.emit("click", 1, 2, 3, 4);
// event.off("click", handle);
// event.emit("click", 1, 2);
// event.once("dbClick", () => {
// console.log(123456);
// });
// event.emit("dbClick");
// event.emit("dbClick");
代码输出结果
function runAsync(x) {
const p = new Promise(r =>
setTimeout(() => r(x, console.log(x)), 1000)
);
return p;
}
function runReject(x) {
const p = new Promise((res, rej) =>
setTimeout(() => rej(`Error: ${x}`, console.log(x)), 1000 * x)
);
return p;
}
Promise.race([runReject(0), runAsync(1), runAsync(2), runAsync(3)])
.then(res => console.log("result: ", res))
.catch(err => console.log(err));
输出结果如下:
0
Error: 0
1
2
3
可以看到在catch捕获到第一个错误之后,后面的代码还不执行,不过不会再被捕获了。
注意:all和race传入的数组中如果有会抛出异常的异步任务,那么只有最先抛出的错误会被捕获,并且是被then的第二个参数或者后面的catch捕获;但并不会影响数组中其它的异步任务的执行。
模块化
js 中现在比较成熟的有四种模块加载方案:
- 第一种是 CommonJS 方案,它通过 require 来引入模块,通过 module.exports 定义模块的输出接口。这种模块加载方案是服务器端的解决方案,它是以同步的方式来引入模块的,因为在服务端文件都存储在本地磁盘,所以读取非常快,所以以同步的方式加载没有问题。但如果是在浏览器端,由于模块的加载是使用网络请求,因此使用异步加载的方式更加合适。
- 第二种是 AMD 方案,这种方案采用异步加载的方式来加载模块,模块的加载不影响后面语句的执行,所有依赖这个模块的语句都定义在一个回调函数里,等到加载完成后再执行回调函数。require.js 实现了 AMD 规范
- 第三种是 CMD 方案,这种方案和 AMD 方案都是为了解决异步模块加载的问题,sea.js 实现了 CMD 规范。它和require.js的区别在于模块定义时对依赖的处理不同和对依赖模块的执行时机的处理不同。
- 第四种方案是 ES6 提出的方案,使用 import 和 export 的形式来导入导出模块
在有
Babel的情况下,我们可以直接使用ES6的模块化
// file a.js
export function a() {}
export function b() {}
// file b.js
export default function() {}
import {a, b} from './a.js'
import XXX from './b.js'
CommonJS
CommonJs是Node独有的规范,浏览器中使用就需要用到Browserify解析了。
// a.js
module.exports = {
a: 1
}
// or
exports.a = 1
// b.js
var module = require('./a.js')
module.a // -> log 1
在上述代码中,
module.exports和exports很容易混淆,让我们来看看大致内部实现
var module = require('./a.js')
module.a
// 这里其实就是包装了一层立即执行函数,这样就不会污染全局变量了,
// 重要的是 module 这里,module 是 Node 独有的一个变量
module.exports = {
a: 1
}
// 基本实现
var module = {
exports: {} // exports 就是个空对象
}
// 这个是为什么 exports 和 module.exports 用法相似的原因
var exports = module.exports
var load = function (module) {
// 导出的东西
var a = 1
module.exports = a
return module.exports
};
再来说说
module.exports和exports,用法其实是相似的,但是不能对exports直接赋值,不会有任何效果。
对于
CommonJS和ES6中的模块化的两者区别是:
- 前者支持动态导入,也就是
require(${path}/xx.js),后者目前不支持,但是已有提案,前者是同步导入,因为用于服务端,文件都在本地,同步导入即使卡住主线程影响也不大。 - 而后者是异步导入,因为用于浏览器,需要下载文件,如果也采用同步导入会对渲染有很大影响
- 前者在导出时都是值拷贝,就算导出的值变了,导入的值也不会改变,所以如果想更新值,必须重新导入一次。
- 但是后者采用实时绑定的方式,导入导出的值都指向同一个内存地址,所以导入值会跟随导出值变化
- 后者会编译成
require/exports来执行的
AMD
AMD是由RequireJS提出的
AMD 和 CMD 规范的区别?
- 第一个方面是在模块定义时对依赖的处理不同。AMD推崇依赖前置,在定义模块的时候就要声明其依赖的模块。而 CMD 推崇就近依赖,只有在用到某个模块的时候再去 require。
- 第二个方面是对依赖模块的执行时机处理不同。首先 AMD 和 CMD 对于模块的加载方式都是异步加载,不过它们的区别在于模块的执行时机,AMD 在依赖模块加载完成后就直接执行依赖模块,依赖模块的执行顺序和我们书写的顺序不一定一致。而 CMD在依赖模块加载完成后并不执行,只是下载而已,等到所有的依赖模块都加载好后,进入回调函数逻辑,遇到 require 语句的时候才执行对应的模块,这样模块的执行顺序就和我们书写的顺序保持一致了。
// CMD
define(function(require, exports, module) {
var a = require("./a");
a.doSomething();
// 此处略去 100 行
var b = require("./b"); // 依赖可以就近书写
b.doSomething();
// ...
});
// AMD 默认推荐
define(["./a", "./b"], function(a, b) {
// 依赖必须一开始就写好
a.doSomething();
// 此处略去 100 行
b.doSomething();
// ...
})
- AMD :
requirejs在推广过程中对模块定义的规范化产出,提前执行,推崇依赖前置 - CMD :
seajs在推广过程中对模块定义的规范化产出,延迟执行,推崇依赖就近 - CommonJs :模块输出的是一个值的
copy,运行时加载,加载的是一个对象(module.exports属性),该对象只有在脚本运行完才会生成 - ES6 Module :模块输出的是一个值的引用,编译时输出接口,
ES6模块不是对象,它对外接口只是一种静态定义,在代码静态解析阶段就会生成。
谈谈对模块化开发的理解
- 我对模块的理解是,一个模块是实现一个特定功能的一组方法。在最开始的时候,js 只实现一些简单的功能,所以并没有模块的概念,但随着程序越来越复杂,代码的模块化开发变得越来越重要。
- 由于函数具有独立作用域的特点,最原始的写法是使用函数来作为模块,几个函数作为一个模块,但是这种方式容易造成全局变量的污染,并且模块间没有联系。
- 后面提出了对象写法,通过将函数作为一个对象的方法来实现,这样解决了直接使用函数作为模块的一些缺点,但是这种办法会暴露所有的所有的模块成员,外部代码可以修改内部属性的值。
- 现在最常用的是立即执行函数的写法,通过利用闭包来实现模块私有作用域的建立,同时不会对全局作用域造成污染。
![[附源码]Python计算机毕业设计Django心理健康系统](https://img-blog.csdnimg.cn/0344369b61e54fee84958502112e8e13.png)