01 前言
端到端语音识别系统在足够多数据上训练后,往往能达到不错的识别效果,然而在实际应用场景中,对于不常见的专有名词,例如人名、产品名、小区名等,往往容易识别错误,此类问题需要快速修复,这就需要用到热词增强功能。
WeNet目前已支持CPU Runtime的热词,包含CTC Prefix Beam Search 和 WFST Beam Search两种解码器的实现,我们在GPU Runtime中的ctc_decoder解码器的基础上实现了热词增强,可同时支持流式与非流式服务,GPU热词已在线上广泛应用。近期,我们将热词代码开源至了WeNet社区[1]。
本文将分别介绍热词的实现方案、使用方法,以及测试效果。
02 GPU服务热词实现方案
WeNet的GPU Runtime支持部署流式和非流式服务,其中解码器均为ctc_decoder[2]中实现的CTC Prefix Beam Search。在原始的ctc_decoder解码器中,已经支持了Ngram语言模型打分,我们参考了语言模型打分具体过程,并在此基础上实现了热词增强功能。
在介绍热词增强功能之前,先回顾下ctc_decoder中的语言模型打分过程。ctc_decoder解码器包含分字语言模型和分词语言模型两种。
中文语音识别时,可以删掉文本中的空格,训练基于分字的Ngram语言模型。假设语言模型阶数为4,计算“语音识别”这句话的概率可以写成:
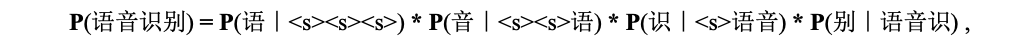
其中“<s>”表示开始标识符,这里4个条件概率中每个概率都包含四个字符。在ctc_decoder解码器中,分字语言模型在每一帧生成新的前缀后都会被使用到。使用分字语言模型打分包含两步,第一步,通过调用make_ngram[3]函数获取当前前缀中的Ngram,即上面条件概率的四个字符“<s>语音识”;第二步,调用语言模型计算上面公式中的条件概率。
英文语音识别时,单词与单词之间需要用空格进行分开,这种情况可以使用分词语言模型。比如计算“end to end asr”的概率可以写成:
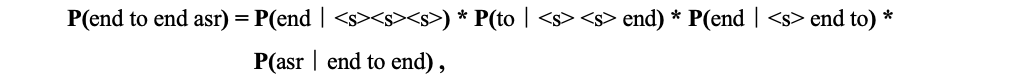
其中语言模型阶数为4,当使用分词语言模型时,每个条件概率中包含4个词。在ctc_decoder解码器中,分词语言模型并不会在每一帧都做语言模型打分,需要积攒几帧已经生成的字符然后串成单词,单词和单词之间按照空格进行隔开,所以分词语言模型只有在遇到空格的时候才会做语言模型打分,上面条件概率中的4个单词组合同样也可以通过make_ngram得到。
在ctc_decoder解码器中,可以使用is_character_based参数来切换分字和分词模型。当is_character_based=True时,使用分字模型;当is_character_based=False时,使用分词模型。
在做热词增强时,可以借鉴语言模型打分的思路,同时复用is_character_based参数。首先通过make_ngram从前缀中得到汉字或者单词的Ngram组合,然后判断词是否在热词词典中,如果词在热词词典中,则将热词分数加上去。在做热词增强时,复用了make_ngram[4]函数用来找固定窗口大小的字和单词,但在热词增强时,可以使用更大的阶数,主要应对比较长的热词。
热词增强和语言模型一样区分了分字和分词的原因如下:因为热词增强在语言模型之前,如果做热词增强make_ngram的阶数高于语言模型make_ngram的阶数,语言模型打分不需要再调用make_ngram,可以直接复用热词中的make_ngram结果。接下来,将详细讲解热词增强中的分字和分词。
2.1 输出字
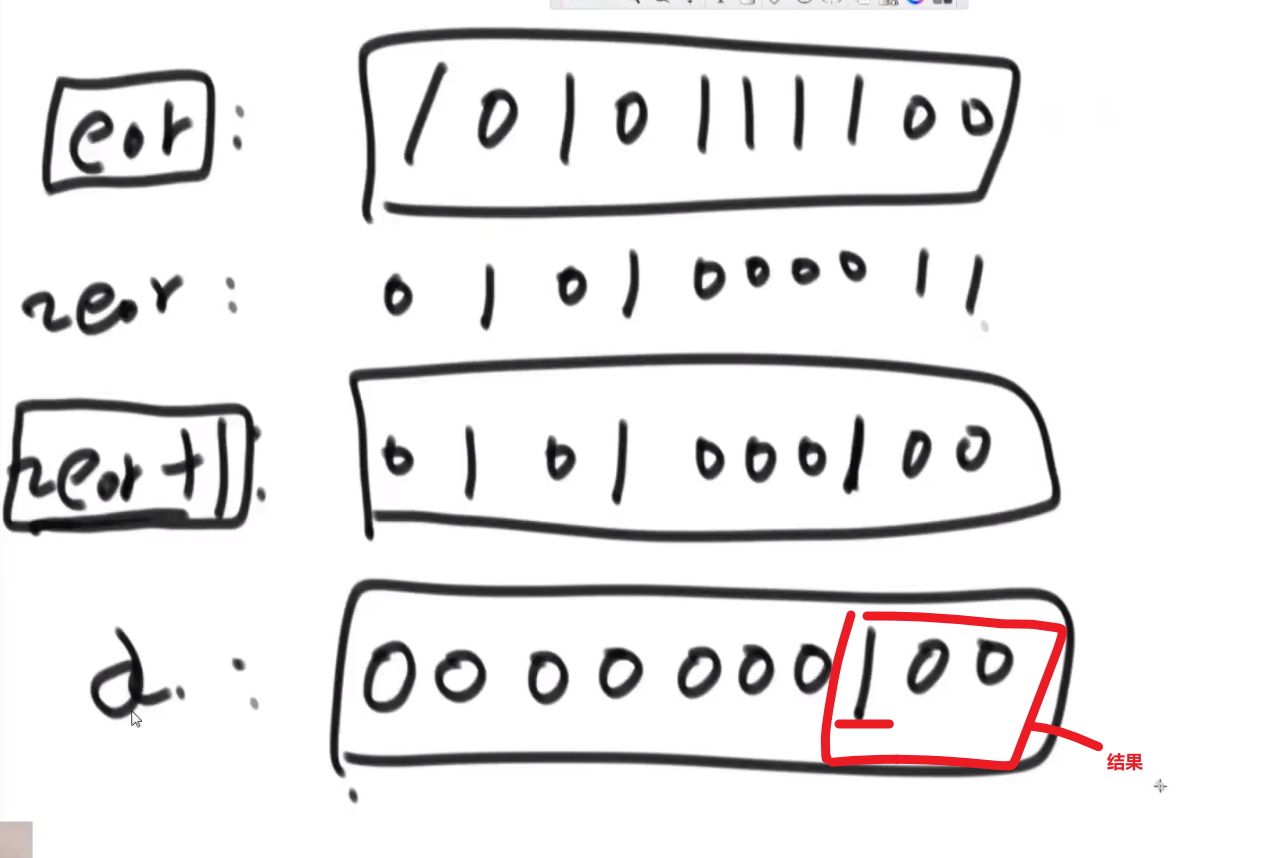
假设输入音频有4帧,第一帧到第四帧解码的字符分别为“语”,“音”,“识”,“别”,如下图所示。在下面例子中,我们假设解码过程每一帧都生成了新的前缀,所以在每一帧都会做热词增强。
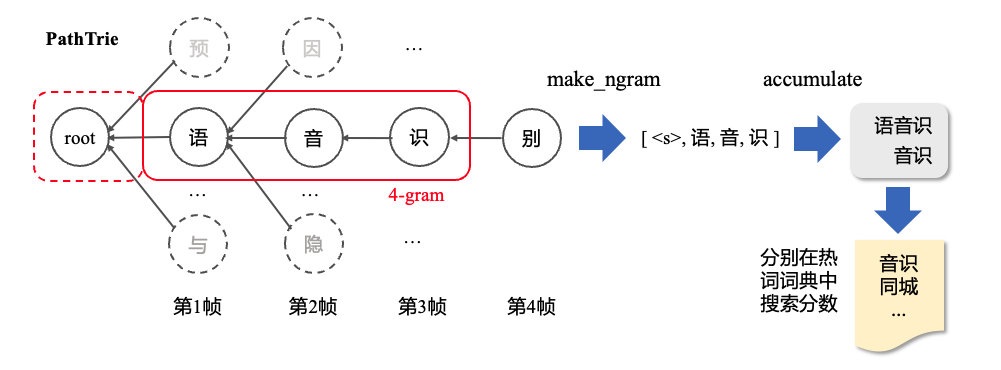
做热词增强时,整体可以分为获取字符、字组成词、加热词分数3个步骤,下面将以第三帧为例,解释输出字的热词增强过程。
Step1:获取字符。调用HotWordsScorer中的make_ngram[4]得到截止到当前帧固定长度窗口内的字符和非<s>的开始索引。比如在第三帧时,假设窗长大小设置为4,将会回溯第三帧、第二帧、第一帧的字符,得到[语, 音, 识]三个字符。由于窗长大小设置为4,会在[语 ,音, 识]的基础上添加“<s>”字符得到[<s>, 语, 音, 识](添加“<s>”的原因在于如果同时再做语言模型打分,可以直接用)。同时也会记录[<s>, 语, 音, 识]中非“<s>”的开始位置索引1。
Step2:字组成词。使用std::accumulate[5]将Step1得到的字符[<s>,语,音,识]组合成为词得到[语音识,音识](默认字组成为词方式),组合成词时需要将“<s>”去掉。
Step3:加热词分数。判断[语音识, 音识]这两个词是否在用户提供的热词词典中。如果在,将热词的权重加入到当前解码路径的logp中。如果“语音识”在热词中,默认不会再继续判断“音识”是否在热词中。
2.2 输出词
当声学模型可以输出空格,除了可以使用2.1中输出字的方式,还可以使用输出词的方式,词与词之间是按照空格进行分隔的。假设输入音频有11帧,每一帧输出如下图所示。其中第4帧、第7帧、第11帧输出的字符为空格。
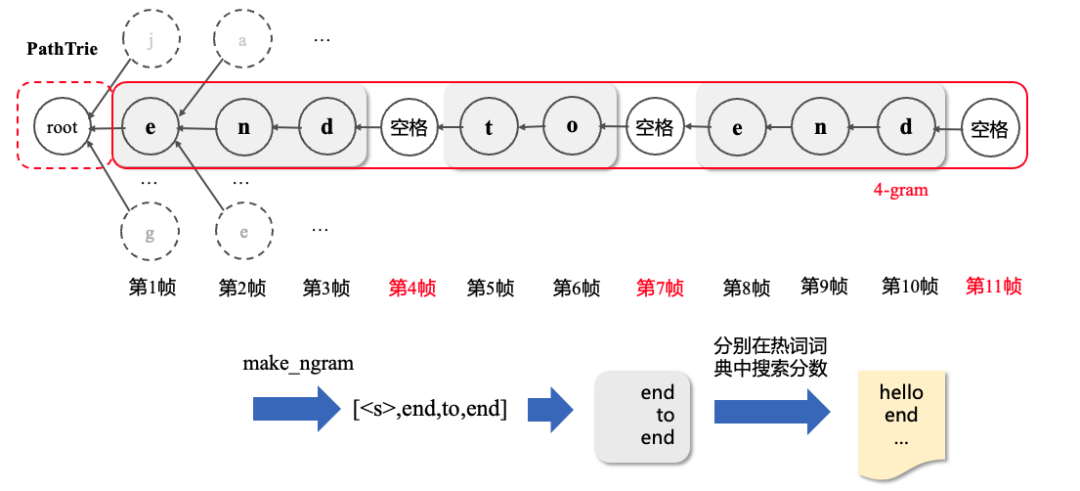
输出为词时,不需要每一步都做热词增强,只需要在输出为空格的时刻,向前面时间步进行回溯即可。接下来介绍如何在第11帧做热词增强。
Step1:获取单词。在输出为空格的时刻,调用HotWordsScorer中的make_ngram[4]得到截止当前帧固定长度窗口内的词语和非“<s>”的开始索引。比如在第11帧时,假设固定窗口大小为4,将会回溯到第7帧、第4帧和第1帧,得到[end, to, end] 3个词,需要在最前面填充“<s>”使得长度为4,得到[<s>, end, to, end]。同时记录下非“<s>”的索引为1。
Step2:加热词分数。判断[<s>, end, to, end]中的“end”,“to”,“end”是否在热词词典中。如果在则将热词的得分加入到当前路径中。
在做完热词打分后,用户可以选择是否做语言模型打分。如果需要做语言模型打分,语言模型Ngram窗口内的词语[<s>, end, to, end]或者字符[<s>, 语, 音, 识]则可以直接复用热词增强时得到的Ngram组合。
介绍完热词增强的实现原理,接下来介绍GPU热词在WeNet中的使用方法。
03 GPU热词的使用方法
3.1 WeNet GPU Runtime中使用
在WeNet GPU Runtime中,包含model_repo(非流式)和model_repo_stateful(流式)两个文件夹,我们主要修改scoring/1/model.py和wenet/1/wenet_onnx_model.py文件,使其能够使用热词增强。

使用热词增强分为如下几步:
Step1: 构造热词词典 hotwords.yaml,将其路径写在config.pbtxt文件中,服务会判断config.pbtxt中hotwords_path是否存在,如果存在则加载热词字典;

Step2: 根据已经加载的热词字典,自动确定热词的最大长度;
Step3: 初始化HotWordsScorer,初始化hotwords_scorer时必须输入热词字典和词汇表vocab,window_length默认长度为4,SPACE_ID为-2,is_character_based为True;
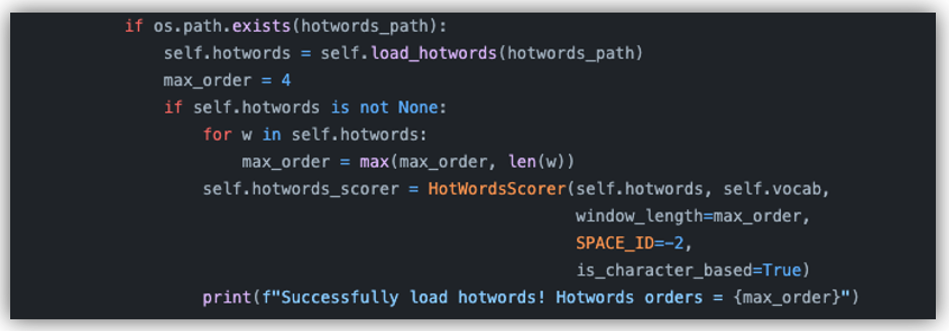
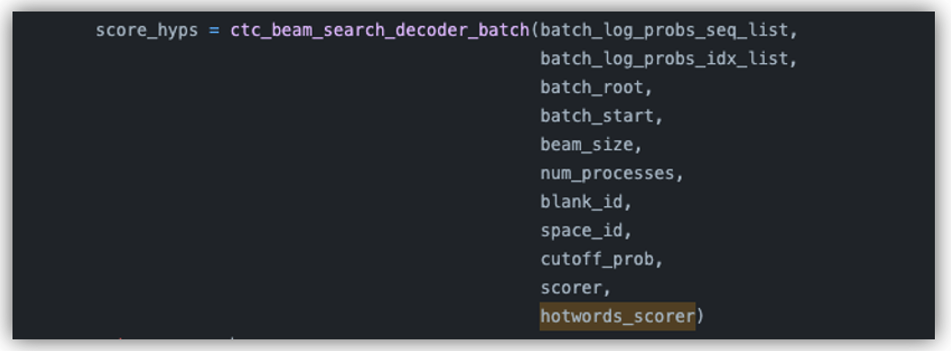
Step4: 将hotwords_scorer作为参数输入到ctc_beam_search_decoder_batch进行解码。
接下来以一条音频为例,测试热词效果,可以参考ctc_decoder中的test_zh.py文件。在测试时,一些解码参数设置为:beam_size=10, blank_id=0, space_id=45,cutoff_prob=1(增大cutoff_prob概率使其能够输出空格字符),alpha=0.5, beta=0.5, window_length=4。热词为“极点”,权重为550(hot_words={'极点': 550}),如果想减少某些词出现的概率,可以设置为负值,权重的数据类型为float。
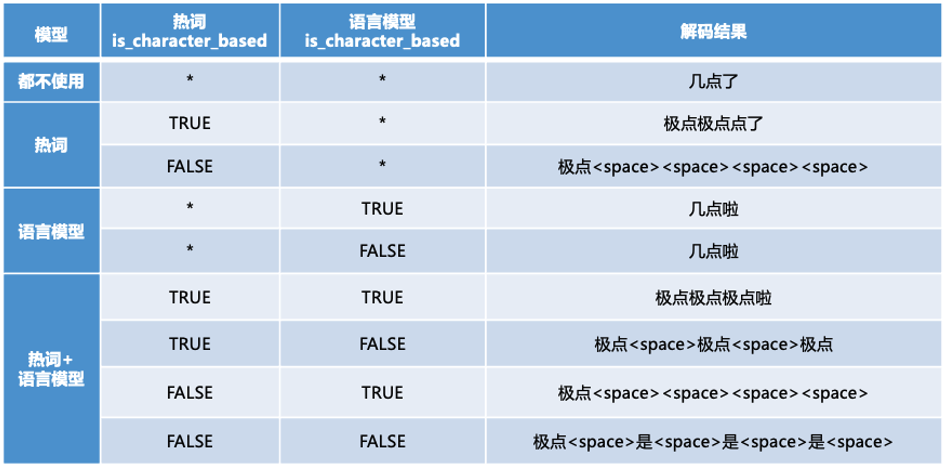
从上表的解码结果来看,加入热词“极点”后,都能够解码出该词。注意,在语言模型is_character_based为False时,这时候使用热词时,需要确保热词在语言模型unigram中或者作为unigram的前缀。因为当语言模型is_character_based为False时,首先会将语言模型unigram词用fst进行存储,然后在解码过程中,每一帧生成的新前缀要在fst中找到一条路径才会生成出真的有效前缀。
3.2 经验之谈
1、在使用WeNet GPU Runtime时,启动tritonserver服务可以添加--model-control-mode=poll --repository-poll-secs=60参数,可以实时热加载热词文件;
2、面对业务场景比较多时,可以设置分业务场景做热词增强。第一种方案是将scoring模块复制几份得到scoring1,scoring2等,然后再将attention_rescoring复制几份得到attention_rescoring1,attention_rescoring2等,不同的业务场景请求不同的attention_rescoring;第二种方案为在ctc_beam_search_decoder_batch解码时,遍历每一个业务线分别进行解码。
3、在使用热词时,先要确定声学模型输出的top beam_size(默认beam_size=10)汉字中有无热词中的汉字,如果没有可以使用TTS合成一部分数据来微调声学模型,或者增大beam_size(10->20);
4、解码器在解码搜索时,在每帧只会保存beam_size条最优路径,有可能加了热词,但是包含热词的路径在中间某一步被剪枝了,这种情况可以增大beam_size(10->20),但是解码耗时会有些上升;
5、一般热词权重设置到10左右,可以先对热词设置一个比较大的权重,看看能否解码出热词,然后再逐步减少权重直到找到最低权重。
6、ctc_decoder中默认的空格为“ ”,如果训练声学模型时将空格用“_”或者“<space>”进行表示,需要将空格[6]改为对应符号。
7、在热词实现2.1节Step2的例子中,我们选择使用了[语音识,音识]的组合方式,当然此处也可以使用 [语音识,语音]的组合,但测试效果不如前者。
04 实验效果
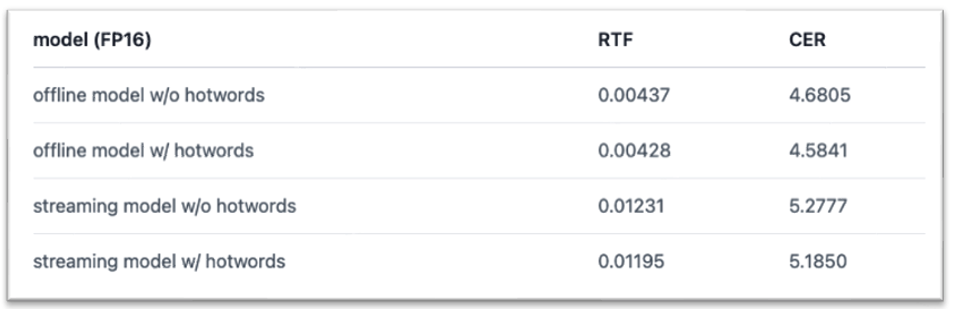
我们分别在AISHELL-1的测试集[7]上,以及AISHELL-1热词测试子集[8]上进行了热词实验,分别对流式与非流式服务是否使用热词进行了比较。实验结果如下:
AISHELL-1 Test dataset
AISHELL-1 hostwords sub-testsets
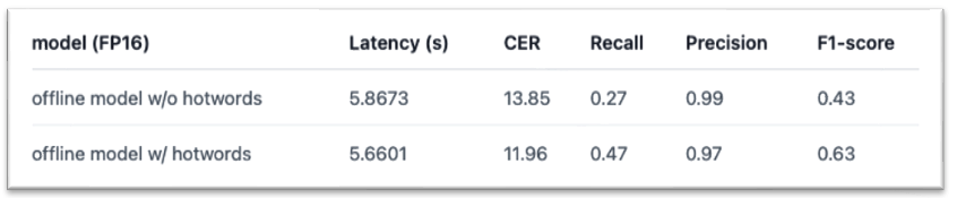
实验结果显示,增加热词可以在几乎不影响解码速度的情况下修复badcase,提升测试集整体准确率。热词文件以及详细实验结果可以参考[9]。
05 后续计划
1. 在现有代码基础上增加字典树实现热词的方案;
2. 支持语言模型部分神经网络语言模型和ngram语言模型一起打分;
3. 支持输出对齐时间戳。
参考资料
[1] https://github.com/wenet-e2e/wenet/pull/1860
[2] https://github.com/Slyne/ctc_decoder
[3] ctc_decoder/swig/scorer.cpp#LL176C34-L176C44
[4] ctc_decoder/swig/hotwords.cpp#L43
[5] ctc_decoder/swig/hotwords.cpp#LL91C9-L91C9
[6] ctc_decoder/swig/scorer.cpp#L166
[7] https://www.openslr.org/33/
[8]https://www.modelscope.cn/datasets/speech_asr/speech_asr_aishell1_hotwords_testsets
[9] https://huggingface.co/58AILab/wenet_u2pp_aishell1_with_hotwords