原文链接:
https://www.ijcai.org/proceedings/2021/0542.pdf
IJCAI 2021
介绍
问题
将嵌套NER视为span分类任务存在两个缺陷,不仅搜索空间大还缺少了实体之间的交互。
IDEA
因此作者提出了sequence-to-set的模型,不再提前给定span,而是提供一个固定的可学习向量集来自适应的学习span。与seq2seq方法相比,作者提出的模型对标签的顺序不敏感,因此更适用于无序的识别任务。
方法
模型包括三个部分:sequence encoder、set decoder和一个基于双向匹配的损失函数。模型的整体结构如下图所示:
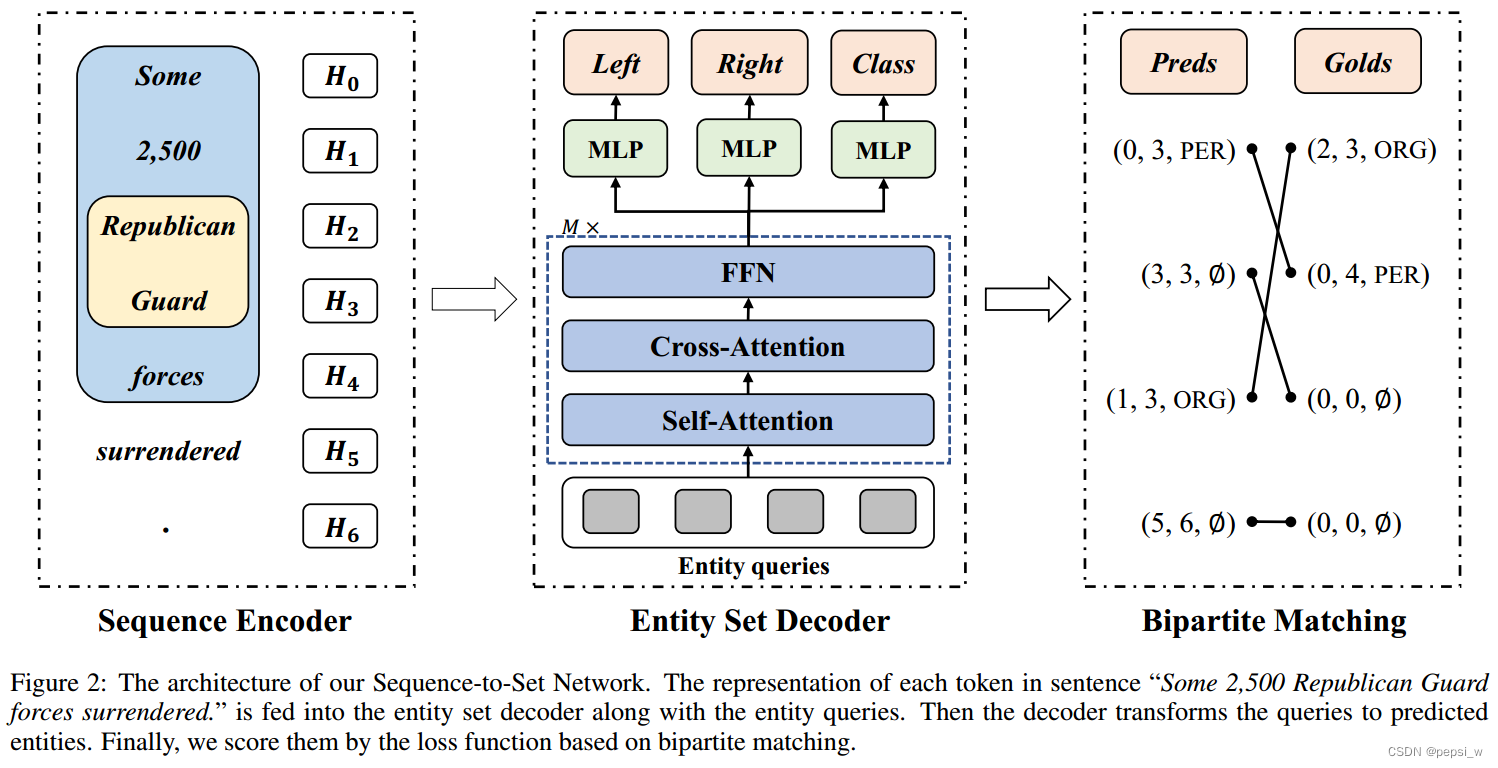
Sequence Encoder
编码器使用BERT和BiLSTM,将第i个token的BERT embedding (对目标token与其前后两个token进行编码后得到的)、GloVE embedding
、part-of-speech (词性)embedding
和字符级的embedding
(由BiLSTM模型生成)进行concat后输入一个BiLSTM去得到最终的序列表征
,如下图所示:
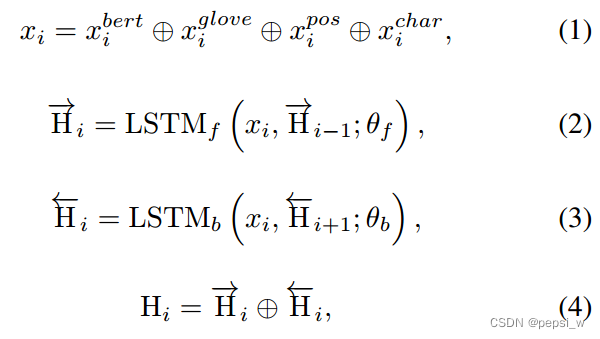
Entity Set Decoder
Entity Set解码器遵循经典的transform架构,使用自注意力和交叉注意力机制来转化N个实体query。自注意力机制来捕获实体之间的依赖性,交叉注意力机制用来获得上下文信息,由于decoder是非自回归的,不需要用掩码机制来防止上下文泄露(这里不是很懂?),因此可以获得完整的上下文语义信息。
N个实体query(Qspan)被M层的entity set decoder转化为output embedding。其中使用自注意力机制:Q = K = V = Qspan,交叉注意力机制:Q = Qspan,K = V = H。这个过程主要涉及多头注意力机制,该过程可以通过以下公式表示:
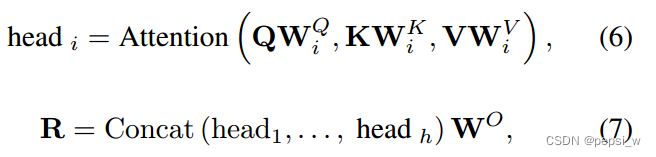
然后将R作为FFN(由带有relu激活函数的三层感知机和一个线性层组成)的输入,其输出表示为U,由于预测的是一个固定大小为N(N被设定为大于序列中的实体数)的实体集,因此对于没有实体识别的情况,使用来表示。给定一个实体query u 下的分类过程如下所示:
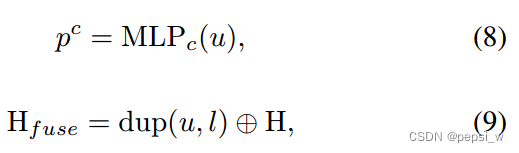

其中dup(u,l)表示将u复制l次,得到l*d的大小,、
、
分别表示实体类别、左右边界的可能性。
Bipartite Matching
在计算训练损失之前,首先需要在预测的实体集中和golden实体集中找到一个最佳匹配(由于模型预测的是一个集合,不是一个个的实体,所以这里将该问题视为最佳匹配的问题)。
golden set表示为y,预测的set表示为,对于大小不足N的y也使用
对其进行填充,为了找到最佳匹配,作者寻找成本最低的N个元素的排列组合(这里没有很看懂,附上原文:To find the optimal matching we search for a permutation of N elements
with the lowest cost)。
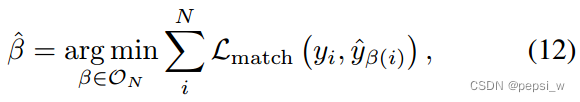
Lmatch表示golden 实体和预测之间的匹配成本,这里使用匈牙利算法来完成这个最佳匹配(因为set是无序的,因此对每一个golden entity y寻找一个最小消耗的)。
考虑到左右边界,将每个golden entity都表示为yi=(li,ri,ci),Lmatch的定义如下:

得到最优匹配之后,计算最终损失:

实验
对比实验
在嵌套NER的多个数据集上进行实验,结果如下所示:

作者认为所提出模型的主要提升在于将嵌套NER任务视为sequence-to-set,与实体内在的无序性是一致的。
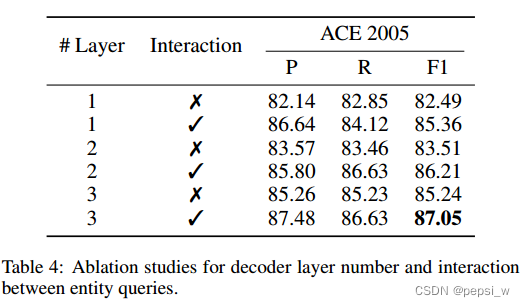
消融实验
作者对decoder的层数和实体query之间的交互进行了消融实验,结果如下图所示:
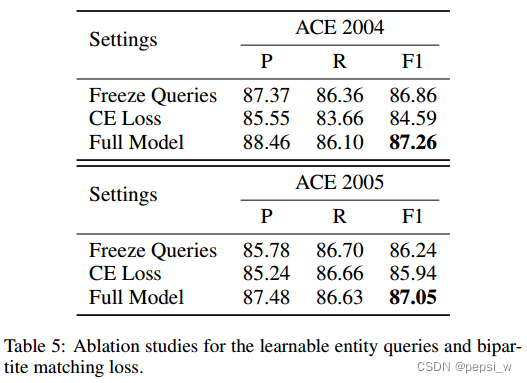
作者还对实体query和双向匹配损失函数进行了消融实验,Freeze query表示冻结query,不再进行改变。CE Loss表示使用交叉熵损失函数来代替作者提出的双向匹配loss。结果如下图所示:
其他实验
作者对Entity Query的数量在ACE2005数据集(实体数量最多为27)上进行了实验,结果如下:
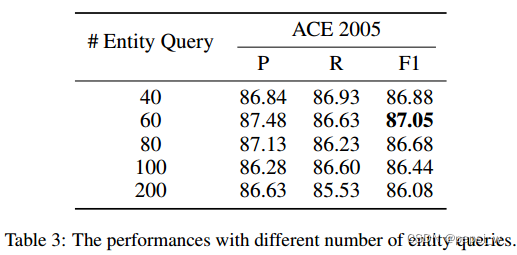
可以看出当query比实际实体多太多的时候,效果反而不太好,因此作者选择query为60进行实验。
总结
这篇论文和上一篇看的论文(PIQN)比较像,作者都差不多,这篇论文更早一点,可以认为PIQN是该方法的改进。从消融实验来看,本文提出的双向匹配loss对模型的性能有较大的提升, 但PIQN并没有继续使用该方法,并且将entity的分配视为一对多的分配问题。并且感觉PIQN的重点在于可学习的query,但本文中的query也是可学习的向量(so,,,PIQN中的这个创新点也不是那么创新?感觉就是将这个点包装了一下,因为本文并没有对该点描述太多。然后将loss换了,主要是分配标签的方法进行了修改,由一对一改为一对多?本人瞎猜测的,如有不对,还请指出!)


![[230608] 阅读TPO58汇总|7:30-9:00+17:05](https://img-blog.csdnimg.cn/cba0e007d19c40d48231d90ce59106c6.png)